cdr系统中的患者数据匹配方法、主索引建立方法及装置
技术领域
1.本发明涉及数据处理技术领域,特别涉及一种cdr系统中的患者数据匹配方法、主索引建立方法及装置。
背景技术:
2.目前医院中信息系统较多,各个信息系统之间的患者标识不一致,无法进行关联及交叉索引,来获得其他相关信息,容易形成信息孤岛,无法实现对医疗数据资源的最大化利用,并且各系统的患者信息一致性和完整性较差。
3.总之,现有技术中,存在各业务系统之间没有统一的患者标识的问题。
技术实现要素:
4.本发明的目的在于提供一种cdr系统中的患者数据匹配方法、主索引建立方法及装置,以解决现有技术中,医院的各业务系统之间没有统一的患者标识的问题。
5.为了解决上述技术问题,根据本发明的第一个方面,提供了一种cdr系统中的患者数据匹配方法,包括:
6.获取待匹配数据和已确认数据,所述待匹配数据包含匹配字段,所述已确认数据包含所述匹配字段;
7.基于所述匹配字段的第i组合,依次获取所述待匹配数据和每一条所述已确认数据的第i相似度;
8.基于所有的所述第i相似度判断匹配是否成功,若成功,基于所有的所述第i相似度得到与所述待匹配数据相匹配的一条所述已确认数据;
9.其中,i的取值范围为1到n的所有整数,n为大于1的整数。
10.可选的,基于所有的所述第i相似度判断匹配是否成功的步骤包括:若每一条所述已确认数据对应的所述第i相似度小于或者等于第i阈值,匹配失败;否则,匹配成功;
11.或者,
12.基于所有的所述第i相似度判断匹配是否成功的步骤包括:若每一条所述已确认数据对应的所有的所述第i相似度的总和小于预设阈值,匹配失败;否则,匹配成功。
13.可选的,基于所有的所述第i相似度得到与所述待匹配数据相匹配的一条所述已确认数据的步骤包括:选择所有的所述第i相似度的总和最大的所述已确认数据。
14.可选的,基于所有的所述第i相似度得到与所述待匹配数据相匹配的一条所述已确认数据的步骤包括:
15.若第i集合中存在至少一条所述已确认数据的所述第i相似度大于第i阈值且i小于n,所述第i集合中所述第i相似度大于所述第i阈值的所述已确认数据组成第i 1集合并重新判断;
16.否则,选择第i集合中的所有的所述第i相似度的总和最大的所述已确认数据,或者选择第i集合中的所述第i相似度最大的所述已确认数据;
17.其中,第1集合为所有所述已确认数据。
18.可选的,获取所述待匹配数据和所述已确认数据的第i相似度的步骤包括:
19.依次获取第i组合中的每一个所述匹配字段对应的相似值,所述相似值基于第i加权参数加权平均后得到所述第i相似度。
20.可选的,所述待匹配数据中每一个所述匹配字段仅存储一个属性值,所述已确认数据中每一个所述匹配字段存储一个或者两个以上的属性值;获取所述匹配字段对应的所述相似值的步骤包括:
21.所述待匹配数据中的属性值与所述已确认数据中对应的所述匹配字段中的每一个属性值进行相似性计算,计算结果加权平均后得到所述相似值。
22.可选的,第1组合包括姓名字段、性别字段和身份证号码字段,所述身份证号码字段对应的所述第1加权参数大于0.5。
23.可选的,所述匹配字段包括姓名字段,获取所述姓名字段对应的所述相似值的方法包括:按照如下公式计算:
[0024][0025]
其中,similarity表示所述相似值,ed
ab
表示a和b之间的编辑距离,max()表示取极大值运算,l
a
表示a的字符串长度,l
b
表示b的字符串长度,a表示所述待匹配数据中的所述姓名字段存储的属性值,b表示所述已确认数据中的所述姓名字段存储的属性值。
[0026]
为了解决上述技术问题,根据本发明的第二个方面,提供了一种cdr系统中的患者主索引建立方法,包括:
[0027]
从至少两个业务系统中获取原始数据,所述原始数据包含匹配字段;
[0028]
所述原始数据基于清洗规则分类为第一数据和第二数据;
[0029]
所述第一数据基于合并规则生成已确认数据,所述已确认数据包含匹配字段和主索引字段;
[0030]
所述第二数据被配置为待匹配数据,所述待匹配数据基于上述的cdr系统中的患者数据匹配方法得到匹配结果;
[0031]
若匹配成功,当前的所述待匹配数据和匹配的所述已确认数据合并;
[0032]
若匹配失败,当前的所述待匹配数据生成临时索引数据。
[0033]
可选的,所述匹配字段包括姓名字段和身份证字段,所述合并规则包括:
[0034]
判断所述第一数据与一条所述已确认数据的所述身份证字段是否相等,以及判断当前的所述第一数据与当前的所述已确认数据的所述姓名字段相等;
[0035]
若所述第一数据与一条所述已确认数据的所述身份证字段相等且当前的所述第一数据与当前的所述已确认数据的所述姓名字段相等;当前的所述第一数据和当前的所述已确认数据合并;
[0036]
否则,当前的所述第一数据独立地转换为一条新的所述已确认数据。
[0037]
可选的,所述第一数据中每一个所述匹配字段仅存储一个属性值,所述已确认数据中每一个所述匹配字段存储一个或者两个以上的属性值,判断所述第一数据与所述已确认数据的所述匹配字段是否相等的步骤包括:
[0038]
若所述第一数据的所述匹配字段的属性值为空值,判断结果为不相等;
[0039]
若所述第一数据的所述匹配字段的属性值不为空值并且所述第一数据的所述匹配字段的属性值与所述已确认数据的所述匹配字段的属性值均不相等,判断结果为不相等;
[0040]
若所述第一数据的所述匹配字段的属性值不为空值并且所述第一数据的所述匹配字段的属性值与所述已确认数据的所述匹配字段的属性值中的一条相等,判断结果为相等。
[0041]
可选的,待合并数据和所述已确认数据合并的步骤包括:
[0042]
所述待合并数据和所述已确认数据依次关于每一个所述匹配字段进行判断,若所述待合并数据的所述匹配字段的属性值不为空值并且所述待合并数据的所述匹配字段的属性值与所述已确认数据的所述匹配字段的属性值均不相等,当前的所述待合并数据的属性值存储入所述已确认数据的所述匹配字段中;
[0043]
其中,所述待合并数据包括所述第一数据和所述待匹配数据。
[0044]
为了解决上述技术问题,根据本发明的第三个方面,提供了一种患者主索引建立装置,所述医疗系统患者主索引建立装置包括匹配模块,所述匹配模块用于执行上述的数据匹配方法。
[0045]
与现有技术相比,本发明提供的cdr系统中的患者数据匹配方法、主索引建立方法及装置中,所述cdr系统中的患者数据匹配方法包括:获取待匹配数据和已确认数据;基于所述匹配字段的至少两个组合,依次获取每一条所述已确认数据的至少两个相似度;基于所有的所述相似度判断匹配是否成功,并得到与所述待匹配数据相匹配的所述已确认数据。基于上述的cdr系统中的患者数据匹配方法,可以构建患者的主索引,并进而获得患者的所有的历史就诊记录,辅助病情诊断和医疗科研,解决了现有技术中,医院的各业务系统之间没有统一的患者标识的问题。另一方面,使用多轮次的匹配方式,也增加了匹配结果的有效性,能够应对复杂的数据工况。
附图说明
[0046]
本领域的普通技术人员将会理解,提供的附图用于更好地理解本发明,而不对本发明的范围构成任何限定。其中:
[0047]
图1是本发明一实施例的cdr系统中的患者数据匹配方法的流程示意图;
[0048]
图2是本发明一实施例的cdr系统中的患者主索引建立方法的流程示意图。
具体实施方式
[0049]
为使本发明的目的、优点和特征更加清楚,以下结合附图和具体实施例对本发明作进一步详细说明。需说明的是,附图均采用非常简化的形式且未按比例绘制,仅用以方便、明晰地辅助说明本发明实施例的目的。此外,附图所展示的结构往往是实际结构的一部分。特别的,各附图需要展示的侧重点不同,有时会采用不同的比例。
[0050]
如在本发明中所使用的,单数形式“一”、“一个”以及“该”包括复数对象,术语“或”通常是以包括“和/或”的含义而进行使用的,术语“若干”通常是以包括“至少一个”的含义而进行使用的,术语“至少两个”通常是以包括“两个或两个以上”的含义而进行使用的,此
外,术语“第一”、“第二”、“第三”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”、“第三”的特征可以明示或者隐含地包括一个或者至少两个该特征,“一端”与“另一端”以及“近端”与“远端”通常是指相对应的两部分,其不仅包括端点,术语“安装”、“相连”、“连接”应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或成一体;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通或两个元件的相互作用关系。此外,如在本发明中所使用的,一元件设置于另一元件,通常仅表示两元件之间存在连接、耦合、配合或传动关系,且两元件之间可以是直接的或通过中间元件间接的连接、耦合、配合或传动,而不能理解为指示或暗示两元件之间的空间位置关系,即一元件可以在另一元件的内部、外部、上方、下方或一侧等任意方位,除非内容另外明确指出外。对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本发明中的具体含义。
[0051]
本发明的核心思想在于提供一种cdr(clinical data resposiry临床数据中心系统)系统中的患者数据匹配方法、主索引建立方法及装置,以解决现有技术中,医院的各业务系统之间没有统一的患者标识的问题。
[0052]
以下参考附图进行描述。
[0053]
请参考图1至图2,其中,图1是本发明一实施例的cdr系统中的患者数据匹配方法的流程示意图;图2是本发明一实施例的cdr系统中的患者主索引建立方法的流程示意图。
[0054]
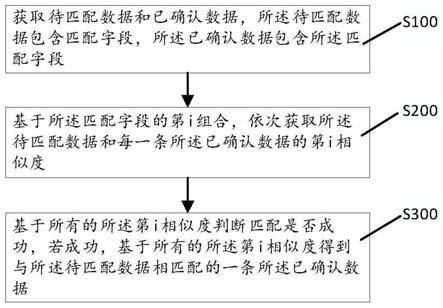
如图1所示,本实施例提供了一种cdr系统中的患者数据匹配方法,包括:
[0055]
s100获取待匹配数据和已确认数据,所述待匹配数据包含匹配字段,所述已确认数据包含所述匹配字段;
[0056]
s200基于所述匹配字段的第i组合,依次获取所述待匹配数据和每一条所述已确认数据的第i相似度;
[0057]
s300基于所有的所述第i相似度判断匹配是否成功,若成功,基于所有的所述第i相似度得到与所述待匹配数据相匹配的一条所述已确认数据;
[0058]
其中,i的取值为1到n的所有整数,n为大于1的整数。
[0059]
在步骤s100中,包含匹配字段应当按照如下思路理解。假设匹配字段中的一条的字段名为“f”,其中某条数据(具体指,所述待匹配数据或者所述已确认数据,此处为了便于描述,简称为数据)的“f”字段的属性值为空值;基于不同的规范或者标准,在该条数据中可能包含“f:null”或者“f:;”的字符串,也可能完全不包含代表“f”字段的字符串。但是,本方法处理的所有数据中,只要存在一条数据包含代表“f”字段的字符串,或者,用于对上述数据进行解析、读取或者后处理的方法中,包含了关于“f”字段的操作方法,就应当理解为这条数据包含了“f”字段。
[0060]
在步骤s200中,实际上一共进行n次计算,第i次计算使用第i组合,并且获得第i相似度。在步骤s200中,第k1次计算和第k2次计算的区别在于,第k1组合和第k2组合不同,和/或,计算方式不同。其中,k1≠k2,k1的取值范围为1到n的所有整数,k2的取值范围为1到n的所有整数。
[0061]
在步骤s300中,判断匹配是否成功,或者得到匹配数据的方案,可以参考本实施例的后续内容进行理解,本领域技术人员也可以通过对本实施例所提供的具体方案进行变通修改,也应当理解为本发明技术方案的保护范围。
[0062]
如此配置,通过多轮次的模糊匹配,能够使得所述待匹配数据找到最接近的匹配数据,并有利于后续的全局索引值的建立。是解决医院的各业务系统之间没有统一的患者标识的问题的核心方法。
[0063]
在一实施例中,基于所有的所述第i相似度判断匹配是否成功的步骤包括:若每一条所述已确认数据对应的所述第i相似度小于或者等于第i阈值(此处应当理解为,对于i取1至n,均成立),匹配失败;否则,匹配成功。
[0064]
假设,所述已确认数据为3条,且编号分别为1、2、3。n的取值为3,第1阈值为0.9,第2阈值为0.9,第3阈值为0.9。一所述待匹配数据与所述已确认数据的相似度如表1所示。
[0065]
表1一所述匹配数据的相似度
[0066]
已确认数据编号第1相似度第2相似度第3相似度10.80.70.620.60.70.830.30.20.3
[0067]
由于表1中的每一条所述已确认数据的第i相似度均小于第i阈值,因此,认为匹配失败。
[0068]
在另一个实施例中,基于所有的所述第i相似度判断匹配是否成功的步骤包括:若每一条所述已确认数据对应的所有的所述第i相似度的总和小于预设阈值,匹配失败;否则,匹配成功。
[0069]
假设,所述已确认数据为3条,且编号分别为1、2、3。n的取值为3,所述预设阈值为2.7。一所述待匹配数据与所述已确认数据的相似度如表2所示。
[0070]
表2一所述匹配数据的相似度
[0071]
已确认数据编号第1相似度第2相似度第3相似度10.80.70.620.60.70.830.30.20.3
[0072]
由于表2中的每一条所述已确认数据的所有相似度的总和小于2.7,因此,认为匹配失败。
[0073]
在一实施例中,基于所有的所述第i相似度得到与所述待匹配数据相匹配的一条所述已确认数据的步骤包括:选择所有的所述第i相似度的总和最大的所述已确认数据。
[0074]
假设,所述已确认数据为3条,且编号分别为1、2、3。n的取值为3。一所述待匹配数据与所述已确认数据的相似度如表3所示。
[0075]
表3一所述匹配数据的相似度
[0076]
已确认数据编号第1相似度第2相似度第3相似度10.80.70.820.60.70.830.30.20.3
[0077]
由于表3中的编号为1的所述已确认数据的所有相似度的总和为2.5,为最大值,因此,选择第1条所述已确认数据作为匹配数据。
[0078]
需理解,尽管表3中第1条数据的所有相似度的总和小于前一个例子中的预设阈值2.7,但是在本实施例中,并未限定判断失败的条件是什么。有可能在本实施例中采用总和大于1即认为匹配成功的方案,也有可能选择第1阈值~第3阈值均为0.5的方案,也有可能选择其他的可行方案。此处的举例仅为说明匹配数据的选择标准,而不是匹配是否成功的判断标准。
[0079]
需理解,当符合条件的数据有至少两条时(例如,有两条数据的最大值相等),按照附加规则选择,例如,选择第1相似度最大的数据,随机选择数据,选择创建时间最早的数据,或者其他的综合判断的规则。在绝大部分情况下,并不会出现所有的所述第i相似度的总和最大的所述已确认数据恰好多于一条的情况,此处的附加规则仅是为了防止程序出错所设置,因此可以设置为较为简单的规则。说明书后续内容中与本段逻辑相似的描述都可以按照本段的思路进行理解。
[0080]
在另一实施例中,基于所有的所述第i相似度得到与所述待匹配数据相匹配的一条所述已确认数据的步骤包括:
[0081]
s301若第i集合中存在至少一条所述已确认数据的所述第i相似度大于第i阈值且i小于n,所述第i集合中所述第i相似度大于所述第i阈值的所述已确认数据组成第i 1集合并重新判断;
[0082]
s302否则,选择第i集合中的所有的所述第i相似度的总和最大的所述已确认数据;
[0083]
其中,第1集合为所有所述已确认数据。
[0084]
假设,所述已确认数据为5条,且编号分别为1、2、3、4、5。n的取值为3,第1阈值为0.6,第2阈值为0.75,第3阈值为0.65。一所述待匹配数据与所述已确认数据的相似度如表4所示。
[0085]
表4一所述匹配数据的相似度
[0086][0087][0088]
在第1轮中,由于编号为3的所述已确认数据的第1相似度为0.6,因此,第2集合为编号为1、2、4、5的所述已确认数据,第3集合为编号为4、5的所述已确认数据,由于判断第3集合时,此时的i已经和n相等,因此,根据“选择第i集合中的所有的所述第i相似度的总和最大的所述已确认数据”选择,选择编号为4的数据。从这里的例子可以看出,尽管编号为3的数据,其所有相似度的总和最大,但是却不是最终匹配到的数据。
[0089]
在另一个例子中,第2阈值为0.8,其他的条件与上一个例子完全相同。此时,第2集合中已经不存在大于第2阈值的数据,因此,选择第2集合中所有相似度总和最大的数据,即
编号为1的数据。
[0090]
上述逻辑的核心思路是,按照类似于淘汰赛的机制进行选择,若某一条所述已确认数据在某一轮中的相似度较低,则会被排除出候选名单。
[0091]
在再一实施例中,基于所有的所述第i相似度得到与所述待匹配数据相匹配的一条所述已确认数据的步骤包括:
[0092]
s301若第i集合中存在至少一条所述已确认数据的所述第i相似度大于第i阈值且i小于n,所述第i集合中所述第i相似度大于所述第i阈值的所述已确认数据组成第i 1集合并重新判断;
[0093]
s302否则,选择第i集合中的所述第i相似度最大的所述已确认数据;
[0094]
其中,第1集合为所有所述已确认数据。
[0095]
上述实施例的主体思路和前一个实施例基本相同,不同之处在于最后选择的是第i相似度最大的数据,其具体的执行过程可以参考前一个实施例进行理解。
[0096]
进一步地,获取所述待匹配数据和所述已确认数据的第i相似度的步骤包括:
[0097]
依次获取第i组合中的每一个所述匹配字段对应的相似值,所述相似值基于第i加权参数加权平均后得到所述第i相似度。
[0098]
例如,所述第i组合包括所述匹配字段“c”、“d”和“e”,其中,“c”的第i加权参数为0.2,“d”的第i加权参数为0.3,“e”的第i加权参数为0.5,“c”对应的相似值为0.7,“d”对应的相似值为0.5,“e”对应的相似值为0.8,则最终的相似度计算结果为0.2*0.7 0.3*0.5 0.5*0.8=0.69。
[0099]
需理解,当i取不同的值时,相同的所述匹配字段对应的第i加权参数可能不同。
[0100]
进一步地,所述待匹配数据中每一个所述匹配字段仅存储一个属性值,所述已确认数据中每一个所述匹配字段存储一个或者两个以上的属性值;获取所述匹配字段对应的所述相似值的步骤包括:
[0101]
所述待匹配数据中的属性值与所述已确认数据中对应的所述匹配字段中的每一个属性值进行相似性计算,计算结果加权平均后得到所述相似值。
[0102]
当所述匹配字段为“c”、“d”和“e”时,一条所述待匹配数据的可能形式如表5所示。
[0103]
表5待匹配数据的示范形式
[0104]
字段名cde属性值386
[0105]
一条所述已确认数据的可能形式如表6所示。
[0106]
表6已确认数据的示范形式
[0107][0108]
表6所示的一条所述已确认数据中,“c”字段对应的属性值为3、4和7。
[0109]
需理解,在实际的业务方法中,所述待匹配数据和所述已确认数据中还包括其他
业务相关的字段,本说明书不限定上述数据在存储非匹配字段时的存储方式。
[0110]
在一个较优的实施例中,第1组合包括姓名字段、性别字段和身份证号码字段,所述身份证号码字段对应的所述第1加权参数大于0.5。例如,所述姓名字段的第1加权参数为0.1,所述性别字段的第1加权参数为0.1,所述身份证号码字段对应的第1加权参数为0.8。如此配置,可以让计算得到的第1相似度具有较高的区分度。
[0111]
在一些实施例中,第2组合可以包括联系电话字段,所述联系电话字段的第2加权参数大于0.5,所述第2组合的其他字段可以根据不同的需求进行设置。第3组合可以包括家庭住址字段,所述家庭住址字段的第3加权参数大于0.5,所述第3组合的其他字段可以根据不同的需求进行设置。
[0112]
所述匹配字段包括姓名字段,获取所述姓名字段对应的所述相似值的方法包括:按照如下公式计算:
[0113][0114]
其中,similarity表示所述相似值,ed
ab
表示a和b之间的编辑距离,max()表示取极大值运算,l
a
表示a的字符串长度,l
b
表示b的字符串长度,a表示所述待匹配数据中的所述姓名字段存储的属性值,b表示所述已确认数据中的所述姓名字段存储的属性值。
[0115]
其中,编辑距离又可以称为levenshtein(人名)距离,指的是两个字符串之间,由一个转换成另一个所需的最少编辑操作次数。许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。编辑距离首先由俄国科学家levenshtein提出。如此配置,一方面解决了姓名字符串之间相似度的计算问题,另一方面,当两个姓名完全不同时,计算结果为0,和预期相吻合。
[0116]
本实施例提供了一种cdr系统中的患者主索引建立方法,请参考图2,所述cdr系统中的患者主索引建立方法包括:
[0117]
s10从至少两个业务系统中获取原始数据,所述原始数据包含匹配字段;
[0118]
s20所述原始数据基于清洗规则分类为第一数据和第二数据;
[0119]
s31所述第一数据基于合并规则生成已确认数据,所述已确认数据包含匹配字段和主索引字段;
[0120]
s41所述第二数据被配置为待匹配数据,所述待匹配数据基于上述的数据匹配方法得到匹配结果;
[0121]
s42若匹配成功,当前的所述待匹配数据和匹配的所述已确认数据合并;
[0122]
s43若匹配失败,当前的所述待匹配数据生成临时索引数据。
[0123]
在图2中,精确数据即所述第一数据,模糊数据即所述第二数据,模糊匹配即上述的数据匹配方法。在步骤s10中,cdr系统的数据即来源于至少两个业务系统的数据,在步骤s42中,合并到精确数据中应当理解为合并到已经生成了主索引的精确数据中,即所述已确认数据中。
[0124]
处理存量数据和处理增量数据的流程,实际上并没有区别,只不过处理存量数据(或者说所述cdr系统中的患者主索引建立方法第一次运行时)时,最初的所述已确认数据的数量为0,而处理增量数据时,已经存在一部分的所述已确认数据。
[0125]
所述主索引字段的生成规则,可以按照实际需求进行设置,在此不进行展开描述。在步骤s20的清洗规则,可以根据实际需要设置,在一实施例中,可以设置为,所述姓名字段为空值以及所述身份证字段为空值的数据分类为所述第二数据,其余的分类为所述第一数据。在其他的实施例中可以设置为其他规则。
[0126]
进一步地,所述匹配字段包括姓名字段和身份证字段,所述合并规则包括:
[0127]
判断所述第一数据与一条所述已确认数据的所述身份证字段是否相等,以及判断当前的所述第一数据与当前的所述已确认数据的所述姓名字段相等;
[0128]
若所述第一数据与一条所述已确认数据的所述身份证字段相等且当前的所述第一数据与当前的所述已确认数据的所述姓名字段相等;当前的所述第一数据和当前的所述已确认数据合并;
[0129]
否则,当前的所述第一数据独立地转换为一条新的所述已确认数据。
[0130]
即,相等的数据合并,不相等的数据独立地转换为一条新的所述已确认数据。其中,转换过程可以包括:复制所述第一数据的全部内容并添加所述主索引字段,转换过程还可以包括因为业务逻辑需要的其他的步骤,本领域技术人员可以根据公知常识进行设置,在此不进行展开说明。从理论上判断,有可能两条不符合条件的数据实际是指向同一个患者的,但是在实际执行中发现,因为这个规则造成的错误量是很小的,而且发生此类错误后,也可以通过人工修正,因此,在本实施例中采用上述的逻辑进行设置和区分。
[0131]
所述第一数据中每一个所述匹配字段仅存储一个属性值,所述已确认数据中每一个所述匹配字段存储一个或者两个以上的属性值,此处的逻辑也可以参考前文中关于表5和表6的内容进行理解。判断所述第一数据与所述已确认数据的所述匹配字段是否相等的步骤包括:
[0132]
若所述第一数据的所述匹配字段的属性值为空值,判断结果为不相等;
[0133]
若所述第一数据的所述匹配字段的属性值不为空值并且所述第一数据的所述匹配字段的属性值与所述已确认数据的所述匹配字段的属性值均不相等,判断结果为不相等;
[0134]
若所述第一数据的所述匹配字段的属性值不为空值并且所述第一数据的所述匹配字段的属性值与所述已确认数据的所述匹配字段的属性值中的一条相等,判断结果为相等。
[0135]
此处的加权平均所使用的权重,可以根据历史数据中各属性出现的次数进行设置,也可以根据其他方式进行设置。
[0136]
待合并数据和所述已确认数据合并的步骤包括:
[0137]
所述待合并数据和所述已确认数据依次关于每一个所述匹配字段进行判断,若所述待合并数据的所述匹配字段的属性值不为空值并且所述待合并数据的所述匹配字段的属性值与所述已确认数据的所述匹配字段的属性值均不相等,当前的所述待合并数据的属性值存储入所述已确认数据的所述匹配字段中;
[0138]
其中,所述待合并数据包括所述第一数据和所述待匹配数据。
[0139]
例如,所述待合并数据的内容如表5所示,所述已确认数据的内容如表6所示,合并后的数据如表7所示。
[0140]
表7合并后的已确认数据的示范形式
[0141][0142]
关于所述待合并数据和所述已确认数据合并其他的非匹配字段的合并方式,可以根据实际需要进行设置,在此不进行展开说明。
[0143]
基于上述方法,可以开发cdr系统,cdr系统集成了医院各个系统的医疗数据,empi(enterprise master patient index,患者主索引)系统对cdr系统建立患者主索引,进行医疗数据的统一管理。患者主索引的准确性取决于患者信息匹配算法的精度。empi系统提供患者主索引生成和患者主索引查询功能。利用empi系统中的患者主索引,医生及相关人员可以快速在cdr系统中找到患者的历史所有的就诊记录,辅助病情诊断和医疗科研。
[0144]
本实施例还提供了一种患者主索引建立装置,包括匹配模块,所述匹配模块用于执行上述的cdr系统中的患者数据匹配方法。
[0145]
可选的,所述患者主索引建立装置还包括:
[0146]
获取模块,用于从至少两个业务系统中获取原始数据,所述原始数据包含匹配字段;
[0147]
分类模块,用于基于清洗规则将所述原始数据分类为第一数据和第二数据;
[0148]
合并模块,用于基于合并规则将所述第一数据生成已确认数据,所述已确认数据包含匹配字段和主索引字段;
[0149]
输入模块,用于将所述第二数据配置为待匹配数据输入所述匹配模块;以及,
[0150]
处理模块,用于基于所述匹配模块的匹配结果处理数据,若匹配成功,当前的所述待匹配数据和匹配的所述已确认数据合并;若匹配失败,当前的所述待匹配数据生成临时索引数据。
[0151]
上述装置的具体工作流程,可以参考本说明书关于cdr系统中的患者主索引建立方法的描述进行理解。
[0152]
上述的患者主索引建立装置能够解决现有技术中,各业务系统之间没有统一的患者标识的问题。
[0153]
与现有技术相比,本发明提供的cdr系统中的患者数据匹配方法、主索引建立方法及装置中,所述cdr系统中的患者数据匹配方法包括:获取待匹配数据和已确认数据;基于所述匹配字段的至少两个组合,依次获取每一条所述已确认数据的至少两个相似度;基于所有的所述相似度判断匹配是否成功,并得到与所述待匹配数据相匹配的所述已确认数据。基于上述的cdr系统中的患者数据匹配方法,可以构建患者的主索引,并进而获得患者的所有的历史就诊记录,辅助病情诊断和医疗科研,解决了现有技术中,医院的各业务系统之间没有统一的患者标识的问题。另一方面,使用多轮次的匹配方式,也增加了匹配结果的有效性,能够应对复杂的数据工况。
[0154]
上述描述仅是对本发明较佳实施例的描述,并非对本发明范围的任何限定,本发明领域的普通技术人员根据上述揭示内容做的任何变更、修饰,均属于本发明技术方案的
保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。