1.本发明涉及机器人控制领域,尤其涉及一种头部姿态识别方法及终端。
背景技术:
2.头部姿态识别是对采集的图片数据,通过人脸检测、人脸关键点检测、姿态估计等技术计算出头部在现实空间中的方位角度,进而实现对头部姿态的识别。头部姿态识别技术具有很高的应用价值,可用于行为分析,人机交互领域等。但是,现有的头部姿态识别在连续计算方位角度时缺乏稳定性、准确性,不利于头部姿态识别技术在日常生活中的应用。
3.目前的主要解决方法有如下两种:一种是将姿态识别功能内置于机器人本体系统中,机器人识别到眼前人物的姿态后执行预设的动作指令;另一种将姿态识别放在远程服务器中,将视频或图片传输至远程服务器进行分析后再进行使用。
4.第一种方法存在如下缺陷:
5.(1)姿态识别算法需要大量的算力,机器人系统通常是单机系统,而机器人系统本身由于是可移动型的,则会由电池进行供电。考虑到功耗问题,通常不会选用高算力的主芯片,相关算法对算力的要求将较大地影响机器人的运行性能;
6.(2)机器人只能执行预设动作,缺乏灵活性;
7.(3)无法远程识别操控者的姿态,只能在机器人前进行1:1的跟随控制。
8.第二种方法存在如下缺陷:
9.(1)需要进行图片传输,传输数据量较大,占用大量的传输带宽,可能造成一定的延时,对网络环境要求较高;
10.(2)如果要保证图片传输带宽,则通常需要在局域网内部署边缘服务器,较为繁琐,对用户使用带来不便;
11.(3)算力集中在远端服务器,支持的控制端较多时,服务器的负载压力较大,需承担大量的算力请求。
12.因此,目前并不能很好地解决头部姿态识别过程中存在的稳定性和准确性问题。
技术实现要素:
13.本发明所要解决的技术问题是:提供一种头部姿态识别方法及终端,提高头部姿态识别的准确性和稳定性。
14.为了解决上述技术问题,本发明采用的一种技术方案为:
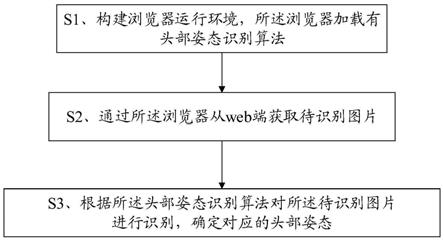
15.一种头部姿态识别方法,包括步骤:
16.s1、构建浏览器运行环境,所述浏览器加载有头部姿态识别算法;
17.s2、通过所述浏览器从web端获取待识别图片;
18.s3、根据所述头部姿态识别算法对所述待识别图片进行识别,确定对应的头部姿态。
19.为了解决上述技术问题,本发明采用的另一种技术方案为:
20.一种头部姿态识别终端,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述头部姿态识别方法中的各个步骤。
21.本发明的有益效果在于:将头部姿态识别算法加载到浏览器中,通过在浏览器中对头部姿态进行识别,降低了对集中化的算力要求压力,由于浏览器运行在各个客户pc前端,因此能够将算力分散到各个客户pc前端,通过浏览器分担了姿态识别所需的算力,从而提升了机器人的运行性能,提高了头部姿态识别的准确性和稳定性。
附图说明
22.图1为本发明实施例的一种头部姿态识别方法的步骤流程图;
23.图2为本发明实施例的一种头部姿态识别终端的结构示意图;
24.图3为本发明实施例的一种头部姿态识别方法中识别出的人脸关键点的示意图;
25.图4为本发明实施例的一种头部姿态识别方法中各前端系统与受控系统之间的对应关系图。
具体实施方式
26.为详细说明本发明的技术内容、所实现目的及效果,以下结合实施方式并配合附图予以说明。
27.请参照图1,一种头部姿态识别方法,包括步骤:
28.s1、构建浏览器运行环境,所述浏览器加载有头部姿态识别算法;
29.s2、通过所述浏览器从web端获取待识别图片;
30.s3、根据所述头部姿态识别算法对所述待识别图片进行识别,确定对应的头部姿态。
31.从上述描述可知,本发明的有益效果在于:将头部姿态识别算法加载到浏览器中,通过在浏览器中对头部姿态进行识别,降低了对集中化的算力要求压力,由于浏览器运行在各个客户pc前端,因此能够将算力分散到各个客户pc前端,通过浏览器分担了姿态识别所需的算力,从而提升了机器人的运行性能,提高了头部姿态识别的准确性和稳定性。
32.进一步地,所述s1包括:
33.接收浏览器访问的站点,判断所述浏览器访问的站点是否为首次访问,若是,则加载头部姿态识别需要的插件。
34.由上述描述可知,当浏览器访问相应的站点时,判断是否为首次访问,仅当首次访问时,才进行头部姿态识别算法的加载,避免了头部姿态识别算法的重复加载,降低不必要的操作及功耗。
35.进一步地,所述插件包括opencv.js插件;
36.所述加载头部姿态识别需要的插件包括:
37.将头部姿态识别中需要进行的滤波操作对应的opencv api添加到所述opencv.js插件的白名单中,并重新编译所述滤波操作对应的opencv函数。
38.由上述描述可知,通过将将滤波操作相关的应用程序添加到opencv.js插件的白名单中,并进行编译,能够生成包含相应滤波器版本的opencv.js,通过滤波器的引入能够
能够对头部姿态识别过程中的数据进行平滑处理,将识别异常的数据进行矫正,进一步提高头部姿态识别的稳定性和准确性。
39.进一步地,所述头部姿态识别算法包括人脸检测模型、关键点检测模型、眼睛睁闭检测模型以及pnp算法;
40.所述s3包括:
41.根据所述人脸检测模型从所述待识别图片中检测出人脸;
42.根据所述关键点检测模型从所述人脸中检测出关键点;
43.从所述关键点中确定出眼睛关键点;
44.根据所述眼睛睁闭模型和所述眼睛关键点确定所述眼睛的睁闭状态;
45.根据所述pnp算法和所述睁闭状态确定出所述人脸的姿态角度;
46.根据所述姿态角度确定对应的头部姿态。
47.由上述描述可知,通过头部姿态识别算法中的人脸检测模型、关键点检测模型、眼睛睁闭检测模型以及pnp算法的配合,能够实现对头部姿态准确可靠的识别。
48.进一步地,所述根据所述人脸检测模型从所述待识别图片中检测出人脸包括:
49.根据所述待识别图片生成正方形的第二图片,所述第二图片的边长等于所述待识别图片的最大边长,并设置所述第二图片每个像素点的颜色值为预设颜色值;
50.将所述待识别的图片绘制到所述第二图片居中的位置;
51.将绘制后的所述第二图片缩放成第一预设大小的第三图片;
52.将所述第三图片的每一个像素点输入至所述人脸检测模型,得到预设个数矩形以及每个矩形对应的置信度;
53.将置信度最大的矩形确定为人脸。
54.由上述描述可知,在将待识别的图片输入人脸检测模型进行人脸检测之前,先进行一系列的预处理,然后将预处理后的图片输入至人脸检测模型,得到多个矩形以及每个矩形的置信度,将置信度最高的矩形确定为人脸,保证了所确定出的人脸的准确性。
55.进一步地,所述根据所述关键点检测模型从所述人脸中检测出关键点包括:
56.根据检测出的人脸从所述待识别的图片中裁剪出第四图片;
57.根据所述第四图片生成正方形的第五图片,所述第五图片的边长等于所述第四图片的最大边长,并设置所述第五图片每个像素点的颜色值为预设颜色值;
58.将所述第四图片绘制到所述第五图片居中的位置;
59.将所述第五图片缩放成第二预设大小的第六图片;
60.将所述第六图片的每一个像素输入到所述关键点检测模型,确定出所述人脸中的关键点。
61.由上述描述可知,在识别出人脸后,先对识别出的人脸图片进行预处理,然后再将其每一个像素点输入关键点检测模型,能够保证准确地对人脸关键点进行识别。
62.进一步地,所述s3之后还包括:
63.s4、根据所述头部姿态确定对应的动作,将所述动作通过控制指令发送给机器人进行对应的动作执行。
64.由上述描述可知,在识别出头部姿态后,根据头部姿态确定对应地动作,并通过控制指令的方式发送给机器人,降低了数据传输量,有利于实时控制机器人,使得机器人能够
跟随着指令进行即开即用。
65.进一步地,所述将所述动作通过控制指令发送给机器人进行对应的动作执行包括:
66.将所述动作对应的控制指令分解为多个子动作指令;
67.将各个子动作指令分别放入对应的子动作指令缓冲队列;
68.控制各个子动作对应的动作执行器从对应的子动作指令缓冲队列提取对应的子动作指令;
69.通过与各个子动作指令对应的动作执行器根据各自提取的所述子动作指令确定对应的执行动作;
70.通过各个动作执行器根据各自对应的执行动作控制所述机器人对应的执行单元执行对应的动作。
71.由上述描述可知,通过对动作进行分解,分解成多个子动作,每个子动作通过指令的方式存储到对应的指令缓冲队列,然后通过对应的动作执行器提取对应的子动作指令并控制机器人对应的执行单元执行对应的动作,通过对动作进行分解、并行传输并通过对应的执行单元并行执行,一方面降低了传输的数据量,另一方面提高了动作执行的速度,从而达到提高了动作执行的实时性。
72.进一步地,所述通过与各个子动作指令对应的动作执行器根据各自提取的所述子动作指令确定对应的执行动作之前包括步骤:
73.为每个子动作指令缓冲队列设置对应的滑动窗口值;
74.根据所述滑动窗口值采用滑窗均值法对提取的对应的子动作指令进行平滑化处理,并将处理后的子动作指令连续性地发送至运动执行队列;
75.所述通过与各个子动作指令对应的动作执行器根据各自提取的所述子动作指令确定对应的执行动作包括:
76.通过与各个子动作指令对应的动作执行器以预设间隔从对应的运动执行队列中提取子动作指令,根据所提起的自动作指令确定对应的执行动作。
77.由上述描述可知,通过为每个子动作指令缓冲队列设置对应的滑动窗口值,并通过滑动窗口值对子动作进行平滑处理后再进行提取、执行,保证了机器人执行动作时的顺畅度。
78.请参照图2,一种头部姿态识别终端,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述头部姿态识别方法中的各个步骤。
79.本发明上述头部姿态识别方法及终端能够适用于需要进行头部姿态识别的应用场景中,比如与机器人的人脸跟随交互、行为分析等,以下通过具体实施方式进行说明:
80.实施例一
81.请参照图1,一种头部姿态识别方法,包括步骤:
82.s1、构建浏览器运行环境,所述浏览器加载有头部姿态识别算法;
83.具体的,接收浏览器访问的站点,判断所述浏览器访问的站点是否为首次访问,若是,则加载头部姿态识别需要的插件,若否,则不需要进行头部姿态识别所需的插件的加载;
84.其中,所述插件包括opencv.js插件、tensorflow.js插件;
85.所述加载头部姿态识别需要的插件包括:
86.将头部姿态识别中需要进行的滤波操作对应的opencv api添加到所述opencv.js插件的白名单中,并重新编译所述滤波操作对应的opencv函数;
87.其中,滤波可以是卡尔曼滤波器,opencv官方提供了可供浏览器使用的js版本的opencv.js,该版本是opencv函数的子集,不包含本算法中需要使用的“卡尔曼滤波”的相关功能,无法使用,因此,需要将“卡尔曼滤波”相关的opencv api添加到opencv.js的白名单中,并使用emscripten重新编译“卡尔曼滤波”相关的c 代码中相关的opencv函数,将该函数编译为webassembly的目标,从而生成带“卡尔曼滤波”版本的opencv.js。
88.s2、通过所述浏览器从web端获取待识别图片;
89.浏览器获取其所在的客户端的摄像头拍摄的待识别图片,使用canvas将摄像头拍摄得到的图像帧数据进行渲染展示;
90.s3、根据所述头部姿态识别算法对所述待识别图片进行识别,确定对应的头部姿态。
91.实施例二
92.本实施例进一步限定了如何进行头部姿态的识别,具体的:
93.所述头部姿态识别算法包括人脸检测模型、关键点检测模型、眼睛睁闭检测模型以及pnp算法;
94.所述s3包括:
95.根据所述人脸检测模型从所述待识别图片中检测出人脸;
96.根据所述关键点检测模型从所述人脸中检测出关键点;
97.从所述关键点中确定出眼睛关键点;
98.根据所述眼睛睁闭模型和所述眼睛关键点确定所述眼睛的睁闭状态;
99.根据所述pnp算法和所述睁闭状态确定出所述人脸的姿态角度;
100.根据所述姿态角度确定对应的头部姿态;
101.其中,所述根据所述人脸检测模型从所述待识别图片中检测出人脸包括:
102.根据所述待识别图片生成正方形的第二图片,所述第二图片的边长等于所述待识别图片的最大边长,并设置所述第二图片每个像素点的颜色值为预设颜色值;
103.将所述待识别的图片绘制到所述第二图片居中的位置;
104.将绘制后的所述第二图片缩放成第一预设大小的第三图片;
105.将所述第三图片的每一个像素点输入至所述人脸检测模型,得到预设个数矩形以及每个矩形对应的置信度;
106.将置信度最大的矩形确定为人脸;
107.所述根据所述关键点检测模型从所述人脸中检测出关键点包括:
108.根据检测出的人脸从所述待识别的图片中裁剪出第四图片;
109.根据所述第四图片生成正方形的第五图片,所述第五图片的边长等于所述第四图片的最大边长,并设置所述第五图片每个像素点的颜色值为预设颜色值;
110.将所述第四图片绘制到所述第五图片居中的位置;
111.将所述第五图片缩放成第二预设大小的第六图片;
112.将所述第六图片的每一个像素输入到所述关键点检测模型,确定出所述人脸中的关键点;
113.在一个具体的实施方式中,在人脸检测时,包括如下步骤:
114.根据输入的待识别图片p1,生成一张正方形的图片p2,其边长等于p1最大边长,每个像素点的颜色值为rgb(127,127,127);
115.将图片p1绘制到图片p2中,位置居中;
116.将图片p2缩放成320*320大小的图片p3;
117.将图片p3的每个像素的r、g、b分量依次放到一维数组a1中;
118.使用tensorflow的人脸检测模型t1,将数组a1作为输入,计算得到4200个矩形以及每个矩形对应的置信度,将置信度最高的矩形r1确定为人脸所在的区域;
119.根据r1,从图片p1中裁剪出人脸图片p4;
120.在确定出人脸图片后,执行人脸关键点检测,其步骤如下:
121.根据图片p4,生成一张正方形的图片p5,其边长等于p4的最大边长,每个像素点的颜色值为rgb(127,127,127);
122.将图片p4绘制到图片p5中,位置居中;
123.将图片p5缩放成160*160大小的图片p6;
124.将图片p6的每个像素的r、g、b分量依次放到一维数组a2中;
125.使用tensorflow的人脸关键点检测模型t2,将数组a2作为输入,计算得到68个人脸关键点的横纵坐标数组landmarks,这68个关键点的位置和编号如图3所示;
126.在确定出人脸关键点之后,从确定出的人脸关键点识别出左眼和右眼,分别根据左眼和右眼的关键点确定出左眼和右眼各自对应的最小外包矩形;然后根据左、右眼对应的最小外包矩形从待识别图片中裁剪出右眼图片和左眼图片;接着将左右眼图片分别转换成左灰度图和右灰度图;将左右灰度图进行预设尺寸的缩放后将各自的像素点分别输入眼睛睁闭模型,从而确定出左右眼的睁闭状态;
127.在一个可选的实施方式中,如图3所示,分别得到左眼的6个关键点和右眼的6个关键点,接着执行人眼状态检测,步骤如下:
128.根据左眼的6个关键点,编号分别为:37、38、39、40、41、42,计算出最小外包矩形r2;
129.根据右眼的6个关键点,编号分别为:43、44、45、46、47、48,计算出最小外包矩形r3;
130.根据r2、r3,从图片p1中裁剪出左眼图片p7、右眼图片p8;
131.将左眼图片p7转换成灰度图p9,将右眼图片p8转换成灰度图p10;
132.将左眼灰度图p9缩放成12*8大小的图片p11,将右眼灰度图p10缩放成12*8大小的图片p12;
133.将图片p11、p12每个像素点的r、g、b分量分别放到一维数组a3、a4中;
134.使用tensorflow的眼睛睁闭检测模型t3,数组a3、a4作为输入,得到左右眼的睁闭结果标识openflags;
135.在进行姿态识别时,设置三维人物头像模型点数组为objectpoints、相机的内参矩阵cameramatrix、相机的畸变系数distcoeffs;
136.使用pnp算法,objectpoints、landmarks、cameramatrix、distcoeffs作为输入得到旋转向量rv,rv是一维度数组;
137.使用卡尔曼滤波算法对旋转向量rv进行平滑处理;
138.根据旋转向量rv计算出翻滚角roll,计算公式为:
139.roll=
‑
1*(180 rv[2]*180/3.1415926))
[0140]
根据旋转向量rv计算出俯仰角pitch,计算公式为:
[0141]
pitch=
‑
1*rv[1]*180/3.1415926
[0142]
根据旋转向量rv计算出偏航角yaw,计算公式为:
[0143]
yaw=
‑
1*rv[0]*180/3.1415926
[0144]
根据openflags、roll、pitch、yaw计算出姿态角度:
[0145]
头部左右转动角度=-1*yaw
[0146]
头部上下转动角度=pitch
[0147]
头部倾斜角度=90
‑
roll
[0148]
左眼张开角度=openflags[0]*70
[0149]
右眼张开角度=openflags[1]*70
[0150]
在识别出姿态后,采用矢量叠加的方式,将三维人物头像姿态识别结果叠加在原摄像头图像帧数据canvas上进行渲染展示。
[0151]
实施例三
[0152]
本实施例进一步限定了在识别出头部姿态后,如何控制机器人执行对应的动作,具体的:
[0153]
所述s3之后还包括:
[0154]
s4、根据所述头部姿态确定对应的动作,将所述动作通过控制指令发送给机器人进行对应的动作执行;
[0155]
其中,所述将所述动作通过控制指令发送给机器人进行对应的动作执行包括:
[0156]
将所述动作对应的控制指令分解为多个子动作指令;
[0157]
将各个子动作指令分别放入对应的子动作指令缓冲队列;
[0158]
控制各个子动作对应的动作执行器从对应的子动作指令缓冲队列提取对应的子动作指令;
[0159]
通过与各个子动作指令对应的动作执行器根据各自提取的所述子动作指令确定对应的执行动作;
[0160]
通过各个动作执行器根据各自对应的执行动作控制所述机器人对应的执行单元执行对应的动作;
[0161]
在一个可选的实施方式中,所述通过与各个子动作指令对应的动作执行器根据各自提取的所述子动作指令确定对应的执行动作之前包括步骤:
[0162]
为每个子动作指令缓冲队列设置对应的滑动窗口值;
[0163]
根据所述滑动窗口值采用滑窗均值法对提取的对应的子动作指令进行平滑化处理,并将处理后的子动作指令连续性地发送至运动执行队列;
[0164]
所述通过与各个子动作指令对应的动作执行器根据各自提取的所述子动作指令确定对应的执行动作包括:
[0165]
通过与各个子动作指令对应的动作执行器以预设间隔从对应的运动执行队列中提取子动作指令,根据所提起的自动作指令确定对应的执行动作;
[0166]
如图4所示,为通过前端系统的浏览器进行姿态识别,并根据姿态识别确定出的动作通过指令发送给对应的受控系统(比如机器人)执行对应的动作的结构示意图,前端系统与受控系统一一对应;
[0167]
在进行动作分解时,在一个可选的实施方式中,可以将机器人头部运动分为颈部、眼球、眼皮、嘴部和眉毛五个执行单元,相应地,将动作分解为上述五个执行单元对应的执行动作;
[0168]
具体实现时,为各个执行单元设置不同的滑动窗口值;
[0169]
机器人从上位机接收控制指令包,由动作执行分类器拆包后得到各个执行单元需要执行的动作对应的控制指令;
[0170]
动作执行分类器将各个位置的控制指令送入对应位置执行器的动作指令缓冲队列;
[0171]
各个动作执行预处理器将对应动作指令缓冲队列中的数据根据设置的滑动窗口值,采用滑窗均值算法使运动控制平滑化,并连续性地将处理后的控制指令送至运动执行队列;
[0172]
动作执行器按照固定间隔不断从运动执行队列中取任务执行;
[0173]
动作执行器根据控制指令计算出机器人舵机实际运动角度;
[0174]
根据机器人各个位置的舵机执行最大角度anglemax、舵机执行最小角度anglemin、舵机转动方向direction、舵机初始角度angledef、控制指令角度angle,计算出机器人舵机实际转动角度:
[0175]
颈部实际转动角度=direction*angle angledef;
[0176]
眼球实际转动角度=direction*angle angledef;
[0177]
眼皮实际转动角度=direction*angle (anglemax
‑
anglemin);
[0178]
嘴巴实际转动角度=direction*angle (anglemax
‑
anglemin);
[0179]
眉毛实际转动角度=(angle>90)?anglemax:anglemin;
[0180]
并通过速度和加速度的时序加以控制。
[0181]
实施例四
[0182]
请参照图2,一种头部姿态识别终端,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现实施例一至实施例三中任一个所述的一种头部姿态识别方法中的各个步骤。
[0183]
综上所述,本发明提供的一种头部姿态识别方法及终端,将头部姿态识别算法加载到浏览器中,通过在浏览器中对头部姿态进行识别,降低了对集中化的算力要求压力,由于浏览器运行在各个客户pc前端,因此能够将算力分散到各个客户pc前端,通过浏览器分担了姿态识别所需的算力,从而提升了机器人的运行性能,提高了头部姿态识别的准确性和稳定性;基于浏览器实现,部署简单,使用方便,只要有浏览器的地方就可以对机器人进行远程控制;在控制对应的机器人执行动作时,是通过指令的形式进行对应动作的传输,并且根据执行指令的执行单元将指令进一步拆分为对应的多个子指令,存入对应的缓冲队列中,不同类型的子指令对应的缓冲队列设置有对应的滑动窗口,实现了子指令的并行传输、
并行平滑话化处理以及并行执行,大大提高了动作执行的效率以及准确性。
[0184]
以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等同变换,或直接或间接运用在相关的技术领域,均同理包括在本发明的专利保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。