(gpus) for the direct simulation monte carlo method[j].2012)。kashkovsky等人提出了基于多gpu的dsmc并行方法,最大实现了48张gpu卡的并行计算,与intel xeon e5420 cpu单核相比,单张m2090 gpu的加速比为30(kashkovsky, alexander. 3d dsmc computations on a heterogeneous cpu
‑
gpu cluster with a large number of gpus[j].2014)。goldsworthy提出了自适应网格下的dsmc异构gpu并行算法,在1300万仿真粒子的无反应流算例中,在单张tesla c2050 gpu上可获得20倍的加速比(goldsworthy, m. j . a gpu
‑
cuda based direct simulation monte carlo algorithm for real gas flows[j].2014)。在异构体系架构下,已有工作主要是基于cuda编程模型的结构网格dsmc应用的gpu并行计算,应用范围有限,可移植性较差。此外,针对非结构网格dsmc应用,研究基于openacc编程模型异构并行算法的相关工作较少。
技术实现要素:
[0005]
为了解决上述问题,本发明提出一种基于mpi x的dsmc并行计算方法、设备及介质,将粗粒度多进程mpi与细粒度多线程有效结合,充分利用硬件特性,可以大大减少通信量和通信次数,有效提升并行效率,降低dsmc的计算成本。
[0006]
本发明的目的是通过以下技术方案实现的:一种基于mpi x的dsmc并行计算方法,包括以下步骤:步骤1、根据计算的节点数目和节点内可用cpu核数对网格进行分区,将其划分为多个独立的分区文件;步骤2、初始化mpi即粗粒度多进程,各进程载入网格数据;步骤3、各进程对载入的所述网格数据分别进行相应的预处理,若为新的计算,各进程初始化子区域流场;若为续算,则各进程根据标识信息读取本进程的流场信息及仿真粒子信息;步骤4、各进程分别启用多线程并行计算各自分区内的粒子运动;步骤5、各进程分别对各自分区内的粒子索引进行排序编号;步骤6、各进程分别对各自分区内的粒子进行碰撞计算;步骤7、各进程分别对各自的子区域流场性质进行采样;步骤8、迭代步数如果达到阈值,则各进程按进程号分别向临时文件中输出本进程的所有网格及仿真粒子的相关信息,同时将各自的流场结果以多区非结构网格形式进行结果输出,否则返回步骤4。
[0007]
进一步地,所述网格数据包括来流参数信息、循环控制信息以及各自的网格分区文件。
[0008]
进一步地,网格划分的分区数为进程数的整数倍,一个进程能够处理多个网格分区,不同进程对网格分区的处理并行进行。
[0009]
进一步地,对于粒子运动超出原本分区边界的粒子,通过进程间的mpi通信发送到粒子移动到的分区对应的进程。
[0010]
进一步地,对于同一分区内粒子的移动和碰撞计算,依据计算平台的体系架构选取不同并行计算方法,若为同构架构,则选取mpi openmp混合并行编程模型;若为异构架构,则选取mpi openacc混合并行编程模型,cpu和gpu的数据传输存在于步骤4和6。
[0011]
进一步地,若选取mpi openacc混合并行编程模型,则使用openacc进行gpu加速时,通过统一内存模型将cpu和gpu的内存空间映射为统一的公共内存空间,自动管理cpu和gpu之间的动态数组的访问。
[0012]
一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现上述基于mpi x的dsmc并行计算方法的步骤。
[0013]
一种计算机可读存储介质,存储有计算机程序,所述计算机程序被处理器执行时实现上述基于mpi x的dsmc并行计算方法的步骤。
[0014]
本发明的有益效果在于:相比于现有技术,本发明将粗粒度多进程(mpi)与细粒度多线程(openmp/openacc)有效结合,充分利用硬件特性,可以大大减少通信量和通信次数,有效提升并行效率,降低dsmc的计算成本。具体有如下优点:(1)进程间通信打包:当粒子移动到的目的分区不属于本进程处理的分区范围时,这需要将该粒子信息通过mpi通信同步到穿越后的分区所属的mpi进程,本发明通过将这类粒子的所有信息打包然后仅通过一次通信来完成信息同步,从而避免多次通信带来的额外开销。
[0015]
(2)mpi和openmp混合两级并行:通过openmp线程共享内存的特性可明显减少不同进程间的通信开销,同时启用的进程数减少意味着所需最小分区数也会减少,从而有效降低预处理过程的网格分区时间开销。
[0016]
(3)mpi和openacc混合两级并行:通过添加openacc相关的编译指导语句将dsmc中的热点函数置于gpu端进行计算,充分利用gpu的超强计算能力来对dsmc进行有效加速,同时采用cuda统一内存模型管理动态数据,消除了在gpu内核中访问结构体数据时需要深度拷贝的障碍,提高了dsmc应用的易用性。
附图说明
[0017]
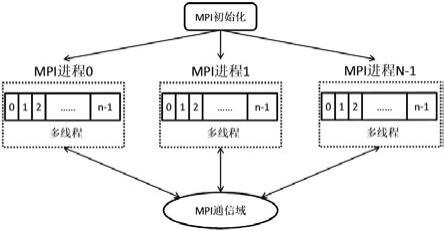
图1是mpi x混合并行结构图。
[0018]
图2是本发明实施例1的基于mpi openmp的dsmc并行计算方法流程图。
[0019]
图3是本发明实施例2的基于mpi openacc的dsmc并行计算方法流程图。
具体实施方式
[0020]
为了对本发明的技术特征、目的和效果有更加清楚的理解,现说明本发明的具体实施方式。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明,即所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0021]
本发明的实施例将提供两种基于大规模非结构的dsmc并行计算方法,包括mpi openmp同构混合并行,以及mpi openacc异构混合并行。本发明通过基于粗粒度多进程(mpi)和细粒度多线程(openmp/openacc)的两级混合并行编程模型对现有的dsmc算法进行并行处理,充分发掘多核cpu和众核gpu的计算潜力,提升dsmc方法的计算速度,以满足dsmc应用对求解规模和速度的需求。
[0022]
实施例1如图1和图2所示,本实施例提供了一种基于mpi openmp的dsmc并行计算方法,包括以下步骤:步骤1、对原网格进行分区,即划分为多个相互独立的小网格,并存放到多个分区文件中;步骤2、初始化各个进程,然后从参数文件以及各自的分区文件中读取网格数据;步骤3、各进程同时对读入的网格数据进行相应的预处理;步骤4、各进程分别启用openmp多线程并行计算各自分区内的粒子运动和壁面碰撞;多线程并行计算过程中,使用openmp规约子句解决存在数据累加的写冲突数据,使用线程互斥区间解决除累加以外的其他数据冲突,对于粒子穿过分区边界面的情况,当这类粒子穿越的目的分区不属于本进程处理的分区范围时,先将该粒子进行标记,待openmp多线程并行计算结束后,将标记粒子暂存到一个临时缓存区,待mpi进程同步后,再通过进程间的mpi通信将缓存区中的粒子发送到穿越后的分区所属的mpi进程;步骤5、待所有进程结束粒子移动的计算后,各进程再对各自分区内运动后的粒子进行重新排序和整理,对网格内的粒子进行重新编码;步骤6、各进程分别对各自分区内的粒子进行碰撞计算,单个进程对分区内的多个网格单元进行openmp多线程并行计算,对于存在的写冲突问题采用和步骤4同样的方法解决;步骤7、各进程分别对各自的子区域流场性质进行采样;步骤8、迭代步数如果达到阈值,则各进程按进程号分别向临时文件中输出本进程的所有网格及仿真粒子的相关信息,同时将各自的流场结果以多区非结构网格形式进行结果输出,否则返回步骤4。
[0023]
下面是粒子移动和碰撞的mpi openmp相应的伪代码,对应上述步骤4和6:algorithm1基于mpi openmp混合并行的dsmcinput:numthread表示线程数,zone表示分区,data_c表示单元数据,data_m表示粒子数据,data_ad表示含累加操作的数据,data_cache表示缓存区,data_thprivate表示线程私有数组;1.functionmovemol(data_m,zone);2.initialdata_cache;3.foreachzoneinmpiprocess;4.!$ompparallel;5.initialdata_thprivate;6.!$ompdoreduction( :data_ad);7.foreachmoleculei;8.update
‑
>data_m[i];9.endfor;10.!$ompenddo;11.!$ompcritical;12.mergedata_thprivate;
13.!$ompendcritical;14.!$ompendparallel;15.endfor;16.updatadata_cache;17.mpi_barrier;18.mpi_communication(data_cache).(以上对应上述步骤4)1.functioncollisions(data_c,zone);2.foreachzoneinmpiprocess;3.!$ompparallel;4.!$ompdoreduction( :data_ad);5.foreachcelliinzone;6.update
‑
>data_c[i];7.endfor;8.!$ompenddo;9.!$ompendparallel;10.endfor.(以上对应上述步骤6)实施例2如图1和图3所示,本实施例提供了一种基于mpi openacc的dsmc并行计算方法,包括以下步骤:步骤1、对原网格进行分区,即划分为多个相互独立的小网格,并存放到多个分区文件中;步骤2、初始化各个进程,然后从参数文件以及各自的分区文件中读取网格数据;步骤3、各进程同时对读入的网格数据进行相应的预处理;步骤4、设备端开辟所需内存空间,将固定常量从主机端通过pcie同步到设备端;步骤5、各进程分别将粒子运动和壁面碰撞所需数据传输到对应的gpu,设备端启用多线程并行计算;多线程并行计算过程中,使用openacc规约子句和原子操作解决存在数据累加的写冲突数据,对于粒子穿过分区边界面的情况,当这类粒子穿越的目的分区不属于本进程处理的分区范围时,先将该粒子进行标记,待设备端计算结束后,将计算结果同步到主机端,然后主机端将标记粒子暂存到一个临时缓存区,待mpi进程同步后,再通过进程间的mpi通信将缓存区中的粒子发送到穿越后的分区所属的mpi进程;步骤6、待所有进程结束粒子移动的计算后,各进程再对各自分区内运动后的粒子进行重新排序和整理,对网格内的粒子进行重新编码;步骤7、各进程分别将各自分区内进行碰撞计算所需的粒子信息传输到对应的gpu,设备端对相应分区内的多个网格单元进行多线程并行计算,碰撞计算结束后将结果同步到主机端;对于存在的写冲突问题采用和步骤5同样的方法解决;步骤8、各进程分别对各自的子区域流场性质进行采样;步骤9、迭代步数如果达到阈值,则各进程按进程号分别向临时文件中输出本进程
的所有网格及仿真粒子的相关信息,同时将各自的流场结果以多区非结构网格形式进行结果输出,否则返回步骤5。
[0024]
下面是粒子移动和碰撞的mpi openacc相应的伪代码,对应上述步骤5和步骤7:algorithm2基于mpi openacc混合并行的dsmcinput:numthread表示线程数,zone表示分区,data_c表示单元数据,data_m表示粒子数据,data_ad表示含累加操作的数据,data_cache表示缓存区;1.functionmovemol(data_m,zone);2.initialdata_cache;3.foreachzoneinmpiprocess;4.!$accupdatedevice(data_m,zone);5.!$accparallel;6.!$accloopreduction( :data_ad);7.foreachmoleculei;8.update
‑
>data_m[i];9.endfor;10.!$accendparallel;11.!$accupdatehost(data_m);12.endfor;13.updatadata_cache;14.mpi_barrier;15.mpi_communication(data_cache).(以上对应上述步骤5)1.functioncollisions(data_c,zone);2.foreachzoneinmpiprocess;3.!$accupdatedevice(data_c,zone);4.!$accparallel;5.!$accloopreduction( :data_ad);6.foreachcelliinzone;7.update
‑
>data_c[i];8.endfor;9.!$accendparallel;10.!$accupdatehost(data_c,data_ad);11.endfor.(以上对应上述步骤7)需要说明的是,对于前述的方法实施例1和2,为了简便描述,故将其表述为一系列的动作组合,但是本领域技术人员应该知悉,本技术并不受所描述的动作顺序的限制,因为依据本技术,某些步骤可以采用其他顺序或者同时进行。其次,本领域技术人员也应该知悉,说明书中所描述的实施例均属于优选实施例,所涉及的动作和模块并不一定是本技术所必须的。
[0025]
实施例3本实施例在实施例1或2的基础上:本实施例提供了一种计算机设备,包括存储器和处理器,该存储器存储有计算机程序,该处理器执行该计算机程序时实现实施例1或2的dsmc并行计算方法的步骤。其中,计算机程序可以为源代码形式、对象代码形式、可执行文件或者某些中间形式等。
[0026]
实施例4本实施例在实施例1或2的基础上:本实施例提供了一种计算机可读存储介质,存储有计算机程序,该计算机程序被处理器执行时实现实施例1或2的dsmc并行计算方法的步骤。其中,计算机程序可以为源代码形式、对象代码形式、可执行文件或者某些中间形式等。存储介质包括:能够携带计算机程序代码的任何实体或装置、记录介质、计算机存储器、只读存储器(rom)、随机存取存储器(ram)、电载波信号、电信信号以及软件分发介质等。需要说明的是,存储介质包含的内容可以根据司法管辖区内立法和专利实践的要求进行适当的增减,例如在某些司法管辖区,根据立法和专利实践,存储介质不包括电载波信号和电信信号。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。