1.本发明涉及软件测试,尤其涉及软件源代码层面的变异测试。
背景技术:
2.评价软件程序的测试过程是否完善是软件测试的一个重要指标。在软件测试中,一个良好的测试过程应当能够感知到被测程序细微的变化。若测试过程不能感知到被测程序细微的变化,说明测试过程是存在缺陷的,或者是测试不够完善。
3.变异测试正是基于上述原理的一种测试过程评价技术。该技术的原理就是对原程序产生细微变异,然后通过测试过程进行测试,判断测试过程是否能够感知这种细微的变异。
4.现有的程序变异工具,比如pit、major,都在中间码阶段注入变异。这样的变异无法被开发人员阅读和理解,也无助于缺陷问题的定位。
技术实现要素:
5.本发明所要解决的问题:中间码阶段注入变异无法被开发人员阅读和理解,无助于缺陷问题的定位。
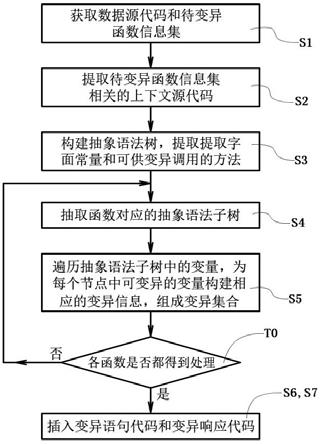
6.为解决上述问题,本发明采用的方案如下:根据本发明的一种源代码层面的程序变异的生成方法,包括如下步骤:s1:获取源代码和变异范围定义信息;所述变异范围定义信息是待变异函数信息的集合;s2:根据所述变异范围定义信息从所述源代码中提取待变异的源代码的上下文;s3:对所述上下文进行词法和语法解析,从而构建所述上下文的抽象语法树;s4:根据所述变异范围定义信息从所述抽象语法树中提取所述待变异函数信息所对应的部分,得到待变异函数的抽象语法树;s5:对所述待变异函数的抽象语法树的节点进行变量遍历,对所遍历的变量,分析其是否具备变异条件;若具备变异条件则构建关于该变量的变异信息,加入至变异集合;所述变异信息包括变异id、变异变量信息、变异位置信息和变异语句;s6:为变异集合中的每个变异信息构建其对应的源代码层面的变异函数;s7:从源代码层面,在所述待变异函数信息所对应函数源代码的最前面插入变异响应代码;所述变异响应代码用于获取变异id,根据所获取的变异id调用变异id对应的变异函数。
7.进一步,根据本发明的源代码层面的程序变异的生成方法,所述步骤s3还包括通过遍历上下文的抽象语法树提取字面常量的步骤;所述步骤s5分析变量是否具备变异条件时,首先判断该变量是否为基本类型的变量,然后再判断该变量是否为变量声明中的变量以及该变量是否可以被赋值;所述步骤s5构建变量的变异信息时,若该变量为基本类型变量,则从所提取的字
面常量中随机选择一个类型与该变量类型一致的常量值,生成将该变量赋值为所选择的常量值作为该变异信息中的变异语句;进一步,根据本发明的源代码层面的程序变异的生成方法,所述源代码为面向对象语言所编写的源代码;所述待变异函数信息中所对应的待变异函数包括对象类的方法;所述步骤s3还包括通过遍历上下文的抽象语法树提取各个对象类的可供变异调用的方法;所述可供变异调用的方法为无返回值、无参数、无异常抛出的方法;所述步骤s5分析变量是否具备变异条件时,首先判断该变量是否为类实例变量,然后在再判断该变量是否为声明中的变量以及该变量是否可以调用所述可供变异调用的方法;所述步骤s5构建变量的变异信息时,若该变量为类实例变量,则从该变量所对应的对象类中随机选取一个可供变异调用的方法,生成该类实例调用所选择的可供变异调用的方法作为该变异信息中的变异语句。
8.根据本发明的一种源代码层面的程序变异的生成装置,包括如下模块:m1,用于:获取源代码和变异范围定义信息;所述变异范围定义信息是待变异函数信息的集合;m2,用于:根据所述变异范围定义信息从所述源代码中提取待变异的源代码的上下文;m3,用于:对所述上下文进行词法和语法解析,从而构建所述上下文的抽象语法树;m4,用于:根据所述变异范围定义信息从所述抽象语法树中提取所述待变异函数信息所对应的部分,得到待变异函数的抽象语法树;m5,用于:对所述待变异函数的抽象语法树的节点进行变量遍历,对所遍历的的变量,分析其是否具备变异条件;若具备变异条件则构建关于该变量的变异信息,加入至变异集合;所述变异信息包括待变异函数信息、变异id、变异变量信息、变异位置信息和变异语句;m6,用于:为变异集合中的每个变异信息构建其对应的源代码层面的变异函数;m7,用于:从源代码层面,在所述待变异函数信息所对应函数源代码的最前面插入变异响应代码;所述变异响应代码用于获取变异id,根据所获取的变异id调用变异id对应的变异函数。
9.进一步,根据本发明的源代码层面的程序变异的生成装置,所述模块m3还包括通过遍历上下文的抽象语法树提取字面常量的模块;所述模块m5分析变量是否具备变异条件时,首先判断该变量是否为基本类型的变量,然后再判断该变量是否为变量声明中的变量以及该变量是否可以被赋值;所述模块m5构建变量的变异信息时,若该变量为基本类型变量,则从所提取的字面常量中随机选择一个类型与该变量类型一致的常量值,生成将该变量赋值为所选择的常量值作为该变异信息中的变异语句;进一步,根据本发明的源代码层面的程序变异的生成装置,所述源代码为面向对象语言所编写的源代码;所述待变异函数信息中所对应的待变异函数包括对象类的方法;所述模块m3还包括通过遍历上下文的抽象语法树提取各个对象类的可供变异调用的方法;
所述可供变异调用的方法为无返回值、无参数、无异常抛出的方法;所述模块m5分析变量是否具备变异条件时,首先判断该变量是否为类实例变量,然后在再判断该变量是否为声明中的变量以及该变量是否可以调用所述可供变异调用的方法;所述模块m5构建变量的变异信息时,若该变量为类实例变量,则从该变量所对应的对象类中随机选取一个可供变异调用的方法,生成该类实例调用所选择的可供变异调用的方法作为该变异信息中的变异语句。
10.本发明的技术效果如下:1、实现了源代码层面的程序变异。
11.2、在变异测试时,可通过外部配置决定调用哪个变异函数,从而便于开发人员定位。
12.3、本发明的方法不限于某种具体编程语言所编写的源代码。
附图说明
13.图1是本发明实施例的流程图。
14.图2是本发明实施例所实现的程序变异插桩代码示例。
具体实施方式
15.下面结合附图对本发明做进一步详细说明。
16.如图1所示,本发明的一种源代码层面的程序变异的生成方法包括如下步骤:数据获取步骤、初始化步骤、变异信息集构建步骤和代码插桩注入步骤。
17.其中,数据获取步骤即为前述的步骤s1,获取源代码和变异范围定义信息。变异范围定义信息用于定义准备在源代码中哪些地方发生变异,本实施例中,采用待变异函数信息描述。具体来说,变异范围定义信息是待变异函数信息的集合。每个待变异函数信息对应于一个待变异的函数,通常包括模块名、函数名等信息,在某些情况下,待变异函数信息还包括文件名。当然若源代码是面向对象语言所编写的源代码,待变异函数也可能是某个对象类的方法,此时,待变异函数信息包括对象类和方法名,用以表示待变异的对象类中的指定的方法。也就是说,根据本发明的方法,所输入的源代码采用何种语言所编写不限。此外,本实施例中,变异范围定义信息采用xml格式的配置文件定义。也就是变异范围定义信息以配置文件的方式输入。但本领域技术人员理解,数据获取步骤表示源代码和变异范围定义信息作为本发明的输入,至于如何输入无需赘述,也不应成为限定。
18.初始化步骤的第一个任务是通过对源代码的词法和语法解析,构建抽象语法树。本领域技术人员理解,现代软件工程中,软件源代码规模往往非常庞大。而变异范围定义信息所涉及的源代码通常是整个源代码中的一小部分。为此,本实施例将初始化步骤分成了两个步骤,也就是前述的步骤s2和步骤s3。步骤s2中,根据变异范围定义信息从源代码中提取待变异的源代码的上下文。步骤s3中,对上下文进行词法和语法解析,从而构建上下文的抽象语法树。通过步骤s2和步骤s3的分解,使得所构建的抽象语法树是仅仅是所输入源代码的一小部分,由此减少计算量并减少内存资源的占用。抽象语法树为本领域技术人员所熟悉,本说明书不再赘述。
19.初始化步骤的第二个任务是通过遍历所构建的抽象语法树提取其中的字面常量。这里所构建的抽象语法树,也就是前述的上下文抽象语法树。提取字面常量时通常与源代码所编程的语言相关,比如在c 中,字面常量通常是指关键词const和#define所限定的常量。但在一些脚本语言中,可能缺少这样的关键词,此时,可以将抽象语法树节点上的数值和字符串提取出来作为字面常量。当然,在比如c 的编程语言中,虽然有关键词限定的字面常量,本领域技术人员理解,也可以将抽象语法树节点上的数值和字符串提取出来作为字面常量。抽取字面常量后得到字面常量的集合。
20.对于面向对象语言所编写的源代码,初始化步骤还有第三个任务,也就是,通过遍历上下文的抽象语法树提取各个对象类的可供变异调用的方法。可供变异调用的方法为无返回值、无参数、无异常抛出的方法。每个对象类提取可供变异调用的方法组成该对象类的可供变异调用的方法集合,进而组成对象类可供变异调用的方法集合的集合。
21.变异信息集构建步骤是一个对变异范围定义信息中的待变异的函数遍历的步骤。图1的步骤t0是一个循环结束条件的判断步骤。其中,“各函数是否都得到处理”中的“函数”是指变异范围定义信息中的待变异的函数,与待变异函数信息对应。对变异范围定义信息中的每个待变异的函数做如下处理:s4:根据变异范围定义信息从抽象语法树中提取待变异函数信息所对应的部分,得到待变异函数的抽象语法树;s5:对待变异函数的抽象语法树的节点进行变量遍历,对所遍历的变量,分析其是否具备变异条件;若具备变异条件则构建关于该变量的变异信息,加入至变异集合。
22.待变异函数的抽象语法树是上下文的抽象语法树的子树。在本实施例的实际处理中,找到待变异函数对应的抽象语法子树根节点即可,因此步骤s4中“提取待变异函数信息所对应的部分”可以理解为找到待变异函数对应的抽象语法子树根节点。步骤s5中“对待变异函数的抽象语法树的节点进行变量遍历”也就是对抽象语法子树根节点下的各子节点进行遍历。若所遍历到的节点为变量,则分析该变量是否具备变异条件;若具备变异条件则构建关于该变量的变异信息,加入至变异集合。变异信息包括变异id、变异变量信息、变异位置信息和变异语句。其中,变异id可以简单为序号,也可以结合序号和所变异的变量名所组成的字符串。比如变异id为“a_2”表示变量a第二个序号上的变异。变异语句是待插入待变异函数体内的程序代码,变异位置信息是变异语句插入至待变异函数体内的位置。变异变量信息用以指代待变异的变量,通常以变量名表示。
23.判断变量是否具体变异条件以及构建变量的变异信息,本领域技术人员理解,均与源代码所编写的编程语言相关。一般的高级编程语言的变量都分成基本类型的变量、结构体的变量、数组变量等概念。基本类型的变量主要包括整型数、浮点数、布尔量、字符串等类型的变量。而面向对象的编程语言中,除了上述类型的变量还包括对象类的类实例变量。尤其在一些高级编程语言中,比如在java语言中,对象类的类实例变量实质是对象类的引用。比如,java语言的代码:string s =
ꢀ“
hello world!”,其中所定义的string类型的类实例变量s是一个对sring类型对象的引用,该语句实质上等价于:string s = new string(“hello world!”);另一方面,java语言中实质不存在字符串类型的变量,都是string类型对象的引用。另一方面,java语言的string类型对象的引用也可以作为基本类型的变量。因为字符串类型的字面常量可以直接赋值给string类型对象的引用。
24.虽然不同编程语言所编写的源代码在对判断变量是否具体变异条件以及构建变量的变异信息有所差异,但以下两个条件是一致的:第一条:对于任何变量,不可能在其定义前进行操作。
25.第二条:常量变量,不能进行非常量操作。
26.对于第一条,也就是,变量在定义时,不具备变异条件,这是显而易见地。
27.对于第二条,也就是,常量变量不具备变异条件。这种情形主要考虑到某些编程语言中的const限定。比如c 语言中定义的语句:const double pi=3.1415926;其中定义的double类型的浮点数变量pi被const关键词所限定,因此该变量在任何时候都不能进行变异,而不具备变异条件,若强行进行变异赋值,变异代码将出现编译错误。
28.再比如c 语句中:int classtest:methoda() const{
…
}其中,classtest类的方法methoda被const所限定,因此其中只要涉及classtest类成员的变量都是不可能进行变异的,而不具备变异条件;若强行进行变异赋值,变异代码将出现编译错误。
29.本实施例中,变异语句分成两类:第一类是对变量进行赋值的语句,所赋的变量值来自于前述步骤s3所提取的字面常量。具体来说,也就是,若遍历到的变量是基本类型的可直接赋值的变量,包括java语言中的string类型变量,从所提取的字面常量中随机选择一个类型与该变量类型一致的常量值,生成将该变量赋值为所选择的常量值作为该变异信息中的变异语句。
30.第二类是对变量进行方法调用的语句,所调用的方法来自于前述s3所提取的对象类的可供变异调用的方法。具体来说,若遍历到的变量一个对象类的类实例变量,则从该变量所对应的对象类中随机选取一个可供变异调用的方法,生成该类实例调用所选择的可供变异调用的方法作为该变异信息中的变异语句。
31.此外,对于java语言中的string类的对象类实例变量,也可以调用其string类中可供变异调用的方法作为该变异信息中的变异语句。也就是说,对于java语言中的string类的对象类实例变量,可以同时作为字面常量赋值的基本类变量,也可以作为对象类的类实例变量。
32.变异信息集构建步骤最终的输出是变异信息集,也就是前述的变异集合,或者变异信息的集合。所输出的每个变异信息集对应于一个待变异函数和待变异函数信息。此时,源代码还是保持原有状态。代码插桩注入步骤各个待变异函数所对应的变异信息集中各变异信息的变异语句在源代码层面以插桩方式注入至源代码形成变异测试源代码,具体包括如下步骤:s6:为变异集合中的每个变异信息构建其对应的源代码层面的变异函数;s7:从源代码层面,在所述待变异函数信息所对应函数源代码的最前面插入变异
响应代码;所述变异响应代码用于获取变异id,根据所获取的变异id调用变异id对应的变异函数。
33.以图2中的代码为例。图2原始的源代码所定义的classtest的methoda方法如下:int classtest::methoda(const int a,const int b) const{
ꢀꢀꢀꢀ
int a,b;
ꢀꢀꢀꢀ
a = a*a*a;
ꢀꢀꢀꢀ
b = b*b*m_p;
ꢀꢀꢀꢀ
return (a
‑
b);}其中,变量a和b被const关键词所限定,因此不可以变异。classtest的成员m_p被方法mehotha的关键词const所限定,因此不可以变异。故此,方法methoda可以被变异的变量为a和b。其中变量a有两个可变异之处:第一个是语句“a=a*a*a;”之前;第二个是语句“return (a
‑
b);”之前。变量b有两个可变异之处:第一个是局域“b = b*b*m_p;”之前;第二个是语句“return (a
‑
b);”之前。由此体现在变异信息集构建步骤输出的变异信息集中包括了四个变异信息。四个变异信息通过步骤s6可以分别构建四个变异函数:int classtest::methoda_a_1(const int a,const int b) const;int classtest::methoda_a_2(const int a,const int b) const;int classtest::methoda_b_1(const int a,const int b) const;int classtest::methoda_b_2(const int a,const int b) const。
34.上述四个函数中a_1,a_2,b_1,b_2为变异id,分别表示变量a的两个可变异之处的变异和变量b的两个可变异之处的变异,变异函数的形式形如:int classtest::methoda_a_1 (const int a,const int b) const{
ꢀꢀꢀꢀ
int a,b;
ꢀꢀꢀꢀ
a = 32;
ꢀꢀꢀꢀ
a = a*a*a;
ꢀꢀꢀꢀ
b = b*b*m_p;
ꢀꢀꢀꢀ
return (a
‑
b);}其中,语句“a = 32;”为插入源代码的变异语句。其中32为来自步骤s3所提取的字面常量。
35.然后通过步骤s7对待变异函数插入变异响应代码,如图2所示,图2中的变异响应代码定义为:
ꢀꢀ
string idvariation = getmethodvariationidfromtestconfig("classtest_methoda");
ꢀꢀ
if (idvariation=="a_1")
ꢀꢀ
{
ꢀꢀꢀꢀꢀꢀ
int retvalue = methoda_a_1(a,b);
ꢀꢀꢀꢀꢀꢀ
return retvalue;
ꢀꢀ
} else if (idvariation=="a_2")
ꢀꢀ
{
ꢀꢀꢀꢀꢀꢀ
int retvalue = methoda_a_2(a,b);
ꢀꢀꢀꢀꢀꢀ
return retvalue;
ꢀꢀ
} else if (idvariation=="b_1")
ꢀꢀ
{
ꢀꢀꢀꢀꢀꢀ
int retvalue = methoda_b_1(a,b);
ꢀꢀꢀꢀꢀꢀ
return retvalue;
ꢀꢀ
} else if (idvariation=="b_2")
ꢀꢀ
{
ꢀꢀꢀꢀꢀꢀ
int retvalue = methoda_b_2(a,b);
ꢀꢀꢀꢀꢀꢀ
return retvalue;
ꢀꢀ
}其中,函数getmethodvariationidfromtestconfig用于获取变异id,然后通过所获取的变异id,也就是idvariation的值决定调用哪一个变异函数,调用后直接返回。若函数getmethodvariationidfromtestconfig提取不到变异id,则调用原函数体。函数getmethodvariationidfromtestconfig的调用可能是通过ui界面获取用户输入的变异id,也可能是通过读取测试配置文件获取变异id。具体情况需要实际软件测试环境而定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。