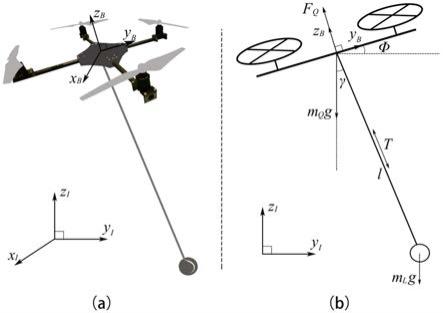
suspended load;页码:4902
–
4909)。aleksandra faust等人进一步优化了上述的学习算法,扩充了轨迹的样本空间,提出了一种在有静态障碍的环境中进行货物运输的强化学习方法(期刊:artificial intelligence;著者:aleksandra faust,ivana palunko,patricio cruz,rafael fierro,and lydia tapia;出版年月:2017;文章题目:automated aerial suspended cargo delivery through reinforcement learning;页码:381
–
398)。伊达尔戈州自治大学的ricardo a.barr
ó
n
‑
g
ó
mez等人提出了一种新型无模型自适应小波网络pid(adaptive wave
‑
net pid,awpid)控制器,实现了无人机位置跟踪与负载减摆控制(会议:2017 20th world congress of the international federation of automatic control(ifac);著者:ricardo a.barr
ó
n
‑
g
ó
mez,luis e.ramos
‑
velasco,eduardo s.espinoza quesada,and luis r.garc
í
a carrillo;出版年月:2017;文章题目:wavelet neural network pid controller for a uas transporting a cable
‑
suspended load;页码:2335
–
2340)。中国石油大学(华东)的cai luo等人设计了一种基于径向基函数神经网络(radial basis function neural network,rbfnn)的非线性反步滑模控制器,该控制器能够对多时变不确定性和干扰进行补偿(期刊:electronics;著者:cai luo,zhenpeng du,and leijian yu;出版年月:2019;文章题目:neural network control design for an unmanned aerial vehicle with a suspended payload;页码:931)。天津大学的韩晓薇等人利用基于能量整形的控制方法构造了一种新型的能量存储函数以处理状态耦合,然后利用神经网络对系统未建模动态特性进行在线估计,并采用基于符号函数的鲁棒控制算法补偿神经网络的估计误差(期刊:控制理论与应用;著者:韩晓薇,鲜斌,杨森;出版年月:2020;文章题目:无人机吊挂空运系统的自适应控制设计;页码:999
–
1006)。
4.基于以上分析可得,现有针对四旋翼无人机吊挂系统的研究结果主要是基于时间驱动的设计,如果需要在机载处理器上在线实时训练神经网络,随着网络层数增加,不可避免地会遇到计算负担过重的问题。为了满足复杂环境下的不同需求,解决人工神经网络在机载处理器上在线学习训练的计算过载问题,除了升级机载处理器这种硬件方法外,进行时间/事件转换以实现事件驱动的软件设计已经成为反馈控制社区的一条新途径。在事件驱动方法的一般框架下,人工神经网络或者控制器仅在满足一定条件时进行更新,在保证控制性能良好的前提下实现网络或者控制器输出的稳定及高效率。密苏里科技大学的avimanyu sahoo等人提出了一种基于多输入多输出未知非线性连续时间仿射系统的事件触发控制方法(期刊:ieee transactions on neural networks and learning systems;著者:avimanyu sahoo,hao xu,and sarangapani jagannathan;出版年月:2016;文章题目:neural network
‑
based event
‑
triggered state feedback control of nonlinear continuous
‑
time systems;页码:497
–
509)。在新框架下,设计的控制器仅在事件触发时进行更新,从而减少了神经网络学习和自适应最优控制两个过程的计算负担。注意到,要求具有初始稳定条件在一定程度上限制了基于事件驱动设计的应用。为此,利用神经网络逼近策略推导出基于事件的非线性折现最优控制律,可以不依赖于特殊的初始条件。
技术实现要素:
5.为克服现有技术的不足,本发明旨在针对吊挂系统空运过程中减小吊挂负载摆动以及降低机载处理器计算负担的需求,提出一种在线轨迹规划方法。在基于事件驱动的前
提下,本发明引入折现代价函数和强化学习机制,将吊挂系统负载摆角的动力学方程转换成非线性仿射系统的形式,在此基础上通过神经网络逼近的方法来求解负载摆角抑制的最优控制问题。本发明采用的技术方案是,基于事件驱动的无人机吊挂系统在线轨迹规划方法,步骤如下:
6.步骤1)确定四旋翼无人机吊挂系统的坐标系定义;
7.四旋翼无人机吊挂系统坐标系定义:{i}={x
i
,y
i
,z
i
}表示固定在大地的惯性坐标系,{b}={x
b
,y
b
,z
b
}表示无人机的机体坐标系,x
i
、y
i
、z
i
(i=i,b)分别对应坐标系三个主轴方向的单位矢量。图1(b)为此系统的二维模型,本发明主要考虑四旋翼无人机吊挂系统在惯性坐标系{i}下y、z方向上的位置状态以及负载摆角及角速度映射在y、z平面上的状态。
8.步骤2)确定四旋翼无人机吊挂系统的动力学模型;
9.通过分析四旋翼无人机吊挂系统的二维模型:采用欧拉
‑
拉格朗日方法对系统进行建模,通过计算可以得到系统的动力学表达式如下
[0010][0011]
其中,表示系统的状态向量,y(t)、z(t)分别表示四旋翼无人机在y、z方向的位移,γ(t)表示负载摆角在y、z平面上的分量。f
q
=[f
y
,f
z
,0]表示系统的控制输入,f
y
、f
z
分别表示无人机在y、z方向的升力。f
d
=[d
y
,d
z
,d
γ
]表示系统受到的未知外界扰动,d
y
、d
z
、d
γ
分别表示系统受到的外界扰动在y、z、γ方向的分量。m(q)、分别表示系统受到的外界扰动在y、z、γ方向的分量。m(q)、分别表示四旋翼无人机吊挂系统的惯性矩阵、向心力矩阵以及重力向量,表示实数域。式(1)中m(q)的表达式为
[0012][0013]
的表达式为
[0014][0015]
g(q)的表达式为
[0016]
g(q)=[0(m
l
m
q
)g m
l
glsinγ]
t
ꢀꢀꢀ
(4)
[0017]
其中,表示吊挂负载质量,表示无人机质量,表示绳长。
[0018]
步骤3)定义系统折现代价函数和最优控制律;
[0019]
将式(1)展开可得负载摆动运动的动力学方程如下
[0020][0021]
输入仿射形式的动力系统在文献和工程中是常见的,将上式整理为如下的连续时间非线性仿射系统形式
[0022][0023]
其中,为等效状态向量,
为非线性仿射系统的等效输入。在上式中f(x)的表达式为
[0024][0025]
g(x)的表达式为
[0026][0027]
f(
·
)与g(
·
)满足局部李普希兹(lipschitz)连续条件。设t=0时,x(0)=x0,且x=0为系统平衡点,此时f(0)=0。在最优调节设计中,针对特定的代价函数来设计状态反馈控制律u(t)。选取为正定常数矩阵,为hermite正定常数阵,定义函数r(x(τ),u(τ))如下
[0028]
r(x(τ),u(τ))=x
t
(τ)qx(τ) u
t
(τ)ru(τ)
ꢀꢀꢀ
(9)
[0029]
定义折现代价函数v(x(t),u(t))如下
[0030][0031]
其中,η>0为折现因子,用来调节收敛速率,e为自然常数。后文v(x(t),u(t))简写为v(x(t))或者v(x)。对于控制输入u(t),若代价函数连续且可微,则
[0032][0033]
经过适当的数学变换,可获得上式中非线性lyapunov方程的无穷小形式如下式所示
[0034][0035]
其中,定义系统(6)的哈密尔顿量为
[0036][0037]
据贝尔曼最优准则,最优代价函数v
*
(x)的表达式为
[0038][0039]
上式满足hamilton jacobi bellman方程,即将最优控制律u
*
(x)设计为
[0040][0041]
根据以上最优控制律,上述的hjb方程可改写为
[0042][0043]
因为r为hermite正定阵,满足(r
‑1)
t
=r
‑1,上式可化为
[0044][0045]
上式为基于时间的经典hjb方程,即在此基础上,下文给出基于事件驱动的自适应评价网设计。
[0046]
步骤4)设计事件驱动机制;
[0047]
定义一个单调递增的触发序列s
i
为i∈n的第i个连续采样时刻,采样输出为采样状态的一个序列。对于所有t∈[s
i
,s
i 1
]有定义事件驱动的误差函数为
[0048][0049]
当t=s
i
时,e
i
(t)=0。在每个触发时刻,系统状态是采样的,e
i
(t)复位为0,反馈控制律
[0050]
得到更新。控制序列通过零阶保持器可成为一个分段的连续时间信号。
[0051]
将上述事件触发机制与式(15)中的最优控制律设计相结合,可得如下的控制设计
[0052][0053]
其中,上式的为下文设计目标。
[0054]
步骤5)设计自适应评价网络;
[0055]
据神经网络的逼近策略,最优代价函数v
*
(x)可重构为
[0056][0057]
其中,为理想权值向量,为激活函数,为重构误差,n
c
为隐含层中神经元的数量。可得上式的梯度向量为
[0058][0059]
因为ω
c
未知,采用评价网逼近上述重构后的最优代价函数,可得近似最优代价函数为
[0060][0061]
其中,为估计权值向量,可得
[0062][0063]
采用逼近策略重构,式(20)可改写为
[0064][0065]
采用评价网逼近上述表达式可得基于事件驱动的近似最优控制律为
[0066][0067]
由以上可得近似哈密尔顿量为
[0068][0069]
考虑到定义
[0070][0071]
将上式中的e
c
(t)对的偏导数定义为ρ(t),即其中,可以求得如下等式
[0072][0073]
迭代更新评价网权值使得目标函数最小化。这里采用归一化梯度下降算法,可得评价网络输出权值的更新率为
[0074][0075]
其中,α
c
>0为设计的评价网学习率增益。
[0076]
在传统的自适应评价网设计中,应该选择一种特殊的权值向量来创建初始的稳定控制器,然后再开始训练神经网络,否则可能会导致闭环系统不稳定。为避免以上情况,引入一个额外的lyapunov候选函数v
s
(x)来改进评价网的学习准则,并利用它来调节评价网的权值向量。令v
s
(x)为保证时间导数为负的连续可微lyapunov候选函数,即
[0077][0078]
据状态向量选择多项式来确定v
s
(x),可选取v
s
(x)=(1/2)x
t
x。
[0079]
当使用式(20)中的基于事件驱动的最优控制律时,为使系统稳定,即需要引入一个额外的项通过沿着的负梯度方向调整来加强训练过程。为此,据式(26)中的基于事件驱动的近似最优控制律,可利用链式法则得到以下梯度下降运算
[0080][0081]
其中,α
s
>0为正常数。综上所述,评价网输出权值更新率由两部分组成,即
[0082][0083]
可得本发明的评价网输出权值更新率为
[0084]
[0085]
定义评价网输出权值的估计误差为
[0086]
为使评价网输出权值估计误差一致最终有界,针对系统状态,需要选取适当的采样频率来获得采样输出作为评价网络的输入,使得||e
i
(t)||2满足下式
[0087][0088]
上式定义为事件驱动的触发条件,其中,ψ为正常数,φ∈(0,1)是设计的参数,常量ξ=||θ||2||r
‑1||2,正定矩阵满足r=θ
t
θ。
[0089]
步骤6)轨迹规划设计;
[0090]
定义四旋翼无人机规划的期望轨迹与标称轨迹的误差信号如下
[0091][0092]
本发明的四旋翼无人机期望轨迹的加速度与设计为如下形式
[0093][0094]
上式中的为减摆设计,与为保证系统稳定的辅助函数,k
γ
、、、及为正常数增益。标称轨迹与保证了四旋翼无人机能准确到达目标位置,标称轨迹要满足如下条件:(1)y
t
(t)、z
t
(t)在有限时间收敛到目标位置。(2)y
t
(t)、z
t
(t)的一二阶导数均能随时间收敛到0,且二阶导数的绝对值与一阶导数均是有上界的正实数。(3)初始值应满足当t=0时,y
t
(t)、z
t
(t)及其一阶导数均为0。
[0095]
本发明选用如下的s形曲线作为标称轨迹
[0096][0097]
其中c
y
、c
z
、n
y
、n
z
、υ、p
y
及p
z
为设计的正常数。
[0098]
步骤7)位置跟踪控制律设计;
[0099]
为使吊挂系统沿着规划的期望轨迹运动,定义四旋翼无人机实时位置与规划的轨迹之间的误差如下
[0100][0101]
选取如下的类pd控制器作为轨迹跟踪控制器
[0102][0103]
其中,其中,其中,及为pd控制器的控制增益,均为正常数。与表示四旋翼无人机在y和z方向上的实时速度分量。
[0104]
以上述控制律使四旋翼无人机吊挂系统跟踪本发明设计的期望轨迹,可以利用基于lyapunov的稳定性分析方法可以得到以下结论:本发明所设计的在线轨迹规划方法可以保证四旋翼无人机y、z方向的位置、速度、负载摆角以及摆角角速度收敛到一定区域内。
[0105]
本发明的特点及有益效果是:
[0106]
1.四旋翼无人机吊挂系统具有欠驱动、强耦合、非线性等特性,本发明针对非线性动态模型未做过多假设以及线性化处理,与实际系统的动态特性较为相符;
[0107]
2.本发明应用了事件触发机制,显著降低了无人机机载处理器处理神经网络学习和自适应最优控制两个过程的计算负担。这为在四旋翼无人机机载处理器上在线训练人工神经网络提供了一种新的手段;
[0108]
3.本发明利用lyapunov稳定性分析方法证明了评价网络输出权值估计误差一致最终有界,并证明了无人机位置误差和负载摆动的收敛;
[0109]
4.本发明通过实际飞行实验,对提出的在线轨迹规划方法进行了验证,并且与点对点的pd跟踪控制方法进行了对比,实验结果表明本发明设计的基于事件驱动的在线轨迹规划方法具有更好的减摆效果以及良好的定位性能。
附图说明:
[0110]
图1是本发明采用的四旋翼无人机吊挂系统模型示意图;
[0111]
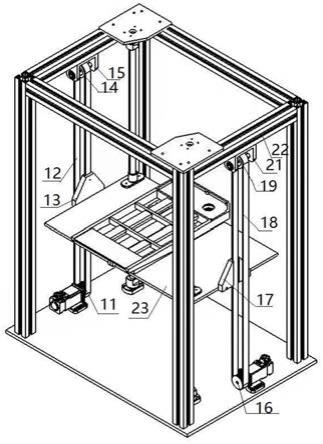
图2是本发明所使用的四旋翼无人机吊挂系统实验平台;
[0112]
图3是位置跟踪控制实验时无人机位置信息的更新曲线图;
[0113]
图4是位置跟踪控制实验时无人机控制输入的更新曲线图;
[0114]
图5是位置跟踪控制实验时无人机负载摆角的更新曲线图;
[0115]
图6是位置跟踪控制实验时自适应神经网络输入输出的更新曲线图;
[0116]
图7是位置跟踪控制实验时神经网络学习过程触发条件的更新曲线图;
[0117]
图8是位置跟踪控制实验时神经网络输出权值的更新曲线图。
具体实施方式
[0118]
本发明在基于事件驱动的前提下,引入折现代价函数和强化学习机制,提出了一种新型的四旋翼无人机吊挂系统在线轨迹规划方法。本发明将吊挂系统负载摆角的动力学方程转换成非线性仿射系统的形式,在此基础上通过神经网络逼近的方法来求解负载摆角抑制的最优控制问题。在存在外界未知扰动的情况下,本发明利用负载摆角的反馈作为人工神经网络的输入,通过在线训练神经网络获得输出作为轨迹规划部分的补偿。本发明采用的技术方案是,基于事件驱动的无人机吊挂系统在线轨迹规划方法,步骤如下:
[0119]
步骤1)确定四旋翼无人机吊挂系统的坐标系定义;
[0120]
四旋翼无人机吊挂系统坐标系定义如图1所示,图1(a)为系统三维模型示意图,其
中{i}={x
i
,y
i
,z
i
}表示固定在大地的惯性坐标系,{b}={x
b
,y
b
,z
b
}表示无人机的机体坐标系,x
i
、y
i
、z
i
(i=i,b)分别对应坐标系三个主轴方向的单位矢量。图1(b)为此系统的二维模型,本发明主要考虑四旋翼无人机吊挂系统在惯性坐标系{i}下y、z方向上的位置状态以及负载摆角及角速度映射在y、z平面上的状态。
[0121]
步骤2)确定四旋翼无人机吊挂系统的动力学模型;
[0122]
通过分析四旋翼无人机吊挂系统的二维模型如图1(b)所示。采用欧拉
‑
拉格朗日方法对系统进行建模,通过计算可以得到系统的动力学表达式如下
[0123][0124]
其中,表示系统的状态向量,y(t)、z(t)分别表示四旋翼无人机在y、z方向的位移,γ(t)表示负载摆角在y、z平面上的分量。f
q
=[f
y
,f
z
,0]表示系统的控制输入,f
y
、f
z
分别表示无人机在y、z方向的升力。f
d
=[d
y
,d
z
,d
γ
]表示系统受到的未知外界扰动,d
y
、d
z
、d
γ
分别表示系统受到的外界扰动在y、z、γ方向的分量。m(q)、分别表示系统受到的外界扰动在y、z、γ方向的分量。m(q)、分别表示四旋翼无人机吊挂系统的惯性矩阵、向心力矩阵以及重力向量,表示实数域。式(1)中m(q)的表达式为
[0125][0126]
的表达式为
[0127][0128]
g(q)的表达式为
[0129]
g(q)=[0(m
l
m
q
)g m
l
glsinγ]
t
ꢀꢀꢀꢀꢀ
(4)
[0130]
其中,表示吊挂负载质量,表示无人机质量,表示绳长。
[0131]
步骤3)定义系统折现代价函数和最优控制律;
[0132]
将式(1)展开可得负载摆动运动的动力学方程如下
[0133][0134]
输入仿射形式的动力系统在文献和工程中是常见的,将上式整理为如下的连续时间非线性仿射系统形式
[0135][0136]
其中,为等效状态向量,为非线性仿射系统的等效输入。在上式中f(x)的表达式为
[0137]
[0138]
g(x)的表达式为
[0139][0140]
f(
·
)与g(
·
)满足局部李普希兹(lipschitz)连续条件。设t=0时,x(0)=x0,且x=0为系统平衡点,此时f(0)=0。在最优调节设计中,针对特定的代价函数来设计状态反馈控制律u(t)。选取为正定常数矩阵,为hermite正定常数阵,定义函数r(x(τ),u(τ))如下
[0141]
r(x(τ),u(τ))=x
t
(τ)qx(τ) u
t
(τ)ru(τ)
ꢀꢀꢀ
(9)
[0142]
定义折现代价函数v(x(t),u(t))如下
[0143][0144]
其中,η>0为折现因子,用来调节收敛速率,e为自然常数。后文v(x(t),u(t))简写为v(x(t))或者v(x)。对于控制输入u(t),若代价函数连续且可微,则
[0145][0146]
经过适当的数学变换,可获得上式中非线性lyapunov方程的无穷小形式如下式所示
[0147][0148]
其中,定义系统(6)的哈密尔顿量为
[0149][0150]
据贝尔曼最优准则,最优代价函数v
*
(x)的表达式为
[0151][0152]
上式满足hamilton jacobi bellman方程,即将最优控制律u
*
(x)设计为
[0153][0154]
根据以上最优控制律,上述的hjb方程可改写为
[0155][0156]
因为r为hermite正定阵,满足(r
‑1)
t
=r
‑1,上式可化为
[0157][0158]
上式为基于时间的经典hjb方程,即在此基础上,下文给出基于事件驱动的自适应评价网设计。
[0159]
步骤4)设计事件驱动机制;
[0160]
定义一个单调递增的触发序列s
i
为i∈n的第i个连续采样时刻,采样输出为采样状态的一个序列。对于所有t∈[s
i
,s
i 1
]有定义事件驱动的误差函数为
[0161][0162]
当t=s
i
时,e
i
(t)=0。在每个触发时刻,系统状态是采样的,e
i
(t)复位为0,反馈控制律
[0163]
得到更新。控制序列通过零阶保持器可成为一个分段的连续时间信号。
[0164]
将上述事件触发机制与式(15)中的最优控制律设计相结合,可得如下的控制设计
[0165][0166]
其中,上式的为下文设计目标。
[0167]
步骤5)设计自适应评价网络;
[0168]
据神经网络的逼近策略,最优代价函数v
*
(x)可重构为
[0169][0170]
其中,为理想权值向量,为激活函数,为重构误差,nc为隐含层中神经元的数量。可得上式的梯度向量为
[0171][0172]
因为ω
c
未知,采用评价网逼近上述重构后的最优代价函数,可得近似最优代价函数为
[0173][0174]
其中,为估计权值向量,可得
[0175][0176]
采用逼近策略重构,式(20)可改写为
[0177][0178]
采用评价网逼近上述表达式可得基于事件驱动的近似最优控制律为
[0179][0180]
由以上可得近似哈密尔顿量为
[0181][0182]
考虑到定义
[0183][0184]
将上式中的e
c
(t)对的偏导数定义为ρ(t),即其中,可以求得如下等式
[0185][0186]
迭代更新评价网权值使得目标函数最小化。这里采用归一化梯度下降算法,可得评价网络输出权值的更新率为
[0187][0188]
其中,α
c
>0为设计的评价网学习率增益。
[0189]
在传统的自适应评价网设计中,应该选择一种特殊的权值向量来创建初始的稳定控制器,然后再开始训练神经网络,否则可能会导致闭环系统不稳定。为避免以上情况,引入一个额外的lyapunov候选函数v
s
(x)来改进评价网的学习准则,并利用它来调节评价网的权值向量。令v
s
(x)为保证时间导数为负的连续可微lyapunov候选函数,即
[0190][0191]
据状态向量选择多项式来确定v
s
(x),可选取v
s
(x)=(1/2)x
t
x。
[0192]
当使用式(20)中的基于事件驱动的最优控制律时,为使系统稳定,即需要引入一个额外的项通过沿着的负梯度方向调整来加强训练过程。为此,据式(26)中的基于事件驱动的近似最优控制律,可利用链式法则得到以下梯度下降运算
[0193][0194]
其中,α
s
>0为正常数。综上所述,评价网输出权值更新率由两部分组成,即
[0195][0196]
可得本发明的评价网输出权值更新率为
[0197][0198]
定义评价网输出权值的估计误差为
[0199]
为使评价网输出权值估计误差一致最终有界,针对系统状态,需要选取适当的采样频率来获得采样输出作为评价网络的输入,使得||e
i
(t)||2满足下式
[0200][0201]
上式定义为事件驱动的触发条件,其中,ψ为正常数,φ∈(0,1)是设计的参数,常量ξ=||θ||2||r
‑1||2,正定矩阵满足r=θ
t
θ。
[0202]
步骤6)轨迹规划设计;
[0203]
定义四旋翼无人机规划的期望轨迹与标称轨迹的误差信号如下
[0204][0205]
本发明的四旋翼无人机期望轨迹的加速度与设计为如下形式
[0206][0207]
上式中的为减摆设计,与为保证系统稳定的辅助函数,k
γ
、、、及为正常数增益。标称轨迹与保证了四旋翼无人机能准确到达目标位置,标称轨迹要满足如下条件:(1)y
t
(t)、z
t
(t)在有限时间收敛到目标位置。(2)y
t
(t)、z
t
(t)的一二阶导数均能随时间收敛到0,且二阶导数的绝对值与一阶导数均是有上界的正实数。(3)初始值应满足当t=0时,y
t
(t)、z
t
(t)及其一阶导数均为0。
[0208]
本发明选用如下的s形曲线作为标称轨迹
[0209][0210]
其中c
y
、c
z
、n
y
、n
z
、v、p
y
及p
z
为设计的正常数。
[0211]
步骤7)位置跟踪控制律设计;
[0212]
为使吊挂系统沿着规划的期望轨迹运动,定义四旋翼无人机实时位置与规划的轨迹之间的误差如下
[0213][0214]
选取如下的类pd控制器作为轨迹跟踪控制器
[0215][0216]
其中,其中,其中,及为pd控制器的控制增益,均为正常数。与表示四旋翼无人机在y和z方向上的实时速度分量。
[0217]
以上述控制律使四旋翼无人机吊挂系统跟踪本发明设计的期望轨迹,可以利用基于lyapunov的稳定性分析方法可以得到以下结论:本发明所设计的在线轨迹规划方法可以保证四旋翼无人机y、z方向的位置、速度、负载摆角以及摆角角速度收敛到一定区域内。
[0218]
以下结合具体实例以及附图对本发明做出详细说明。
[0219]
一、实验平台介绍
[0220]
为为了验证本发明设计的基于事件驱动的四旋翼无人机吊挂空运系统在线轨迹规划方法的实际效果,本发明采用如图2所示的实验平台进行了飞行实验。实验平台由两部分组成:(1)运动捕捉系统,系统能够实时采集无人机及吊挂负载的位置信息;(2)自主开发的四旋翼无人机吊挂系统,无人机机载处理器接收来自运动捕捉系统提供的位置信息。
[0221]
实验平台的相关参数为:mq=1.008kg,mp=0.076kg,l=1.05m及g=9.81m/s2。
[0222]
二、实验验证与分析
[0223]
采用本发明设计的在线轨迹规划方法与不加轨迹规划的点对点的pd跟踪控制方法作对比,在上述的实验平台上进行了一组对比实验。不加轨迹规划的点对点pd跟踪控制方法中,定义四旋翼无人机实时位置与目标位置之间的误差如下
[0224][0225]
其中,y
d
,z
d
为设定的目标位置。
[0226]
两种方法采用上述类pd控制器及其相关参数,使四旋翼无人机在吊挂负载的情况下到达目标位置。
[0227]
(1)参数选择
[0228]
在实际飞行实验中,本发明设计的基于事件驱动的近似最优控制律部分相关参数选取如下:q=diag[0.001 0.05],r=diag[0.01 0.02],v
s
(x)=(1/2)x
t
x,η=0.6,α
c
=0.1,α
s
=0.0015,n
c
=10。用作评价网输入的系统状态的采样时间为式(35)触发条件中的相关参数选取如下:φ=0.5,ψ=25。轨迹规划设计相关参数选取如下:k
11
=6.0,k
12
=5.0,k
21
6.0,k
22
=5.0,k
γ
=1.0。标称轨迹中的相关参数选取如下c
y
=1.2,c
z
=1.2,n
y
=0.48,n
z
=0.48,v=3.5,p
y
=3.0,p
z
=0.3。位置跟踪控制律中的控制增益选取如下:=0.3。位置跟踪控制律中的控制增益选取如下:四旋翼无人机的起始位置和目标位置分别设置为:y0=0m,z0=
‑
1.75m与y
d
=3m,z
d
=
‑
1.45m。
[0229]
(2)结果分析
[0230]
飞行实验中,定义当四旋翼无人机到达目标位置并保持在规定误差带(目标位置的5%)内时,系统进入稳态。定义调节时间为四旋翼无人机进入稳态所需的最短时间。通过对图3以及图5的动态过程进行具体分析,可得到表1,表1是在线轨迹规划方法和点对点的pd跟踪控制方法下系统调节时间的对比结果。通过分析可知,两种方法下,四旋翼无人机在y、z方向位移的调节时间相近,无人机均能较平滑的到达目标位置。但是比较负载摆角的调节时间,在线轨迹规划方法明显优于点对点的pd跟踪控制方法,并且从图5中可知,在线轨迹规划方法下,负载摆角的振荡幅值以及振荡次数均远小于点对点的pd跟踪控制方法下的摆角幅值与次数。根据图4可知,对于控制输入u
y
(t),从动态调节过程来看,在线轨迹规划方法控制器的输出相比较点对点的pd跟踪控制方法控制器的输出平缓许多。总的来说,动
态过程中,在四旋翼无人机位移方面,两种方法的效果相近,但在负载摆角方面,在线轨迹规划方法的减摆效果明显优于点对点的pd跟踪控制方法。
[0231]
对图3以及图5中的状态量的稳态过程进行定量分析,选取各个状态量进入稳态后的数据,分别对图中各个量求取了平均绝对误差(mean absolute error,mae),均方根误差(mean square error,mse)。表3,表4分别是在线轨迹规划方法和点对点的pd跟踪控制方法稳态后的平均绝对误差和均方根误差的对比。对于无人机y方向位移y(t),在线轨迹规划方法的平均绝对误差以及均方根误差略小于点对点的pd跟踪控制方法;对于无人机z方向位移z(t)以及负载摆角γ(t),两种方法的平均绝对误差以及均方根误差相近。总的来看,两种方法下吊挂系统的稳态性能均相近。图4中控制输入量u
y
(t)、u
z
(t)的稳态性能和y、z方向的位移y(t)、z(t)的稳态性能对应,合理地解释了y、z方向的位移y(t)、z(t)的变化曲线,间接体现了在线轨迹规划方法对负载优良的减摆性能。
[0232]
表2:调节时间比较
[0233]
调节时间/s在线轨迹规划方法点对点的pd跟踪控制方法t
sy
9.5938.250t
sz
6.7826.302t
sγ
7.54328.416
[0234]
表3:稳态平均绝对误差(mae)比较
[0235]
mae/m在线轨迹规划方法点对点的pd跟踪控制方法y0.01160.0213z0.00790.0073γ0.71540.7264
[0236]
表4:稳态均方根误差(rmse)比较
[0237]
rmse/m在线轨迹规划方法点对点的pd跟踪控制方法y0.02280.0300z0.00930.0089γ0.86880.8926
[0238]
当权衡控制精度和计算复杂度时,通过反复实验得到基于事件触发的评价网络的更新频率取20hz时控制效果较好,此时评价网络输入的系统状态的采样时间为网络学习过程的触发条件和神经网络的实际输入分别如图6和图7所示。图6表示在实际飞行过程中,为避免小角度摆动过于频繁造成的影响,在满足评价网络输入持续激励条件前提下对神经网络的输入γ(t)做了处理,即降低了摆角绝对值在0.04rad以内的输入值的幅值。图7表明经过以上处理后,学习过程始终满足式(35)中的触发条件,即||e
i
(t)||2/e
t
的值小于1。
[0239]
如图8所示,评价网的输出权值向量最终收敛。从图中可以发现,权值向量的初始值都被设为零,说明初始控制律不需要是稳定的。可以观察到输出权值向量的收敛发生在t=7.64s,之后系统进入了小角度摆动状态。
[0240]
本发明设计的创新之处除了上述对负载优良的减摆性能外,还有如下一点:在达到相同控制效果的前提下,与基于时间的评价网络相比较,基于事件触发的评价网络有着
更低的更新频率,为此降低了无人机机载处理器的运算负担。原因在于,在只涉及无人机外环控制的轨迹规划中,为达到良好的位置跟踪效果,无人机外环控制器的控制更新频率有一定的下限,并且基于时间的评价网设计普遍采用与无人机外环控制器相同的更新频率。在本发明实验中,无人机采用的外环控制器的控制更新频率不低于50hz,这就要求机载处理器具有较强的运算能力能够处理基于时间的评价网的迭代更新。为解决机载处理器算力不足的问题,本发明设计的基于事件触发机制的在线轨迹规划方法,能在保证系统稳定性以及位置跟踪效果的前提下,将评价网络的更新频率降低至20hz,这显著降低了机载处理器在处理评价网络的迭代更新时的计算消耗。
[0241]
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。