1.本发明属于强化学习技术领域,更具体地,涉及一种分层决策的完全合作多智能体强化学习方法和系统。
背景技术:
2.强化学习(reinforcement learning,rl),又称再励学习、评价学习或增强学习,是机器学习的范式和方法论之一,用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题。多个智能体参与的强化学习面临“维数灾难”问题,即动作空间的大小随智能体的个数呈指数增长。
技术实现要素:
3.针对现有技术的以上缺陷或改进需求,本发明提供了一种分层决策的完全合作多智能体强化学习方案,通过采用分层决策的方法实现多智能体强化学习,减小动作空间,提高训练速度。
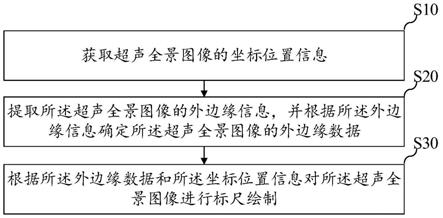
4.为实现上述目的,按照本发明的一个方面,提供了一种分层决策的完全合作多智能体强化学习方法,包括:
5.s1初始化模型参数;
6.s2对每一个智能体i,每隔t时间步长,产生上层动作;具体为,对每一个智能体i,每隔t时间步长,根据智能体i观察到的环境状态o
i
,对智能体i所有可能的高层动作计算执行的概率根据上述概率随机产生智能体i的上层动作其中是智能体i的上层动作集合,是智能体i的上层策略函数,是其参数,t是预设值;
7.s3对每一个智能体i,在每个时间步长,产生下层动作;
8.s4将所有智能体产生的下层动作输入到环境中执行,得到总回报r和新的环境状态,所有智能体对新的环境状态的观察为o'=(o'1,o'2,...,o'
n
);
9.s5在每个时间步长,更新下层全局状态
‑
动作函数的参数;
10.s6对每一个智能体i,在每个时间步长,更新下层策略函数的参数;
11.s7每隔t时间步长,更新上层全局状态
‑
动作函数参数;
12.s8对每一个智能体i,每隔t时间步长,更新上层策略函数的参数;
13.s9如果学习过程收敛或者达到最大迭代次数,则结束学习,否则返回s2。
14.本发明的一个实施例中,所述步骤s3具体为:对每一个智能体i,在每个时间步长,根据智能体i产生的上层动作和观察到的环境状态o
i
,对智能体i的上层动作所属的所有下层动作计算执行的概率按照上述概率,随机产生智能体i的下层动作其中是智能体i的上层动作所属的下层动作集合,
是智能体i的下层策略函数,是其参数。
15.本发明的一个实施例中,所述步骤s5具体为:
16.更新下层全局状态
‑
动作函数q
l
(o,a
l
|θ
l
)的参数θ
l
,其中q
l
(o,a
l
|θ
l
)为下层全局状态
‑
动作函数,o=(o1,o2,...,o
n
)是所有智能体的联合观察状态,是所有智能体的联合下层动作,l
l
是损失函数,l
l
对参数θ
l
连续可导,λ是学习率,γ∈(0,1]是折扣因子,o'=(o'1,o'2,...,o'
n
)是所有智能体对新的环境状态的观察。
17.本发明的一个实施例中,所述步骤s6具体为:对每一个智能体i,更新下层策略函数的参数的参数其中λ
l
是下层策略函数的学习率。
18.本发明的一个实施例中,所述步骤s7具体为:每隔t时间步长,更新上层全局状态
‑
动作函数q
h
(o,a
h
|θ
h
)的参数θ
h
,其中q
h
(o,a
h
|θ
h
)为上层全局状态
‑
动作函数,o=(o1,o2,...,o
n
)是所有智能体的联合观察状态,是所有智能体的联合上层动作,l
h
是损失函数,l
h
对参数θ
h
连续可导,λ是学习率,γ∈(0,1]是折扣因子,r
t
为前t个时间步长的累积回报,o'=(o'1,o'2,...,o'
n
)是所有智能体对新的环境状态的观察。
19.本发明的一个实施例中,所述步骤s8具体为:每隔t时间步长,对每一个智能体i,更新上层策略函数的参数θ
ih
,其中λ
h
是上层策略函数的学习率。
20.本发明的一个实施例中,间隔步长数5≤t≤20。
21.8、如权利要求1或2所述的分层决策的完全合作多智能体强化学习方法,其特征在于,上层全局状态
‑
动作值函数q
h
、下层全局状态
‑
动作值函数q
l
、智能体i的上层策略函数智能体i的下层策略函数均为循环神经网络。
22.本发明的一个实施例中,所述步骤s1中,初始化的参数包括:上层全局状态
‑
动作值函数的参数θ
h
、下层全局状态
‑
动作值函数的参数θ
l
、所有智能体的上层策略函数的参数{θ
ih
}、所有智能体的下层策略函数的参数初始化的方法是随机产生(0,1/n)均匀分布的随机数,其中n是上层全局状态
‑
动作值函数q
h
、下层全局状态
‑
动作值函数q
l
、智能体i的上层策略函数智能体i的下层策略函数中间层的维数。
23.按照本发明的另一方面,还提供了一种分层决策的完全合作多智能体强化学习系统,包括参数初始化模块、上层动作产生模块、下层动作产生模块、环境状态更新模块、下层
动作函数参数更新模块、下层策略函数参数更新模块、上层动作函数参数更新模块、上层策略函数参数更新模块和学习终止判断模块,其中:
24.所述参数初始化模块,用于初始化模型参数;
25.所述上层动作产生模块,用于对每一个智能体i,每隔t时间步长,产生上层动作;具体为,对每一个智能体i,每隔t时间步长,根据智能体i观察到的环境状态o
i
,对智能体i所有可能的高层动作计算执行的概率根据上述概率随机产生智能体i的上层动作其中是智能体i的上层动作集合,是智能体i的上层策略函数,θ
ih
是其参数,t是预设值;
26.所述下层动作产生模块,用于对每一个智能体i,在每个时间步长,产生下层动作;
27.所述环境状态更新模块,用于将所有智能体产生的下层动作输入到环境中执行,得到总回报r和新的环境状态,所有智能体对新的环境状态的观察为o'=(o'1,o'2,...,o'
n
);
28.所述下层动作函数参数更新模块,用于在每个时间步长,更新下层全局状态
‑
动作函数的参数;
29.所述下层策略函数参数更新模块,用于对每一个智能体i,在每个时间步长,更新下层策略函数的参数;
30.所述上层动作函数参数更新模块,用于每隔t时间步长,更新上层全局状态
‑
动作函数参数;
31.所述上层策略函数参数更新模块,用于对每一个智能体i,每隔t时间步长,更新上层策略函数的参数;
32.所述学习终止判断模块,用于判断是否学习过程收敛或者达到最大迭代次数,如果是则结束学习,否则转所述上层动作产生模块。
33.总体而言,通过本发明所构思的以上技术方案与现有技术相比,具有如下有益效果:
34.(1)本发明通过对多个智能体的动作空间分层,有效的缓解了多智能体强化学习面临“维数灾难“问题,使得本方法能够处理有更多智能体参与的场景;
35.(2)本发明提出在ac(actor
‑
critic,参与者
‑
评价者)框架下采用分层决策的方法,由粗到精、逐层细化的进行决策,将每一层的动作空间的大小限制在一个合理的范围内,提高了智能体决策的效率;
36.(3)此外,由于动作空间的减小,简化了值网络和策略网络的设计及其参数规模,加快了训练的收敛速度。
附图说明
37.图1是本发明分层决策的完全合作多智能体强化学习方法的流程示意图;
38.图2是本发明分层决策的完全合作多智能体强化学习方法的原理示意图;
39.图3是本发明分层决策的完全合作多智能体强化学习系统的结构示意图。
具体实施方式
40.为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
41.如图1所示,本发明提供了一种分层决策的完全合作多智能体强化学习方法,包括:
42.s1初始化模型参数;
43.初始化的参数包括:上层全局状态
‑
动作值函数的参数θ
h
、下层全局状态
‑
动作值函数的参数θ
l
、所有智能体的上层策略函数的参数{θ
ih
}、所有智能体的下层策略函数的参数初始化的方法是随机产生(0,1/n)均匀分布的随机数,其中n是上层全局状态
‑
动作值函数q
h
、下层全局状态
‑
动作值函数q
l
、智能体i的上层策略函数智能体i的下层策略函数中间层的维数;
44.s2对每一个智能体i,每隔t时间步长,产生上层动作;
45.如图2所示,为本发明分层决策的完全合作多智能体强化学习方法的原理示意图,对每一个智能体i,每隔t时间步长,根据智能体i观察到的环境状态o
i
,对智能体i所有可能的高层动作计算执行的概率根据上述概率随机产生智能体i的上层动作其中是智能体i的上层动作集合,是智能体i的上层策略函数,是其参数,t是预设值;
46.优选地,间隔步长数5≤t≤20;
47.s3对每一个智能体i,在每个时间步长,产生下层动作;
48.对每一个智能体i,在每个时间步长,根据智能体i产生的上层动作和观察到的环境状态o
i
,对智能体i的上层动作所属的所有下层动作计算执行的概率按照上述概率随机产生智能体i的下层动作其中是智能体i的上层动作所属的下层动作集合,是智能体i的下层策略函数,是其参数;
49.s4将所有智能体产生的下层动作输入到环境中执行,得到总回报r和新的环境状态,所有智能体对新的环境状态的观察为o'=(o'1,o'2,...,o'
n
);
50.s5在每个时间步长,更新下层全局状态
‑
动作函数的参数;
51.更新下层全局状态
‑
动作函数q
l
(o,a
l
|θ
l
)的参数θ
l
,其中q
l
(o,a
l
|θ
l
)为下层全局状态
‑
动作函数,o=(o1,o2,...,o
n
)是所有智能体的联合观察状态,是所有智能体的联合下层动作,l
l
是损失函数,l
l
对参数θ
l
连续可导,
λ是学习率,γ∈(0,1]是折扣因子,o'=(o'1,o'2,...,o'
n
)是所有智能体对新的环境状态的观察;
52.s6对每一个智能体i,在每个时间步长,更新下层策略函数的参数;
53.对每一个智能体i,更新下层策略函数的参数的参数其中λ
l
是下层策略函数的学习率;
54.s7每隔t时间步长,更新上层全局状态
‑
动作函数参数;
55.每隔t时间步长,更新上层全局状态
‑
动作函数q
h
(o,a
h
|θ
h
)的参数θ
h
,其中q
h
(o,a
h
|θ
h
)为上层全局状态
‑
动作函数,o=(o1,o2,...,o
n
)是所有智能体的联合观察状态,是所有智能体的联合上层动作,l
h
是损失函数,l
h
对参数θ
h
连续可导,λ是学习率,γ∈(0,1]是折扣因子,r
t
为前t个时间步长的累积回报,o'=(o'1,o'2,...,o'
n
)是所有智能体对新的环境状态的观察;
56.s8对每一个智能体i,每隔t时间步长,更新上层策略函数的参数;
57.每隔t时间步长,对每一个智能体i,更新上层策略函数的参数的参数其中λ
h
是上层策略函数的学习率;
58.s9如果学习过程收敛或者达到最大迭代次数,则结束学习,否则返回s2。
59.进一步地,所述上层全局状态
‑
动作值函数q
h
、下层全局状态
‑
动作值函数q
l
、智能体i的上层策略函数智能体i的上层策略函数均为循环神经网络。
60.如图3所示,本发明提供了一种分层决策的完全合作多智能体强化学习系统,包括参数初始化模块、上层动作产生模块、下层动作产生模块、环境状态更新模块、下层动作函数参数更新模块、下层策略函数参数更新模块、上层动作函数参数更新模块、上层策略函数参数更新模块和学习终止判断模块,其中:
61.所述参数初始化模块,用于初始化模型参数;
62.所述上层动作产生模块,用于对每一个智能体i,每隔t时间步长,产生上层动作;具体为,对每一个智能体i,每隔t时间步长,根据智能体i观察到的环境状态o
i
,对智能体i所有可能的高层动作计算执行的概率根据上述概率随机产生智能体i的上层动作其中是智能体i的上层动作集合,是智能体i的上层策略函数,是其参数,t是预设值;
63.所述下层动作产生模块,用于对每一个智能体i,在每个时间步长,产生下层动作;
64.所述环境状态更新模块,用于将所有智能体产生的下层动作输入到环境中执行,得到总回报r和新的环境状态,所有智能体对新的环境状态的观察为o'
=(o'1,o'2,...,o'
n
);
65.所述下层动作函数参数更新模块,用于在每个时间步长,更新下层全局状态
‑
动作函数的参数;
66.所述下层策略函数参数更新模块,用于对每一个智能体i,在每个时间步长,更新下层策略函数的参数;
67.所述上层动作函数参数更新模块,用于每隔t时间步长,更新上层全局状态
‑
动作函数参数;
68.所述上层策略函数参数更新模块,用于对每一个智能体i,每隔t时间步长,更新上层策略函数的参数;
69.所述学习终止判断模块,用于判断是否学习过程收敛或者达到最大迭代次数,如果是则结束学习,否则转所述上层动作产生模块。
70.本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。