技术特征:
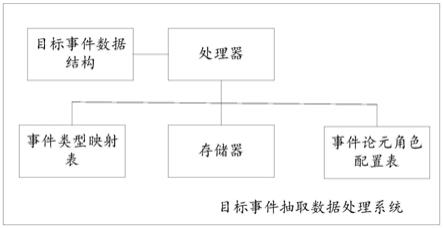
1.一种目标事件抽取数据处理系统,其特征在于,包括预先配置的事件论元角色配置表、预先配置的事件类型映射表、预设的目标事件数据结构、存储有计算机程序的存储器和处理器,其中,所述事件类型映射表用于存储触发词和事件类型的映射记录,所述触发词和事件类型的映射记录包括触发词字段和事件类型字段;所述事件论元角色配置表用于存储事件论元角色信息记录,所述事件论元角色信息记录包括事件类型字段、论元角色字段和论元角色优先级字段;所述事件论元角色配置表和预先配置的事件类型映射表同步更新,所述目标事件数据结构包括目标触发词数据段、目标事件类型数据段和目标论元角色数据段;所述处理器执行所述计算机程序时,实现以下步骤:步骤s1、从待处理文本中提取候选触发词,构建候选触发词列表{a1,a2,
…
a
n
},a
n
为第n个候选触发词,n的取值范围为1到n,n为待处理文本中候选触发词的数量;步骤s2、基于所述事件类型映射表获取每一候选触发词对应的事件类型,若存在预设的目标事件类型,则将所述目标事件类型对应的候选触发词确定为目标触发词a
n0
,将所述目标触发词存储至所述目标触发词数据段、将所述目标数据类型存储至目标事件类型数据段,执行步骤s3,否则,确定所述待处理文本中不存在目标事件,结束流程;步骤s3、根据所述事件论元角色配置表确定目标事件类型对应的目标论元角色列表{b1,b2,
…
b
m
},b1、b2、
…
b
m
的优先级依次降低,b
m
为第m个目标论元角色,m的取值范围为1到m,m为目标事件类型对应的目标论元角色数量,初始化m=1,初始化历史信息h
m
=a
m0
;步骤s4、基于a
m0
、b
m
、h
m
从所述待处理文本中提取出第m论元信息c
m
;步骤s5、比较m和m,若m<m,则设置m=m 1,返回执行步骤s4,若m=m,则将{c1,c2,
…
c
m
}存储至目标论元角色数据段,生成目标事件数据。2.根据权利要求1所述的系统,其特征在于,还包括预设的触发词列表、预先训练的词性分析模型和语法分析模型,所述触发词列表包括触发词、触发词词性语法信息和/或触发词词性信息,所述步骤s1中、从待处理文本中提取候选触发词,包括:步骤s11、将所述待处理文本进行分词和去停用词处理,得到分词列表,将所述分词列表与所述触发词列表中的触发词进行匹配,得到候选分词列表;步骤s12、将所述待处理文本输入所述语法分析模型中获取候选分词的语法信息,和/或,将所述分词列表和所述待处理文本输入所述词性分析模型中,获取每一候选分词的词性信息;步骤s13、将候选分词列表中与所述触发词列表中对应触发词的词性信息和/或语法信息不一致的候选分词过滤掉,得到候选触发词。3.根据权利要求2所述的系统,其特征在于,所述系统还包括触发词发现模型,用于从待处理文本中提取候选触发词,所述触发词分类模型基于预设的第一文本样本训练集和第一神经网络模型架构训练得到,所述第一文本训练集包括第一文本样本和对应的触发词,所述第一神经网络模型架构为序列标注架构;所述处理器执行所述计算机程序时,还实现以下步骤:
步骤s10、从所述第一文本样本训练集获取第一文本样本,将预设的触发词问句与所述第一文本样本通过预设的分隔符进行拼接,得到第一拼接文本样本,基于预设的编码器对所述第一拼接文本样本进行编码,并设置第一拼接文本样本对应的第一实际输出标注序列,所述第一实际输出标注序列中,触发词问句对应的位置全部标注为1,第一文本样本对应的触发词位置标注为1,非触发词位置标注为0;步骤s20、将编码后的第一拼接文本样本作为预设的第一神经网络架构的输入,得的第一预测输出标注序列,基于所述第一拼接文本样本的第一实际输出标注序列和第一实际输出标注序列调整所述第一神经网络架构参数,训练得到所述触发词发现模型。4.根据权利要求3所述的系统,其特征在于,所述步骤s13之后还包括:步骤s14、基于所述编码器对所述待处理文本进行编码,并输入所述触发词发现模型中,得到候选触发词;步骤s15、将所述步骤s13和步骤s14得到的候选触发词求并集,生成所述候选触发词列表。5.根据权利要求2所述的系统,其特征在于,所述系统还包括触发词发现模型,用于从待处理文本中提取候选触发词,所述触发词发现模型基于预设的第一文本训练集和二分类模型架构训练得到,所述第一文本训练集包括第一文本样本和对应的触发词;所述处理器执行所述计算机程序时,还实现以下步骤:步骤s101、从所述第一文本样本训练集获取第一文本样本,将所述第一文本样本中的触发词作为正样本词,将所述第一文本样本进行切片,得到切片分词,随机抽取切片后的切片分词组成非触发词作为负样本词;步骤s102、将正样本和负样本分别基于预设的编码器进行编码后输入预设的二分类模型架构中进行分类预测,基于样本预测分类结果和实际分类结果调整所述二分类模型架构的参数,生成触发词发现模型。6.根据权利要求5所述的系统,其特征在于,骤s104、基于所述编码器对所述待处理文本进行分词和去停用词处理,得到分词列表,将每一分词进行编码,并输入所述触发词发现模型中,将分类结果为触发词的分词确定为候选触发词;步骤s105、将所述步骤s13和步骤s104得到的候选触发词求并集,生成所述候选触发词列表。7.根据权利要求1所述的系统,其特征在于,所述系统还包括预先训练的论元信息抽取模型,所述论元信息抽取模型基于预设的第三文本样本训练集和第三神经网络模型架构训练得到,所述第三文本样本训练集包括y个第三文本样本{e1,e2,
…
e
y
},e
y
为第y个第三文本样本,e
y
对应的样本触发词为ea
y
,e
y
对应的样本论元角色{be1,be2,
…
be
ym
},e
y
对应的样本论元信息{ce1,ce2,
…
ce
ym
},其中,y的取值范围为1到y,be1、be2、
…
be
ym
的优先级依次降低,be
i
为e
y
对应的第i个样本论元角色,ce
i
为e
y
对应的第i个样本论元信息,be
i
与ce
i
对应,i的取值范围为1到ym;所述第三神经网络模型架构为序列标注模型架构;
所述处理器执行所述计算机程序时,还实现以下步骤:步骤s100、初始化y=1;步骤s200、初始化i=1,样本历史信息bh
y
=ea
y
;步骤s300、基于be
i
、ea
y
生成对应的样本论元角色问句文本bf
i
;步骤s400、将bf
i
、e
y
、bh
y
输入预设的编码器,对e
y
和bf
i
进行编码,得到el
y
,将el
y
输入所述第三神经网络模型架构,得到对应的第二预测输出标注序列lc
i
,lc
i
对应的bf
i
的位置标注为0;步骤s500、基于e
y
、ce
i
生成第二实际输出标注序列ld
i
,所述第二实际输出标注序列中,e
y
对应的ce
i
位置标注为1,非ce
i
位置标注为0;步骤s600、基于lc
i
和ld
i
判断当前训练的第三神经网络模型架构是否达到预设的模型精度,若达到,则将当前第三神经网络模型架构确定为所述论元信息抽取模型,否则,执行步骤s700;步骤s700、基于lc
i
和ld
i
调整当前第三神经网络模型架构参数,比较i与ym的大小,若i<ym,则设置i=i 1,返回执行步骤s300,若i=ym,执行步骤s800;步骤s800、比较y与y的大小,若y<y,则设置y=y 1,返回执行步骤s200,若y=y,则返回执行步骤s100。8.根据权利要求3
‑
7中任意一项所述的系统,其特征在于,所述系统还包括预先配置的文字序号映射表,用于存储文字与序号的映射关系,每一文字对应一个唯一的序号,所述编码器基于所述文字序号映射表将待编码文本的每一文字转换为对应的序号,然后基于每一序号在所述待编码文本中的位置信息,将每一序号编码为预设维度的向量,若所述编码器还接收到历史信息,则基于所述历史信息以及每一序号在所述待编码文本中的位置信息将每一序号编码为预设维度的向量。9.根据权利要求8所述的系统,其特征在于,所述编码器为预训练语言模型,所述预训练语言模型包括bert模型、roberta模型和albert模型。10.根据权利要求3所述的系统,其特征在于,所述预设的分隔符为[sep],所述系统还配置有预设的mask算法,所述mask算法配置为将[sep]之前的输入部分遮蔽,对遮蔽部分只执行编码,不执行预测。
技术总结
本发明涉及一种目标事件抽取数据处理系统,包括预先配置的事件论元角色配置表、预先配置的事件类型映射表、预设的目标事件数据结构、存储有计算机程序的存储器和处理器,其中,所述事件类型映射表用于存储触发词和事件类型的映射记录,所述触发词和事件类型的映射记录包括触发词字段和事件类型字段;所述事件论元角色配置表用于存储事件论元角色信息记录,所述事件论元角色信息记录包括事件类型字段、论元角色字段和论元角色优先级字段;所述事件论元角色配置表和预先配置的事件类型映射表同步更新,所述目标事件数据结构包括目标触发词数据段、目标事件类型数据段和目标论元角色数据段。本发明提高了目标事件抽取结果的完整性和准确性。性和准确性。性和准确性。
技术研发人员:林方 傅晓航 常宏宇 张正义
受保护的技术使用者:中科雨辰科技有限公司
技术研发日:2021.09.02
技术公布日:2021/11/30
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。