1.本发明涉及工业过程故障监测与诊断领域,尤其涉及一种基于小样本学习的工业报警泛滥根源诊断方法及存储介质。
背景技术:
2.近些年,分布式控制系统或数据采集与监控系统的广泛应用,生产和管理的自动化水平逐步提高。但同时,由于大型工业设施中包含大量生产设备和复杂的生产过程,导致异常状况频现并且容易快速传播扩散,为工业生产带来严峻的安全问题。而报警监控系统作为现代大规模复杂工业的核心成分,其性能的优劣直接影响到工业生产运行的安全性、稳定性和高效性。通过近些年国内外学者的研究,报警监控中的诸多问题,如误报警、漏报警、抖振报警和关联报警等,都得到了有效解决,但报警泛滥仍是困扰操作运营人员的难点问题。
3.报警泛滥是制约大型工业系统中报警监控系统性能的主要瓶颈。ansi/isa
‑
18.2标准将报警泛滥定义为“大量报警信号出现导致报警率超过运营人员响应能力的情形”,规定每10分钟出现10个报警作为识别报警泛滥出现的基准阈值和每10分钟5个作为识别报警泛滥消逝的阈值,并建议报警泛滥的出现时间不超过总运营时间的1%。但实际工业中的报警泛滥无论是在报警率还是占比时间上,都远远超过这个标准。由于大型工业设施规模庞大、结构复杂,大量的监测变量和复杂的网络结构,导致异常状况频发并广泛传播,形成报警泛滥。而报警泛滥的频繁出现和传播,导致报警系统丧失其有效性,无法给操作运营人员提供有效的报警监控信息,从而极易导致生产事故的发生。因此,如何针对报警泛滥的分析与抑制研究成为学术界和工业界共同关注的问题。
4.报警泛滥的形成原因众多、类型不同、复杂程度不同,给报警泛滥的分析和应用带来挑战。现有研究方法主要集中于报警泛滥序列的相似性比对和报警泛滥序列的模式挖掘、和报警泛滥的分类方法,为报警泛滥的研究提供有效解决方法。然而,这些理论都是基于连续过程数据,但是忽略了与异常状况直接相关的报警事件数据,相比于连续过程数据,报警事件数据包含更少的数据量,并且包含有效信息的比例更大。同时,由于实际工业中,带标签的样本获取步骤繁琐、成本代价高,导致大量根源诊断方法应用受到限制,如何利用少量样本建立面向报警泛滥的根源诊断模型也值得进一步关注。
技术实现要素:
5.为了解决实际工业中,带标签的样本获取步骤繁琐、成本代价高,导致大量根源诊断方法应用受到限制的技术问题,本发明提供了一种利用报警事件数据和少量带标签样本来构建工业报警泛滥根源诊断模型的方法。相比于连续过程数据,报警事件数据包含更少的数据量,但由于其与故障问题直接相关,因此,包含有效信息的比例更大。通过对报警事件日志进行预处理,然后提取报警泛滥序列;利用word2vec方法对提取的报警泛滥序列进行文本编码,得到新的可直接计算的报警泛滥序列。
6.由于带标签的工业故障样本不易直接获取,本发明提出了一种基于小样本学习(few
‑
shot learning,fsl)的工业报警泛滥根源诊断方法,量化不同故障类间差异。并提出一种基于原型网络的改进理论,用于进一步分析报警事件数据的时间序列特性,该方法利用长短期记忆网络(long short term memory,lstm)进行特征提取,通过训练,得到诊断模型。基于小样本学习的建模方法利用少量报警泛滥事件序列构建报警泛滥根源诊断模型,可以提高诊断的实用性和有效性。所提方法的具体步骤如下:
7.获取历史报警事件日志;
8.对所述历史报警事件日志进行预处理;
9.提取由显著故障引起的工业报警泛滥序列;
10.搭建基于词嵌入的报警事件数据结构化编码模型,将所述历史报警事件日志输入所述基于词嵌入的报警事件数据结构化编码模型,不断更新模型参数,获取最佳结构化编码模型;
11.通过所述最佳结构化编码模型,对所述由显著故障引起的工业报警泛滥序列进行数据编码,得到结构化编码的工业报警泛滥序列;
12.通过长短期记忆网络提取所述结构化编码的报警泛滥序列中各序列的时间序列特征,结合基于原型网络的小样本学习,获取各报警泛滥序列的空间表达向量,从而搭建工业报警泛滥根源诊断模型;
13.将待诊断的工业报警事件日志进行预处理及结构化编码后,输入所述工业报警泛滥根源诊断模型,并输出最终根源诊断类型。
14.进一步地,所述预处理包括:
15.检查并统一报警事件数据配置信息和日志格式,修改不规范数据类型,并进一步删除信息不完整的事件数据;
16.去除抖振报警及冗余报警,通过设置延时器、滤波器、阈值死区、时间死区进行优化处理,提取由显著故障引起的报警泛滥序列。
17.进一步地,所述由显著故障引起的工业报警泛滥序列表示为:
18.f=[a1,a2,
…
,a
m
,1≤m≤m]
[0019]
其中,a
m
表示报警泛滥序列f中第m个报警,m表示报警泛滥序列的长度。
[0020]
进一步地,所述搭建基于词嵌入的报警事件数据结构化编码模型,将所述历史报警事件日志输入所述基于词嵌入的报警事件数据结构化编码模型,不断更新模型参数,获取最佳结构化编码模型的步骤,具体包括:
[0021]
提取各连续历史报警事件日志中所有独立报警事件数据标签;
[0022]
根据n个所述独立报警事件数据标签制作报警数据类型库,利用独热编码获得报警事件数据的初步结构化编码表示;
[0023]
初始化一个n*d维的权重矩阵v,其中n为权重矩阵v的行数,与独立报警事件数据标签的个数相等,d为权重矩阵v的列数,利用所述报警事件数据的初步结构化编码表示做内积计算,获取报警事件数据的结构化编码结果;
[0024]
初始化d*n维的权重矩阵w,其中d为权重矩阵w的行数,n为权重矩阵w的列数,利用多个连续历史报警事件日志库中,当前报警事件数据的结构化编码结果与其前后c个窗口内的报警事件数据结构化编码结果做内积计算,结合softmax函数对计算结果进一步映射,
从而建立基于词嵌入的报警事件数据结构化编码模型;
[0025]
计算所述基于词嵌入的报警事件数据结构化编码模型的平均对数概率,最大化期望输出概率,利用梯度下降法进行参数更新,获取最佳结构化编码模型。
[0026]
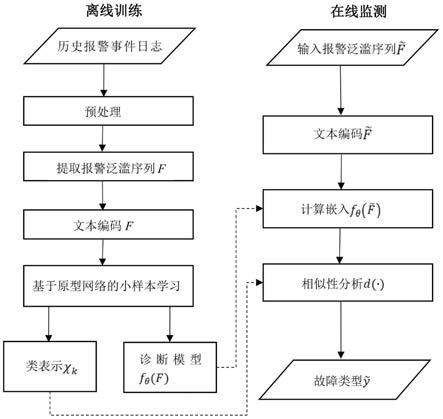
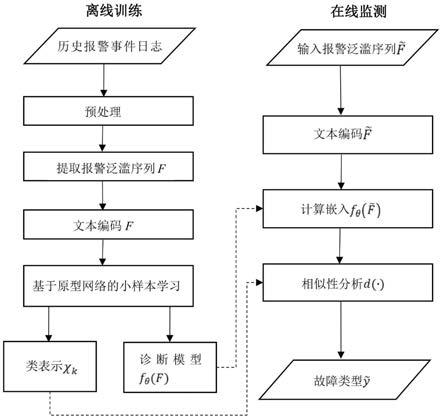
进一步地,所述通过长短期记忆网络提取所述结构化编码的报警泛滥序列中各序列的时间序列特征,结合基于原型网络的小样本学习,获取各报警泛滥序列的空间表达向量,从而搭建工业报警泛滥根源诊断模型的步骤,具体包括:
[0027]
通过长短期记忆网络提取所述结构化编码的报警泛滥序列的时序信息,将不同长度的所述结构化编码的报警泛滥序列转化为相同维度大小的编码矩阵;
[0028]
将不同类型的报警泛滥序列的编码矩阵分布到高维空间平面,计算同一根源类型下不同报警泛滥序列的空间表达向量,利用其空间均值作为每类根源类型的原型表示,从而建立工业报警泛滥根源诊断模型。
[0029]
进一步地,所述将待诊断的工业报警事件日志进行预处理及结构化编码后,输入所述工业报警泛滥根源诊断模型,并输出最终根源诊断类型的步骤,具体包括:
[0030]
将待诊断的工业报警事件日志经过预处理后,提取待诊断的工业报警泛滥序列;
[0031]
通过所述最佳结构化编码模型,对所述待诊断的工业报警泛滥序列进行结构化编码,得到结构化编码的待诊断报警泛滥序列;
[0032]
将所述结构化编码的待诊断报警泛滥序列输入所述工业报警泛滥根源诊断模型,计算待诊断报警泛滥序列的空间表达向量;
[0033]
将所述待诊断报警泛滥序列的表达向量与每类根源类型的原型表示进行欧氏距离计算,采用最近邻比较,将空间相对距离最小的根源类型作为最终根源诊断类型。
[0034]
为了实现上述目的,本发明还提供了一种存储介质,所述存储介质为计算机可读存储介质,所述计算机可读存储介质中存储有任一所述的基于小样本学习的工业报警泛滥根源诊断方法。
[0035]
本发明的有益效果在于:在实际工业故障样本缺乏的情况下,提出一种基于报警事件数据和少量样本来构建高精度报警泛滥根源诊断模型的方法,可以提高诊断的实用性和有效性。本发明应用于工业监测与诊断系统中,针对报警泛滥根源诊断的问题,提出基于小样本学习的工业报警泛滥根源诊断方法,在实际工业故障样本缺乏的情况下,利用所提方法可以快速诊断出引起报警泛滥的根源故障,从而确保生产过程的安全性,对于提升工业监控系统的性能具有重要意义。
附图说明
[0036]
下面将结合附图及实施例对本发明作进一步说明,附图中:
[0037]
图1为本发明一种基于小样本学习的工业报警泛滥根源诊断方法的根源诊断流程图;
[0038]
图2为本发明部分报警泛滥序列图;
[0039]
图3为本发明部分编码后报警泛滥序列图;
[0040]
图4为本发明一种基于小样本学习的工业报警泛滥根源诊断方法诊断每种故障类型的正确率图。
具体实施方式
[0041]
为了对本发明的技术特征、目的和效果有更加清楚的理解,现对照附图详细说明本发明的具体实施方式。
[0042]
本实施例基于vam报警平台模型设计仿真实验,验证方法的有效性。所采用的数据来源于vam平台仿真实验,通过触发故障生成报警事件日志。该系统包含35个不同的故障(mal1~35),其中显著故障包括mal15、16、17、23、24、25、26、27、27、28、29、30、32和33。这些显著故障都有很大可能导致报警泛滥的发生。为了保证工业故障仿真的合理性,对报警系统虚拟配置增加了若干规则,如下:
[0043]
a)每次只触发一个异常事件;
[0044]
b)引发下一个异常事件前,应确保系统处于稳定运行状态,即先前异常事件的影响被视为结束;
[0045]
在本实施中,故障的模拟时间设置为从20到60分钟,故障模拟时间段间距为10分钟。延时器被配置为300秒,以抑制抖振报警等虚假报警泛滥。
[0046]
如图1所示,所提方法主要包括离线训练和在线诊断两个部分。
[0047]
步骤1、离线训练:
[0048]
从报警事件日志中提取报警泛滥序列,然后进行文本编码得到新的报警泛滥序列,作为模型输入,利用长短期记忆网络和基于原型网络的小样本学习方法搭建根源诊断模型。
[0049]
步骤1.1、报警泛滥序列提取:
[0050]
从历史报警事件日志中准确提取报警泛滥序列是进行根源诊断的先决条件。但是,由于日志格式和存在抖振报警等问题,使报警泛滥根源诊断方法的有效性受到质疑。因此,对历史报警事件日志进行充分的预处理能够保证数据的合理性和有效性,以便提取更为准确的工业报警泛滥序列。对历史报警事件日志的预处理分为两步,具体如下:
[0051]
a)时间戳和日志格式的检查:不同历史报警日志可能会有不同的格式,导致分析困难。因此需要进一步修改或删除不规整数据,以确保数据格式统一;
[0052]
b)减少抖振报警:表示采用延时定时器,可以有效规避虚假报警泛滥的出现,进一步增强真实故障问题引起的报警泛滥序列的合理性。
[0053]
经过预处理,大大减少了历史报警事件日志中的滋扰报警。进一步的,根据ansi
‑
isa
‑
18.2标准规定:“每10分钟出现10个报警作为识别报警泛滥出现的基准阈值和每10分钟5个作为识别报警泛滥消逝的阈值”。进一步的,报警泛滥序列f提取并被表示为:
[0054]
f=<a1,a2,
…
,a
m
,1≤m≤m>,
[0055]
其中a
m
表示序列f中第m个报警,m表示报警泛滥序列的长度。
[0056]
在本实施例中,对采集的历史报警事件日志进行预处理,提取由显著故障引起的13类报警泛滥序列。对于每种故障根源类别,收集10个历史报警泛滥序列。提取的部分报警泛滥序列如图2所示。
[0057]
步骤1.2、文本编码:
[0058]
由于报警事件序列是文本信息,不可直接计算,本发明根据多个所述连续历史报警事件日志库,搭建了一种基于词嵌入的报警事件数据结构化编码模型(基于skip
‑
gram模型),以用于报警泛滥序列的结构化编码。本发明所采用的模型框架如附表所示,可以捕获
并表达连续历史报警事件日志库中各报警事件数据的时间序列关系。
[0059]
首先,取连续历史报警事件日志库中所有独立不重复报警事件数据信号;根据n个独立报警事件信号制作报警数据类型库,利用独热编码获得报警事件数据的初步结构化编码表示,即报警事件数据类型库的第i个报警信号,被表示为二值向量η
i
=[0,...,0,1,0,...0]
t
,其中
’1’
为报警时间日志库中第i个位置,且整个报警数据类型库可以表示为n*n维的初步结构化编码矩阵;
[0060]
进一步地,将每个报警映射到d维空间,通过初始化权重矩阵将所有报警映射到权重矩阵v上,利用权重矩阵与报警事件数据的初步结构化编码进行内积计算,获取报警事件数据的结构化编码。
[0061]
进一步地,给出多个连续历史报警事件日志库,日志库中共有t个报警信号。基于词嵌入的报警事件数据结构化编码模型的优化目标是最大化平均对数概率φ,该概率表示为
[0062][0063]
其中c是模型训练时的窗口长度,与日志库中第t个报警a
t
相关,a
t j
表示日志库中距离第t个报警信号间距为j的报警信号,其中
‑
c≤j≤c,当j<0时,说明该报警信号发生在a
t
之前发生,当j>0时,在a
t
之后发生,p(a
t j
|a
t
)表示条件概率。
[0064]
进一步地,由于函数最大值不容易计算,因此,最大平均对数概率可以进一步转换为
[0065][0066]
其中,条件概率p(a
t j
|a
t
)可以表示为
[0067][0068]
其中v
a j
表示报警信号作为模型训练中作为中心报警时的结构化编码向量,v
′
a j
表示报警信号作为模型训练中作为背景报警时的结构化编码向量,表示相应矩阵的转置,n表示所有报警标签的个数总和,表示第n个标签对应的报警事件数据结构化编码,表示当前第t个报警的结构化编码。
[0069]
进一步地,利用梯度下降法极小化目标函数:
[0070][0071]
进一步地,更新所需的结构化编码
[0072]
[0073]
其中α是迭代权重。
[0074]
最终,利用向量来实现报警a
m
的结构化表示。第一数据集通过结构化编码后得到新的报警泛滥序列f为
[0075][0076]
本发明中,根源类型由k类组成,其中c样本作为训练集,l样本作为验证集,可以表示为h
s
和h
r
分别表示训练集和验证集,f
s
和f
r
分别表示相应的报警泛滥序列,y
s
和y
r
分别表示工业报警泛滥序列对应的故障根源类型。部分编码后的报警泛滥序列如图3所示。
[0077]
步骤1.3、离线建模:
[0078]
提出一种基于原型网络的改进理论,用于分析小样本学习的时间序列数据。该网络能识别出在训练过程中从未见过的新类别,并且对于每个类别只需要很少的已知标签的样例数据。原型网络将每个类别中的样例数据映射到一个空间当中,并且提取“空间均值”来表示为该类的原型。进一步使用欧氏距离作为距离度量,通过训练使得验证集样本到本类原型表示的距离为最近,到其它类原型表示的距离较远。
[0079]
利用长短期记忆网络(long and short term memory,lstm)进行特征提取。lstm有三个主要特性,包括输入门、遗忘门和输出门。以下方程式给出了一层存储单元h
m
的更新,其中h
m
‑1表示在上一个序列步骤中在同一层的上一个输出。候选记忆单元的值被计算为
[0080][0081]
输入栅极g
m
用于确定单元格状态是否更新,为
[0082][0083]
遗忘门f
m
用于控制是否将先前的状态保留,为
[0084][0085]
输出门o
m
用于控制单元状态的最终输出,为
[0086][0087]
更新内存单位值c
m
,即
[0088][0089]
然后计算lstm单位输出h
m
,即
[0090]
h
m
=o
m
⊙
tanh(c
m
)
[0091]
其中w
αβ
(α=c,g,f,o andβ=x,h)表示不同门机制的不同输入,b
α
表示相应的偏差向量;σ代表应用sigmoid函数,表示逐元素乘积(hadamard product)。c
m
是lstm记忆单元的值,是候选记忆单元的值。通过训练,可以得到f(
·
)函数,即诊断模型本身。
[0092]
基于上述的改进原型网络方法,计算每一类的原型。每个原型计算由该类根源类型训练集样本获取的平均向量表示。第k类根源χ
k
的原型被计算为
[0093][0094]
其中f表示将报警泛滥事件序列提取到特征向量中的lstm模块,c表示训练集样本个数。因此,待测根源类型属于第k类的概率由一个非参数的softmax分类器计算,具体实现为:
[0095][0096]
其中k表示总的种类,χ
k
′
表示所有根源类型分别对应的原型,d表示度量函数,本发明中利用欧式距离作为具体的度量函数,即
[0097][0098]
因此通过分类器可以计算出属于第k类的概率,进而判断故障类型。
[0099]
步骤2、在线诊断:
[0100]
在线诊断中,对输入的报警泛滥序列进行结构化编码,利用诊断模型计算报警泛滥序列的高维空间嵌入,然后与原始故障的类表示进行距离度量,从而比较相似性,以判断故障根源类型,实现故障根源的诊断。进一步的,根据几个评价指标来衡量模型的诊断效果。具体步骤如下:
[0101]
a)在线采集的报警泛滥的结构化编码。数据预处理后,从在线的待诊断报警事件日志中采集新的报警泛滥序列利用结构化编码模型进行数据表示。
[0102]
b)高维空间计算。基于训练好的诊断模型f,将编码后的报警泛滥序列输入诊断模型,获取诊断模型的输出高维向量
[0103]
c)距离度量分析。利用欧式距离计算类原型和在线报警泛滥的高维空间向量的相关性,利用最近邻法判断故障根源类型。待诊断的的故障类型可表示为
[0104][0105]
通过以上步骤,可以实现工业报警泛滥根源类型的在线诊断。
[0106]
模型的根源诊断性能可以根据accuracy(精度),macro
‑
precision(宏
‑
精度率),macro
‑
recall(宏
‑
召回率)和macro
‑
f1分数(宏
‑
f1分数)等评价指标进行评估。
[0107]
accuracy计算公式为
[0108][0109]
其中n
an
表示此故障类型被误检测为其它故障类型的数量;n
af
表示其它故障类型被误检测为此故障类型的数量;n
tf
表示其它故障样本的总数;n
tn
表示此故障样本的总数,其中n
tp
表示故障类型被正确诊断的数量。
[0110]
其他三个指标作为多分类的诊断指标,其中l表示测试集样本数目,这里参数l表示第l个样本带入模型所计算出的相应参数。因此,三个宏指标被定义为:
[0111][0112][0113][0114]
得到的诊断结果如下:
[0115]
表1:所提方法的根源诊断结果
[0116][0117]
表1表明利用所提出的方法建立的根源诊断模型具有较高的性能。因此,可以得出结论,所提出的基于报警泛滥事件序列和fsl方法(小样本学习方法)在根源诊断中是有效的。所提方法针对不同故障类型的诊断结果如图4所示。
[0118]
作为可选地实施方式,本实施例还提供了一种存储介质,所述存储介质为计算机可读存储介质,所述计算机可读存储介质中存储有任一所述的基于小样本学习的工业报警泛滥根源诊断方法。
[0119]
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者系统不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者系统所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括该要素的过程、方法、物品或者系统中还存在另外的相同要素。
[0120]
上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。在列举了若干装置的单元权利要求中,这些装置中的若干个可以是通过同一个硬件项来具体体现。词语第一、第二、以及第三等的使用不表示任何顺序,可将这些词语解释为标识。
[0121]
以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。