1.本发明涉及数据存储技术领域,具体涉及一种记录对象存储桶统计计数的方法。
背景技术:
2.对象存储,即基于对象的存储,是用来描述解决和处理离散单元的方法的通用术语,这些离散单元称为对象。与文件一样,对象包含数据,但是和文件不同的是,对象在一个层结构中不会再有层级结构。每个对象都在一个被称作存储池的扁平地址空间的同一级别里,一个对象不会属于另一个对象的下一级。
3.文件和对象都有与它们所包含的数据相关的元数据,但是对象是以扩展元数据为特征的。每个对象都被分配一个唯一的标识符,允许一个服务器或者最终用户来检索对象,而不必知道数据的物理地址。这种方法对于在云计算环境中自动化和简化数据存储有帮助。对象存储经常被比作在一家高级餐厅代客停车,当一个顾客需要代客停车时,他就把钥匙交给别人,换来一张收据;这个顾客不用知道他的车被停在哪,也不用知道在他用餐时服务员会把他的车移动多少次。在这个比喻中,一个存储对象的唯一标识符就代表顾客的收据。
4.对象存储网关(rgw)是对象存储提供的一种服务,使得客户能够利用标准对象存储api来访问对象存储集群,而对象存储网关通过内部接口来访问底下的存储引擎。
5.对象存储网关一般为web服务,提供标准的restful接口,在对象网关层可以进行用户权限的控制、协议的转换以及数据分析处理等,极大地丰富了对象存储的使用场景。
6.用于存放存储对象(object)的容器被称作存储空间或存储桶(bucket),可简称“桶”,每个存储对象必须从属于某个存储桶。不同的存储桶具有不同的配置属性,包括地域、访问权限、存储类型等。用户可以根据实际生产中存储对象的需求来创建不同属性的存储桶。
7.存储桶的统计计数属于该存储桶的元数据信息,主要用于保存该存储桶的对象统计信息,包括对象总数、对象总大小等,每个存储桶自身均具有唯一的统计计数。在分布式存储ceph中统计计数存放在omap(单机键值存储系统)中,在key/value(键值)结构下对应为一个名为rgw_bucket_dir_header的一个key(键)。
8.每个存储桶均具有唯一的统计计数,在高并发场景下如果采用同步更新统计计数的方法则会由于请求在osd(对象存储引擎)中的排队而出现阻塞i/o的现象,所以现阶段很多厂商记录存储桶统计计数的方式是异步进行。在进行相关统计计数的更新操作时,会把需要更新的内容变成一条消息发送至第三方组件,由后台去消费这条消息,异步地进行统计计数的更新。这种异步的统计方案依赖于第三方组件,其优点是不会因更新统计信息而造成写操作i/o流程的阻塞,对性能影响较小,并且,在多个客户端或者多个线程并发对同一个存储桶进行操作时,可以避免冲突场景;但其缺点也很明显,具体表现在如下两方面:1)依赖第三方消息队列,维护成本加大,当将消息异步发送到队列时,需要对消息进行持久化,防止由于掉电而产生的消息丢失,导致统计计数未能正确更新;
2)由于采用异步更新方案,所以当对存储对象操作完成后,对于统计计数的更新会存在一定的延时,所以在异步更新的操作没有完成时,对统计信息的读取会不准确。
9.另一种记录存储桶统计计数的方案是同步统计,当对象存储网关每次收到写请求,在完成对存储桶中的存储对象的put/delete操作时,同步地将该存储桶的统计计数进行更新,对于统计计数的更新也属于这次修改操作i/o流程的一部分。所以同步统计的方案会使得写请求的耗时增加,但由于是同步操作,所以对于统计信息的读取不会不准确。但在高并发场景下,当多个客户端中的多个线程对同一个存储桶中的存储对象进行操作时,所有的线程均会去更新这个存储桶所属的统计计数,而由于统计计数的唯一性,在ceph中会将这个请求在osd中排队,变成串行执行,会导致性能下降。
技术实现要素:
10.在同步更新统计计数的方案中,由于分布式存储ceph本身的架构,在高并发场景下在同一时间只会有一个线程对目标存储桶的统计计数进行更新,所以会存在请求排队而阻塞i/o的问题,使请求的处理流程增加了额外的排队等待耗时。鉴于此,本发明提出一种记录对象存储桶统计计数的方法,旨在同步统计的流程基础上,通过更换后端存储组件的方法来解决高并发场景下由于请求排队而造成的不必要的等待耗时,并避免在高并发场景下对同一个key修改而造成的写冲突问题和写热点问题。
11.一种记录对象存储桶统计计数的方法,包括如下步骤:s1、对象存储网关完成写操作后,对目标对象所属存储桶的统计计数的键的值进行同步更新;s2、将目标存储桶的统计计数的键拆分为若干子键,将整个键空间分成指定片数的子空间;s3、任务线程从其缓存中读取目标键的值,修改后重新储存,并且持久化到该目标键的子键所属的分布式事务键值数据库;s4、对象存储网关接受读取目标存储桶统计计数的请求后,结合请求对应的存储桶,分拆成对多个子键的处理请求并下发到后端的分布式事务键值数据库;s5、分布式事务键值数据库对目标存储桶的统计计数的子键进行遍历,并在分布式事务键值数据库节点中进行归并处理,再将归并的结果返回到对象存储网关进行二次归并。
12.进一步地,步骤s1中,对象存储网关的每个线程在完成自身写请求后,根据对象所属存储桶和自身线程id生成目标存储桶统计计数的键。
13.进一步地,当客户端下发写请求到对象存储网关时,对象存储网关将写请求派发到多个线程进行处理。
14.进一步地,通过步骤s2对统计计数的键进行拆分后,执行写操作时,执行写操作的线程要先按照预先约定格式拼接需要修改的键。
15.进一步地,执行写操作的线程按照预先约定格式拼接需要修改的键,包括:执行写操作的线程按照<(uuid % shard_num) bucket id separate char uuid>的格式,将需要修改的键的子键拼接起来;其中,(uuid % shard_num)是将uuid根据分片数目shard_num取模拼接而成;bucket id表示存储桶id;separate char为分隔符;uuid是由对象存储网关id和线程id生成的一个通用唯一识别码。
16.进一步地,步骤s2中对统计计数的键进行拆分时,分配给每个对象存储网关一个唯一的id,同时,每个对象存储网关所具有的线程也拥有在所属对象存储网关内独立的id;在更新统计计数时,每个线程独立去完成对自身相关键的更新。
17.进一步地,步骤s2中对统计计数的键进行拆分时,子键的结构设计为:首先是目标存储桶的id,其后是用于与其它子键进行区分的分隔符,再利用对象存储网关id和线程id生成一个通用唯一识别码拼接在末尾。
18.进一步地,分片形成的子键分散到不同的分布式事务键值数据库节点上。
19.进一步地,步骤s5中,执行读操作时,在分布式事务键值数据库中对目标存储桶的统计计数的子键按<分片编号 bucket id>遍历,并进行归并。
20.进一步地,步骤s5执行读操作包括:当客户端下发对目标存储桶的读请求到对象存储网关时,对象存储网关将读请求转发到后端的每个分布式事务键值数据库节点;每个节点对目标存储桶的统计计数的子键前缀遍历,所述子键前缀即分片后的对象存储网关id外加线程id再拼接上bucket id,此时并不将结果进行返回,而是将结果下推到分布式事务键值数据库进行协处理,将遍历结果在分布式事务键值数据库内部进行归并,归并不同的子键后缀<对象存储网关id 线程id>;每个分布式事务键值数据库节点将归并的结果返回至对象存储网关,在对象存储网关内部进行二次归并。
21.本发明技术方案的有益效果包括:本发明在同步统计的流程基础上,通过更换后端存储组件(将存储桶的元数据存储方式由原有的单机键值存储系统替换为分布式事务键值数据库)来解决高并发场景下由于请求排队而造成的不必要的等待耗时,将排队的串行请求变成并行;并且,重新设计了统计计数的键,将原先存储桶唯一的统计计数键拆分为多个子键,避免了在高并发场景下对同一个键修改而造成的写冲突;此外,对这些子键进行了分片处理,使得其在存储至后端分布式数据库时可以避免写热点问题。
附图说明
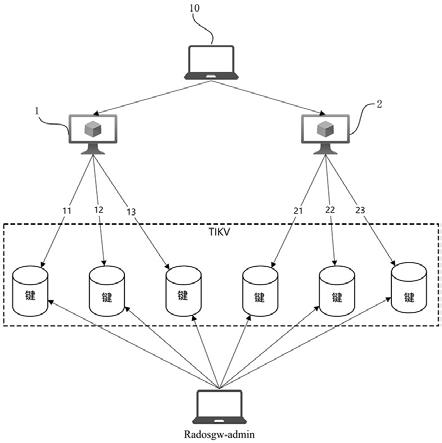
22.图1是本发明实施例记录对象存储桶统计计数的方法的实施架构图。
23.图2是本发明实施例统计计数的子键结构示意图。
24.图3是本发明实施例记录统计计数流程示意图。
25.图4是本发明实施例同步统计计数读取流程示意图。
具体实施方式
26.下面结合附图和具体的实施方式对本发明作进一步说明。
27.本发明的具体实施例提出一种记录对象存储桶统计计数的方法,包括如下步骤:s1、对象存储网关完成写操作后,对目标对象所属存储桶的统计计数的键的值进行同步更新。s2、将目标存储桶的统计计数的键拆分为若干子键,将整个键空间分成指定片数的子空间;对统计计数的键进行拆分后,执行写操作时,执行写操作的线程要先按照预先约定格式拼接需要修改的键。s3、任务线程从其缓存中读取目标键的值,修改后重新储存,并且持久化到该目标键的子键所属的分布式事务键值数据库。s4、对象存储网关接受读取目标存储桶统计计数的请求后,结合请求对应的存储桶,分拆成对多个子键的处理请求并下发到后端的分布式事务键值数据库。s5、分布式事务键值数据库对目标存储桶的统计计数的子键进行遍历,并在分布式事务键值数据库节点中进行归并处理,再将归并的结果返回到对象存储网关进行二次归并。
28.与分布式存储ceph对于元数据的存储方式不同,本发明上述实施例的方法将存储
桶的元数据存储方式从原先的omap(单机键值存储系统)替换成分布式的tikv(分布式事务键值数据库),这对于元数据的读/写性能有一定的提高,即减少了由于同步统计所产生的额外i/o耗时。此外,由于后端存储更换,请求不会发往osd(对象存储引擎),在高并发场景下,对于某个存储桶统计计数key(键)的修改不需要进行排队,即由串行处理改为了并行处理。
29.但是在高并发场景下,在执行写请求时,由于统计计数的唯一性,写请求会频繁地出现冲突问题,常见的解决方案包括两种,对资源加锁和冲突重试。对资源加锁,会存在获取锁的等待时间,在等待的过程中i/o会被阻塞,影响性能。冲突重试,会在资源冲突时再次执行造成冲突的流程,除了正常i/o流程的阻塞之外,还会存有额外的内存开销。故此,本发明针对同步统计方案进行了优化,对存储桶的统计计数的键拆分成了多个子键,将统计计数的更新绑定到对应的线程,有效地避免了写冲突。
30.对统计计数的键进行拆分可以有效地避免写冲突,但由于拆分后的所有子键前缀是相同的,所以存在分布式系统常见的写热点问题,该问题会导致i/o的压力无法分摊到每个节点,故而又产生了新的技术问题,本发明针对这个现象也进行了改进,将统计计数的键进行分片处理并打散,将整个键空间(键的范围)通过哈希分成指定片数的子空间,属于同一子空间的子键在写入时会落入同一个range(区间)或者相邻的range。
31.在处理写请求时,由于原有的单个统计计数的键被拆分成多个子键,所以在执行对于统计计数的读请求时,需要将拆分后的统计计数的子键进行批量读取,再进行归并处理,获取最终的统计计数结果。但拆分统计计数的键造成键数量增多,最多可至10w量级,如果将键值全部读入至rgw(对象存储网关)会使得业务压力激增。所以,本发明将归并统计计数的键的部分操作下推至各个tikv节点,每个tikv节点遍历各自与目标存储桶相关的统计计数信息,在tikv节点内进行初步归并统计,再将结果回传至rgw,进行二次归并,这样在rgw进行归并的key的数量等于tikv节点数,成倍地减少了归并的key的数量级,有效地减少了网络开销和rgw层的业务压力。
32.请参考图1,为本发明记录对象存储桶统计计数的方法的实施架构图。如图1所示,客户端10会向对象存储网关(如网关1、网关2等)下发对象写请求。对象存储网关在收到写请求时,会将请求派发至多个线程,比如:网关1收到客户端10下发的写请求时,会将写请求分发至属于它的多个线程(如线程11、线程12、线程13等);网关2收到客户端10下发的写请求时,会将写请求分发至属于它的多个线程(如线程21、线程22、线程23等)。对象存储网关的每个线程在完成自身写请求后,根据对象所属存储桶和自身线程id生成目标存储桶统计计数的键。在对象存储网关层,为了将原有的统计计数的key进行分片 ,需要分配给每个rgw一个独一无二的id,而每个rgw中所具有的线程也拥有在所属rgw内独立的id,在更新统计计数时,每个线程独立去完成对自身相关key的更新。
33.为解决同步统计高并发场景下的写入冲突,本发明将存储桶唯一的统计计数key重新设计,将其拆分成若干个子key。子key的结构设计为:首先是目标存储空间bucket的id,加上特殊的分隔符,再利用对象存储网关id和线程id生成一个uuid(通用唯一识别码)拼接在末尾。由于后端存储为分布式数据库tikv,所以会存在写热点问题,需要对这些key进行分片处理,将上步骤生成的uuid根据shard_num(分片数目)进行取模,拼接成为上步骤生成的子key的前缀。这一操作将统计计数key进行了打散,使其落入所分成的片中,分散至
不同的tikv节点上。因此,本发明对统计计数key拆分后的结构由对象存储网关id和线程id生成的64位uuid按照分片数目打散,接上对应bucket的id、用于与其他key进行区分的特殊分隔符和uuid,如图2所示,为<(uuid % shard_num) bucket id separate char uuid>的格式,其中,(uuid % shard_num)为前缀,bucket id表示目标存储桶的id;separate char是与其它子key区别开来的特殊分隔符;uuid是由对象存储网关id和线程id生成的一个通用唯一识别码,位于末尾。在执行写操作时,执行写操作的线程按照<(uuid % shard_num) bucket id separate char uuid>的格式,将需要修改的键的子键拼接起来。
34.在采用了tikv作为后端存储组件,并将存储桶统计计数的key进行拆分以及key空间分片处理的基础上,本发明记录统计计数的写请求流程如图3所示,包括:1.1 客户端下发多个对不同object的put/delete请求到rgw,rgw将请求分摊到多个线程(如thread 1、thread 2、
…
、thread n)并处理;1.2 在每个线程完成自身的object写请求后,会根据object所属bucket和自身线程id去生成目标存储桶统计计数key;1.3每个线程在自身的统计计数缓存中读取这个目标存储桶统计计数key并进行修改(比如修改容量、数目等),修改后将结果写入tikv。
35.在读取存储桶的统计计数时,由于统计计数key被拆分为多个子key,所以在读取时需要将这些子key进行批量读取,并将结果进行归并处理。具体读取流程参考图4,包括:2.1 当客户端下发对目标存储桶的读请求到对象存储网关时,对象存储网关将读请求转发到后端的每个分布式事务键值数据库节点;2.2 每个节点对目标存储桶的统计计数的子键前缀遍历,所述子键前缀即分片后的对象存储网关id外加线程id再拼接上bucket id,此时并不将结果进行返回,而是将结果下推到分布式事务键值数据库进行协处理,将遍历结果在分布式事务键值数据库内部进行归并,归并不同的子键后缀<对象存储网关id 线程id>;2.3 每个分布式事务键值数据库节点将归并的结果返回至对象存储网关,在对象存储网关内部进行二次归并。
36.综上,本发明对同步统计方案进行了改造,实现了在高并发场景下的并行记录统计计数,减少了多个写请求的排队耗时,提高了写性能,并且对读请求可能造成的影响进行了优化,减轻了读取统计计数请求的业务压力。
37.以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的技术人员来说,在不脱离本发明构思的前提下,还可以做出若干等同替代或明显变型,而且性能或用途相同,都应当视为属于本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。