1.本发明涉及人工智能技术领域,尤其涉及一种基于人工智能检索和提取手术视频片段的方法及系统。
背景技术:
2.根据我国统计年报可以看到有6171.58、6930.44万人次进行各项手术。随着人民日益增长的医疗质量需求,对手术技能人员的需求也在日益扩大。一方面,需要医学生尽快的能学习到手术技能、手术中突发事件的处理方法;其次为了提高手术质量,外科手术医生也会反复查看自己或他人曾经的手术视频,以此帮助提升自己的手术技能。
3.但是长时间的手术视频观看会花费医生大量时间,长时间观看手术视频会降低医生和学生的注意力,因此可能会错过部分重要步骤或感兴趣的手术时间。尤其是持续时间超长的手术视频(例如腹腔镜胰十二指肠切除术手术,一般长达6
‑
8小时),这样回看视频时对医生来说是巨大的负担,学习的效率极低。无法快速定位到某一具体手术过程、定位到手术中发生的某一起或者某一类手术事件,即无法对视频进行快速检索,从而快速找到感兴趣的时间进行重点浏览。另外根据管理需要或者业务应用需要,医院或者行政管理机构需要将手术过程中的关键信息提取,即通过自动化的方法提取手术过程中关键的视频片段或者图片,以用于对手术过程进行学习研究、知识库构建、安全行为评估样本和主刀技术能力评估样本选取,然而,现有的技术却无法实现该需求。
技术实现要素:
4.本发明的目的在于克服现有技术的缺点,提供了一种基于人工智能检索和提取手术视频片段的方法及系统,解决了目前医护人员在观看手术视频时存在的问题。
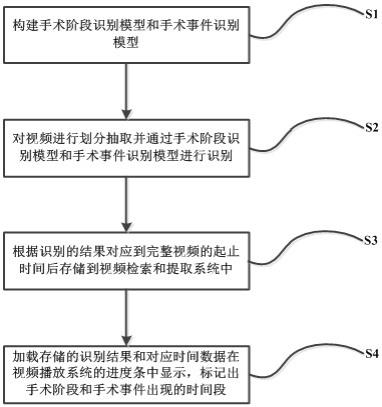
5.本发明的目的通过以下技术方案来实现:一种基于人工智能检索和提取手术视频片段的方法,所述方法包括:将视频划分为多个视频片段并等间距抽取视频片段的多张图片输入到手术阶段识别模型和手术事件识别模型中,在进行图像特征提取后分别识别出图片中的手术阶段和手术事件;根据视频片段的起止时间输出手术阶段和手术事件的识别结果对应到完整视频的起止时间后,将识别结果的对应时间存储在视频检索系统和视频提取系统中;加载视频检索系统和视频提取系统中的识别结果和对应时间数据在视频播放系统的进度条中显示,并标记出手术阶段和手术事件出现的时间段。
6.所述方法还包括根据视频中手术事件和手术阶段的出现时间,抽取出对应视频或者图片制作成手术知识库,让医生或专家快速浏览进行安全性评估和主刀技能评估。
7.所述将视频划分为多个视频片段并等间距抽取视频片段的多张图片输入到手术阶段识别模型和手术事件识别模型中,在进行图像特征提取后分别识别出图片中的手术阶段和手术事件包括:
将视频划分为多个视频片段,等间距抽取视频片段的n张图片,将每张图片存储为(n,c,h,w)格式的四维张量,n表示每个视频片段的抽帧数,c表示每张图片的通道数,h为图片的宽度,w表示图片的长度;将四维张量表示的图片放入由多个2d卷积、relu激活层、批归一化层和一个全连接层组成的resnet网络中提取图像特征,并将图像特征的格式存储为(m,s),m表示输入图片数,s表示预设特征向量长度;将格式为(m,s)的图像特征向量分m次输入到lstm网络中,进行连续视频帧的手术阶段和手术事件识别。
8.所述视频检索系统和视频提取系统的构建方法包括:采用手术阶段识别模型和手术事件识别模型对输入的图片进行基于深度学习的推理,得到手术阶段信息和手术事件信息;通过定制化的视频播放软件为用户输出手术阶段和手术事件出现时间段在进度条上展示,实现视频检索系统的构建;通过手术阶段识别模型和手术事件识别模型识别到的关键手术过程的起止时间点,根据定制化的抽取软件将视频中相应的视频片段进行抽取或者将视频按照一定的帧率抽取为静态图片,实现视频抽取系统的构建。
9.所述方法还包括将视频进行划分之前实现对手术阶段识别模型和手术事件识别模型构建的步骤;所述手术阶段识别模型和手术事件识别模型构建步骤包括:根据专家经验、指南、论著建立手术阶段理论模型和手术事件理论模型,并对收集的手术视频根据手术阶段理论模型和手术事件理论模型对手术阶段和手术事件进行边界划分;将大量视频数据按照分辨率的要求进行收集成图片,并对收集完成的图片进行手术阶段时间段和手术事件时间段的标注。
10.将完成标注的手术阶段数据和手术事件数据分布按照相应比例随机分配进入训练集、验证集和测试集,并通过resnet网络和lstm网络对训练集、验证集和测试集图片进行训练、验证和测试,完成手术阶段识别模型和手术事件识别模型的构建。
11.所述将大量视频数据按照分辨率的要求进行收集成图片,并对收集完成的图片进行手术阶段时间段和手术事件时间段的标注包括:按照每个手术视频分辨率不低于预设值且每秒不低于预设帧的要求收集手术视频数据,并以图片的形式保存;对收集完成的图片通过ffmpeg软件统一转码为相同的格式,并通过标注软件anvil完成对手术阶段时间段和手术事件时间段的初步标注;通过专业人员对完成初步标注的视频数据再进行人工标注,并将初步标注不合格的图片进行修改得到标注合格的图片。
12.所述通过resnet网络和lstm网络对训练集、验证集和测试集图片进行训练、验证和测试,完成手术阶段识别模型和手术事件识别模型的构建包括:将训练集、验证集和测试集的图片存储为(n,c,h,w)格式的四维张量,n表示每个视频片段的抽帧数,c表示每张图片的通道数,h为图片的宽度,w表示图片的长度;将四维张量表示的图片放入由多个2d卷积、relu激活层、批归一化层和一个全连
接层组成的resnet网络中提取图像特征,并将图像特征的格式存储为(m,s);将格式为(m,s)的图像特征向量分m次输入到lstm网络中,进行连续视频帧的手术阶段和手术事件识别并记录起止时间;将识别结果放入交叉熵损失函数中进行计算得到损失,并使用梯度下降的方式更新模型参数,以此构造手术阶段识别模型和手术事件识别模型。
13.一种基于人工智能检索和提取手术视频片段的系统,它包括识别模块、视频检索与提取模块以及视频播放模块;所述识别模块用于将视频划分为多个视频片段并等间距抽取视频片段的多张图片输入到手术阶段识别模型和手术事件识别模型中,在进行图像特征提取后分别识别出图片中的手术阶段和手术事件;所述视频检索与提取模块用于根据视频片段的起止时间输出手术阶段和手术事件的识别结果对应到完整视频的起止时间后,将识别结果的对应时间存储在视频检索和提取单元中;所述视频播放模块用于加载视频检索系统和视频提取系统中的识别结果和对应时间数据在视频播放系统的进度条中显示,并标记出手术阶段和手术事件出现的时间段。
14.还包括构建模块,所述构建模块用于构建视频检索与提取单元、手术阶段识别模型以及手术事件识别模型。
15.还包括视频收集与标注模块,所述视频收集与标注模块用于将大量视频数据按照分辨率的要求进行收集成图片,并对收集完成的图片进行手术阶段时间段和手术事件时间段的标注。
16.本发明具有以下优点:一种基于人工智能检索和提取手术视频片段的方法及系统,通过对手术视频中关于手术阶段合并手术事件进行识别,并将其对应的时间点在播放的时间轴的进度条上进行显示,能够使得医护人员在观看手术视频时能够快速定位到自己需要关注的手术阶段或者手术事件,极大地节省了观看手术视频的时间,提高了学习效率;同时通过构建了手术知识库等能够服务与医学院学生和外科手术医生,同时具备较高的社会效益和经济效益。
附图说明
17.图1 为本发明方法的流程示意图;图2 为视频播放系统中进度条显示效果示意图。
具体实施方式
18.为使本技术实施例的目的、技术方案和优点更加清楚,下面将结合本技术实施例中附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本技术一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本技术实施例的组件可以以各种不同的配置来布置和设计。因此,以下结合附图中提供的本技术的实施例的详细描述并非旨在限制要求保护的本技术的保护范围,而是仅仅表示本技术的选定实施例。基于本技术的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得
的所有其他实施例,都属于本技术保护的范围。下面结合附图对本发明做进一步的描述。
19.如图1所示,本发明的一种实施例涉及一种基于人工智能检索和提取手术视频片段的方法,具体包括以下内容:s1、对手术阶段识别模型和手术事件识别模型进行构建;其具体包括以下内容:s11、根据专家经验、指南、论著建立手术阶段理论模型和手术事件理论模型,并对收集的手术视频根据手术阶段理论模型和手术事件理论模型对手术阶段和手术事件进行边界划分;s12、将大量视频数据按照分辨率的要求进行收集成图片,并对收集完成的图片进行手术阶段时间段和手术事件时间段的标注。具体为:按照每个手术视频分辨率不低于720
×
560且每秒不低于21帧的要求收集手术视频数据,并以图片的形式保存;对收集完成的图片通过ffmpeg软件统一转码为相同的mpeg
‑
4格式,并通过标注软件anvil video annotation research tool完成对手术阶段时间段和手术事件时间段的初步标注;通过由6个经过前期培训合格的外科专科医师负责质量控制,对完成初步标注的视频数据再进行人工标注,并将初步标注不合格的图片进行修改得到标注合格的图片。
20.s13、将完成标注的手术阶段数据和手术事件数据分布按照8:1:1的比例随机分配进入训练集、验证集和测试集,并通过resnet网络和lstm网络对训练集、验证集和测试集图片进行训练、验证和测试,完成手术阶段识别模型和手术事件识别模型的构建。
21.其中,所有模型均使用anaconda、qtcreator平台进行开发,图像处理使用nvidia tesla v100图形处理器。
22.s2、将视频划分为多个视频片段并等间距抽取视频片段的多张图片输入到手术阶段识别模型和手术事件识别模型中,在进行图像特征提取后分别识别出图片中的手术阶段和手术事件;进一步地,其具体包括:s21、将视频划分为多个视频片段,等间距抽取视频片段的n张图片,将每张图片存储为(n,c,h,w)格式的四维张量,n表示每个视频片段的抽帧数,c表示每张图片的通道数,h为图片的宽度,w表示图片的长度;s22、将四维张量表示的图片放入由多个2d卷积、relu激活层、批归一化层和一个全连接层组成的resnet网络中提取图像特征,并将图像特征的格式存储为(m,s),m表示输入图片数,s表示预设特征向量长度;进一步地,卷积层或者全连接层计算公式为:,其中y表示计算输出,n表示神经元个数,表示第i个神经元的权重,表示第i个神经元的输入数据,b为计算结果添加一个偏移量,当为卷积计算时和是二维矩阵,当为全连接计算时和是一维向量。
23.批归一化层计算公式为:,其中bn表示批归一化计算输出,x表示输入数据,e[x]表示x张量的均值,var[x]表示x张量的方差,表示一个极小的参数为
保证分母不为0,γ和β为可学习系数。
[0024]
relu激活函数的计算公式为:,其中relu表示计算输出,z表示输入张量,max()表示取其中的最大值。
[0025]
s23、将格式为(m,s)的图像特征向量分m次输入到lstm网络中,进行连续视频帧的手术阶段和手术事件识别。lstm网络中由多个单元组成,提供忘记距离现在时间过久远的信息,通过新视频帧的输入更新当前状态完成识别。
[0026]
进一步地,lstm网络中一个单元的计算公式如下:lstm网络中一个单元的计算公式如下:lstm网络中一个单元的计算公式如下:lstm网络中一个单元的计算公式如下:lstm网络中一个单元的计算公式如下:lstm网络中一个单元的计算公式如下:其中h
t
表示t时刻的隐藏状态;c
t
表示lstm在t时刻的细胞计算结果;x
t
表示在t时刻的输入数据;h
t
‑1表示t
‑
1时刻的隐藏状态;i
t
表示输入操作后的计算结果;f
t
表示经过忘记操作后的计算结果;g
t
表示输出操作的结果;o
t
表示细胞核上一时刻信息融合操作的输出;w
ii
、w
hi
、b
ii
、b
hi
分别表示lstm细胞中提取输入数据特征的权重参数和偏移量;w
if
、w
hf
、b
if
、b
hf
分别表示lstm细胞中遗忘门中计算的权重参数和偏移量;w
ig
、w
hg
、b
ig
、b
hg
分别表示lstm细胞中输出门中计算的权重参数和偏移量; w
io
、w
ho
、b
io
、b
ho
分别表示lstm细胞中更新门中计算的权重参数和偏移量;σ()为sigmiod函数计算,其中,
⊙
表示同或运算。
[0027]
s3、根据视频片段的起止时间输出手术阶段和手术事件的识别结果对应到完整视频的起止时间后,将识别结果的对应时间存储在视频检索系统和视频提取系统中;s4、加载视频检索系统和视频提取系统中的识别结果和对应时间数据在视频播放系统的进度条中显示;并标记出手术阶段和手术事件出现的时间段。
[0028]
如图2所示,在播放时间轴提供手术阶段信息、手术事件信息,外科医生可以快速检索到需要观看的视频片段;其中播放时间轴下方有三条进度条对应时间轴,在一段时间中发生了某项事件或处于某个阶段,则会在对应时间位置标注出现对应手术阶段和手术事件。
[0029]
同时,根据视频中手术事件和手术阶段的出现时间,使用ffmpeg软件抽取出对应视频或者图片制作成手术知识库,让医生或专家快速浏览进行安全性评估和主刀技能评估。
[0030]
进一步地,视频检索系统和视频提取系统的构建方法包括:采用手术阶段识别模型和手术事件识别模型对输入的图片进行基于深度学习的推理,得到手术阶段信息和手术事件信息;通过定制化的视频播放软件为用户输出手术阶段和手术事件出现时间段在进度条上展示,实现视频检索系统的构建;
通过手术阶段识别模型和手术事件识别模型识别到的关键手术过程的起止时间点,根据定制化的抽取软件将视频中相应的视频片段进行抽取或者将视频按照一定的帧率抽取为静态图片,实现视频抽取系统的构建。
[0031]
进一步地,通过resnet网络和lstm网络对训练集、验证集和测试集图片进行训练、验证和测试,完成手术阶段识别模型和手术事件识别模型的构建包括:将训练集、验证集和测试集的图片存储为(n,c,h,w)格式的四维张量,n表示每个视频片段的抽帧数,c表示每张图片的通道数,h为图片的宽度,w表示图片的长度;将四维张量表示的图片放入由多个2d卷积、relu激活层、批归一化层和一个全连接层组成的resnet网络中提取图像特征,并将图像特征的格式存储为(m,s);将格式为(m,s)的图像特征向量分m次输入到lstm网络中,进行连续视频帧的手术阶段和手术事件识别。lstm网络中由多个单元组成,提供忘记距离现在时间过久远的信息,通过新视频帧的输入更新当前状态完成识别。
[0032]
将识别结果放入交叉熵损失函数中进行计算得到损失,并使用梯度下降的方式更新模型参数,以此构造手术阶段识别模型和手术事件识别模型。其中celoss表示计算输出,m表示类别数;y
ic
表示指示变量(0或1),如果该类别和样本的类别相同就是1,否则是0;p
ic
表示对于观测样本属于类别c的预测概率。
[0033]
本发明的另一实施例涉及一种基于人工智能检索和提取手术视频片段的系统,它包括识别模块、视频检索与提取模块以及视频播放模块;所述识别模块用于将视频划分为多个视频片段并等间距抽取视频片段的多张图片输入到手术阶段识别模型和手术事件识别模型中,在进行图像特征提取后分别识别出图片中的手术阶段和手术事件;所述视频检索与提取模块用于根据视频片段的起止时间输出手术阶段和手术事件的识别结果对应到完整视频的起止时间后,将识别结果的对应时间存储在视频检索和提取单元中;所述视频播放模块用于加载视频检索系统和视频提取系统中的识别结果和对应时间数据在视频播放系统的进度条中显示,并标记出手术阶段和手术事件出现的时间段。
[0034]
进一步地,还包括构建模块,所述构建模块用于构建视频检索与提取单元、手术阶段识别模型以及手术事件识别模型。
[0035]
进一步地,还包括视频收集与标注模块,所述视频收集与标注模块用于将大量视频数据按照分辨率的要求进行收集成图片,并对收集完成的图片进行手术阶段时间段和手术事件时间段的标注。
[0036]
以上所述仅是本发明的优选实施方式,应当理解本发明并非局限于本文所披露的形式,不应看作是对其他实施例的排除,而可用于各种其他组合、修改和环境,并能够在本文所述构想范围内,通过上述教导或相关领域的技术或知识进行改动。而本领域人员所进行的改动和变化不脱离本发明的精神和范围,则都应在本发明所附权利要求的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。