1.本发明涉及数据处理技术领域,具体涉及一种基于词频打分算法获取法律文书案件地点的方法。
背景技术:
2.nlp(natural language processing)即自然语言处理,是计算机科学领域与人工智能领域中的一个重要方向,它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。
3.在我国司法公开的大背景下,对于法律文书的研究成为了学界业界十分重要的一个课题,而对于文书中提到的案件发生的地理位置也是一个十分重要的变量,其可以用来分析区域民事纠纷、犯罪地点的分布情况。但是由于自然语言规律比较庞杂,单纯使用传统的正则提取十分困难。
技术实现要素:
4.针对现有技术的不足,本发明旨在提供一种基于词频打分算法获取法律文书案件地点的方法,使用词频融合的算法来来进行文本提取,解决信息提取不准确的问题。
5.为了实现上述目的,本发明采用如下技术方案:
6.一种基于词频打分算法获取法律文书案件地点的方法,具体过程为:
7.s1、将待处理的司法文书采用分类算法分成设定的各种文书类型;
8.s2、将经过分类后的司法文书进行特征提取,获得待处理司法文书中包含地理位置的句子列表和受理法院名称的信息;
9.s3、通过top10和top1的tf
‑
idf融合算法得到待处理司法文书的句子列表中每个句子的评分;具体过程为:
10.s3.1、对每一种文书类型均找到2000份该文书类型下的司法文书样本;
11.s3.2、对每种文书类型,均将每份司法文书样本进行分句,然后将分句中的含有地理位置的句子筛选出来,再人工给这些句子打分;打分标准为:将地理位置从低到高分为省、市、区/县、街道、小区、楼宇信息、房间信息七个等级,等级越高,分数的权重越高,每个句子的分数为该句子中含有的地理位置中所有等级的分数总和;完成人工打分后,对每份司法文书均找出含有地理位置的分数最高的前10个句子和其中分数最高的句子;
12.s3.3、对于每种文书类型,均将每份司法文书样本的最高分的10个句子进行分词,然后通过tf
‑
idf词频算法得到每个词语的分数;计算公式如下:
13.tf词频公式为:
14.idf逆词频公式为:
15.tf
‑
idf最终的公式为:tfidf
i,j
=tf
i,j
×
idf
i
;
16.其中,n
k,j
是词语t
i
在文书d
j
中的出现次数,∑
k
n
k,j
是在文书d
j
中所有词语的出现次数之和;|d|为文书总数,|{j:ti∈d
j
}|为包含词语t
i
的文书数目;
17.s3.4、对于每种文书类型,均对每份司法文书样本里面的最高分句子进行分词,也通过tf
‑
idf词频算法得到每个词语的分数;
18.s3.5、形成每种文书类型的地理词库打分算法,每种文书类型的地理词库打分算法中,每个词语的分数由步骤s3.3中获得的该词语的分数和步骤s3.4中获得的该词语的分数各占50%权重加总得出;
19.s3.6、将步骤s2获得的司法文书的包含地理位置的句子列表中每一个句子进行分词,并根据其所属的文书类型利用步骤s5形成的相应的地理词库打分算法对句子中的各个词语进行打分并加总得到该句子的最终分数,从而得到一个得分最高的句子,然后跳转至步骤s4;
20.s4、对待处理司法文书的评分最高的句子进行地理位置的特征提取,得到该司法文书的案件地点;具体过程为:
21.s4.1、利用步骤s2获得的受理法院名称,获得该受理法院名称的地理位置信息;
22.s4.2、对步骤s3.6获得的得分最高的句子中的地理位置,通过全国的省市区词库找到对应的省、市、县,通过详细地址的词库找到这个句子里面提到的街道、小区、酒店的相关详细地址信息;
23.s4.3、融合步骤s4.1和步骤s4.2得到的地理信息,通过校验和拼接,得到最终的案件地点。
24.进一步地,步骤s1的具体过程为:
25.以待处理的司法文书作为输入,先根据司法文书的标题初步判断其属于哪种类型,如果根据标题无法识别出其文书类型,进一步通过各种文书类型对应的案由关键词库对于该司法文书进行二次划分,最终将输入的司法文书进行分类。
26.进一步地,步骤s2的具体过程为:
27.s2.1、从待处理司法文书的正文中将受理法院名称通过特征工程提取出来;
28.s2.2、对待处理司法文书的正文进行分句,得到一个初始句子列表,然后通过现有的地理词库和自行搜集构建的地理词库,判断每个句子中是否包含地理位置,如果没有则丢弃该句子,如果有则存留下来,最终过滤得到一个该司法文书的包含地理位置的句子列表。
29.进一步地,步骤s3.2中,每一个等级所得的分数为2^x,,x表示等级,省、市、区/县、街道、小区、楼宇信息、房间信息的等级x分别为0,1,2,
…
,6。
30.本发明提供一种计算机可读存储介质,所述计算机可读存储介质内存储有计算机程序,所述计算机程序被处理器执行时实现上述方法。
31.本发明提供一种设备,包括处理器和存储器,所述存储器用于存储计算机程序;所述处理器用于执行所述计算机程序时,实现上述方法。
32.本发明的有益效果在于:本发明对司法文书中的案件地理位置提取的时候,通过tf
‑
idf和权重矫正算法给地理句子打分,最终再通过多标签体系找到详细的位置,可以有效提高法律文书犯罪地点提取的准确性。
附图说明
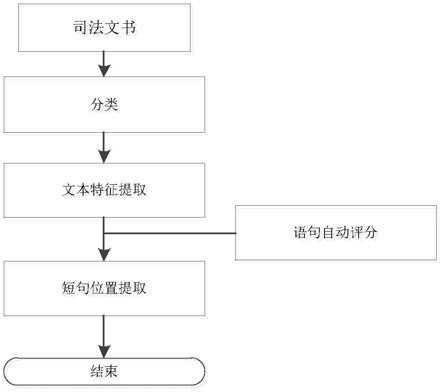
33.图1为本发明实施例方法的总体流程示意图;
34.图2为本发明实施例方法中步骤s1的流程示意图;
35.图3为本发明实施例方法中步骤s2的流程示意图;
36.图4为本发明实施例方法中步骤s3的流程示意图;
37.图5为本发明实施例方法中步骤s4的流程示意图。
具体实施方式
38.以下将结合附图对本发明作进一步的描述,需要说明的是,本实施例以本技术方案为前提,给出了详细的实施方式和具体的操作过程,但本发明的保护范围并不限于本实施例。
39.本实施例提供一种基于词频打分算法获取法律文书案件地点的方法,如图1所示,具体过程为:
40.s1、将待处理的司法文书采用分类算法分成刑事、民事、行政、执行等各种文书类型;
41.s2、将经过分类后的司法文书进行特征提取,获得待处理司法文书中包含地理位置的句子列表和受理法院名称等相关信息;
42.s3、通过top10和top1的tf
‑
idf融合算法得到待处理司法文书的句子列表中每个句子的评分;
43.s4、对待处理司法文书的评分最高的句子进行地理位置的特征提取,得到该司法文书的案件地点。
44.进一步地,如图2所示,步骤s1的具体过程为:
45.以待处理的司法文书作为输入,先根据司法文书的标题初步判断其属于哪种类型,如果根据标题无法识别出其文书类型,进一步通过各种文书类型对应的案由关键词库对于该司法文书进行二次划分,最终将输入的司法文书进行分类。先对司法文书进行分类的目的在于方便后续过程对不同格式的文书进行区分处理。
46.进一步地,如图3所示,步骤s2的具体过程为:
47.s2.1、从待处理司法文书的正文中将受理法院名称通过特征工程提取出来;
48.s2.2、对待处理司法文书的正文进行分句,得到一个初始句子列表,然后通过现有的地理词库和自行搜集构建的地理词库,判断每个句子中是否包含地理位置,如果没有则丢弃该句子,如果有则存留下来,最终过滤得到一个该司法文书的包含地理位置的句子列表。
49.进一步地,如图4所示,步骤s3的具体过程为:
50.s3.1、对每一种文书类型均找到2000份该文书类型下的司法文书样本。
51.s3.2、对每种文书类型,均将每份司法文书样本进行分句,然后将分句中的含有地理位置的句子筛选出来,再人工给这些句子打分;打分标准为:将地理位置从低到高分为省、市、区/县、街道、小区、楼宇信息、房间信息七个等级,等级越高,分数的权重越高,每个句子的分数为该句子中含有的地理位置中所有等级的分数总和;完成人工打分后,对每份司法文书均找出含有地理位置的分数最高的前10个句子(不足的后面留空)和分数最高的
句子(即前面10个句子中分数最高的句子)。
52.在本实施例中,每一个等级所得的分数为2^x,,x表示等级,省、市、区/县、街道、小区、楼宇信息、房间信息的等级x分别为0,1,2,
…
,6。例如,省为2^0=1,那么市即为2^1=2,如果一个句子中含有的地理位置包括有省、市、区/县,则该句子的分数就是2^0 2^1 2^2=7,这样就可以对于句子有一个初步的打分。
53.s3.3、对于每种文书类型,均将每份司法文书样本的最高分的10个句子进行分词,然后通过tf
‑
idf词频算法得到每个词语的分数;计算公式如下:
54.tf词频公式为:
55.idf逆词频公式为:
56.tf
‑
idf最终的公式为:tfidf
i,j
=tf
i,j
×
idf
i
;
57.其中,n
i,j
是词语t
i
在文书d
j
中的出现次数,∑
k
n
k,j
是在文书d
j
中所有词语的出现次数之和;|d|为文书总数,|{j:t
i
∈d
j
}|为包含词语t
i
的文书数目(即n
i,j
≠0的文书数目)。
58.例如,在某个一共有100词的句子中“街道”、“的”和“抓获”分别出现了1次、5次和2次,分词文书句子总量正好是20000(2000*10);"的"在15000个句子中出现过;“街道”在300个句子中出现过,“抓获”在500的句子中出现,如果新输入的句子是:
‘
李某在广东省龙岗区的惠盐街道抢劫被抓获’,通过分词找到了里面的关键词
‘
街道’,
‘
的’,
‘
抓获’几个关键词,首先计算tf(词频):街道:0.015;的:0.75;应用:0.025;然后计算idf(逆文档频率):街道:log(20000/300)=1.8239;的:log(20000/15000)=0.1249;应用:log(20000/500)=1.6020;最后该句子计算的tf
‑
idf=0.015*1.8239 0.75*0.1249 0.025*1.602=0.1610。
59.s3.4、对于每种文书类型,均对每份司法文书样本里面的最高分句子进行分词,也通过tf
‑
idf词频算法得到每个词语的分数;
60.s3.5、形成每种文书类型的地理词库打分算法,每种文书类型的地理词库打分算法中,每个词语的分数由步骤s3.3中获得的该词语的分数和步骤s3.4中获得的该词语的分数各占50%权重加总得出;
61.s3.6、将步骤s2获得的司法文书的包含地理位置的句子列表中每一个句子进行分词,并根据其所属的文书类型利用步骤s5形成的相应的地理词库打分算法对句子中的各个词语进行打分并加总得到该句子的最终分数,从而得到一个得分最高的句子,然后跳转至步骤s4。
62.进一步地,如图5所示,步骤s4的具体过程为:
63.s4.1、利用步骤s2获得的受理法院名称,获得该受理法院名称的地理位置信息;
64.s4.2、对步骤s3.6获得的得分最高的句子中的地理位置,通过全国的省市区词库找到对应的省、市、县,通过详细地址的词库找到这个句子里面提到的如街道、小区、酒店的相关详细地址信息。
65.s4.3、融合步骤s4.1和步骤s4.2得到的地理信息,通过校验和拼接,得到最终的案件地点。
66.对于本领域的技术人员来说,可以根据以上的技术方案和构思,给出各种相应的
改变和变形,而所有的这些改变和变形,都应该包括在本发明权利要求的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。