1.本发明涉及一种针对海量文本数据的定向筛选架构及方法,可以提供对海量文本进行筛选的计算架构以及闭环解决方案,属于计算机科学领域。
背景技术:
2.随着网络的发展以及网民数量的持续增长,每天产生的信息越来越多。在自然语言处理领域,面对如此海量的信息空间,如何更快更准确的找到用户感兴趣的内容是一个迫切需要解决的问题。一方面每天产生的文本数据越来越多,需要更强的计算能力才能够对文本进行全量的处理;另一方面,基于海量的文本数据以及用户兴趣更准确的筛选数据,发现用户感兴趣的内容。同时用户兴趣随时间在变化,因此设计一种闭环的海量文本数据的筛选架构及方法是十分有必要的。
3.文本筛选常用方法有两种思路:1.基于规则,筛选满足某种格式或包含某些具体词汇的文本,常用于某些规律较为明显的文本,比如广告宣传等。这种方法简单、效率高、可以处理海量的复杂的自然语言数据,但对文本质量要求较高,如果文本含有大量噪声甚至错误,则容易造成误匹配,降低筛选准确率。适用场景有限,要求目标文本有明显规律。同时,规则设置太严容易能保证提高准确率,却容易漏选,规则太宽不容易漏选但准确率降低,需要有所取舍。2.基于语义,使用文本分类算法筛选出需要的文本。文本分类可以使用各种文本主题模型,或svm、贝叶斯分类模型、决策树等经典分类算法,或使用神经网络对文本进行分类。这一类方法更灵活,能处理更复杂的分类问题,准确度相对较高,但往往受限于训练语料,一般越是复杂的算法需要的训练语料的数量越大,且文本分类适用于文本类型明确且有限的情景,若语料库中的文本差异性过大,类型复杂,基于语义的文本分类算法难以应对。
技术实现要素:
4.针对现有海量文本数据的定向筛选方法存在的问题,本发明的主要目的是提供一种针对海量文本数据的定向筛选架构及方法,从海量文本数据中基于多通道数据以及融合模型筛选特定的文本数据,并且通过用户研判,不断更新模型,提高筛选准确率。本方法首先提出了一种基于大数据平台的计算架构和方法,本架构包括数据接入层、存储层、计算层、模型层、业务研判层、知识库层,提供数据接入能力、数据存储能力、数据实时/离线分析能力、模型训练能力、业务研判能力、模型动态更新能力,提供多通道数据筛选能力和多证据融合能力。单一的文本筛选方法不足以应对海量文本数据的筛选,本方法结合了基于规则和基于语义两种思路,首先设计了多项文本预处理步骤在计算层实时处理文本噪声和错误文本,然后在模型层使用基于规则的关键词匹配和句式匹配得到疑似目标文本,然后使用textcnn文本分类模型对疑似目标进行进一步分类,并针对textcnn网络的预训练做了优化。本方法结合了基于规则的方法的高效率,和基于语义的方法的高准确性的优点。且设计了自动化反馈修正方法,在业务模型层提供数据研判能力,充分利用业务人员在使用过程
中新产生的标注信息修正模型,提高文本筛选模型准确率,使筛选模型更符合业务需求。
5.本发明的技术方案为:
6.一种针对海量文本数据的定向筛选方法,其步骤包括:
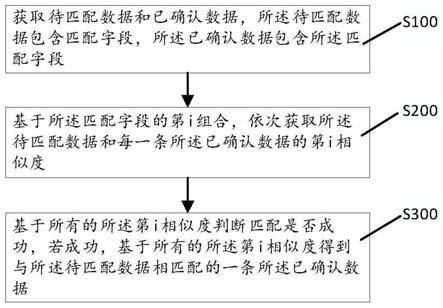
7.1)使用关键词匹配方法从待筛选文本中获取疑似目标文本;
8.2)从已标注的目标文本中提取该目标文本的常用句式,并将所提取的常用句式分为与业务强相关句式、与业务弱相关句式;对待筛选文本进行模糊句式匹配,如果与业务强相关句式匹配,则将当前待筛选文本判断为目标文本,若与业务弱相关句式匹配,则将当前待筛选文本判定为疑似目标文本;
9.3)使用训练后的文本分类模型textcnn对每一疑似目标文本进行分类;
10.4)根据疑似目标文本匹配上的关键词的个数确定该疑似目标文本的评估值e1;根据文本分类模型textcnn对疑似目标文本的分类判别结果,确定该疑似目标文本的评估值e2;基于疑似目标文本与外部辅助语料的信息匹配结果确定该疑似目标文本的评估值e3;然后基于疑似目标文本的评估值e1、评估值e2和评估值e3,计算得到该疑似目标文本最终的加权评分;将加权评分高于设定阈值的疑似目标文本反馈给业务研判层;
11.5)业务研判层确定反馈的疑似目标文本是否为目标文本并给出相应的标注;然后根据新标注的数据更新关键词、添加匹配句式、训练更新文本分类模型textcnn。
12.进一步的,如果一常用句式始终包含设定关键词,则该常用句式为与业务强相关句式,否则为与业务弱相关句式。
13.进一步的,目标文本的标注信息包括文本关键词、文本中的实体名称。
14.进一步的,更新关键词的方法为:计算当前关键词词库中的关键词在最新标注为目标文本中的出现频率,若出现频率低于设定阈值则舍去对应关键词,并将最新标注为目标文本中的新出现的关键词添加到关键词词库中。
15.进一步的,所述外部辅助语料包含与目标文本相关的命名实体信息;根据疑似目标文本与外部辅助语料中匹配的命名实体个数确定评估值e3。
16.进一步的,所述外部辅助语料与待筛选文本是同类型文本或不同类型文本。
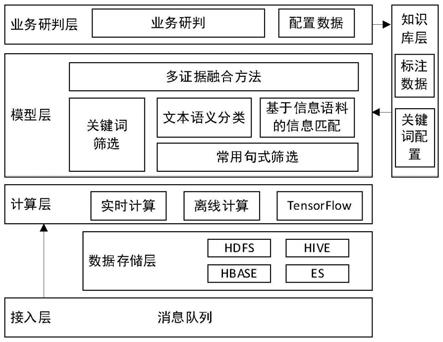
17.一种针对海量文本数据的定向筛选架构,其特征在于,包括数据接入层、存储层、计算层、模型层、业务研判层和知识库层;其中,数据接入层,用于接入数据;存储层,用于对接入的数据进行持久化存储;模型层,用于分别利用多通道数据筛选模型、多证据融合模型对海量文本数据进行文本筛选;以及根据知识库层存储的研判数据以及筛选配置数据对多通道数据筛选模型、多证据融合模型进行更新;其中,多通道数据筛选模型使用关键词匹配方法从待筛选文本中获取疑似目标文本;以及从已标注的目标文本中提取该目标文本的常用句式,并将所提取的常用句式分为与业务强相关句式、与业务弱相关句式,然后对待筛选文本进行模糊句式匹配,如果与业务强相关句式匹配,则将当前待筛选文本判断为目标文本,若与业务弱相关句式匹配,则将当前待筛选文本判定为疑似目标文本;计算层,用于使用训练后的文本分类模型textcnn对每一疑似目标文本进行分类;以及根据疑似目标文本匹配上的关键词的个数确定该疑似目标文本的评估值e1;根据文本分类模型textcnn对疑似目标文本的分类判别结果,确定该疑似目标文本的评估值e2;基于疑似目标文本与外部辅助语料的信息匹配结果确定该疑似目标文本的评估值e3;然后基于疑似目标文本的评估值e1、评估值e2和评估值e3,计算得到该疑似目标文本最终的加权评分;业务研判层,用于
确定反馈的疑似目标文本是否为目标文本并给出相应的标注以及下发筛选配置给模型层;然后模型层根据新标注的数据更新关键词、添加匹配句式、训练更新文本分类模型textcnn;知识库层,用于存储业务研判层的研判数据以及筛选配置数据。
18.进一步的,所述接入层采用消息队列实现数据的接入。
19.本方法一方面针对海量文本数据的筛选提出一种计算架构,为业务提供定向筛选能力;第二个方面提出一种多通道数据筛选流程对文本数据进行筛选,第三个方面提出一种多证据融合方法对筛选出的文本进行评分,并通过业务人员的持续标注自动化反馈,提升文本筛选准确率。
20.根据本发明的第一个方面,针对海量数据的定向筛选场景,设计一种计算架构,提供数据接入、存储、实时计算、离线计算、模型筛选、业务研判、自动更新模型的闭环解决方案。该设计架构主要是基于消息队列实现数据的接入与持久化,提供spark streaming以及flink开发接口,支持实时计算能力,提供spark离线计算接口,支持提交离线计算任务,同时提供tensorflow机器学习平台,支持数据模型的训练与发布;在模型层,针对具体的海量文本数据筛选场景,提供多通道数据筛选模型以及多证据融合模型进行文本筛选;在业务研判层,支持用户对筛选数据进行研判以及下发新的筛选配置(例如关键词等);知识库层存储用户的研判数据以及配置数据等;模型层读取知识库层存储的用户研判结果以及配置数据进行模型的更新,形成闭环。
21.本发明的第二个方面,提出一种多通道数据筛选方法对文本数据进行筛选。途径一,根据业务需求建立关键词库,在模型层筛选出包含关键词的文本,但由于文本数量巨大且文本中存在噪声和错误,以及中文词汇的一词多义现象,命中关键词的文本不能保证是目标文本,需要进行进一步判断;途径二,提取已标注的目标文本的常用句式(句式提取方法可详见参考文献:李伟.现代汉语句型自动识别的研究[d].厦门大学)。其中,经系统推荐得到推荐文本,业务人员在推荐文本中进行研判,研判结果是正类的即为目标文本,标注信息包括多方面信息,包括该文本是否是目标文本、文本关键词、文本中的实体名称。并将这些常用句式分为与业务强相关句式,和与业务弱相关的句式,句式是否与业务强相关是通过该剧始终是否包含关键词判断的,如果包含关键词,则是强相关,否则是弱相关。在模型层对待筛选的文本进行模糊句式匹配,如果能匹配上业务强相关句式,则直接判断为目标文本,若匹配上业务弱相关句式,则待下一步处理。根据以上两个途径的结果,命中关键词的文本和匹配上业务弱相关的文本不能确定是否是目标文本。使用标注文本训练textcnn文本分类模型,textcnn对文本浅层特征的抽取能力很强,在短文本领域如搜索、对话领域、意图分类时效果很好,应用广泛,且速度快,可以在语义层面有效对待确定文本进行进一步分类。
[0022]
本发明的第三个方面,提出一种多证据融合方法对筛选出的文本进行评分,并通过业务人员的持续标注自动化反馈,提升文本筛选准确率。主要有三方面的证据,(1)关键词。在文本筛选任务中,关键词筛选是最简单有效的方法之一,命中关键词的个数更多的文本可能是目标文本的概率更高,本发明在模型层首先对文本进行关键词匹配;(2)文本语义分类模型。依据文本匹配上的业务强相关句式或弱相关句式,以及textcnn的分类模型判别结果,分别设定相应的分数,本发明在模型层提供文本分类能力;(3)基于外部辅助语料的信息匹配。引入外部语料辅助判断,由于外部辅助语料不一定和待筛选文本是同类型文本,
但包含与目标文本相关的信息,即存在目标文本中的命名实体,如人物、机构等,可以对辅助语料在模型层进行命名实体识别,抽取相关的信息,计算文本中出现的相关实体个数。综合以上三方面的证据,对文本给出最终的加权评分。系统将有限推荐评分较高的文本。
[0023]
本发明的第四个方面,设计了一种有效的自动化反馈优化机制。若业务人员在使用系统时,对推荐文本给出了新的标注。为了使系统拥有持续提高筛选准确度的能力,使用新标注的数据更新关键词、添加匹配句式、更新textcnn文本分类模型,这种自动化的反馈机制可以充分利用标注信息,使模型的筛选结果更贴近业务需求。考虑到关键词的时效性,系统将对每个关键词在最近一段时间的筛选文本中出现的次数进行统计,若出现次数过少,则予以删除。
[0024]
与现有技术相比,本发明的积极效果为:
[0025]
(1)针对海量文本数据的定向筛选,提供一种计算架构以及闭环的解决方案,提供离线、实时计算能力以及多通道筛选与融合模型,并且基于研判数据可以持续提高模型筛选的准确率;
[0026]
(2)设计了一种多通道数据筛选流程及方法,结合基于规则和基于语义的文本筛选方法,高效处理海量文本数据,使用多重筛选标准保证筛选准确率;
[0027]
(3)使用多方面证据对文本筛选结果进行验证,一方面加强了筛选结果可信度,另一方面也为业务人员的判别提供了便利;
[0028]
(4)设计了多通道的反馈修正机制,虑及关键词的时效性,即时更新筛选模型,使得文本筛选系统可以根据业务需求进行即时修正。
附图说明
[0029]
图1为针对海量文本数据的定向筛选架构示例图;
[0030]
图2为多通道数据筛选流程图;
[0031]
图3为多证据推荐文本评分流程图;
[0032]
图4为多通道反馈修正机制图。
具体实施方式
[0033]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图,对针对海量文本数据的定向筛选架构及方法进一步详细说明。
[0034]
图1给出了针对海量文本数据的定向筛选架构示意图。如图中所示,整体架构分为5部分,主要包括数据接入子系统,数据存储子系统,实时计算子系统,模型子系统,业务应用子系统。数据接入层主要是提供实时的海量文本数据接入能力,数据存储层主要将消息队列的数据持久化到存储中,以供后续进行离线计算分析,计算层主要是提供实时计算能力(spark streaming,flink等)以及离线计算能力(spark),同时提供机器学习平台(tensorflow)支撑模型训练,模型层主要提供多通道数据筛选模型以及多证据融合模型支撑海量文本数据的筛选,研判层基于应用界面为业务人员提供研判能力,支持对筛选的文本数据进行人工研判,并且将研判结果写入到知识库层进行存储,模型层基于知识库层研判结果对海量文本数据筛选模型进行动态更新。
[0035]
图2为多通道数据筛选流程图。多通道数据筛选流程及方法:(1)关键词匹配:知识
库层建立关键词词库,用户通过业务研判层配置关键词,模型层遍历该词库,计算待筛选文本中包含关键词的个数;(2)句式匹配:在模型层根据训练语料中的正类文本,提取出现频率较高的句式,将句式信息分为业务强相关的句式和业务弱相关的句式,然后对待筛选文本进行句式匹配,与业务强相关句式相匹配的可直接判断为目标文本,与业务弱相关句式相匹配的进行下一步判断;(3)在模型层对训练语料进行分词、去停用词、纠错、长度截断等预处理,使用word-to-vector算法训练词向量,将文本使用向量表示,训练textcnn文本分类模型,对命中关键词的文本和匹配业务弱相关句式的文本,使用相同的预处理方式进行预处理和向量表示,使用训练好的分类模型进行分类。最终所得结果为:业务强相关句式相匹配的文本、与分类模型判断为正类的文本所取并集。
[0036]
图3是多证据推荐文本评分流程图。多证据融合方法:证据一:关键词。在模型层对文本中出现的关键词进行计数;证据二:语义判别。该部分包括在模型层根据文本匹配上的业务强相关句式或弱相关句式,以及textcnn的分类模型判别结果,给出相应的分数;证据三:基于外部辅助语料的信息匹配(外部辅助语料是根据业务方的要求获取的特定语料库,文本与辅助语料的匹配指的就是文本中包含的外部辅助预料中出现的不同的实体个数;同一实体重复出现不重复计数)。在模型层对外部辅助语料进行命名实体识别,抽取人名和组织机构名,计算文本中出现的实体个数。综合以上三方面的证据,对文本给出最终的加权评分,系统将优先推荐评分较高的文本。
[0037]
图4解释了多通道反馈修正机制。若业务人员在使用系统时,在业务研判层对推荐文本给出了新的标注。则使用新的标注数据,(1)统计原有关键词库中的每个关键词在近期正类文本中出现的次数,若次数过少(比如低于10次),则舍弃,并将正类文本的关键词添加入知识库层的关键词配置表;(2)提取常用句式添加入常用句式表;(3)将标注的正类和负类文本添加入模型训练语料库,重新训练textcnn分类模型。
[0038]
尽管为说明目的公开了本发明的具体内容、实施算法以及附图,其目的在于帮助理解本发明的内容并据以实施,但是本领域的技术人员可以理解:在不脱离本发明及所附的权利要求的精神和范围内,各种替换、变化和修改都是可能的。本发明不应局限于本说明书最佳实施例和附图所公开的内容,本发明要求保护的范围以权利要求书界定的范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。