1.本发明涉及图像标注、文本分类、音乐注释和场景识别等多个应用领域,具体涉及一种基于多输出残差编码的多标签分类方法。
背景技术:
2.传统监督学习的目标是学习一个从输入空间映射到输出空间的函数,其中输出是单个标签(用于预测任务)或单个实值(用于回归任务),通常可以用简单的答案来解决问题。例如,采用传统的二进制分类模型来检测电子邮件是否为垃圾邮件。随着日益复杂的需求,单个标签和单输出已经不再满足需求,许多问题中一个实例常常伴随着多个标签。例如,将新闻分为时事类、娱乐类、体育类、财经类、科技类等等。因此迫切需要机器学习模型进行复杂的决策。这种复杂的决策通常可以通过多标签分类来处理。
3.多标签分类是计算机视觉中一个重要的学习问题,其中每个类空间代表一个特定维度中实例的语义。随着大数据技术的广泛应用,多个类之间的交互变得更加复杂。多标签分类为每个实例同时分配多个标签,这在从图像自动标注和文档分类,到音乐情感分析等多个领域都是至关重要的。
4.由于大数据技术的发展,多标签分类面临着因数据维度过高所带来的运算成本高、预测效率低和准确度低等问题。基于标签嵌入的方法可以将原始标签空间投射到低维度的压缩空间中,在保留标签基本信息的同时捕捉到标签之间的关联性。这种方法被称为编码
‑
解码范式。再者,度量学习旨在根据不同的任务自主学习出针对某个特定任务的距离度量函数,当与依赖于距离或相似性的技术结合使用时,已被证明是有效的。度量学习可用于空间映射,目标是基于监督信息来学习数据的变换。最流行的两种监督形式为:相似/相异约束和相对距离约束。其学到的变换矩阵能够用于将数据映射到一个新的嵌入空间。在变换后的空间中,相似样本之间的距离小,不相似样本之间的距离大,从而对数据进行区分。
技术实现要素:
5.本发明针对分类问题中因数据维度过高所带来的运算成本高、预测效率低和准确度低等问题,提出了一种基于多输出残差编码的多标签分类方法,该方法学习对于两个带有不同标签的最近实例的适当距离度量,以获取标签空间中更合理的低秩结构和特征空间和标签空间之间的拟合关系,达到对数据进行映射降维的效果。与传统的多标签分类方法相比较,降低运算成本的同时提高了准确度,具有良好的应用价值。
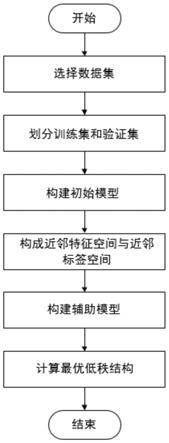
6.为实现上述发明目的,本发明提供以下技术方案:一种基于多输出残差编码的多标签分类方法,包括如下步骤
7.1)选择数据集corel5k为原始数据集,所述数据集corel5k是多标签分类用于图像标注领域的基准数据集;
8.2)将原始数据集corel5k按n∶m比例划分为原始训练集set_tr和验证集set_te;
9.3)构建原始训练集set_tr的初始模型w1;
10.4)根据相似性约束获得原始训练集set_tr中每个实例的多个邻居,构建近邻特征空间近邻标签空间和k对数据集
11.5)构建k对数据集的辅助模型w2;
12.6)利用初始模型w1和辅助模型w2计算原始训练集set_tr的标签空间y上的最优低秩结构v;
13.7)将拟合关系p和最优低秩结构v应用到验证集set_te上,预测set_te的输出标签。
14.进一步的,上述步骤3)构建原始训练集set_tr的初始模型w1包括如下步骤:
15.3.1)计算原始训练集set_tr的特征空间x与标签空间y之间的拟合关系p,计算公式如下:
16.p=(xx
t
)
‑1xy
t
17.式中:x是原始特征空间,y是原始标签空间;
18.3.2)用f范数对特征空间x与标签空间y之间的实例残差进行编码,公式如下:
[0019][0020]
式中:p为原始特征空间x与原始标签空间y之间的拟合关系,y
‑
p
t
x为特征空间x与标签空间y之间的实例残差,||
·
||
f
为f范数;
[0021]
3.3)令编码公式最小化并赋予约束条件,得到初始模型w1,模型如下:
[0022][0023]
其中,所述约束条件如下:
[0024]
s.t.v
t
yy
t
v=i
[0025]
模型中:r
q*d
为q*d的空间,s.t.为约束条件,i是单位矩阵。
[0026]
进一步的,上述步骤4)中构建近邻特征空间近邻标签空间和k对数据集包括如下步骤:
[0027]
4.1)计算原始训练集set_tr中的每一个实例的k个邻居;
[0028]
4.2)由所有实例的第i(i=1,...,k)个邻届构成第i个近邻特征空间其对应的标签向量构成第一个近邻标签空间
[0029]
4.3)根据近邻特征空间和近邻标签空间构建k对数据集
[0030]
进一步的,上述步骤5)构建k对数据集的辅助模型w2包括如下步骤:
[0031]
5.1)计算每一对邻居特征空间与邻居标签空间之间的拟合关系p
i
(i=1,...,k),计算公式如下:
[0032]
[0033]
式中:是邻居特征空间,是邻居标签空间,k为近邻个数;
[0034]
5.2)针对每一对用f范数对近邻特征空间与近邻标签空间之间的实例残差进行编码,公式如下:
[0035][0036]
式中:p
i
(i=1,...,k)为与之间的拟合关系,为特征空间与标签空间之间的实例残差,||
·
||
f
为f范数;
[0037]
5.3)将每一对的编码公式进行累加,公式如下:
[0038][0039]
5.4)令累加公式最小化并赋予约束条件,得到辅助模型w2,模型如下:
[0040][0041]
其中,所述约束条件如下:
[0042][0043]
r
q*d
为q*d的空间,s.t.为约束条件,i是单位矩阵。
[0044]
进一步的,上述步骤6)计算原始训练集set_tr的标签空间y上的最优低秩结构v包括如下步骤:
[0045]
6.1)将初始模型w1和辅助模型w2合并,得到多标签分类模型w,在原始训练集set_tr上进行训练并学习标签空间中的低秩投影v,模型如下:
[0046][0047]
其中,所述约束条件如下:
[0048][0049]
λ是一个常数参数,表示第二项在模型中所占的权重,k为近邻个数,x是原始特征空间,y是原始标签空间,p为x与y之间的拟合关系,是邻居特征空间,是邻居标签空间,p
i
(i=1,...,k)为与之间的拟合关系,r
q*d
为q*d的空间,s.t.为约束条件,i是单位矩阵;
[0050]
6.2)对多标签分类模型w做优化处理,得到优化结果w
‑
[0051][0052]
式中:tr(
·
)表示矩阵的迹线;
[0053]
6.3)通过使用拉格朗日乘数法将优化结果w
‑
划分为d个优化子问题,得出最优低秩结构v中的每一列v
l
(l=1,...,d)应满足以下特征方程式,公式如下:
[0054][0055]
式中:μ
l
(l=1,...,d)是引入的拉格朗日乘数,v
l
(l=1,...,d)是所求的标签空间上的最优低秩结构v中的每一列,共有d列;
[0056]
6.4)计算协方差矩阵a,公式如下:
[0057][0058]
6.5)计算协方差矩阵a的前d个最大特征值得到μ1,...,μ
d
,μ1,...,μ
d
对应的特征向量分别为v1,...,v
d
,(v1,...,v
d
)构成最优低秩结构v。
[0059]
进一步的,上述步骤7)中预测测试集set_te的输出标签包括如下步骤:
[0060]
7.1)计算度量矩阵q;
[0061]
q=vv
t
[0062]
式中:v为最优低秩结构;
[0063]
7.2)计算验证集set_te中的每一个实例的k个邻居;
[0064]
7.3)采用加权最近邻投票的方式来预测验证集set_te中每一个实例的输出标签。
[0065]
进一步的,上述步骤4.1)中计算原始训练集set_tr中的一个实例的k个邻居包括如下步骤:
[0066]
4.1.1)计算实例x
(i)
(i=1,...,n)与原始训练集set_tr中其他所有实例之间的欧氏距离d,公式如下:
[0067][0068]
式中:x
(i)
(i=1,...,n)和x
(j)
(j=1,...,n)都是原始训练集set_tr中的实例;
[0069]
4.1.2)对实例x
(j)
(i=1,...,n)与原始训练集set_tr中其他所有实例之间的欧氏距离d进行由小到大排序;
[0070]
4.1.3)根据排序结果,取前k个最小值,得到x
(i)
(i=1,...,n)的k个邻居,记为
[0071]
进一步的,上述步骤7.2)中计算验证集set_te中的每一个实例的k个邻居包括如下步骤:
[0072]
7.2.1)计算每个实例x
(j)
(j=1,...m)与原始训练集set_tr中其他所有实例之间的马氏距离d,计算公式如下:
[0073][0074]
式中:x
(j)
(j=1,...m)为验证集set_te中的实例,x
(i)
(i=1,...n)为原始训练集set_tr中的实例,q为度量矩阵;
[0075]
7.2.2)对实例x
(j)
(j=1,...m)与原始训练集set_tr中其他所有实例之间的马氏距离d进行由小到大排序;
[0076]
7.2.3)根据排序结果,取前k个最小值,得到每个实例x
(j)
(j=1,...m)在原始特征空间x中的k个邻居。
[0077]
本发明提供一种基于多输出残差编码的多标签分类方法,采用监督学习的机制,通过联合分析实例及其邻居的多个残差以学习到合适的距离度量,从而获得标签空间上的更好的低秩结构和特征空间和标签空间之间的拟合关系。然后,预测验证集中实例的输出标签。本发明有效的解决了分类问题中因数据维度过高所带来的运算成本高、预测效率低和准确度低等问题,可以增强处理高维多标签分类任务的性能,具有较好的应用价值。
附图说明
[0078]
图1为本发明中基于多输出残差编码的多标签分类方法流程图。
具体实施方式
[0079]
下面结合附图以及具体实施例对本发明作进一步的说明,需要指出的是,下面仅以一种优选的技术方案对本发明的技术方案以及设计原理进行详细阐述,但本发明的保护范围并不限于此。
[0080]
所述实施例为本发明的优选的实施方式,但本发明并不限于上述实施方式,在不背离本发明的实质内容的情况下,本领域技术人员能够做出的任何显而易见的改进、替换或变型均属于本发明的保护范围。
[0081]
本发明提供的一种基于多输出残差编码的多标签分类方法流程参见图1,包括如下步骤:
[0082]
1)选择数据集corel5k为原始数据集,所述数据集corel5k是多标签分类用于图像标注领域的基准数据集;
[0083]
2)将原始数据集corel5k按n∶m比例划分为原始训练集set_tr和验证集set_te;在本发明具体实施例中,n=7,m=3;
[0084]
3)构建原始训练集set_tr的初始模型w1;
[0085]
作为本发明的优选实施例,步骤3)包括如下内容:
[0086]
3.1)计算原始训练集set_tr的特征空间x与标签空间y之间的拟合关系p,计算公式如下:
[0087]
p=(xx
t
)
‑1xy
t
[0088]
式中:x是原始特征空间,y是原始标签空间;
[0089]
3.2)用f范数对特征空间x与标签空间y之间的实例残差进行编码,公式如下:
[0090]
[0091]
式中:p为原始特征空间x与原始标签空间y之间的拟合关系,y
‑
p
t
x为特征空间x与标签空间y之间的实例残差,||
·
||
f
为f范数;
[0092]
3.3)令编码公式最小化并赋予约束条件,得到初始模型w1,模型如下:
[0093][0094]
其中约束条件如下:
[0095]
s.t.v
t
yy
t
v=i
[0096]
模型中:r
q*d
为q*d的空间,s.t.为约束条件,i是单位矩阵;
[0097]
4)根据相似性约束获得原始训练集set_tr中实例的多个邻居,构成近邻特征空间与近邻标签空间作为本发明的优选实施例,包括如下步骤:
[0098]
4.1)计算原始训练集set_tr中的每一个实例的k个邻居;其中,作为本发明的优选实施例,计算每一个实例的k个邻居包括如下步骤:
[0099]
4.1.1)计算实例x
(i)
(i=1,...,n)与原始训练集set_tr中其他所有实例之间的欧氏距离d,公式如下:
[0100][0101]
式中:x
(j)
(i=1,...,n)和x
(j)
(j=1,...,n)都是原始训练集set_tr中的实例;
[0102]
4.1.2)对实例x
(i)
(i=1,...,n)与原始训练集set_tr中其他所有实例之间的欧氏距离d进行由小到大排序;
[0103]
4.1.3)根据排序结果,取前k个最小值,得到x
(j)
(i=1,...,n)的k个邻居,记为
[0104]
4.2)由所有实例的第i(i=1,...,k)个邻居构成第i个近邻特征空间其对应的标签向量构成第一个近邻标签空间
[0105]
4.3)构建k对数据集
[0106]
5)构建k对数据集的辅助模型w2;作为本发明的优选实施例,包括如下步骤:
[0107]
5.1)计算每一对邻居特征空间与邻居标签空间之间的拟合关系p
i
(i=1,...,k),公式如下:
[0108][0109]
式中:是邻居特征空间,是邻居标签空间,k为近邻个数;
[0110]
5.2)针对每一对用f范数对近邻特征空间与近邻标签空间之间的实例残差进行编码,公式如下:
[0111][0112]
式中:p
i
(i=1,...,k)为与之间的拟合关系,为特征空间与标签空间之间的实例残差,||
·
||
f
为f范数;
[0113]
5.3)将每一对的编码公式进行累加,公式如下:
[0114][0115]
5.4)令累加公式最小化并赋予约束条件,得到辅助模型w2,模型如下:
[0116][0117]
其中约束条件如下:
[0118][0119]
模型中:r
q*d
为q*d的空间,s.t.为约束条件,i是单位矩阵;
[0120]
6)计算原始训练集set_tr的标签空间y上的最优低秩结构v;作为本发明的优选实施例,包括如下步骤:
[0121]
6.1)将初始模型w1和辅助模型w2合并,得到多标签分类模型w,在原始训练集set_tr上进行训练并学习标签空间中的低秩投影v,模型如下:
[0122][0123]
其中约束条件如下:
[0124][0125]
模型中:λ是一个常数参数,表示第二项在模型中所占的权重,k为近邻个数,x是原始特征空间,y是原始标签空间,p为x与y之间的拟合关系,是邻居特征空间,是邻居标签空间,p
i
(i=1,...,k)为与之间的拟合关系,r
q*d
为q*d的空间,s.t.为约束条件,i是单位矩阵;
[0126]
6.2)对多标签分类模型w做优化处理,得到优化结果w
‑
[0127][0128]
式中:tr(
·
)表示矩阵的迹线;
[0129]
6.3)通过使用拉格朗日乘数法将优化结果w
‑
划分为d个优化子问题,得出最优低秩结构v中的每一列v
l
(l=1,...,d)应满足以下特征方程式,公式如下:
[0130][0131]
式中:μ
l
(l=1,...,d)是引入的拉格朗日乘数,v
l
(l=1,...,d)是所求的标签空间上的最优低秩结构v中的每一列,共有d列;
[0132]
6.4)计算协方差矩阵a,公式如下:
[0133][0134]
6.5)计算协方差矩阵a的前d个最大特征值得到μ1,...,μ
d
,μ1,...,μ
d
对应的特征向量分别为v
1,
...,v
d
,(v1
,
...,v
d
)构成最优低秩结构v;
[0135]
7)将拟合关系p和最优低秩结构v应用到验证集set_te上,预测set
‑
te的输出标签;作为本发明的优选实施例,包括如下步骤:
[0136]
7.1)计算度量矩阵q;
[0137]
q=vv
t
[0138]
式中:v为最优低秩结构;
[0139]
7.2)计算验证集set_te中的每一个实例的k个邻居;作为本发明的优选实施例,计算每一个实例的k个邻居包括如下步骤:
[0140]
7.2.1)计算每个实例x
(j)
(j=1,...m)与原始训练集set_tr中其他所有实例之间的马氏距离d,公式如下:
[0141][0142]
式中:x
(j)
(j=1,...m)为验证集set_te中的实例,x
(i)
(i=1,...n)为原始训练集set_tr中的实例,q为度量矩阵;
[0143]
7.2.2)对实例x
(j)
(j=1,...m)与原始训练集set_tr中其他所有实例之间的马氏距离d进行由小到大排序;
[0144]
7.2.3)根据排序结果,取前k个最小值,得到每个实例x
(j)
(j=1,...m)在原始特征空间x中的k个邻居;
[0145]
7.3)采用加权最近邻投票的方式来预测验证集set_te中每一个实例的输出标签。
[0146]
本发明提供了一种基于多输出残差编码的多标签分类方法,采用监督学习的机制,通过对实例及其邻居的残差嵌入学习到合适的距离度量,从而获得标签空间上的更好的低秩结构以及特征空间和标签空间之间的拟合关系。然后,预测验证集中实例的输出标签。本发明有效的解决了分类问题中因数据维度过高所带来的运算成本高、预测效率低等问题。与传统的多标签分类方法相比较,本发明更好的处理高维多标签分类任务,具有较好的应用价值。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。