一种基于bayeslstm的语种识别方法
技术领域
1.本发明涉及语种识别领域,具体来说,涉及一种基于bayeslstm的语种识 别方法。
背景技术:
2.文本语种识别被当做是一种基于某种特殊特征的文本分类任务。目前主要 采用基于n
‑
gram模型的方法和基于深度学习的方法。现有全监督分类器 langid.py是基于多项式贝叶斯分类方法实现了一种对场景不敏感的语种识 别模型,通过概率计算的方式判断一组候选语言中最有可能的语言概率值。可 以识别97种语言场景,其特征抽取采用互信息的特征n
‑
gram项,这种基于 n
‑
gram模型的方法适用于长文本,测试文档越长,识别的准确率越高。该方 法对短文本的识别比较局限,尤其是对关注中文简体、中文正体、中文繁体等, 在识别中存在较大的困难。
3.针对相关技术中的问题,目前尚未提出有效的解决方案。
技术实现要素:
4.本发明的目的在于提供一种基于bayeslstm的语种识别方法,以解决 上述背景技术中提出的问题。
5.为实现上述目的,本发明提供如下技术方案:
6.一种基于bayeslstm的语种识别方法,包括以下步骤:
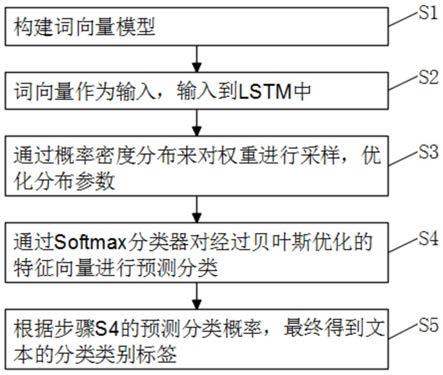
7.s1、构建词向量模型;
8.s2、词向量作为输入,输入到lstm中;
9.s3、通过概率密度分布来对权重进行采样,优化分布参数;
10.s4、通过softmax分类器对经过贝叶斯优化的特征向量进行预测分类;
11.s5、根据步骤s4的预测分类概率,最终得到文本的分类类别标签。
12.进一步的,所述步骤s1构建词向量模型包括以下步骤:
13.s11、对采集的语种的语料文件进行预处理形成语料库;
14.s12、对每个语种采用token生成器将每个句子表示为词向量和字向量;
15.s13、将输入的词转化为向量,然后将词中的每一个字符进行了拆解;
16.s14、用lstm模型将词所包含的所有字符转化为向量,并对词和字符转化 的向量进行拼接。
17.进一步的,所述步骤s2词向量作为输入,输入到lstm中包括以下步骤:
18.s21、以第一步的词向量作为输入,很好地保留了句子中词与词之间的信 息;
19.s22、lstm网络信息的更新和保留是由输入门、遗忘门、输出门和一个单 元来实现的。
20.进一步的,所述输入门决定了当前时刻网络的输入有多少保存到单元状 态;
21.所述遗忘门决定了上一时刻的单元状态有多少保留到当前时刻;
22.所述输出门控制单元状态有多少输出到lstm的当前输出值。
23.与现有技术相比,本发明具有以下有益效果:本发明根据网络爬虫数据构 建语种语料库,通过对不同语言文本进行字符串处理后得到训练集数据;构建 基于贝叶斯优化的lstm模型的语种识别方法,利用长短记忆网络(lstm)学 习词语之间的依赖关系,并采用贝叶斯的概率密度分布对网络的权重参数进行 优化;接着对训练数据进行时序迭代训练,更新模型参数;搭建语种识别系统 进行预测。本发明的方法通过估计模型参数的不确定性来提高模型的鲁棒性和 语种识别的准确率。
附图说明
24.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施 例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是 本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的 前提下,还可以根据这些附图获得其他的附图。
25.图1是根据本发明实施例的一种基于bayeslstm的语种识别方法的流程 图。
具体实施方式
26.下面,结合附图以及具体实施方式,对发明做出进一步的描述:
27.请参阅图1,根据本发明实施例的一种基于bayeslstm的语种识别方 法,包括以下步骤:
28.步骤s1:构建词向量模型
29.对采集的语种的语料文件进行预处理形成语料库,对每个语种采用 token生成器将每个句子表示为词向量和字向量。即将输入的词转化为向 量,然后将词中的每一个字符进行了拆解,用lstm模型将词所包含的所有 字符转化为向量,并对词和字符转化的向量进行拼接。
30.步骤s2:词向量作为输入,输入到lstm中。
31.以第一步的词向量作为输入,很好地保留了句子中词与词之间的信息。 lstm网络信息的更新和保留是由输入门it、遗忘门ft、输出门ot和一个 cell单元ct来实现的。
32.输入门(inputgate)决定了当前时刻网络的输入xt有多少保存到单元 状态ct,可以避免当前无关紧要的内容进入记忆。
33.i
t
=σ(w
i
x
t
u
i
h
t
‑1 b
i
)
34.遗忘门(forget gate)决定了上一时刻的单元状态ct
‑
1有多少保留到 当前时刻ct,可以保存很久很久之前的信息.表示为:
35.f
t
=σ(w
f
x
t
u
f
h
t
‑1 b
f
)
36.输出门(output gate)控制单元状态ct有多少输出到lstm的当前输出 值ht,可以控制长期记忆对当前输出的影响.表示为:
37.o
t
=σ(w
o
x
t
u
o
h
t
‑1 b
o
)
38.当前时刻更新后的信息由ct来表示:
39.c
t
=f
t
×
c
t
‑1 i
t
×
g
t
40.其中:g
t
=tanh(w
g
x
t
u
g
h
t
‑1 b
g
)
41.最终输出的信息为:
42.c
t
=o
t
×
tanh(c
t
)
43.其中w,u表示神经网络的权重系数,b表示偏置,xt表示输入的词向 量,ht
‑
1是lstm层上一时刻的隐藏层的输出结果,ct
‑
1表示上一时刻的 历史信息,gt表示候选状态下当前单元的信息,σ和tanh表示为激活函数。
44.步骤s3:由于lstm不能很好地学习不同词语相对于句子的重要程度, 本文结合贝叶斯神经网络的核心思想,提出基于贝叶斯优化的lstm方法。 通过概率密度分布来对权重进行采样,优化分布参数,而不是设置一个固 定的权重。在第i次,在模型第n层上对权重的采样表示为:
[0045][0046]
在第i次,在模型第n层上对偏置b的采样表示为:
[0047][0048]
其中p,u为可训练参数,表示不同的权重分布。n(0,1)表示标准正 态分布。
[0049]
步骤s4:本文采用计算简单,效果显著的softmax分类器对经过贝叶 斯优化的特征向量vt进行预测分类:
[0050]
y=soft max(w
v
v
t
b
v
)
[0051]
其中wv,bv表示优化后的权重和偏置。
[0052]
步骤s5:根据的预测分类概率,最终得到文本的分类类别标签。
[0053]
通过本发明的上述方案,本发明根据网络爬虫数据构建语种语料库,通 过对不同语言文本进行字符串处理后得到训练集数据;构建基于贝叶斯优化的 lstm模型的语种识别方法,利用长短记忆网络(lstm)学习词语之间的依赖 关系,并采用贝叶斯的概率密度分布对网络的权重参数进行优化;接着对训练 数据进行时序迭代训练,更新模型参数;搭建语种识别系统进行预测。本发明 的方法通过估计模型参数的不确定性来提高模型的鲁棒性和语种识别的准确 率。
[0054]
为了方便理解本发明的上述技术方案,以下就本发明在实际过程中的 工作原理或者操作方式进行详细说明。
[0055]
在实际应用时,bayeslstm方法是用于图片生成、语言建模中的一种 快速有效的方法。其中贝叶斯神经网络通过概率密度分布对权重进行采样, 然后优化分布参数。利用这一点,我们不仅能够衡量训练数据本身与预测 结果的置信度与不确定性,而且能够增强词语相对于句子的权重依赖关系。 而lstm旨在解决使用标准的循环神经网络(rnn)处理长序列数据时发生 的信息消失问题。由于文本所要处理的语料文件本身是一种序列化数据, 而循环神经网络(rnn)能够较好地处理序列问题,但当训练文本长度过长 时,容易出现梯度消失的问题。长短期记忆网络(long short
‑
term memory, lstm)作为一种特定形式的rnn,能够有效解决rnn无法处理的长距离依赖 问题。
[0056]
对于中文细分领域的语种识别任务,包括中文简体、中文正体、中文繁体 等,需要识别中文不同形体,如“中国”与“中國”,提出了基于贝叶斯lstm 的语种识别方法,结合bayeslstm方法,将其应用于中文语言细分领域,以区 别简体、繁体、及粤语的文本语言类型。
[0057]
本发明根据网络爬虫数据构建语种语料库,通过对不同语言文本进行字符 串处
理后得到训练集数据;构建基于贝叶斯优化的lstm模型的语种识别方法, 利用长短记忆网络(lstm)学习词语之间的依赖关系,并采用贝叶斯的概率密 度分布对网络的权重参数进行优化;接着对训练数据进行时序迭代训练,更新 模型参数;搭建语种识别系统进行预测。本发明的方法通过估计模型参数的不 确定性来提高模型的鲁棒性和语种识别的准确率。
[0058]
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员 而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例 进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等 同物限定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。