1.本发明涉及数据处理技术领域,尤其涉及一种目标事件抽取数据处理系统。
背景技术:
2.随着互联网的迅速普及和发展,大量数据信息在网络中产生和传播,如何从海量自然语言文本中及时准确地找到需要的信息变得日益迫切。海量自然语言文档具有数据量大,结构不统一,冗余度较高、更新快等特点。现有技术中通常采用机器学习的方式训练得到一个事件抽取模型来进行事件抽取,事件抽取技术是从非结构化信息中抽取出用户感兴趣的事件,并以结构化呈现给用户。但是,直接采用一个事件抽取模型的方式进行事件抽取的方法比较依赖于语料,如果语料数量小、不全面或不合适的话会对事件抽取结果有很大的影响,尤其对于没有被作为训练样本的进行学习的事件类型,会导致事件抽取的准确度低,抽取的事件信息不完成整。由此可知,如何提高事件抽取结果的完整性和准确性,成为亟待解决的技术问题。
技术实现要素:
3.本发明目的在于,提供一种目标事件抽取数据处理系统,提高了目标事件抽取结果的完整性和准确性。
4.根据本发明一方面,提供了一种目标事件抽取数据处理系统,包括预先配置的事件论元角色配置表、预先配置的事件类型映射表、预设的目标事件数据结构、存储有计算机程序的存储器和处理器,其中,所述事件类型映射表用于存储触发词和事件类型的映射记录,所述触发词和事件类型的映射记录包括触发词字段和事件类型字段;所述事件论元角色配置表用于存储事件论元角色信息记录,所述事件论元角色信息记录包括事件类型字段、论元角色字段和论元角色优先级字段;所述事件论元角色配置表和预先配置的事件类型映射表同步更新,所述目标事件数据结构包括目标触发词数据段、目标事件类型数据段和目标论元角色数据段;
5.所述处理器执行所述计算机程序时,实现以下步骤:
6.步骤s1、从待处理文本中提取候选触发词,构建候选触发词列表{a1,a2,
…
a
n
},a
n
为第n个候选触发词,n的取值范围为1到n,n为待处理文本中候选触发词的数量;
7.步骤s2、基于所述事件类型映射表获取每一候选触发词对应的事件类型,若存在预设的目标事件类型,则将所述目标事件类型对应的候选触发词确定为目标触发词a
n0
,将所述目标触发词存储至所述目标触发词数据段、将所述目标数据类型存储至目标事件类型数据段,执行步骤s3,否则,确定所述待处理文本中不存在目标事件,结束流程;
8.步骤s3、根据所述事件论元角色配置表确定目标事件类型对应的目标论元角色列表{b1,b2,
…
b
m
},b1、b2、
…
b
m
的优先级依次降低,b
m
为第m个目标论元角色,m的取值范围为1到m,m为目标事件类型对应的目标论元角色数量,初始化m=1,初始化历史信息h
m
=a
m0
;
9.步骤s4、基于a
m0
、b
m
、h
m
从所述待处理文本中提取出第m论元信息c
m
;
10.步骤s5、比较m和m,若m<m,则设置m=m 1,返回执行步骤s4,若m=m,则将{c1,c2,
…
c
m
}存储至目标论元角色数据段,生成目标事件数据。
11.本发明与现有技术相比具有明显的优点和有益效果。借由上述技术方案,本发明提供的一种目标事件抽取数据处理系统可达到相当的技术进步性及实用性,并具有产业上的广泛利用价值,其至少具有下列优点:
12.本发明通过依次抽取触发词、事件类型和论元信息,且在论元抽取过程中,通过设置论元优先级以及融合历史信息,提高了论元信息抽取的准确性,进而也提高了目标事件抽取结果的完整性和准确性。
13.上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其他目的、特征和优点能够更明显易懂,以下特举较佳实施例,并配合附图,详细说明如下。
附图说明
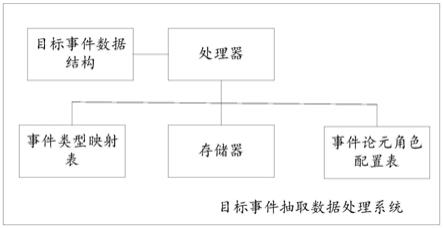
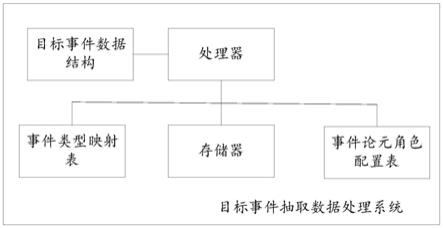
14.图1为本发明实施例提供的目标事件抽取数据处理系统示意图。
具体实施方式
15.为更进一步阐述本发明为达成预定发明目的所采取的技术手段及功效,以下结合附图及较佳实施例,对依据本发明提出的一种目标事件抽取数据处理系统的具体实施方式及其功效,详细说明如后。
16.本发明实施例提供了一种目标事件抽取数据处理系统,如图1所示,包括预先配置的事件论元角色配置表、预先配置的事件类型映射表、预设的目标事件数据结构、存储有计算机程序的存储器和处理器,其中,所述事件类型映射表用于存储触发词和事件类型的映射记录,所述触发词和事件类型的映射记录包括触发词字段和事件类型字段;所述事件论元角色配置表用于存储事件论元角色信息记录,所述事件论元角色信息记录包括事件类型字段、论元角色字段和论元角色优先级字段;所述事件论元角色配置表和预先配置的事件类型映射表同步更新,所述目标事件数据结构包括目标触发词数据段、目标事件类型数据段和目标论元角色数据段;
17.所述处理器执行所述计算机程序时,实现以下步骤:
18.步骤s1、从待处理文本中提取候选触发词,构建候选触发词列表{a1,a2,
…
a
n
},a
n
为第n个候选触发词,n的取值范围为1到n,n为待处理文本中候选触发词的数量;
19.步骤s2、基于所述事件类型映射表获取每一候选触发词对应的事件类型,若存在预设的目标事件类型,则将所述目标事件类型对应的候选触发词确定为目标触发词a
n0
,将所述目标触发词存储至所述目标触发词数据段、将所述目标数据类型存储至目标事件类型数据段,执行步骤s3,否则,确定所述待处理文本中不存在目标事件,结束流程;
20.步骤s3、根据所述事件论元角色配置表确定目标事件类型对应的目标论元角色列表{b1,b2,
…
b
m
},b1、b2、
…
b
m
的优先级依次降低,b
m
为第m个目标论元角色,m的取值范围为1到m,m为目标事件类型对应的目标论元角色数量,初始化m=1,初始化历史信息h
m
=a
m0
;
21.步骤s4、基于a
m0
、b
m
、h
m
从所述待处理文本中提取出第m论元信息c
m
;
22.步骤s5、比较m和m,若m<m,则设置m=m 1,返回执行步骤s4,若m=m,则将{c1,c2,
…
c
m
}存储至目标论元角色数据段,生成目标事件数据。
23.本发明实施例通过依次抽取触发词、事件类型和论元信息,且在论元抽取过程中,通过设置论元优先级以及融合历史信息,提高了论元信息抽取的准确性,进而也提高了目标事件抽取结果的完整性和准确性。
24.所述步骤s1具体可通过预先训练触发词发现模型,从待处理文本中抽取触发词或者设置触发词列表提取等形式来构建候选触发词列表,以下通过几个实施例来对触发词分类模型的构建方法进行详细说明:
25.实施方式一、
26.所述触发词发现模型基于预设的第一文本样本训练集和第一神经网络模型架构训练得到,所述第一文本训练集包括第一文本样本和对应的触发词,所述第一神经网络模型架构为序列标注架构;
27.所述处理器执行所述计算机程序时,还实现以下步骤:
28.步骤s10、从所述第一文本样本训练集获取第一文本样本,将预设的触发词问句与所述第一文本样本通过预设的分隔符进行拼接,得到第一拼接文本样本,基于预设的编码器对所述第一拼接文本样本进行编码,并设置第一拼接文本样本对应的第一实际输出标注序列,所述第一实际输出标注序列中,触发词问句对应的位置全部标注为1,第一文本样本对应的触发词位置标注为1,非触发词位置标注为0;
29.作为一种实施例,所述预设的分隔符为[sep],所述系统还配置有预设的mask算法,所述mask算法配置为将[sep]之前的输入部分遮蔽,对遮蔽部分只执行编码,不执行预测,所述mask算法使得第一神经网络模型架构在进行序列标注时,仅对[sep]之后的第一文本样本进行标注。
[0030]
步骤s20、将编码后的第一拼接文本样本作为预设的第一神经网络架构的输入,得的第一预测输出标注序列,基于所述第一拼接文本样本的第一实际输出标注序列和第一实际输出标注序列调整所述第一神经网络架构参数,训练得到所述触发词发现模型。
[0031]
可以理解的是,基于所述第一拼接文本样本的第一实际输出标注序列和第一实际输出标注序列调整所述第一神经网络架构参数,直接采用现有的模型训练方式即可,例如求解交叉熵,使得交叉熵最小时结束模型训练等,在此不再展开描述。
[0032]
实施方式二、
[0033]
所述触发词发现模型基于预设的第一文本训练集和二分类模型架构训练得到,需要说明的是,二分类模型架构具体可以为svm支持向量机,决策树等,也可以为序列标注模型,输出序列的每个位置上标注二分类结果,所述第一文本训练集包括第一文本样本和对应的触发词;
[0034]
所述处理器执行所述计算机程序时,还实现以下步骤:
[0035]
步骤s101、从所述第一文本样本训练集获取第一文本样本,将所述第一文本样本中的触发词作为正样本词,将所述第一文本样本进行切片,得到切片分词,随机抽取切片后的切片分词组成非触发词作为负样本词;
[0036]
需要说明的是,随着时间的发展,会有一些新的触发词出现,如果直接从文本中抽取当前文本中的非触发词作为负样本,如果后续这些非触发词转换为触发词,则会对模型
精确度有很大的影响。因此,采用将第一文本样本进行切片,得到切片分词,切片分词可能为第一文本样本的一个字,也可能为第一文本样本多个连续的字,随机抽取切片后的切片分词组成非触发词作为负样本词,这样组合的大的负样本词很大概率一定是负样本,很小概率会转换为正样本,起到了对负样本稀释的作用,提高了触发词发现模型的准确定和可靠性。
[0037]
步骤s102、将正样本和负样本分别基于预设的编码器进行编码后输入预设的二分类模型架构中进行分类预测,基于样本预测分类结果和实际分类结果调整所述二分类模型架构的参数,生成触发词发现模型。
[0038]
实施方式三、
[0039]
所述系统包括预设的触发词列表、预先训练的词性分析模型和语法分析模型,所述触发词列表包括触发词、触发词词性语法信息和/或触发词词性信息,所述步骤s1中、从待处理文本中提取候选触发词,包括:
[0040]
步骤s11、将所述待处理文本进行分词和去停用词处理,得到分词列表,将所述分词列表与所述触发词列表中的触发词进行匹配,得到候选分词列表;
[0041]
步骤s12、将所述待处理文本输入所述语法分析模型中获取候选分词的语法信息,和/或,将所述分词列表和所述待处理文本输入所述词性分析模型中,获取每一候选分词的词性信息;
[0042]
步骤s13、将候选分词列表中与所述触发词列表中对应触发词的词性信息和/或语法信息不一致的候选分词过滤掉,得到候选触发词。
[0043]
实施方式三能够在触发词列表中新增触发词,使得系统能够识别出新增触发词,能够适用于第事件信息的零次学习场景中,通过步骤s12和步骤s13,能够基于词性和语法,将错误提取的触发词进行过滤,提高提取触发词的精确性。
[0044]
实施方式四、
[0045]
为了更加全面地提取待处理文本中的触发词,进一步提高触发词提取的准确性和可靠性,可以将实施方式三与实施方式一、实施方式二中的至少一个触发词发现模型相结合,将不同实施方式求得的候选触发词求并集,得到所述候选触发词列表。
[0046]
以下通过几个具体实施方式对事件类型的确定实现方式进行详细说明:
[0047]
实施方式一、
[0048]
所述预先训练的事件类型分类模型基于预设的第二文本样本训练集和第二神经网络模型架构训练得到,所述第二文本样本训练集包括第二文本样本、第二文本样本对应的触发词、第二文本样本对应的事件类型,所述第二神经网络模型架构为多分类模型架构,输出向量为{d1,d2,
…
d
r
},r为事件类型名称数量,d
r
为输入触发词属于第r事件类型的概率值;
[0049]
所述处理器执行所述计算机程序时,实现以下步骤:
[0050]
步骤s201、从预设的第二文本样本训练集获取第二文本样本,基于第二文本样本对应的触发词生成对应的触发词所属事件类型问句,将对应的触发词所属事件类型问句与所述第二文本样本通过预设的分隔符进行拼接,得到第二拼接文本样本,基于预设的编码器对所述第二拼接文本样本进行编码,并设置第二拼接文本样本对应的第二实际输出向量,第二实际输出向量中,第二文本样本对应的触发词实际所属事件类型的概率值为1,其
他概率值为0;
[0051]
步骤s202、将编码后的第二拼接文本样本输入所述第二神经网络模型架构中,得到第二预测输出向量,基于所述第二预测输出向量和第二实际输出向量调整所述第二神经网络模型架构的参数,生成所述事件类型分类模型。
[0052]
可以理解的是,基于所述第二预测输出向量和第二实际输出向量调整所述第二神经网络模型架构的参数,直接采用现有的模型训练方式即可,例如求解交叉熵,使得交叉熵最小时结束模型训练等,在此不再展开描述。
[0053]
实施方式二、
[0054]
所述系统还包括事件类型名称列表{d1,d2,
…
d
r
},d
r
为第r个事件类型名称,r的取值范围为1到r,r为事件类型名称数量,所述步骤s2中,获取每一候选触发词对应的事件类型,包括:
[0055]
步骤s21、将d
r
输入预设的编码器进行编码,并对编码结果进行池化处理得到第r事件类型名称池化编码d
r’;
[0056]
其中,池化处理具体可以为将每列参数求平均,或者获取每列参数的最大值。
[0057]
步骤s22、将a
n
输入所述编码器,进行编码并对编码结果进行池化处理,得到第n候选触发词池化编码a
n’,d
r’和a
n’向量维度相同;
[0058]
步骤s23、判断是否存在r,使得r满足argmaxcos(a
n’,d
r’),且cos(a
n’,d
r’)>d1,其中,cos(a
n’,d
r’)表示a
n’与d
r’的余弦相似度,d1为预设的第一相似度阈值,若存在,将该第r事件类型确定为第n候选触发词对应的事件类型。
[0059]
所述步骤s23中,若不存在r,使得r满足argmaxcos(a
n’,d
r’),且cos(a
n’,d
r’)>d1,则执行步骤s24:
[0060]
步骤s24、获取从大到小排序的预设前g个cos(a
n’,d
r’)值{cos1,cos2,
…
cos
g
},cos
g
为第g个cos(a
n’,d
r’),g的取值为1到g,若任意g均满足cos
g 1
‑
cos
g
<d2,d2为预设的误差阈值,则执行步骤s25,否则,确定所述事件类型名称列表中不存在第n候选触发词对应的事件类型;
[0061]
步骤s25、将cos
g
对应的候选触发词与所述触发词列表进行匹配,若不存在于所述触发词列表中,则将对应的cos
g
从{cos1,cos2,
…
cos
g
}中删除;
[0062]
步骤s26、若执行步骤s25操作之后的{cos1,cos2,
…
cos
g
}为空集,则确定所述事件类型名称列表中不存在第n候选触发词对应的事件类型,否则,将执行步骤s25操作之后的{cos1,cos2,
…
cos
g
}中的最大cos
g
对应的事件类型确定为第n候选触发词对应的事件类型。
[0063]
需要说明的是,实施方式一对于已经通过模型训练的事件类型能够快速准确识别,实施方式二能够在事件类型名称列表中新增事件类型,有更好的扩展性,实施方式二能够适用于零次学习事件信息的场景中,即对于没有采用模型训练过得事件数据,也能够快速准确地抽取出来。
[0064]
作为一种实施例,所述论元信息抽取模型基于预设的第三文本样本训练集和第三神经网络模型架构训练得到,所述第三文本样本训练集包括y个第三文本样本{e1,e2,
…
e
y
},e
y
为第y个第三文本样本,e
y
对应的样本触发词为ea
y
,e
y
对应的样本论元角色{be1,be2,
…
be
ym
},e
y
对应的样本论元信息{ce1,ce2,
…
ce
ym
},其中,y的取值范围为1到y,be1、be2、
…
be
ym
的优先级依次降低,be
i
为e
y
对应的第i个样本论元角色,ce
i
为e
y
对应的第i个样
本论元信息,be
i
与ce
i
对应,i的取值范围为1到ym;所述第三神经网络模型架构为序列标注模型架构;
[0065]
所述处理器执行所述计算机程序时,还实现以下步骤:
[0066]
步骤s100、初始化y=1;
[0067]
步骤s200、初始化i=1,样本历史信息bh
y
=ea
y
;
[0068]
步骤s300、基于be
i
、ea
y
生成对应的样本论元角色问句文本bf
i
;
[0069]
步骤s400、将bf
i
、e
y
、bh
y
输入预设的编码器,对e
y
和bf
i
进行编码,得到el
y
,将el
y
输入所述第三神经网络模型架构,得到对应的第二预测输出标注序列lc
i
,lc
i
对应的bf
i
的位置标注为0;
[0070]
其中,所述步骤s400中,每一个论元信息的抽取,均融入了历史信息,即使得论元信息抽取模型已知样本触发词和已经抽取到的论元信息,即本轮抽取中,这几处已知位置一定不是目标标注位置,即这几个位置信息必然为标注为0。此外,论元角色按照预设的优先级排序,能够使得论元信息抽取模型先抽取易于抽取的论元信息,随着论元信息抽取难度增加,历史信息也增加,增加的历史信息能够引导模型更加快速准确地抽取出下一个论元信息。
[0071]
需要说明的是,步骤s400中也是对bf
i
和e
y
通过预设的分隔符进行了拼接,然后编码器基于bh
y
以及bf
i
和e
y
中对应的文字位置信息对拼接后的bf
i
和e
y
进行编码。预设的分隔符可以为[sep],mask算法使得第三神经网络模型架构在进行序列标注时,仅对[sep]之后的e
y
进行标注。
[0072]
步骤s500、基于e
y
、ce
i
生成第二实际输出标注序列ld
i
,所述第二实际输出标注序列中,e
y
对应的ce
i
位置标注为1,非ce
i
位置标注为0;
[0073]
步骤s600、基于lc
i
和ld
i
判断当前训练的第三神经网络模型架构是否达到预设的模型精度,若达到,则将当前第三神经网络模型架构确定为所述论元信息抽取模型,否则,执行步骤s700;
[0074]
步骤s700、基于lc
i
和ld
i
调整当前第三神经网络模型架构参数,比较i与ym的大小,若i<ym,则设置i=i 1,返回执行步骤s300,若i=ym,执行步骤s800;
[0075]
步骤s800、比较y与y的大小,若y<y,则设置y=y 1,返回执行步骤s200,若y=y,则返回执行步骤s100。
[0076]
需要说明的是,触发词发现模型、事件类型分类模型中设置为问句是为了在系统采用级联模型的情况下,保持与论元抽取模型的一致性,提高系统的精确度设置的,模型参数确定后,在实际使用过程中,采用触发词发现模型抽取触发词以及采用事件类型分类模型获取事件类型时可以不再输入对应的问句。但是论元抽取模型的问句仍要输入,因为论元抽取模型的问句还要起到引导论元抽取模型标注对应论元信息的作用。
[0077]
作为一种实施例,所述步骤s4包括:
[0078]
步骤s41、基于a
m0
、b
m
生成第m论元角色问句文本f
m
,将待处理文本、f
m
、h
m
输入预设的编码器中,对待处理文本和f
m
进行编码,得到l
m
,将l
m
输入所述论元信息抽取模型,得到对应的第二预测输出标注序列lc
m
;
[0079]
需要说明的是,步骤s41同步骤s400步骤一致,将待处理文本和f
m
基于预设的分隔
码进行拼接,再基于拼接后的待处理文本和f
m
的文字的位置信息以及当前的历史信息对拼接后的待处理文本和f
m
进行编码。
[0080]
步骤s42、基于lc
m
和l
m
,从所述待处理文本中抽取提取出第m论元信息c
m
。
[0081]
需要说明的是,由于论元信息抽取模型的信息标注结果仅是对待处理文本对应的信息进行标注,而实际输入的编码文本是拼接后的待处理文本和f
m
进行编码,因此需要根据待处理文本和f
m
原始文字的位置关系,结合论元信息抽取模型输出的序列标注结果确定对应的第m论元信息c
m
。
[0082]
需要说明的是,论元角色优先级可以直接基于历史经验进行确定,也可以基于用于输入进行确定,还可通过样本论元角色分布来确定,作为一种实施例,所述处理器执行所述计算机程序时,还实现以下步骤:
[0083]
步骤s301、基于预设的第三文本样本训练集中的所有样本论元角色组成的样本论元角色集合确定每一待判断论元角色优先级的事件类型对应的论元角色的优先级,其中,所述样本论元角色集合为{bex1,bex2,
…
bex
z
},bex
z
为第z个样本论元角色,z的取值范围为1到z,z为样本论元角色集合中的样本论元角色数量,待判断论元角色优先级的事件类型对应的论元角色集合为{bx1,bx2,
…
bx
w
},bx
w
为待判断论元角色优先级的事件类型对应的第w个论元角色,w的取值范围为1到w,w为待判断论元角色优先级的事件类型对应的论元角色数量;
[0084]
所述步骤s301具体包括:
[0085]
步骤s302、将bx
w
输入预设的编码器进行编码,并对编码结果进行池化处理得到待判断论元角色池化编码bx
w’;
[0086]
步骤s303、将bex
z
输入预设的编码器进行编码,并对编码结果进行池化处理得到样本论元角色池化编码bex
z’,bx
w’和bex
z’的向量维度相同;cos(bx
w’,bex
z’)
[0087]
步骤s304、获取bx
w
对应的优先级权重p
w
:
[0088][0089]
步骤s305、按照bx
w
对应的优先级权重p
w
从大到小的顺序生成待判断论元角色优先级的事件类型对应的论元角色的优先级。
[0090]
需要说明的是,本发明实施例中所涉及所有编码器均为同一个编码器,作为一种实施例,所述系统还包括预先配置的文字序号映射表,用于存储文字与序号的映射关系,每一文字对应一个唯一的序号,所述编码器基于所述文字序号映射表将待编码文本的每一文字转换为对应的序号,然后基于每一序号在所述待编码文本中的位置信息,将每一序号编码为预设维度的向量,若所述编码器还接收到历史信息,则基于所述历史信息以及每一序号在所述待编码文本中的位置信息将每一序号编码为预设维度的向量。具体的,所述编码器为预训练语言模型,所述预训练语言模型包括bert模型、roberta模型和albert模型等。
[0091]
需要说明的是,一些示例性实施例被描述成作为流程图描绘的处理或方法。虽然流程图将各步骤描述成顺序的处理,但是其中的许多步骤可以被并行地、并发地或者同时实施。此外,部分步骤的顺序可以被重新安排。当其操作完成时处理可以被终止,但是还可以具有未包括在附图中的附加步骤。处理可以对应于方法、函数、规程、子例程、子程序等等。
[0092]
以上所述,仅是本发明的较佳实施例而已,并非对本发明作任何形式上的限制,虽然本发明已以较佳实施例揭露如上,然而并非用以限定本发明,任何熟悉本专业的技术人员,在不脱离本发明技术方案范围内,当可利用上述揭示的技术内容作出些许更动或修饰为等同变化的等效实施例,但凡是未脱离本发明技术方案的内容,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化与修饰,均仍属于本发明技术方案的范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。