和其他用户行为影响w2。
11.本发明的一个实施例中,所述当前用户行为影响w1的计算方式为:
[0012][0013]
其中,代表节点间的第k条最短路径,并且假设两个目标用户节点之间共有t条最短路径,pi
u,v
表示两个目标用户节点间的行为影响传播。
[0014]
本发明的一个实施例中,所述两个目标用户节点间的行为影响传播pi
u,v
用下式计算:
[0015][0016]
其中,代表节点u和节点v之间的第k条路径,表示节点v
i
和节点v
j
之间的关系权重,(v
i
,v
j
)表示节点u和节点v之间所有路径上的节点,包括节点u和节点v,f
i
表示每一个用户节点v
i
的行为影响力。
[0017]
本发明的一个实施例中,用户节点v
i
的行为影响力f
i
用下式计算:
[0018]
f
i
=tr(ia(i))
[0019]
tr(ia(i))表示用户节点v
i
对应的用户历史行为描述文本的特征矩阵ia的迹。
[0020]
本发明的一个实施例中,所述其他用户行为影响w2为:w2=defree(v
i
),使用图论节点的度计算。
[0021]
本发明的一个实施例中,所述步骤s3具体包括:将每个目标用户的历史行为描述文本形成的特征矩阵ia作为bi
‑
lstm网络的输入,训练bi
‑
lstm学习每个目标用户的行为特征,输出已知目标用户、商品的情况下,用户对物品行为的概率值,其中,记前向lstm输出的概率向量为后向lstm输出的概率向量为两个概率向量记录了行为空间三类行为的概率值,即在用户历史行为描述文本中捕捉到的行为种类,将目标用户和其它用户影响力权重加入模型训练中,对于一个目标用户v
i
,得到加权输出概率向量
[0022]
本发明的一个实施例中,所述行为空间的三类行为具体包括:点击,购买,收藏。
[0023]
按照本发明的另一方面,还提供了一种基于多因素加权bi
‑
lstm学习的用户行为预测系统,包括目标用户历史行为特征提取模块、多因素权重学习模块和行为预测模块,其中:
[0024]
所述目标用户历史行为特征提取模块,用于将收集好的目标用户历史行为描述文本先由word2vec转变为向量表示形式,再利用transformer从用户历史行为描述文本中提取目标用户历史行为特征;
[0025]
所述多因素权重学习模块,用于根据所述目标用户历史行为特征,基于注意力机制自适应学习历史行为的多因素权重;
[0026]
所述行为预测模块,用于根据所述多因素权重,利用bi
‑
lstm和集束搜索策略进行行为预测。
[0027]
总体而言,通过本发明所构思的以上技术方案与现有技术相比,具有如下有益效果:
[0028]
(1)通过直接分析用户历史行为描述文本和已知社交网络来学习用户的行为特征,相比通过先从数据中抓取用户行为再进行行为预测的传统方法,数据收集方法更灵活,数据分析方法更多样,具有更好的普适性;
[0029]
(2)根据目标用户历史行为描述文本和社交网络信息对用户之间的行为影响力在发出的影响和受到的影响两个方向进行考量,相比于整体考虑网络中影响力传播的传统方法,更贴近现实生活中用户的社交影响情况;
[0030]
(3)通过训练双向长短时记忆网络来将用户历史行为描述文本和行为预测链接,双向长短时记忆网络能够克服传统记忆网络方法对文本信息利用不充分、丢失文本信息、受无关信息干扰较大等问题,再加入权重因素的调节,能够提高行为预测的准确性。
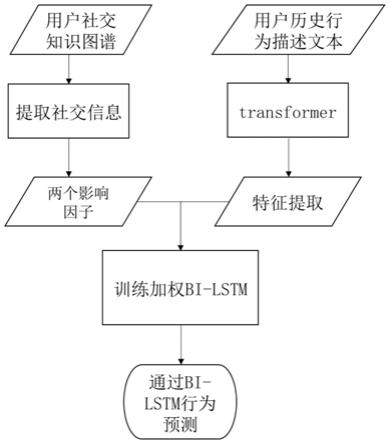
附图说明
[0031]
图1是本发明实施例中一种基于多因素bi
‑
lstm学习的行为预测方法的流程示意图。
具体实施方式
[0032]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
[0033]
如图1所示,本发明提供了一种基于多因素bi
‑
lstm学习的行为预测方法,包括以下步骤:
[0034]
步骤s1:将收集好的目标用户历史行为描述文本先由word2vec转变为向量表示形式,再利用transformer从用户历史行为描述文本中提取目标用户历史行为特征;
[0035]
具体地,所述步骤s1包括:
[0036]
首先基于收集到的目标用户历史行为描述文本,将目标用户历史行为描述文本首先进行分词,然后再将每个词通过词向量模型word2vec转变为向量表示形式,构建初始化文本向量矩阵其中每一个表示句子中一个词的嵌入向量。将向量矩阵in输入transformer翻译模型,不断进行自注意力机制self
‑
attention学习后得到目标用户历史行为描述文本的特征矩阵ia,矩阵ia的每一行为一个词的特征向量。
[0037]
步骤s2:根据所述目标用户历史行为特征,基于注意力机制自适应学习历史行为的多因素权重;
[0038]
具体地,所述步骤s2中要计算当前用户行为影响w1、其他用户行为影响w2。计算方式如下:
[0039]
步骤s21:基于最短最大传播策略的当前用户行为影响w1计算。w1初始值计算方式如下:
[0040]
目标用户知识图谱用图的形式进行表示,即g=(v,e,w),其中v是目标用户节点集合,e代表目标用户节点之间的关系集合,w表示目标用户节点之间关系的权重矩阵。采用最
短最大传播策略方法,即选择目标用户节点之间最短的传播路径,且其行为影响传播强度最大。用w表示目标用户节点之间的关系权重,f表示目标用户节点的行为影响力。假设p
u,v
表示节点u和节点v的所有路径集合,那么两个目标用户节点间的行为影响传播可以用下式计算:
[0041][0042]
其中,代表节点u和节点v之间的第k条路径,表示节点v
i
和节点v
j
之间的关系权重,(v
i
,v
j
)表示节点u和节点v之间所有路径上的节点,包括节点u和节点v。f
i
表示每一个用户节点v
i
的行为影响力,计算方式如下:
[0043]
f
i
=tr(ia(i))
[0044]
tr(ia(i))表示用户节点v
i
对应的用户历史行为描述文本的特征矩阵ia的迹。最终的当前用户行为影响w1计算如下:
[0045][0046]
其中,代表节点间的第k条最短路径,并且假设两个目标用户节点之间共有t条最短路径。
[0047]
步骤s22:基于网络结构的其他用户行为影响w2计算。
[0048]
对于一个目标用户v
i
而言,其它用户行为的影响依赖于用户之间的邻居关系,因此,其他用户行为影响w2=degree(v
i
),这里使用图论节点的度计算。
[0049]
步骤s3:根据所述多因素权重,利用bi
‑
lstm和集束搜索策略进行行为预测。
[0050]
具体地,所述步骤s3包括:
[0051]
将每个目标用户的历史行为描述文本形成的特征矩阵ia作为bi
‑
lstm网络的输入,训练bi
‑
lstm学习每个目标用户的行为特征,输出已知目标用户、商品的情况下,用户对物品行为的概率值。其中,记前向lstm输出的概率向量为后向lstm输出的概率向量为两个概率向量记录了行为空间{点击,购买,收藏}三类行为的概率值,即在用户历史行为描述文本中捕捉到的行为种类。将目标用户和其它用户影响力权重加入模型训练中,对于一个目标用户v
i
,得到加权输出概率向量
[0052]
需要说明的是,两个向量分别是三个元素组成的向量,其中每个元素对应一类行为的概率值,本发明方法中只考虑这三类最常见且具有影响力的行为。训练好的加权bi
‑
lstm能够通过输入用户的历史描述文本向量矩阵,输出对用户的行为概率预测结果。
[0053]
以下结合具体实施例进一步地说明本发明方法:
[0054]
(1)提取目标用户历史行为特征:
[0055]
首先基于收集到的目标用户历史行为描述文本,将目标用户历史行为描述文本首先进行分词,然后再将每个词由word2vec转变为向量表示形式,构建初始化文本向量矩阵其中每一个(l=1,2,
…
m)表示句子中一个词的嵌入向量。将向量矩阵in输入transformer翻译模型,不断进行自注意力机制self
‑
attention学习后
得到目标用户历史行为描述文本的特征矩阵ia,矩阵ia的每一行为一个词的特征向量。
[0056]
以“张三收藏了电影”为例,将“张三收藏了电影”首先分词为“张三”“收藏”“电影”由word2vec转变为词向量矩阵输入transformer后,经过学习得到特征矩阵其中分别表示“张三”、“收藏”、“电影”的词向量,且具有相同的维度。
[0057]
(2)基于注意力机制自适应学习历史行为的多因素权重:
[0058]
首先从用户行为知识图谱中挖掘影响因素,本发明选择了两个主要影响因素进行分析,分别为当前用户行为影响w1、其他用户行为影响w2。计算方式如下:
[0059]
步骤s21:基于最短最大传播策略的当前用户行为影响w1计算。
[0060]
w1初始值计算方式如下:
[0061]
目标用户知识图谱用图的形式进行表示,即g=(v,e,w),其中v是目标用户节点集合,如e代表目标用户节点之间的关系集合,w表示节点之间关系的权重矩阵。采用最短最大传播策略方法,即选择目标用户节点之间最短的传播路径,其行为影响传播强度最大。用w表示目标用户节点之间的关系权重,f表示目标用户节点的行为影响力。假设p
u,v
表示节点u和节点v的所有路径集合,那么两个目标用户节点间的行为影响传播可以以下式计算:
[0062][0063]
其中,代表节点u和节点v之间的第k条路径,表示节点v
i
和节点v
j
之间的关系权重,(v
i
,v
j
)表示节点u和节点v之间所有路径上的节点,包括节点u和节点v,f
i
表示每一个用户节点v
i
的行为影响力。计算方式如下:
[0064]
f
i
=tr(ia(i))
[0065]
tr(ia(i))表示用户节点v
i
对应的用户历史行为描述文本的特征矩阵ia的迹。
[0066]
tr(ia(i))表示用户节点v
i
对应的用户历史行为描述文本的特征矩阵ia。最终的当前用户行为影响w1计算如下:
[0067][0068]
其中,代表节点间的第k条最短路径,并且假设两个目标用户节点之间共有t条最短路径。
[0069]
步骤s22:基于网络结构的其他用户行为影响w2计算。
[0070]
对于一个目标用户v
i
而言,其它用户行为的影响依赖于用户之间的邻居关系,因此其他用户行为影响w2=degree(v
i
),这里使用图论节点的度计算。
[0071]
(3)利用加权bi
‑
lstm和集束搜索策略进行行为预测:
[0072]
将每个目标用户的历史行为描述文本形成的特征矩阵ia作为bi
‑
lstm的输入,训练bi
‑
lstm学习每个目标用户的行为特征,输出已知目标用户、商品的情况下,用户对物品行为的概率值。其中,记前向lstm输出的概率向量为后向lstm输出的概率向量为两个概率向量记录了行为空间{点击,购买,收藏}三类行为的概率值,即在用户历史行为描
述文本中捕捉到的行为种类。将目标用户和其它用户影响力权重加入模型训练中,对于一个目标用户v
i
,得到加权输出概率向量
[0073]
训练好的加权bi
‑
lstm能够通过输入用户的历史描述文本向量矩阵,输出对用户的行为概率预测结果。
[0074]
进一步地,本发明还提供了一种基于多因素加权bi
‑
lstm学习的用户行为预测系统,包括目标用户历史行为特征提取模块、多因素权重学习模块和行为预测模块,其中:
[0075]
所述目标用户历史行为特征提取模块,用于将收集好的目标用户历史行为描述文本先由word2vec转变为向量表示形式,再利用transformer从用户历史行为描述文本中提取目标用户历史行为特征;
[0076]
所述多因素权重学习模块,用于根据所述目标用户历史行为特征,基于注意力机制自适应学习历史行为的多因素权重;
[0077]
所述行为预测模块,用于根据所述多因素权重,利用bi
‑
lstm和集束搜索策略进行行为预测。
[0078]
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。