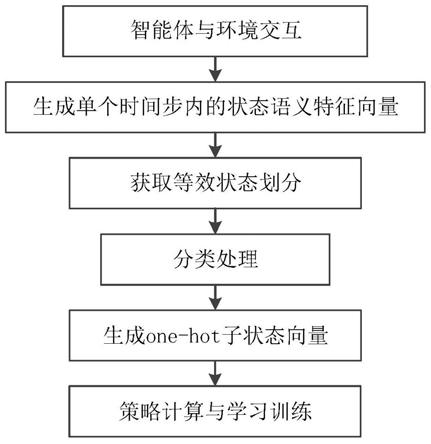
1.本发明属于数据挖掘技术领域,更具体地,涉及一种基于多语义因素与特征聚合的目标用户隐性关系分类方法。
背景技术:
2.电子商务平台的用户数量繁多,且这些用户具有多样化的属性特征和行为活动,并且用户之间具有各种无法直接通过显式信息获得的联系,挖掘使用电子商务平台的用户之间的隐性关系逐渐成为个性化推荐领域的一项重要需求。随着电子商务活动越来越繁多和复杂,出于分析用户社群和优化推荐等目的,对电子商务涉及的目标用户分析方面的各类研究也越来越广泛,其中主流方法之一是对目标用户关系进行分类。
3.目标用户间关系抽取研究包括基于模式匹配的方法和基于机器学习的方法。传统的模式匹配方法提取目标用户间关系依赖于制定的规则和初始的种子,会存在数据的稀疏性等问题,而机器学习方法依赖人工标注目标用户背景知识数据集的大小、质量和手工特征设计的合理性,效果均不佳。
技术实现要素:
4.针对现有技术的以上缺陷或改进需求,本发明提供了一种基于多语义因素与特征聚合的目标用户隐性关系分类方法,基于多语义因素与特征聚合的目标用户隐性关系分类方法能够更好地捕捉原始描述文本的整体特征,并通过融合目标用户的局部语义特征和全局语义特征对目标用户关系进行分类,为社群的发现以及社群关系的挖掘提供支撑。
5.为实现上述目的,按照本发明的一个方面,提供了一种基于多语义因素与特征聚合的目标用户隐性关系分类方法,包括:
6.步骤s1:从已知目标用户的事件文本提取情境语义特征、行为语义特征和情感语义特征三类局部语义特征;
7.步骤s2:将三类局部语义特征进行加权融合,引入自注意力机制,得到事件文本的多语义因素聚合特征;
8.步骤s3:对目标用户的事件文本信息通过双向长短期记忆网络进行全局语义特征提取;
9.步骤s4:将多语义因素聚合特征和全局语义特征输入训练好的分类器,对输出特征softmax后得到目标用户之间的关系类别。
10.本发明的一个实施例中,所述步骤s1包括:
11.对含有目标用户相关事件的文本数据进行采集,对采集的事件文本进行分词,从分词后的文本中提取事件的“情境词”、“行为词”和“情感词”;
12.使用卷积核学习每类词的局部语义嵌入。
13.本发明的一个实施例中,从分词后的文本中提取事件的“情境词”、“行为词”和“情感词”,包括:
14.每条事件文本的“行为词”是通过词性分类器提取事件文本中的动词得到,“情感词”是通过知网hownet情感词典定位事件文本中的积极情感词和消极情感词得到,“情境词”是通过预先训练好的隐含狄利克雷分布(lda,latent dirichlet allocation)模型得到。
15.本发明的一个实施例中,使用卷积核学习每类词的局部语义嵌入,具体为:
16.对一条含有目标用户的事件文本,通过词性分类器、词典定位、lda模型分别得到事件文本中的所有情境词、行为词和情感词,记为情境词集合{bg}、行为词集合{ac}和情感词集合{em};使用卷积核学习每类词的局部语义嵌入:
[0017][0018]
其中,r表示非线性激活函数relu,w[t;t k]表示{bg}、{ac}和{em}每类中第t到t k个词的词向量序列,n表示{bg}、{ac}和{em}每类中词的数量,h
k
表示尺度为k的卷积核,上式将每条事件文本的三类词汇集合分别进行特征提取,得到每条事件文本数据中情境词集合{bg}第i个词的语义嵌入w1
i
,行为词集合{ac}第i个词的语义嵌入w2
i
,情感词集合{em}第i个词的语义嵌入w3
i
,三类词集合中所有词的语义嵌入分别形成这条事件文本的情境语义特征向量行为语义特征向量行为语义特征向量和情感语义特征向量向量长度l、m、n由卷积核的窗口尺寸和一条事件文本中每类词的词汇个数决定。
[0019]
本发明的一个实施例中,所述步骤s2中,将三类局部语义特征进行加权融合,包括:
[0020]
对事件文本的背景语义特征行为语义特征情感语义特征计算每条事件文本三种局部语义向量的权重:件文本三种局部语义向量的权重:
[0021]
对于每条事件文本的三种向量的权重,将s1、s2、s3进行归一化,得到三个权重k1、k2、k3,通过池化层得到加权的三维向量,作为一条事件文本的语义特征向量其中p()为池化函数,用于把向量降为一维。
[0022]
本发明的一个实施例中,所述步骤s2中,引入自注意力机制,得到事件文本的多语义因素聚合特征,包括:
[0023]
加入自注意力机制,将作为每条事件文本的嵌入输入,经过自注意力网络得到每条事件文本的多语义因素聚合特征
[0024]
7、如权利要求1或2所述的基于多语义因素与特征聚合的目标用户隐性关系分类方法,其特征在于,所述步骤s3包括:
[0025]
对采集到的包含目标用户的事件文本数据,将每条事件文本通过dictionarize得到词汇的预训练字典索引向量后,将向量输入双向长短时记忆网络(bi
‑
lstm),分别得到每条事件文本数据的全局语义特征向量
[0026]
本发明的一个实施例中,所述步骤s4包括:
[0027]
训练关系分类器,输入训练数据包括目标用户相关的事件文本和所有已知的用户关系类别,通过融合两个目标用户相应事件对应的多语义因素聚合特征向量和全局特征向量训练得出最佳的分类参数;
[0028]
根据目标用户相应事件对应的多语义因素聚合特征向量和全局特征向量得到两个目标用户之间的关系分类,得到关系类别。
[0029]
本发明的一个实施例中,训练关系分类器的目标函数如下:
[0030][0031]
其中,r是距离度量函数,s和y是关系度量函数,θ和γ是需要训练得出的分类器参数,通过s和y相加得到两个用户之间的关系表示,经过softmax后输出具体的关系分类,l是两个用户之间的已有的关系类别。
[0032]
总体而言,通过本发明所构思的以上技术方案与现有技术相比,具有如下有益效果:
[0033]
(1)直接基于用户事件文本提取文本特征,能充分保留用户事件文本的信息,更精确、灵活地挖掘语义信息;
[0034]
(2)结合局部和整体文本特征全面构建对用户事件文本的语义特征模型,是对已知信息的扩充挖掘,能够缓解数据的稀疏性问题;
[0035]
(3)通过用户相关事件文本来推断用户关系,突破了传统方法通过用户个人信息来获取关系而现实中用户个人真实信息难以获取的限制,同时只利用公开事件文本进行关系分析也满足越来越严格的网络安全要求。
附图说明
[0036]
图1是本发明提出的基于多语义因素与特征聚合的目标用户隐性关系分类方法。
具体实施方式
[0037]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
[0038]
如图1所示,本发明提供了一种基于多语义因素与特征聚合的目标用户隐性关系分类方法,包括以下步骤:
[0039]
步骤s1:从已知目标用户的事件文本提取情境语义特征、行为语义特征和情感语义特征三类局部语义特征;步骤s1包括:
[0040]
首先对含有目标用户相关事件的文本数据进行采集,对采集的事件文本进行分词,通过不同的方法从分词后的文本中提取事件的“情境词”、“行为词”和“情感词”。每条事件文本的“行为词”是通过词性分类器提取事件文本中的动词得到,“情感词”是通过知网hownet情感词典定位事件文本中的积极情感词和消极情感词得到,“情境词”通过预先训练
好的隐含狄利克雷分布(lda,latent dirichlet allocation)模型得到。
[0041]
对一条含有目标用户的事件文本,通过上述词性分类器、词典定位、lda模型分别得到事件文本中的所有情境词、行为词和情感词,记为情境词集合{bg}、行为词集合{ac}和情感词集合{em}。使用卷积核学习每类词的局部语义嵌入。具体如下式:
[0042][0043]
其中,r表示非线性激活函数relu,w[t;t k]表示{bg}、{ac}和{em}每类中第t到t k个词的词向量序列,n表示{bg}、{ac}和{em}每类中词的数量,h
k
表示尺度为k的卷积核,bias是激活函数的偏置项。上式将每条事件文本的三类词汇集合分别进行特征提取,得到每条事件文本数据中情境词集合{bg}第i个词的语义嵌入w1
i
,行为词集合{ac}第i个词的语义嵌入w2
i
,情感词集合{em}第i个词的语义嵌入w3
i
。三类词集合中所有词的语义嵌入分别形成这条事件文本的情境语义特征向量行为语义特征向量和情感语义特征向量和情感语义特征向量向量长度l、m、n由卷积核的窗口尺寸和一条事件文本中每类词的词汇个数决定;
[0044]
步骤s2:将三类局部语义特征进行加权融合,引入自注意力机制,得到事件文本的多语义因素聚合特征;步骤s2包括:
[0045]
对于权力要求2中得到的事件文本的背景语义特征行为语义特征情感语义特征计算每条事件文本三种局部语义向量的权重:
[0046][0047][0048][0049]
对于每条事件文本的三种向量的权重,将s1、s2、s3进行归一化,得到三个权重k1、k2、k3。通过池化层得到加权的三维向量,作为一条事件文本的语义特征向量:
[0050][0051]
其中p()为池化函数,用于把向量降为一维。
[0052]
加入自注意力机制,将作为每条事件文本的嵌入输入,经过自注意力网络得到每条事件文本的多语义因素聚合特征
[0053]
步骤s3:对目标用户的事件文本信息通过双向长短期记忆网络(bi
‑
lstm,bi
‑
directional long short
‑
term memory)进行全局语义特征提取;步骤s3包括:
[0054]
对采集到的包含目标用户的事件文本数据,将每条事件文本通过dictionarize得到词汇的预训练字典索引向量后,将向量输入双向长短时记忆网络(bi
‑
lstm),分别得到每条事件文本数据的全局语义特征向量
[0055]
步骤s4:将多语义因素聚合特征和全局语义特征输入训练好的分类器,对输出特征softmax后得到目标用户之间的关系类别;步骤s4包括:
[0056]
首先训练关系分类器。输入训练数据包括目标用户相关的事件文本和所有已知的用户关系类别,通过融合两个目标用户相应事件对应的多语义因素聚合特征向量和全局特征向量训练得出最佳的分类参数,训练的目标函数如下:
[0057][0058]
其中,r是距离度量函数,s和y是关系度量函数,θ和γ是需要训练得出的分类器参数,通过s和y相加得到两个用户之间的关系表示,经过softmax后输出具体的关系分类,l是两个用户之间的已有的关系类别。
[0059]
得到关系分类器后,可以根据目标用户相应事件对应的多语义因素聚合特征向量和全局特征向量得到两个目标用户之间的关系分类,得到的关系类别属于已有的关系中的一种。
[0060]
以下以一具体实施例说明本发明技术方案:
[0061]
(1)采集含有目标用户的相关事件的文本数据,通过卷积核提取事件文本的背景语义特征、行为语义特征和情感语义特征:
[0062]
首先对含有目标用户相关事件的文本数据进行采集,对采集的事件文本进行分词,通过不同的方法从分词后的文本中提取事件的“情境词”、“行为词”和“情感词”。每条事件文本的“行为词”是通过词性分类器提取事件文本中的动词得到,“情感词”是通过知网hownet情感词典定位事件文本中的积极情感词和消极情感词得到,“情境词”通过预先训练好的lda模型得到,lda模型的主题类型设为20,每类主题的词汇数量设为3,选择“情境词”时,选择一条事件文本输出的主题结果中分布概率最大的前5类主题的相应词汇作为这条事件文本的“情境词”。
[0063]
对一条含有目标用户的事件文本,通过词性分类器得到事件文本中的所有情境词、行为词和情感词,记为情境词集合{bg}、行为词集合{ac}和情感词集合{em}。例如输入文本
“……
a和b经常于x地会面
……”
,利用分词方法分为“a/和/b/经常/于/x地/会面”,得到情境词“x地”“会面”,行为词“会面”和情感词“经常”。
[0064]
使用卷积核提取每类词的局部语义特征。具体如下式:
[0065][0066]
其中,r表示非线性激活函数relu,w[t;t k]表示{bg}、{ac}和{em}每类中第t到t k个词的词向量序列,h
k
表示尺度为k的卷积核。上式将每条事件文本的三类词汇集合分别进行特征提取,得到每条事件文本数据中情境词集合{bg}第i个词的语义特征w1
i
,行为词集合{ac}第i个词的语义特征w2
i
,情感词集合{em}第i个词的语义特征w3
i
。三类词集合中所有词的语义特征分别形成这条事件文本的背景语义特征向量有词的语义特征分别形成这条事件文本的背景语义特征向量行为语义特征向量和情感语义特征
向量向量长度l、m、n由卷积核的窗口尺寸和一条事件文本中每类词的词汇个数决定。
[0067]
在
“……
a和b经常于x地会面
……”
中,通过卷积核分别提取句子的三类局部语义特征。背景语义特征中包含“x地”“会面”的词汇嵌入,行为语义特征包含“会面”的词汇嵌入,情感语义特征包含“经常”的词汇嵌入。
[0068]
(2)对原始文本进行全局语义特征提取;
[0069]
对于权力要求2中得到的事件文本的背景语义特征行为语义特征情感语义特征计算每个词的三种局部语义向量的权重:
[0070][0071][0072][0073]
对于每条事件文本的三种向量的权重,将s1、s2、s3进行归一化,得到三个权重k1、k2、k3。通过池化层得到加权的三维向量,作为一条事件文本的语义特征向量
[0074][0075]
其中p()为池化函数,能够把向量降为一维。加入自注意力机制,将作为每条事件文本的嵌入输入,经过自注意力网络得到每条事件文本的多语义因素聚合特征向量
[0076]
(3)引入自注意力机制,加权求和得到多语义因素聚合特征;
[0077]
对采集到的包含目标用户的事件文本数据,将每条事件文本通过dictionarize得到字典索引向量后,将向量输入双向长短时记忆网络(bi
‑
lstm),分别得到每条事件文本数据的全局语义特征向量
[0078]
例如,对于事件“a和b于x地会面”和“b和c在y公司供职”,获得两个事件分别的
[0079]
(4)输入分类器,得到目标目标用户之间的关系类别;
[0080]
首先训练关系分类器。输入训练数据包括目标用户相关的事件文本和所有已知的用户关系类别,通过融合两个目标用户相应事件对应的多语义因素聚合特征向量和全局特征向量训练得出最佳的分类参数,目标函数如下:
[0081][0082]
其中,r是距离度量函数,s和y是关系度量函数,θ和γ是需要训练得出的分类器参数,通过s和y相加得到两个用户之间的关系表示,经过softmax后输出具体的关系分类,l是两个用户之间的已有的关系类别。
[0083]
得到关系分类器后,可以根据目标用户相应事件对应的多语义因素聚合特征向量
和全局特征向量得到两个目标用户之间的关系分类,得到的关系类别属于已有的关系中的一种。
[0084]
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。