1.本发明涉及数据交易平台中数据确权领域,尤其涉及一种电力系统交易平台结构化数据确权方法。
背景技术:
2.伴随着近几年电力系统的数字化转型,电力系统数据迅猛增长,在电力系统数据交易系统中,对于录入系统中的数据文件中的数据需要进行确权。
3.伴随着近几年电力数据存储,数据挖掘等技术的发展,数据正变得越来越值钱。数据交易量也正逐年上升,如何在数据交易平台中确定数据的所有权,避免数据倒卖行为成为当下一个热门话题。
4.数据确权的交易通常不能支持数据的全局校对或着校对速度较慢。对数据内容的确权一般采用逐条比较的方法,费时费力且对硬件设备要求较高。如何完成数据内容的低延时确权是当下亟待解决的一个问题。
技术实现要素:
5.为了解决以上技术问题,本发明提供了一种电力系统交易平台结构化数据确权方法,对电力交易系统中的结构化交易数据进行确权,保证数据交易中用户的数据资产安全。
6.本发明的技术方案是:
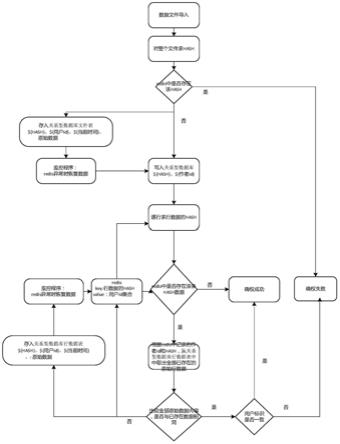
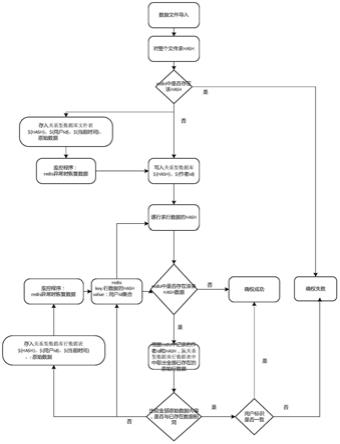
7.一种电力系统交易平台结构化数据确权方法,在数据交易系统中,对于录入系统中的数据文件中的数据进行确权,应用三层过滤即1)、对文件hash校验;2)、对行数据hash校验;3)、对行原始数据校验;通过文件整体比较、文件中行数据hash比较及文件数据详细内容的直接比较三个层级的比较快速判断出数据文件中的内容所有权,完成对数据内容的低延时确权。
8.进一步的,
9.具体步骤如下:
10.步骤一:上传电力系统数据;
11.步骤二:对整个结构化数据计算hash,前边拼接data_字符串作为key,判断redis是否存在该key,若存在则确权失败,非本人数据;若不存在将该数据记入redis中value为当前用户标识;并同时存入关系型数据库中;以备redis异常时恢复数据;
12.步骤三:遍历数据文件中数据,取一条数据d1计算hash,设置求得一条数据的hash值为h1;
13.步骤四:比较redis中存储的是否包含key为h1的数据,如果不存在,则该条数据未存入系统中,标记该条数据属于该用户;继续开始步骤三,执行下一条数据;如果存在;则该条数据可能已经在系统中存在,需要进一步确认;此时获取redis中的数据,设为r1;
14.步骤五:获取redis中r1的全部数据内容,其数据内容为集合类型,集合中存储该条hash对应的数据的用户标识;根据hash和用户标识,从关系型数据库中取出全部的原始
数据;
15.步骤六:将从关系型数据库中取出的数据集s1逐条与d1比较,s1中的内容若与d1有相同内容的,进行步骤七;如果全不同则进行步骤八;
16.步骤七:比较s1中内容与d1相同的数据的录入用户标识是否为同一人,若为同一人则视为该用户的数据;若不为同一人,则视为非本用户数据,给予标记;标记完成后执行步骤三;
17.步骤八:依据d1组装新数据,分别存入redis中和关系型数据库中;
18.其中存入redis中的逻辑:取key为h1的数据集合;若为空,则创建新集合;将当前用户标识添加到集合中;
19.存入关系型数据库的逻辑:存入${行数据的hash}、${当前用户标识}、${当前时间戳},及当前的行数据和用户标识;
20.数据存入之后,进行步骤三。
21.再进一步的,
22.系统启动时,启动监控程序,监控redis的状态,保证redis中数据与关系型数据库中数据信息一致;若不一致时,依据关系型数据库中的数据,恢复redis中的数据,保证数据的可靠性。
23.本发明的有益效果是
24.数据确权的交易通常不能支持数据的全局校对或着校对速度较慢,该发明主要效果是数据确权时对数据全局校对的情况下,极大的提高了数据确权的效率。
附图说明
25.图1是本发明的工作流程示意图。
具体实施方式
26.为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例,基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
27.伴随着近几年电力系统的数字化转型,电力系统数据迅猛增长,在电力系统数据交易系统中,对于录入系统中的数据文件中的数据进行确权。通过文件整体比较、文件中行数据hash比较及文件数据详细内容的直接比较三个层级的比较快速判断出数据文件中的内容所有权,完成对数据内容的低延时确权。
28.具体步骤如下:
29.步骤一:上传电力系统数据。
30.步骤二:对整个结构化数据计算hash,前边拼接data_字符串,如data_${hash}作为key,判断redis是否存在该key,若存在则确权失败,非本人数据;若不存在将该数据记入redis中value为当前用户标识。并同时存入关系型数据库中,其包括${行数据的hash}、${当前用户标识}、${当前时间戳}、用户id。以备redis异常时恢复数据。
31.步骤三:遍历数据文件中数据,取一条数据d1计算hash,假设求得一条数据的hash
值为h1。
32.步骤四:比较redis中存储的是否包含key为h1的数据,如果不存在,则该条数据未存入系统中,标记该条数据属于该用户。继续开始步骤三,执行下一条数据。如果存在。则该条数据可能已经在系统中存在,需要进一步确认。此时获取redis中的数据,假设为r1
33.步骤五:获取redis中r1的全部数据内容,其数据内容为集合类型,集合中存储该条hash对应的数据的用户标识。根据hash和用户标识,从关系型数据库中取出全部的原始数据。
34.步骤六:将从关系型数据库中取出的数据集s1逐条与d1比较,s1中的内容若与d1有相同内容的,进行步骤七。如果全不同则进行步骤八;
35.步骤七:比较s1中内容与d1相同的数据的录入用户标识是否为同一人,若为同一人则视为该用户的数据;若不为同一人,则视为非本用户数据,给予标记。标记完成后执行步骤三。
36.步骤八:依据d1组装新数据,分别存入redis中和关系型数据库中。其中存入redis中的逻辑:取key为h1的数据集合。若为空,则创建新集合。将当前用户标识添加到集合中。存入关系型数据库的逻辑:存入${行数据的hash}、${当前用户标识}、${当前时间戳},及当前的行数据和用户标识。数据存入之后,进行步骤三。
37.另外,系统启动时,启动两个监控程序,监控redis的状态,保证redis中数据与关系型数据库中数据信息一致。若不一致时,依据关系型数据库中的数据,恢复redis中的数据,保证数据的可靠性。
38.本发明应用三层过滤,每层过滤确权数据的方法。1、对文件hash校验;2、对行数据hash校验;3、对行原始数据校验
39.通过三层过滤,数据量逐层递减,提高确权效率和可靠性。
40.以上所述仅为本发明的较佳实施例,仅用于说明本发明的技术方案,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内所做的任何修改、等同替换、改进等,均包含在本发明的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。