1.本发明属于数据挖掘技术领域,更具体地,涉及一种基于多层属性分析的跨空间目标虚拟身份关联方法。
背景技术:
2.虚拟身份关联技术在公共安全领域具有重要的应用价值,虚拟身份关联技术可以发现互联网用户的真实身份,进而挖掘用户的异常行为,有助于帮助公安机关对犯罪分子进行定位甚至对犯罪行为进行预测,从而阻止违法犯罪行为的发生。采用机器学习等方法发现不同互联网账户的关联,有助于识别互联网用户的真实身份。通过挖掘互联网用户特征来构建用户画像,进而通过用户画像计算用户相似性,从而实现虚拟身份关联。
3.由于网络虚拟空间中用户的身份信息具有虚假性、不完整性等特点,导致进行虚实映射所用的用户关键信息较少且缺乏准确性,因此用户的多重虚拟身份难以建立对应关系。现有的虚拟身份关联技术往往从用户的基础信息或用户社交关系出发,根据用户基础信息相似性或用户社交相似性实现虚拟身份关联。然而,当用户的信息不全或者不真实时,仅利用单一属性的身份关联效果不佳。
技术实现要素:
4.针对现有技术的以上缺陷或改进需求,本发明提供了一种基于多层属性分析的跨空间目标虚拟身份关联方法,对网络空间中用户在不同平台的虚拟身份进行关联,对用户的身份背景信息、政治观点、社交关系等多层属性进行分析,综合考虑不同维度的用户信息,从而提高用户身份关联的准确性。
5.为实现上述目的,本发明提供了一种基于多层属性分析的跨空间目标虚拟身份关联方法,包括:
6.步骤s1:使用赋权法计算用户基础信息相似度,其中用户基础信息包括用户名、性别、地址和年龄;
7.步骤s2:运用双向长短期记忆网络模型计算用户观点相似度,其中用户观点隐藏于用户发布的文本中;
8.步骤s3:采用基于图神经网络的方法计算用户社交关系相似度,其中用户社交关系以用户间链接信息及互动信息表征;
9.步骤s4:综合考虑用户基础信息相似度、用户观点相似度以及用户社交关系相似度,计算用户相似度。
10.本发明的一个实施例中,所述步骤s1包括:
11.用户的基础信息包括用户名、性别、年龄、地址,以(属性,值)的形式存在,用户i的属性信息表示为其中每个用户包含l个属性;
12.针对a、b两个用户分别计算其每个属性的相似度
13.用户各属性相似度表示为采用熵权法计算各属性的权重w
k
,用户的基础信息相似度表示为:
14.本发明的一个实施例中,进行属性相似度计算时,针对不同类型的属性,分别采用不同方式计算其相似性,具体为:
15.针对数值型属性,采用数值匹配方式计算其相似度;
16.针对字符型属性,采用levenshein距离计算其相似度。
17.本发明的一个实施例中,所述步骤s2包括:
18.设包含用户a的观点的文本为t
a
,提取的整体特征向量为θ
a
;包含用户b的观点的文本为t
b
,提取的整体特征向量为θ
b
;计算用户a、b的观点相似度:
19.本发明的一个实施例中,对文本提取整体特征向量的方式为:
20.将词语i的嵌入向量和特征向量进行拼接得到其局部特征;
21.将文本的局部特征输入双向lstm以得到文本的整体特征;
22.采用平均池化方法对lstm的输出特征进行处理得到文本的整体特征向量。
23.本发明的一个实施例中,将词语i的嵌入向量和特征向量进行拼接得到其局部特征,具体为:
24.已知包含用户观点的社交平台词汇数据库集合为w=(w1,w2,
…
,w
n
},其中,n表示词汇库中的词语数目,选择包含用户观点的文本t进行分词,得到文本t的one
‑
hot编码c
t
={c1,c2,
…
,c
t
,
…
,c
n
},运用word2vec方法得到第t个词语的嵌入向量v
t
,运用特征抽取方法对文本进行特征抽取,得到t个词语的特征向量将词语i的嵌入向量和特征向量进行拼接得到其局部特征
25.本发明的一个实施例中,将文本的局部特征输入双向lstm以得到文本的整体特征,具体为:
26.前向lstm更新过程如下:
[0027][0028]
f_i
t
=σ(w
xi
x
t
w
hi
f_h
t
‑1 w
ci
f_c
t
‑1 b
i
)
[0029]
f_f
t
=σ(w
xf
x
t
w
hf
f_h
t
‑1 w
cf
f_c
t
‑1 b
f
)
[0030][0031]
f_o
t
=σ(w
xo
x
t
w
ho
f_h
t
‑1 w
co
f_c
t
‑1 b
o
)
[0032][0033]
式中,σ表示sigmoid函数,f_i
t
、f_i
t
、f_o
t
分别表示输入门、遗忘门和输出门,w表示权重矩阵,b
i
、b
f
、b
o
、b
g
表示偏置项,f_c
t
‑1、f_c
t
分别表示t
‑
1、t个单元的细胞状态,f_h
t
表示第t个单元的输出。
[0034]
反向lstm的更新过程与前向lstm更新过程相似,反向lstm第t个单元的输出以及细胞状态分别为b_h
t
、b_c
t
,将前向lstm与反向lstm的细胞状态及输出进行融合得到第t个
词语的特征向量f
t
=[f_h
t
,f_c
t
,b_h
t
,b_c
t
],整个文本的输出特征为f={f1,f2,
…
,f
t
,
…
,f
n
}。
[0035]
本发明的一个实施例中,采用平均池化方法对lstm的输出特征进行处理得到文本的整体特征向量,具体为:文本的整体特征向量θ=mean(f)。
[0036]
本发明的一个实施例中,所述步骤s3包括:
[0037]
在基于图神经网络的社交模型中,以用户作为图节点,用户之间的关注信息、粉丝信息社交关系以网络的边表示,用户的转发、评论、点赞、@社交行为作为图节点的属性信息,基于用户的社交关系及社交行为构建的图神经网络为g={v,e,l
v
,l
e
},其中具体定义如下:
[0038]
用户:v={v1,v2,
……
,v
m
}表示含有m个用户的用户集合,v
i
表示其中第i个用户;
[0039]
社交属性:l
v
={l1,l2,
……
l
n
}表示用户节点特征向量集合,其中l
i
为第i个用户节点的特征向量,表示第i个用户的社交属性信息,社交属性信息包括用户的转发、评论、点赞、@社交行为;
[0040]
社交关系:e={l
(i,j)
|(i,j∈n}表示边集,其中l
(i,j)
表示用户i和用户j的社交关系,l
(i,j)
=1表示用户i对用户j存在关注行为,用户i是j的粉丝;l
(i,j)
=0表示用户i对用户j不存在关注行为,i不是j的粉丝,l
e
={l
(i,j)
|(i,j∈n)}表示边的特征向量的集合。
[0041]
根据上述定义构建社交图神经网络g,神经网络中节点v的状态嵌入h
v
及节点输出o
v
分别表示为:h
v
=f(x
v
,x
ne|v|
,h
ne|v|
,l
co|v|
),o
v
=g(h
v
,x
v
),式中,x
v
表示节点v的特征,即用户的社交属性信息;x
ne|v|
表示节点v的邻居节点的特征;l
co|v|
表示节点v的边的特征,即用户之间的社交关系;h
ne|v|
表示节点v的邻居节点的状态嵌入;f(
·
)表示局部聚合函数;g(
·
)表示局部输出函数。
[0042]
从训练集d1中选取训练样本输入模型,通过迭代训练学习f和g的参数,使得预测尽量接近样本h,模型训练好后,将用户a和b的数据输入模型,得到用户的嵌入向量x
a
和x
b
,计算用户社交关系相似度:
[0043]
本发明的一个实施例中,所述步骤s4包括:
[0044]
根据用户基础信息相似度用户观点相似度用户社交关系相似度计算用户a、b综合相似度式中,w1、w2、w3分别为基础信息相似度、用户观点相似度、用户社交关系相似度的权重,且满足
[0045]
总体而言,通过本发明所构思的以上技术方案与现有技术相比,具有如下有益效果:
[0046]
与传统的身份关联方法相比,本发明方法采用基于深度学习的多属性相似度计算,综合考虑了用户的基础信息、用户观点信息以及用户的社交关系,能够提高身份关联的准确度,实现了目标多重虚拟身份关联。
附图说明
[0047]
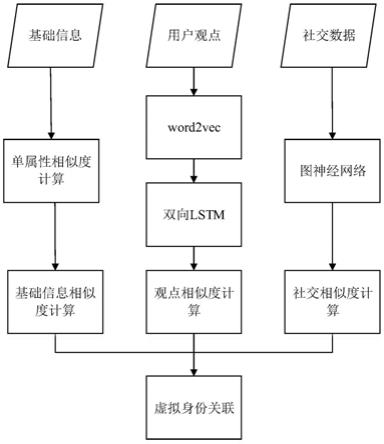
图1为本发明基于多层属性分析的跨空间目标虚拟身份关联方法的流程示意图。
具体实施方式
[0048]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
[0049]
如图1所示,本发明提供了一种基于多层属性分析的跨空间目标虚拟身份关联方法,包括以下步骤:
[0050]
步骤s1:使用赋权法计算用户基础信息相似度,用户基础信息包括用户名、性别、地址、年龄等信息;
[0051]
步骤s1包括:用户的基础信息包括用户名、性别、年龄、地址等基础身份信息,通常以(属性,值)的形式存在,用户i的属性信息可以表示为其中每个用户包含l个属性。首先,针对a、b两个用户分别计算其每个属性的相似度首先,进行属性相似度计算,针对不同类型的属性,分别采用不同方式计算其相似性。针对数值型属性,采用数值匹配方式计算其相似度,如性别“男”与性别“女”相似度为0,性别“男”与性别“男”相似度为1。针对字符型属性,如用户名等,采用levenshein距离计算其相似度。则用户各属性相似度可表示为采用熵权法计算各属性的权重w
k
,用户的基础信息相似度可表示为:
[0052]
步骤s2:运用双向长短期记忆网络(lstm,long short
‑
term memory)模型计算用户观点相似度,用户观点隐藏于用户发布的文本中;
[0053]
步骤s2包括:
[0054]
已知包含用户观点的社交平台词汇数据库集合为w=(w1,w2,
…
,w
n
},其中,n表示词汇库中的词语数目。选择包含用户观点的文本t进行分词,得到文本t的one
‑
hot编码c
t
={c1,c2,
…
,c
t
,
…
,
…
c
n
}。运用word2vec方法得到第t个词语的嵌入向量v
t
。运用特征抽取方法对文本进行特征抽取,得到个词语的特征向量将词语i的嵌入向量和特征向量进行拼接得到其局部特征
[0055]
将文本的局部特征输入双向lstm以得到文本的整体特征,其中,前向lstm更新过程如下:
[0056][0057]
f_i
t
=σ(w
xi
x
t
w
hi
f_h
t
‑1 w
ci
f_c
t
‑1 b
i
)
[0058]
f_f
t
=σ(w
xf
x
t
w
hf
f_h
t
‑1 w
cf
f_c
t
‑1 b
f
)
[0059]
[0060]
f_o
t
=σ(w
xo
x
t
w
ho
f_h
t
‑1 w
co
f_c
t
‑1 b
o
)
[0061][0062]
式中,σ表示sigmoid函数,f_i
t
、f_i
t
、f_o
t
分别表示输入门、遗忘门和输出门,w表示权重矩阵,b
i
、b
f
、b
o
、b
g
表示偏置项,f_c
t
‑1、f_c
t
分别表示t
‑
1、t个单元的细胞状态,f_h
t
表示第t个单元的输出。
[0063]
反向lstm的更新过程与前向lstm更新过程相似,反向lstm第t个单元的输出以及细胞状态分别为b_h
t
、b_c
t
。将前向lstm与反向lstm的细胞状态及输出进行融合得到第t个词语的特征向量f
t
=[f_h
t
,f_c
t
,b_h
t
,b_c
t
],整个文本的输出特征为f={f1,f2,
…
,f
t
,
…
,f
n
};
[0064]
然后,采用平均池化方法对lstm的输出特征进行处理得到文本的整体特征:θ=mean(f);
[0065]
设包含用户a的观点的文本为t
a
,采用上述方法提取的特征向量为θ
a
。包含用户b的观点的文本为t
b
,采用上述方法提取的特征向量为θ
b
。计算用户a、b的观点相似度:
[0066]
步骤s3:采用基于图神经网络的方法计算用户社交关系相似度,用户社交关系以用户间链接信息及互动信息表征;
[0067]
步骤s3包括:
[0068]
在基于图神经网络的社交模型中,以用户作为图节点,用户之间的关注信息、粉丝信息等社交关系以网络的边表示,用户的转发、评论、点赞、@等社交行为作为图节点的属性信息。基于用户的社交关系及社交行为构建的图神经网络为g={v,e,l
v
,l
e
},其中具体定义如下:
[0069]
(1)用户
[0070]
v={v1,v2,
……
,v
m
}表示含有m个用户的用户集合,v
i
表示其中第i个用户。
[0071]
(2)社交属性
[0072]
l
v
={l1,l2,
……
l
n
}表示用户节点特征向量集合。其中,l
i
为第i个用户节点的特征向量,表示第i个用户的社交属性信息,社交属性信息包括用户的转发、评论、点赞、@等社交行为。
[0073]
(3)社交关系
[0074]
e={l
(i,j)
|(i,j∈n}表示边集,其中l
(i,j)
表示用户i和用户j的社交关系,l
(i,j)
=1表示用户i对用户j存在关注行为,用户i是j的粉丝;l
(i,j)
=0表示用户i对用户j不存在关注行为,i不是j的粉丝。l
e
={l
(i,j)
|(i,j∈n)}表示边的特征向量的集合。
[0075]
根据上述定义构建社交图神经网络g,神经网络中节点v的状态嵌入h
v
及节点输出o
v
可分别表示为:
[0076]
h
v
=f(x
v
,x
ne|v|
,h
ne|v|
,l
co|v|
)
[0077]
o
v
=g(h
v
,x
v
)
[0078]
式中,x
v
表示节点v的特征,即用户的社交属性信息;x
ne|v|
表示节点v的邻居节点的特征;l
co|v|
表示节点v的边的特征,即用户之间的社交关系;h
ne|v|
表示节点v的邻居节点的
状态嵌入;f(
·
)表示局部聚合函数;g(
·
)表示局部输出函数。
[0079]
从训练集d1中选取训练样本输入模型,通过迭代训练学习f和g的参数,使得预测尽量接近样本h。模型训练好后,将用户a和b的数据输入模型,得到用户的嵌入向量x
a
和x
b
,计算用户社交关系相似度:
[0080][0081]
步骤s4:综合考虑用户基础信息相似度、用户观点相似度以及用户社交关系相似度,计算用户相似度;
[0082]
步骤s4包括:
[0083]
根据用户基础信息相似度用户观点相似度用户社交关系相似度计算用户a、b综合相似度
[0084][0085]
式中,w1、w2、w3分别为基础信息相似度、用户观点相似度、用户社交关系相似度的权重,且满足
[0086]
以下结合一具体实例说明本发明基于多层属性分析的跨空间目标虚拟身份关联方法,包括:
[0087]
(1)数据采集
[0088]
基于多属性的跨空间目标关联所用信息主要包括用户基础信息、用户观点信息以及用户社交信息。用户基础信息d1可以通过收集用户在各平台的注册信息获取,用户观点信息d2可以通过收集用户在社交平台上发布的文字信息获取,用户社交行为信息d3包含用户社交关系信息以及用户社交行为信息,用户社交关系信息可以通过收集用户的关注信息及粉丝信息获取,用户的社交行为信息可以通过收集用户的评论行为、点赞行为、分享行为及@等行为获取。
[0089]
(2)用户基础信息相似度计算
[0090]
用户的基础信息包括用户名、性别、年龄、地址等基础身份信息,通常以(属性,值)的形式存在,用户i的属性信息可以表示为其中每个用户包含l个属性。首先,针对a、b两个用户分别计算其每个属性的相似度首先,进行属性相似度计算,针对不同类型的属性,分别采用不同方式计算其相似性。针对数值型属性,采用数值匹配方式计算其相似度,如性别“男”与性别“女”相似度为0,性别“男”与性别“男”相似度为1。对于字符型属性,如用户名等,采用levenshein距离计算其相似度。则用户各属性相似度可表示为采用熵权法计算各属性的权重w
k
,用户的基础信息相似度可表示为:
[0091]
[0092]
(3)用户观点相似度计算
[0093]
已知包含用户观点的社交平台词汇数据库集合为w=(w1,w2,
…
,w
n
},其中,n表示词汇库中的词语数目。从d2中选择包含用户观点的文本t进行分词,得到文本t的one
‑
hot编码c
t
={c1,c2,
…
,c
t
,
…
,
…
c
n
}。运用word2vec方法得到第t个词语的嵌入向量:
[0094]
v
t
=w
word
c
t
[0095]
式中,w
word
表示词向量矩阵词语文本t的嵌入向量v
t
=(v1,v2,
…
,v
i
,
…
,
…
,v
n
)。其中,v
i
∈r1×
k
表示第i个词语的嵌入向量,k表示嵌入向量特征维数。例:词汇库为[小张,小李,喜欢,吃,苹果,橘子],文本“小张喜欢吃苹果”分词结果为[小张,喜欢,吃,苹果],其嵌入向量为(v1,v2,v3,v4)。
[0096]
对文本t进行预处理和特征抽取,抽取的特征包括位置特征,词性标注特征,名实体标注特征、依赖关系特征、上下位标志特征等k类特征,对各文本特征进行向量化处理得到第t个词语的特征向量:
[0097][0098]
式中,表示第i个特征的特征向量矩阵,将词语i的嵌入向量和特征向量进行拼接得到其局部特征
[0099]
将文本的局部特征输入双向lstm以得到文本的整体特征,其中,前向lstm更新过程如下:
[0100][0101]
f_i
t
=σ(w
xi
x
t
w
hi
f_h
t
‑1 w
ci
f_c
t
‑1 b
i
)
[0102]
f_f
t
=σ(w
xf
x
t
w
hf
f_h
t
‑1 w
cf
f_c
t
‑1 b
f
)
[0103][0104]
f_o
t
=σ(w
xo
x
t
w
ho
f_h
t
‑1 w
co
f_c
t
‑1 b
o
)
[0105][0106]
式中,σ表示sigmoid函数,f_i
t
、f_i
t
、f_o
t
分别表示输入门、遗忘门和输出门,w表示权重矩阵,b
i
、b
f
、b
o
、b
g
表示偏置项,f_c
t
‑1、f_c
t
分别表示t
‑
1、t个单元的细胞状态,f_h
t
表示第t个单元的输出。
[0107]
反向lstm的更新过程与前向lstm更新过程相似,反向lstm第t个单元的输出以及细胞状态分别为b_h
t
、b_c
t
。将前向lstm与反向lstm的细胞状态及输出进行融合得到第t个词语的特征向量f
t
=[f_h
t
,f_c
t
,b_h
t
,b_c
t
],整个文本的输出特征为f={f1,f2,
…
,f
t
,
…
,f
n
}。
[0108]
然后,采用平均池化方法对lstm的输出特征进行处理得到文本的整体特征:
[0109]
θ=mean(f)
[0110]
设包含用户a的观点的文本为t
a
,采用上述方法提取的特征向量为θ
a
。包含用户b的观点的文本为t
b
,采用上述方法提取的特征向量为θ
b
。计算用户a、b的观点相似度:
[0111]
[0112]
(4)用户社交关系相似度计算
[0113]
利用d3中用户关注信息、粉丝信息、用户点赞行为、评论行为、转发及@等行为构建用户社交关系数据集d。从d中随机选取30%数据作为训练集d1,其余数据作为测试集d2。
[0114]
在基于图神经网络的社交模型中,以用户作为图节点,用户之间的关注信息、粉丝信息等社交关系以网络的边表示,用户的转发、评论、点赞、@等社交行为作为图节点的属性信息。基于用户的社交关系及社交行为构建的图神经网络为g={v,e,l
v
,l
e
},其中具体定义如下:
[0115]
(4.1)用户
[0116]
v={v1,v2,
……
,v
m
}表示含有m个用户的用户集合,v
i
表示其中第i个用户。
[0117]
(4.2)社交属性
[0118]
l
v
={l1,l2,
……
l
n
}表示用户节点特征向量集合。其中,l
i
为第i个用户节点的特征向量,表示第i个用户的社交属性信息,社交属性信息包括用户的转发、评论、点赞、@等社交行为。
[0119]
(4.3)社交关系
[0120]
e={l
(i,j)
|(i,j∈n}表示边集,其中l
(i,j)
表示用户i和用户j的社交关系,l
(i,j)
=1表示用户i对用户j存在关注行为,用户i是j的粉丝;l
(i,j)
=0表示用户i对用户j不存在关注行为,i不是j的粉丝。l
e
={l
(i,j)
|(i,j∈n)}表示边的特征向量的集合。
[0121]
根据上述定义构建社交图神经网络g,神经网络中节点v的状态嵌入h
v
及节点输出o
v
可分别表示为:
[0122]
h
v
=f(x
v
,x
ne|v|
,h
ne|v|
,l
co|v|
)
[0123]
o
v
=g(h
v
,x
v
)
[0124]
式中,x
v
表示节点v的特征,即用户的社交属性信息;x
ne|v|
表示节点v的邻居节点的特征;l
co|v|
表示节点v的边的特征,即用户之间的社交关系;h
ne|v|
表示节点v的邻居节点的状态嵌入;f(
·
)表示局部聚合函数;g(
·
)表示局部输出函数。
[0125]
从训练集d1中选取训练样本输入模型,通过迭代训练学习f和g的参数,使得预测尽量接近样本h。模型训练好后,将用户a和b的数据输入模型,得到用户的嵌入向量x
a
和x
b
,计算用户社交关系相似度:
[0126][0127]
(5)用户相似度计算
[0128]
根据用户基础信息相似度用户观点相似度用户社交关系相似度综合计算用户a、b相似度:
[0129][0130]
式中,w1、w2、w3分别为基础信息相似度、用户观点相似度、用户社交关系相似度的权重,且满足
[0131]
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。