技术特征:
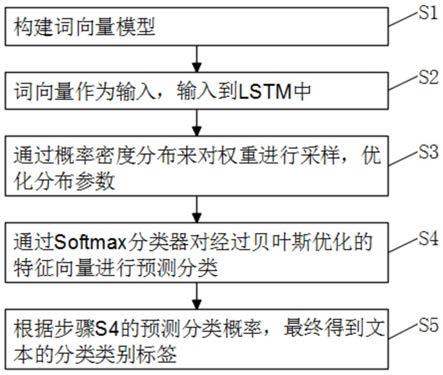
1.一种基于bayeslstm的语种识别方法,其特征在于,包括以下步骤:s1、构建词向量模型;s2、词向量作为输入,输入到lstm中;s3、通过概率密度分布来对权重进行采样,优化分布参数;s4、通过softmax分类器对经过贝叶斯优化的特征向量进行预测分类;s5、根据步骤s4的预测分类概率,最终得到文本的分类类别标签。2.根据权利要求1所述的一种基于bayeslstm的语种识别方法,其特征在于,所述步骤s1构建词向量模型包括以下步骤:s11、对采集的语种的语料文件进行预处理形成语料库;s12、对每个语种采用token生成器将每个句子表示为词向量和字向量;s13、将输入的词转化为向量,然后将词中的每一个字符进行了拆解;s14、用lstm模型将词所包含的所有字符转化为向量,并对词和字符转化的向量进行拼接。3.根据权利要求1所述的一种基于bayeslstm的语种识别方法,其特征在于,所述步骤s2词向量作为输入,输入到lstm中包括以下步骤:s21、以第一步的词向量作为输入,很好地保留了句子中词与词之间的信息;s22、lstm网络信息的更新和保留是由输入门、遗忘门、输出门和一个单元来实现的。4.根据权利要求3所述的一种基于bayeslstm的语种识别方法,其特征在于,所述输入门决定了当前时刻网络的输入有多少保存到单元状态;所述遗忘门决定了上一时刻的单元状态有多少保留到当前时刻;所述输出门控制单元状态有多少输出到lstm的当前输出值。
技术总结
本发明公开了一种基于BayesLSTM的语种识别方法,包括以下步骤:S1、构建词向量模型;S2、词向量作为输入,输入到LSTM中;S3、通过概率密度分布来对权重进行采样,优化分布参数;S4、通过Softmax分类器对经过贝叶斯优化的特征向量进行预测分类;S5、根据步骤S4的预测分类概率,最终得到文本的分类类别标签。有益效果:本发明的方法通过估计模型参数的不确定性来提高模型的鲁棒性和语种识别的准确率。模型的鲁棒性和语种识别的准确率。模型的鲁棒性和语种识别的准确率。
技术研发人员:周少龙 陈欣洁 余智华 冯凯 李建广
受保护的技术使用者:中科天玑数据科技股份有限公司
技术研发日:2021.03.17
技术公布日:2021/12/6
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。