1.本发明属于数据出入湖技术领域,尤其是涉及一种高性能的数据湖系统及数据存储方法。
背景技术:
2.数据湖是一个用于存储企业的各种各样原始数据的大型仓库,其中的数据可供存取、处理、分析及传输。数据湖的一部分价值是把不同种类的数据汇聚到一起,另一部分价值是不需要预定义的模型就能进行数据分析。
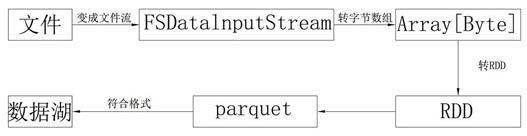
3.数据湖对文件进行格式转变,存储为数据湖支持的parquet,具体如图1所示,数据湖采用api接口将需要入湖的文件转成文件流,然后将文件流转成字节数组,再将字节数组转变成一个rdd,这个rdd包含文件的原始数据(字节数组)和元数据(文件名称,大小等),数据湖底层代码将rdd以parquet格式进行存储,以使数据符合数据湖格式。申请人在使用目前的数据湖系统过程中发现随着文件的增大,文件从湖中读出的速度成倍增长,严重影响数据湖出湖性能。
4.为了解决上述技术问题,申请人查阅了大量资料,没有查询到能够有效解决数据湖出湖性能的方案。申请人经过大量的研究发现,在一些非关系型数据库中,一个字段可以包含多个字段,对应多种字段类型,而目前的数据湖在将文件流转成数组的时候所有字段都只对应一种字段类型,为此,申请人从字段结构入手,对字段结构提出了改进,并获得了显著的效果。
技术实现要素:
5.本发明的目的是针对上述问题,提供一种高性能的数据湖系统;本发明的另一目的是针对上述问题,提供一种能够帮助数据湖系统提高性能的数据存储方法。
6.为达到上述目的,本发明采用了下列技术方案:一种数据湖系统的数据存储方法,包括以下步骤:s1.将文件转成文件流;s2.将文件流转成一个数组嵌套多个子数组的形式;s3.将所述的转成rdd后存储至数据湖的存储层中。
7.在上述的数据湖系统的数据存储方法中,步骤s2中,所述数组嵌套子数组的数量为2
‑
8个。
8.在上述的数据湖系统的数据存储方法中,步骤s2中,所述数组嵌套子数组的数量与当前硬件环境cpu内核数量相一致。
9.在上述的数据湖系统的数据存储方法中,系统通过读取配置文件的方式获取当前硬件环境cpu内核数量从而动态确定相应数量的子数组。
10.在上述的数据湖系统的数据存储方法中,步骤s2与s3之间还包括:
检测当前数组大小,若在设定值之内,则以单行形式存储当前数组;若超过设定值,则将当前数组切分以分行存储,且每行的数组大小均小于设定值。
11.在上述的数据湖系统的数据存储方法中,当数组大小大于设定值时,分行数量n为n=m/s 1,其中m表示数组大小,s表示设定值,/表示整除取商。
12.在上述的数据湖系统的数据存储方法中,对大于设定值的数组切分成多个后返回包含多个rdd的迭代器。
13.在上述的数据湖系统的数据存储方法中,还包括通过轮询自动存储方法:a1.轮询监听文件,在每次轮询中,获得指定路径下所有文件的绝对路径,将其放入到一个数组中,作为最新的偏移量;a2.取上一次轮询的结果,两个数组做差集;a3.根据差集结果获得在此次轮询中, 新增文件的绝对路径,随后通过步骤s1
‑
s3将新增文件存入数据湖。
14.在上述的数据湖系统的数据存储方法中,本系统通过继承fileformat类对数据湖系统重写批读和批写以使数据湖系统支持批读和批写。
15.一种高性能的数据湖系统,采用上述存储方法进行数据存储。
16.本发明的优点在于:提出嵌套的字段结构,为出湖过程的并行处理提供字段结构基础,有效提高出湖性能;嵌套 多行存储的方式,提升大文件存储能力,提高存储上限;通过轮询监听的方式主动将新增文件存入数据湖,实现对新增文件的流处理,提高数据湖的存储性能;根据硬件内核灵活生成嵌套的子数组数量,使数据湖具有更强的扩展性能,针对不同的用户均能够保持最佳的入湖效率,满足用户需求;将数组按照指定大小切分成多个后通过迭代器返回,不使用列表返回,能够有效避免outofmemoryerror(产生栈内存溢出)错误。
附图说明
17.图1为文件入湖的流程图;图2为现有出入湖系统单个txt文件写入写出耗时实验结果图;图3为现有出入湖系统单个pdf文件写入写出耗时实验结果图;图4为现有出入湖系统单个mp4文件写入写出耗时实验结果图;图5为现有出入湖系统单个gz文件写入写出耗时实验结果图;图6为本方案出入湖系统单个txt文件写入耗时实验结果图;图7为本方案出入湖系统单个txt文件读出耗时实验结果图;图8为本方案出入湖系统单个pdf文件写入耗时实验结果图;图9为本方案出入湖系统单个pdf文件读出耗时实验结果图;图10为本方案出入湖系统单个mp4文件写入耗时实验结果图;图11为本方案出入湖系统单个mp4文件读出耗时实验结果图;图12为本方案出入湖系统单个gz文件写入耗时实验结果图;
图13为本方案出入湖系统单个gz文件读出耗时实验结果图。
具体实施方式
18.下面结合附图和具体实施方式对本发明做进一步详细的说明。
19.本实施例公开了一种数据湖系统的数据存储方法,包括以下步骤:s1.将文件转成文件流;s2.将文件流转成一个数组嵌套多个子数组的形式;s3.将所述的数组转成rdd,使其满足数据湖的parquet格式要求后存储至数据湖的存储层中。
20.优选地,本方案通过读取配置文件的方式获取当前硬件环境cpu内核数量从而动态确定相应的嵌套数量,具体为,将文件流转成然后将该数组嵌套子数组的数量与当前硬件环境cpu内核数量相一致的数组。如一个文件流以非嵌套方式转换的数组形式为[1,2,3,4,5,6,7,8],则,若当前硬件环境cpu内核数量为2核,经过本方案嵌套方式转换后的数组形式为嵌套两个子数组的形式,即[[1,2,3,4],[5,6,7,8]];若当前硬件环境cpu内核数量为4核,经过本方案嵌套方式转换后的数组形式为嵌套四个子字数组的形式,即[[1,2],[3,4][5,6],[7,8]]。其它内核数量的情况依此类推。当嵌套数量与cpu内核数量一致时,可以获得最快的读出速度,经过前述自适应方式,能够使数组的嵌套数量与cpu内核相适配,从而保持最佳的读出速度,有效提高出湖性能。
[0021]
优选地,本实施例步骤s2与s3之间还包括:检测当前数组大小,若在设定值之内,则以单行形式存储当前数组;若超过设定值,则将当前数组切分以分行存储,且每行的数组大小均小于设定值。且当数组大小大于设定值时,分行数量n为n=m/s 1,其中m表示数组大小,s表示设定值,/表示整除取商。如数组大小为50mb,设定值为60mb,则n=50/60 1=0 1=1;如数组大小为100mb,设定值为60mb,则n=100/60 1=1 1=2。在切分为多行时,可以使前面几行每行大小为设定值,最后一行为当前数组的剩余字节,也可以每一行平均分配,还可以根据数组情况自由分配,例如可以优选使属于同一子数组的字节放在同一行。
[0022]
进一步地,对大于设定值的数组切分成多个后返回包含多个rdd的迭代器。将数组按照指定大小切分成多个后通过迭代器返回,不使用列表返回,能够有效避免outofmemoryerror(产生栈内存溢出)错误。
[0023]
进一步地,本方法还包括通过轮询自动存储方法,主要是在代码层面,通过轮询(polling)的方式,监听某文件夹下的文件是否有新增,若有新增则将新增文件存入数据湖,具体过程如下:a1.在每次轮询中,获得指定路径下所有文件的绝对路径,将其放入到一个数组中,作为最新的偏移量;a2.取上一次轮询的结果,两个数组做差集;a3.根据差集结果获得在此次轮询中, 新增文件的绝对路径,随后通过步骤s1
‑
s3将新增文件存入数据湖。
[0024]
本方案通过轮询的方式监听文件夹,能够主动将新增文件加入到数据湖,在将数据湖连接数据源后,用户启动针对该数据源的轮询自动存储功能,无需用户手动将新增文
件,满足实际业务需求,进一步提高数据湖存储性能。
[0025]
进一步地,本方法还通过继承fileformat类对数据湖系统重写buildreader(批读)和preparewrite(批写)两个方法来实现批读和批写功能。
[0026]
buildreader的实现与目前spark公司的类似,但数据湖底层将rdd以parquet进行存储后向数据湖返回rdd格式的类型不同,spark返回单个rdd,本方案返回多个迭代器,包含多个rdd,每次返回一小部分,计算机处理完成当前部分后再返回下一部分进行处理,能够有效避免outofmemoryerror。
[0027]
preparewrite的实现方法为,获取多个相关数组,将多个相关数组拼接成一个数组,并通过输出流输出。
[0028]
本实施例还提供一种采用上述存储方法进行数据存储的高性能的数据湖系统。
[0029]
为了验证本方案数据湖系统的数据存储方法的优越性,对基于本方法存储的数据湖系统和现有普通存储的数据湖系统进行出入湖实验对比:实验环境:硬件环境,li7 10代8核,l16g内存;软件环境,lhadoop 伪分布式存储,lubuntu 18.04;jvm环境,l
‑
xms2048m(初始堆大小),l
‑
xmx4096m(最大堆大小)。
[0030]
部分测试数据:不同格式文件的单个写入写出测试:文本文件(txt,pdf);视频文件(mp4);压缩文件(gz)本次采用真实实验数据,没有采用代码随机生成的文件,每组数据写入写出重复3
‑
5次,取平均值为结果。
[0031]
部分实验结果如图2
‑
13所示,图2
‑
图5为现有技术普通存储方式的出入湖系统的出入湖实验结果图,其中,图2为单个txt文件写入写出耗时,由图可知,在写入写出文件达到356张时,写出耗时143347ms,写入耗时13240ms。
[0032]
图3为单个pdf文件写入写出耗时,由图可知,在写入写出文件达到200.8mb时,写出耗时78663ms,写入耗时8796ms。
[0033]
图4为单个mp4文件写入写出耗时,由图可知,在写入写出文件达到391mb时,写出耗时44242ms,写入耗时11003ms。
[0034]
图5为单个gz文件写入写出耗时,由图可知,在写入写出文件达到325mb时,写出耗时309683ms,写入耗时9754ms。
[0035]
图6
‑
图13为采用本方案存储方式的出入湖系统的出入湖实验结果图,其中,图6为单个txt文件写入耗时,由图可知,在写入文件达到356张时,嵌套子数组数量为2、4、6和8的数组结构写入耗时分别需要10417ms、11328ms、10636ms、9978ms。与图2对比可以看到写入速度比普通数据湖系统稍快。
[0036]
图7为单个txt文件读出耗时,由图可知,在读出文件达到356张时,嵌套子数组数量为2、4、6和8的数组结构读出耗时分别需要42439ms、14849ms、12103ms、9868ms。与图2对比可以看到,各嵌套数量情形的读出速度均比普通数据湖系统提高很多。
[0037]
图8为单个pdf文件写入耗时,由图可知,在写入文件达到200.8mb时,嵌套子数组
数量为2、4、6和8的数组结构写入耗时分别需要7664ms、77107ms、7038ms、7307ms。与图3对比可以看到写入速度比普通数据湖系统稍快。
[0038]
图9为单个pdf文件读出耗时,由图可知,在读出文件达到200.8mb时,嵌套子数组数量为2、4、6和8的数组结构读出耗时分别需要22114ms、7724ms、5702ms、6549ms。与图3对比可以看到,各嵌套数量情形的读出速度均比普通数据湖系统提高很多。
[0039]
图10为单个mp4文件写入耗时,由图可知,在写入文件达到391mb时,嵌套子数组数量为2、4、6和8的数组结构写入耗时分别需要11732ms、9702ms、10861ms、11008ms。与图4对比可以看到写入速度接近于普通数据湖系统。
[0040]
图11为单个mp4文件读出耗时,由图可知,在读出文件达到391mb时,嵌套子数组数量为2、4、6和8的数组结构读出耗时分别需要114045ms、33027ms、16389ms、14851ms。与图4对比可以看到,嵌套数量为2的读出速度比普通数据湖系统要慢,但是其余嵌套数量为4、6和8时均比普通数据湖系统快,尤其是嵌套数量为8时,读出速度明显比普通数据湖系统快。
[0041]
图12为单个gz文件写入耗时,由图可知,在写入文件达到325mb时,嵌套子数组数量为2、4、6和8的数组结构写入耗时分别需要10002ms、9415ms、8633ms、8417ms。与图5对比可以看到写入速度接近于普通数据湖系统。
[0042]
图13为单个gz文件读出耗时,由图可知,在读出文件达到325mb时,嵌套子数组数量为2、4、6和8的数组结构读出耗时分别需要81297ms、25790ms、12503ms、9386ms。与图5对比可以看到各嵌套数量情形的读出速度均比普通数据湖系统提高很多。
[0043]
由以上实验图可以看到,采用本方案方式存储的数据湖系统相较于现有技术的数据湖系统在入湖性能上略有提升,但是在出湖性能上却能够大幅度提升,所以本方案能够有效提高数据湖出湖性能。另外,本实验的实验环境是8核内核,所以嵌套数量为8的数组结构具有最高的出入湖性能,这可以从图6
‑
13中与嵌套数量分别为2、4和6的对比可以明显看出。
[0044]
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
[0045]
尽管本文较多地使用了数组、存储层、文件流、嵌套、迭代器等术语,但并不排除使用其它术语的可能性。使用这些术语仅仅是为了更方便地描述和解释本发明的本质;把它们解释成任何一种附加的限制都是与本发明精神相违背的。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。