1.本发明属于海洋浪高预测技术领域,尤其涉及一种海洋浪高预测方法、系统、计算机设备、存储介质、终端。
背景技术:
2.海浪预测是海洋工程建设、海上运输、环境保护和军事行动等活动的重要保障。在港口建造方面,海浪影响着海岸的形状,关系着港口、航道以及各种海上建筑的设计和建造。异常的海洋波动会对海岸、港口及海上建筑造成难以估量的损失,但海浪成因复杂,海浪高度预测难度很大。海浪成因复杂,波浪的出现和产生具有很高的随机性。除了海上风浪,海浪还可能和海面物体接触产生新的波动,这使海洋浪高预测的难度进一步增加。
3.传统的浪高预测方法使用物理模型对海浪进行建模,传统模型的建立一般以navier
‑
stokes方程组为基础。传统模型包括:使用几何模型、海浪谱数值模拟和物理模型对海浪生成进行模拟。这些方法通过足够多的环境数据对海浪产生的现实环境进行模拟,需要大量计算资源来对海洋环境进行建模。
4.不同于资源消耗巨大的传统物理模型预测方法,近年来计算设备性能大大提高,运算能力增强,出现了诸如深度学习的高效算法。这些算法能够在较短的时间内模拟出一个近似的海浪高度预测模型。加之合理的参数和足够多的实际数据,不仅可以增加预测的准确性,还能提高海洋浪高预测速度。近年来,海洋浪高预测与人工智能方法相结合,正成为海洋浪高领域的大发展方向。
5.现有技术存在的问题及缺陷为:
6.(1)传统的浪高预测方法使用物理模型对海浪进行建模,通过足够多的环境数据对海浪产生的现实环境进行模拟,需要大量计算资源来对海洋环境进行建模,资源消耗巨大。
7.(2)使用诸如均方差高度场等统计学方法来完成海浪建模的方法,由于海浪成因复杂,而且对于海上多样的物理特征,并不能全面且准确地进行采集,这使得这些经典的统计学方法无法准确地模拟海上的波浪运动情况。
8.(3)利用遥感观测进行海浪高度监测的方法中,遥感卫星成本高昂,缺乏高性能预测算法,在数据处理上做到更高精度,以提高海浪浪高预测效率。
9.传统方法在解决环境复杂的现实问题时,使用到大量的计算资源,且建模算法的运行时间较长,导致快速寻找最优解非常困难。由于这类模型计算量过于庞大,经验模型、几何模型以及物理模型难以得到及时准确的预测结果,对于海况复杂的近海区域其预测能力有限。在大面积海况复杂的海域中,需要对海域每一个质点进行模拟,数值模型将耗费巨大的运算资源并且需要花费大量的时间进行建模和运算。
技术实现要素:
10.针对现有技术存在的问题,本发明提供了一种海洋浪高预测方法。
11.本发明是这样实现的,一种海洋浪高预测方法,所述海洋浪高预测方法包括以下步骤:
12.选取相关系数高的特征作为预测海浪高度的输入特征;按照粒子群行为特征建立混沌模型,解决粒子群过早收敛问题;cdw为bp模型进行初始化阶段的优化;在cpso
‑
bp模型中,混沌粒子群优化算法(cpso)在解空间中寻找最优的粒子对bp网络的初始权值和阈值进行优化;使用cpso算法优化过的参数作为elm网络的初始权值和阈值传入elm网络;利用cpso
‑
bp模型或cpso
‑
elm模型进行海洋预警领域浪高预测。进一步,步骤一中,所述特征选取,包括:
13.在选择输入特征时,确定每个特征与海浪高度的相关性,每个输入参数与海浪高度之间的相关系数进行分析,选取相关系数高的特征作为预测海浪高度的输入特征;其中,备选的神经网络输入特征,包括平均海平面msl、10米风速u分量u10、10米风速v分量v10、平均海波方向mwd、平均海波周期mwp五项特征。
14.通过皮尔逊相关系数r
x,y
计算各个变量与海浪高度swh的相关性,以相关性作为参考选取神经网络的输入特征;皮尔逊相关系数r
x,y
用来定量分析变量问的相关性,r
x,y
∈[
‑
1,1],当|r
x,y
|接近于1,两者相关性高,当|r
x,y
|接近于0,两者相关性低;r
x,y
的正负代表两个变量的相关性正负,根据以下公式进行计算:
[0015][0016]
其中,|r
x,y
|>0.8时,两个变量高度相关;当|r
x,y
|∈[0.3,0.5))时,两个变量低度相关;当|r
x,y
|<0.3时,两个变量弱相关。
[0017]
u10和v10分别为精度和纬度上的风速分量,其相关性不适合单独拿出来作为海浪高度预测的参数;通过特征融合,计算观测点风速值uv用作网络的输入,uv可由以下公式进行计算:
[0018][0019]
特征融合后的新特征uv与swh具有最高的相关性,且与mwp不同,uv不具有后验性,可以作为输入特征。
[0020]
选用p值pvalue来分析各参数的显著性。当原假设成立时,p值代表极端情况的发生几率;p值越小表示极端情况发生的几率越小,p值越大表示极端情况发生的几率大,故p值的大小表示各参数的显著性。当p值小于005时,表示该变量具有显著性;当p值小于0001时,表示该变量具有高显著性;只有当显著性高且相关系数高时,将这个参数用作输入特征才有意义。好的输入拥有高相关性且p值一般小于01,具有越小的p值才可认为两组数据有明显关系。uv和msl与swh具有高度相关性,故选用uv和msl作为网络的输入特征进行浪高。
[0021]
进一步,步骤二中,所述cpso算法的确定,包括:
[0022]
粒子群优化算法分为两种状态:探索状态和开发状态。处于探索状态时,传统粒子群算法用随机的方式去搜索问题空间,但这时粒子可能经过变异,而陷入局部最优解;处于开发状态时,粒子群向最优区域聚合。当使用粒子群算法进行求解时,通过引入混沌学习算法,按照其粒子群行为特征建立其混沌模型,来解决粒子群过早收敛的问题。
[0023]
对粒子群进行位置初始化,第i个粒子的初始位置表示为:
[0024]
x
i
=(x
i,1
,x
i,2
,...x
i,n
),i∈[1,m];
[0025]
在生成初始向量之后,使用混沌算法对生成的初始向量进行混沌初始化。利用混沌算法的特性对于初始向量的每一个x
i
分别赋予n个初始值,生成混沌变量通过如下公式可以将初始值从问题空间映射到混沌空间:
[0026][0027]
找到当前最优解和整个粒子群中的最优解来决定更新速率,当前适应度最高的解记作p
i
,整个粒子群中的最优解记作p
g
。
[0028]
第i个粒子的当前最优解表示为:
[0029]
p
i
=(p
i1
,p
i2
,...p
in
),i∈[1,m];
[0030]
全局最优解表示为:
[0031][0032]
pso通过在不同轮次改变每个粒子的速度,使解朝向趋于p
i
和p
g
的方向更新从而得到最优解。
[0033]
第i个粒子通过以下等式对速度进行更新:
[0034][0035]
其中,c1是局部加速系数,c2是整体加速系数,ω∈r,被称之为惯性权重系数r1和r2为(0,1)区间内的随机实数;小值c1和大值c2能使粒子在优化的后期收敛到全局最优解;局部加速系数由以下公式计算:
[0036][0037]
整体加速系数由以下公式计算:
[0038][0039]
其中,c
1i
和c
2i
是加速系数c1和c2的初始值,且c
1f
和c
2f
是加速系数的最终值。
[0040]
自适应惯性权重系数可由以下公式计算:
[0041][0042]
其中,ω
max
和ω
min
分别为权重系数ω的最大值和最小值,随着进化过程推进,ω逐渐减小;f是当前粒子的适应度,f
av
为粒子群整体的适应度平均值,f
min
为粒子群中的最小适应度。
[0043]
第i个粒子通过以下等式对速度进行更新:
[0044][0045]
其中,x
i
是粒子i的位置,v
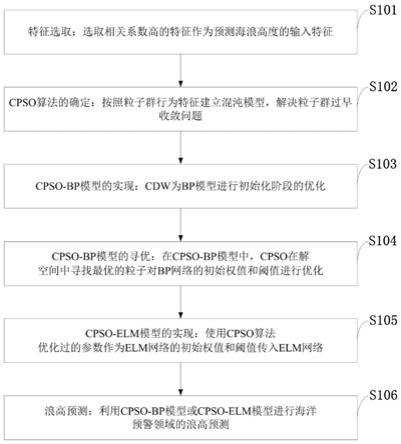
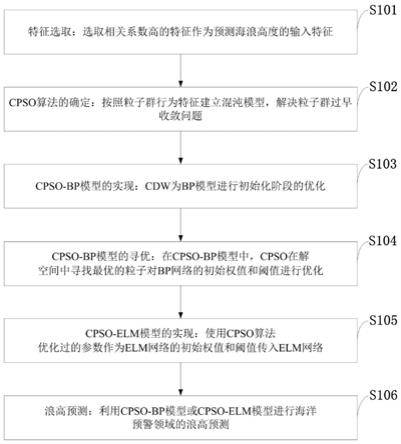
i
代表粒子i的速率,v
i
∈(v
min
,v
max
),v
min
和v
max
在[0,1]之内;λ∈r被称为限制因子,用于调整ω∈r,限制速率;当达到最大轮次或收敛至符合适应度要求时,计算终止。
[0046]
进一步,步骤三中,所述cpso
‑
bp模型的实现,包括:
[0047]
(1)确定bp网络模型结构。
[0048]
通过特征选取,本发明选择uv和msl作为输入特征值。确定网络输入节点数s
i
为2,隐藏层节点数s
o
为1,将隐藏层节点数s
l
设置为5;其中,每个粒子的维数n可通过以下公式计算:
[0049]
n=s
i
×
s
l
s
l
×
s
o
s
l
s
o
q,q=1;
[0050]
其中,q为每个粒子的适应度值,将其放在每个粒子的最后一维构成一个22维的粒子x
i
;s
i
×
s
l
为输入层到隐藏层的权值的数量,s
l
为隐藏层的阈值的数量,粒子的维数n=22。
[0051]
(2)设置cpso初始参数。
[0052]
设置限制因子λ=0.92,自适应惯性权重因子的最大值ω
max
=0.9和最小值ω
min
=0.4,设置加速系数初始值c
1i
=c
2i
=0.5,设置加速系数最终值c
1f
=c
2f
=2.5。
[0053]
(3)根据bp网络模型的结构,生成cpso算法中的初始向量和混沌向量。
[0054]
将输入层到隐藏层的权值和隐藏层的阈值作为cpso矩阵中的元素,cpso中的每一个粒子都表示bp网络的初始参数。对种群x初始化,模型随机产生一个大小m为2000的粒子群,初始种群的第i个粒子由以下公式计算:
[0055]
x
i
=(x
i,1
,x
i,2
,...x
i,m
),i=1,2,...,22;
[0056]
然后,为x
i
中每一个参数加入一个微小的扰动,由此生成初始混沌向量,第i个初始混沌向量由以下公式计算:
[0057][0058]
(4)通过适应度的大小来对种群中的每一个粒子进行打分。
[0059]
每一个粒子的适应度为均方差的倒数,通过适应度的大小来对种群中的每一个粒子进行打分,将各个粒子的得分设为向量的最后一项,适应度与bp网络模型的权值和阈值一起作为该粒子的参数,以确定一个粒子的结构。第i个粒子的适应度由以下公式计算:
[0060][0061]
通过得到的适应度值对每个粒子进行排序,排名前五的粒子作为优胜粒子,排名次五的粒子作为临时粒子。
[0062]
(5)为粒子群按照适应度值进行排序,再对粒子群进行寻优,生成新的粒子群。
[0063]
按照适应度得分,排序最靠前的5个粒子作为优胜粒子,记作i=1,2,...,5,在这五个粒子之后排名次五粒子作为临时粒子,记作然后以这十个被选出来的优胜粒子和临时粒子作为新的中心,与随机矩阵相加19次,分别生成19个新的粒子。可表示为随机生成一个22维矩阵y=[y
1 y
2 ... y
22
],其中。将分别与矩阵y相加,将相加后的新矩阵归一化到与y相同的区间。相加后的新矩阵可由以下公式计算:
[0064][0065]
其中,l
manx
由以下公式计算:
[0066]
l
max
={max||x
i
y
i
|,i=1,2,...,22},n=1,2,...,19;
[0067]
每一个优胜粒子和临时粒子与之后生成的19个z
n
组成一个新的粒子群。从而产生5个新的优胜粒子群,记作以及5个新的临时粒子群,记作
[0068]
(6)混沌趋同和混沌异化操作。
[0069]
将五个优胜粒子和五个临时粒子分别作为中心,生成10个新的粒子群,将新生成的粒子按照适应度值进行重新排序。
[0070]
混沌趋同:当子群体进行趋同操作时,种群会以自己内部得分最高的个体为中心,生成新的子群体,如果新的子群体中有比自己得分高的,那么则以新的优胜个体为中心继续趋同操作。更新计算粒子的适应度f的平均值f
av
和适应度f的最小值f
min
,更新权重系数ω。
[0071]
混沌异化:更新自适应惯性权重系数ω、局部加速系数c1和整体加速系数c2,计算出粒子进行混沌化后的速度和粒子新位置。根据粒子的新位置重新计算粒子坐标和适应度f,当出现f值更高的粒子,就用这一粒子生成新的粒子群,将适应度值低的粒子淘汰,直到粒子群成熟,所有个体收敛。
[0072]
如果异化后的粒子群仍未收敛,则重复该步骤直至网络收敛。
[0073]
(7)将适应度最高的个体x
best
=[x
1 x
2 ... x
22
]作为bp神经网络的输入。
[0074]
将x
best
中x1,x2,...,x
10
作为网络输入层到隐藏层的连接权值,记作将x
best
中x
11
,x
12
,...,x
15
作为神经隐藏层到输出层的连接权值,记作w2=[x
11
,x
12
,...,x
15
]
t
;将x
best
中x
16
,x
17
,...,x
20
作为隐藏层中各个节点的阈值,记作b1=[x
16
,x
17
,...,x
20
]
t
将x
best
中x
21
作为输出层中各个节点的阈值,记作b2=[x
21
]
t
。将w=[w1,w2]
t
和b=[b1,b2]
t
分别作为bp网络的初始权值和阈值,形成初始cpso
‑
bp模型。
[0075]
(8)训练预测模型,进行仿真预测。
[0076]
进一步,步骤四中,所述cpso
‑
bp模型的寻优,包括:
[0077]
在cpso
‑
bp模型中,cpso在解空间中寻找最优的粒子对bp网络的初始权值和阈值进行优化,cpso通过趋同和异化运算来发掘适应度更高的粒子;在进行趋同运算之前,cpso先根据适应度值将所有粒子进行排序,从排名靠前的粒子中找到最优粒子和临时粒子;由最优粒子和临时粒子为中心,生成新的粒子群,对每个新生成的粒子群进行排序,进行趋同和异化操作;当异化过程不再产生适应度值更高的粒子,即找到最优粒子时,不再对粒子群进行更新,算法结束。
[0078]
在cpso的优化过程中,在选取5个优胜粒子和5个临时粒子之后,分别以它们为中心生成了5个优胜粒子群和5个临时粒子群。每个粒子群适应度得分在经过一定次数的变化之后趋于一个稳定值,这说明粒子群已经成熟,适应度得分不再变化。当每个粒子群经过趋同运算,每个粒子群的最终得分为其内部得分最高的粒子的适应度值。在进行最优粒子群更新之后,进入异化阶段。
[0079]
优胜粒子群中的子种群2,子种群3和子种群4的适应度值得分低于临时粒子群中的子种群1、子种群2和子种群5的适应度值得分。所以,由临时粒子群中的子种群1、子种群2和子种群5取代优胜粒子群中的子种群2,子种群3和子种群4作为新的优胜粒子群进入异化阶段。然后将优胜粒子群被替换的三个粒子群淘汰,再在临时粒子群中随机生成三个新的
粒子群,进入异化阶段。在经过4次趋同运算之后粒子群的适应度得分不再变化,说明此时所有的粒子群已经成熟,满足算法停止条件,cpso算法寻优至此结束。将cpso找到的适应度值最高的粒子的值传入bp神经网络作为初始权值和阈值。
[0080]
进一步,步骤五中,所述cpso
‑
elm模型的实现,包括:
[0081]
cpso
‑
elm模型的形式与cpso
‑
bp模型类似。cpso在算法策略上不变,在cpso算法运行结束后将算法寻找到的最优解传入elm作为其初始权值和阈值。
[0082]
elm在确定输入层到隐藏层各个节点的权值和隐藏层的阈值后,elm能自行确定隐藏层神经元到输出层神经元的权值;通过特征选取,选择uv和msl作为输入特征值,通过训练bp神经网络对swh进行预测;输入神经元个数s
i
为2,输出层节点数s
o
为1,将隐藏层节点个数s
l
设置为5;其中,每个粒子的维数n,通过以下公式计算:
[0083]
n=s
i
×
s
l
s
l
q,q=1;
[0084]
其中,q为每个粒子的适应度值,将其放在每个粒子的最后一维构成一个16维的粒子x
i
;s
i
×
s
l
为输入层到隐藏层的权值数量;s
l
为隐藏层神经元的阈值数量,粒子的维数n=16。
[0085]
cpso
‑
elm模型的基本思想是将使用cpso算法优化过的参数作为elm网络的初始权值和阈值传入elm网络,通过优化神经网络参数来对预测的效果进行优化。
[0086]
本发明的另一目的在于提供一种应用所述的海洋浪高预测方法的海洋浪高预测系统,所述海洋浪高预测系统包括:
[0087]
特征选取模块,用于选取相关系数高的特征作为预测海浪高度的输入特征;
[0088]
cpso算法确定模块,用于按照粒子群行为特征建立混沌模型,解决粒子群过早收敛问题;
[0089]
cpso
‑
bp模型实现模块,用于通过cdw为bp模型进行初始化阶段的优化;
[0090]
cpso
‑
bp模型寻优模块,在cpso
‑
bp模型中,用于通过cpso在解空间中寻找最优的粒子对bp网络的初始权值和阈值进行优化;
[0091]
cpso
‑
elm模型实现模块,用于使用cpso算法优化过的参数作为elm网络的初始权值和阈值传入elm网络;
[0092]
浪高预测模块,用于利用cpso
‑
bp模型进行海洋预警领域的浪高预测。
[0093]
本发明的另一目的在于提供一种计算机设备,所述计算机设备包括存储器和处理器,所述存储器存储有计算机程序,所述计算机程序被所述处理器执行时,使得所述处理器执行如下步骤:
[0094]
选取相关系数高的特征作为预测海浪高度的输入特征;按照粒子群行为特征建立混沌模型,解决粒子群过早收敛问题;cdw为bp模型进行初始化阶段的优化;在cpso
‑
bp模型中,cpso在解空间中寻找最优的粒子对bp网络的初始权值和阈值进行优化;使用cpso算法优化过的参数作为elm网络的初始权值和阈值传入elm网络;利用cpso
‑
bp模型进行海洋预警领域的浪高预测。
[0095]
本发明的另一目的在于提供一种计算机可读存储介质,存储有计算机程序,所述计算机程序被处理器执行时,使得所述处理器执行如下步骤:
[0096]
选取相关系数高的特征作为预测海浪高度的输入特征;按照粒子群行为特征建立混沌模型,解决粒子群过早收敛问题;cdw为bp模型进行初始化阶段的优化;在cpso
‑
bp模型
中,cpso在解空间中寻找最优的粒子对bp网络的初始权值和阈值进行优化;使用cpso算法优化过的参数作为elm网络的初始权值和阈值传入elm网络;利用cpso
‑
bp模型进行海洋预警领域的浪高预测。
[0097]
本发明的另一目的在于提供一种信息数据处理终端,所述信息数据处理终端用于实现所述的海洋浪高预测系统。
[0098]
结合上述的所有技术方案,本发明所具备的优点及积极效果为:机器学习方法能够在较短的时间内构建海浪高度预测模型。相对于传统浪高预测物理模型,本发明提供的海洋浪高预测方法,使用深度学习方法进行浪高预测有着准确性高、成本低、运行速度快的优点;在海洋预警中的浪高预测问题上,非常适合使用深度学习方法进行浪高预测。
[0099]
本发明旨在结合bp神经网络和cpso算法构建一个准确高效的海浪高度预测模型。通过混沌粒子群优化算法的寻优能力,来弥补神经网络固有的不足,得到一个较传统物理方法更为高效的模型,在保证预测准确率的情况下,使资源和建模时间的消耗降低。
[0100]
本发明使用一个基于混沌粒子群优化算法优化的bp神经网络模型(cpso
‑
bp)用于进行海洋浪高预测。通过逐代筛选,找到一个最优的粒子,并将cpso算法的结果传递给bp神经网络。将cpso算法的计算结果作为bp神经网络的初始权值和阈值,形成cpso
‑
bp模型,通过使用训练后的cpso
‑
bp网络进行海洋浪高预测任务,使网络的预测性能得到提升。
[0101]
本发明实验使用中期天气预报中心2020年的渤海和黄海各6个站点每6小时记录一次的浪高数据。通过对浪高数据各个参数与浪高之间的相关系数进行计算和分析,选取了模型的输入特征。分别使用st
‑
bp、cpso
‑
elm、cpso
‑
bp模型使用前11个月的数据进行训练,用第12个月的数据作为测试集来评估三个模型的浪高预测效果。通过对三个模型预测结果的回归曲线、预测曲线和各个实验指标的对比,从预测准确性、及时性、鲁棒性和泛化能力角度,分析了cpso
‑
bp模型在解决海洋预警领域浪高预测问题上的优势。本发明对cpso
‑
bp和cpso
‑
elm模型海洋浪高预测模型的研究,对今后海洋浪高预测相关问题的研究具有重要参考作用和应用价值。
附图说明
[0102]
为了更清楚地说明本发明实施例的技术方案,下面将对本发明实施例中所需要使用的附图做简单的介绍,显而易见地,下面所描述的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下还可以根据这些附图获得其他的附图。
[0103]
图1是本发明实施例提供的海洋浪高预测方法流程图。
[0104]
图2是本发明实施例提供的海洋浪高预测系统结构框图;
[0105]
图中:1、特征选取模块;2、cpso算法确定模块;3、cpso
‑
bp模型实现模块;4、cpso
‑
bp模型寻优模块;5、cpso
‑
elm模型实现模块;6、浪高预测模块。
[0106]
图3是本发明实施例提供的elm拓扑结构图。
[0107]
图4是本发明实施例提供的bp神经网络拓扑结构图。
[0108]
图5是本发明实施例提供的各项特征与海浪高度的皮尔逊相关系数柱状图。
[0109]
图6是本发明实施例提供的2020年121
°
e,40
°
n站点uv、u10、v10和swh曲线图。
[0110]
图7是本发明实施例提供的bp神经网络结构图。
[0111]
图8是本发明实施例提供的cpso
‑
bp模型流程图。
[0112]
图9是本发明实施例提供的优胜粒子群的趋同过程适应度得分示意图。
[0113]
图10是本发明实施例提供的临时粒子群的趋同过程适应度得分示意图。
[0114]
图11是本发明实施例提供的优胜粒子群经异化之后的趋同过程适应度得分示意图。
[0115]
图12是本发明实施例提供的临时粒子群经异化后的趋同过程适应度得分示意图。
[0116]
图13是本发明实施例提供的cpso
‑
elm模型预测流程图。
[0117]
图14是本发明实施例提供的渤海和黄海观测站点分布图。
[0118]
图15是本发明实施例提供的2020年渤海站点浪高分布图。
[0119]
图16是本发明实施例提供的2020年黄海站点浪高分布图。
[0120]
图17是本发明实施例提供的st
‑
bp在训练和测试阶段的线性回归散点分布图。
[0121]
图18是本发明实施例提供的cpso
‑
elm在训练和测试阶段的线性回归散点分布图。
[0122]
图19是本发明实施例提供的cpso
‑
bp在训练和测试阶段的线性回归散点分布图。
[0123]
图20是本发明实施例提供的渤海海域真实浪高与三种模型预测曲线对比图。
[0124]
图21是本发明实施例提供的黄海海域真实浪高与三种模型预测曲线对比图。
[0125]
图22是本发明实施例提供的渤海预测结果四项指标平均值对比柱状图。
[0126]
图23是本发明实施例提供的黄海预测结果四项指标平均值对比柱状图。
[0127]
图24是本发明实施例提供的预测结果四项指标方差对比柱状图。
具体实施方式
[0128]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
[0129]
混沌粒子群优化算法被广泛应用到需要大量计算的优化问题之中,通过将一个解空间巨大的寻优问题转化为问题域中少量粒子的寻优过程,这将大大简化优化过程,减小寻优过程中的计算量。混沌算法与遗传算法所生成的解可能具有更高的多样性和进化能力,在许多涉及粒子群优化的研究中,都开始采用混沌映射作为进行系统优化的方法。混沌算法适合用来改进启发式算法用来解决海洋浪高预测问题,且算法具有极快的处理速度,对于大尺度海况复杂的海域能够进行快速准确的预测。混沌粒子群优化算法算法适用于对人工神经网络初始参数的优化任务。混沌粒子群优化算法与人工神经网络优势互补,两者特性相吻合,结合两者优势的模型适合作为进行海洋预警领域海洋浪高预测任务的预测模型。
[0130]
本发明通过bp神经网络结合混沌粒子群算法(chaotic particle swarm optimization,简称cpso)算法构建一个准确高效的海浪高度预测模型。通过混沌粒子群优化算法的寻优能力,来弥补神经网络固有的不足,得到一个较传统物理方法更为高效的模型,在保证预测准确率的情况下,使资源和建模时间的消耗降低。
[0131]
针对现有技术存在的问题,本发明提供了一种海洋浪高预测方法、系统、计算机设备、存储介质、终端,下面结合附图对本发明作详细的描述。
[0132]
如图1所示,本发明实施例提供的海洋浪高预测方法包括以下步骤:
[0133]
s101,特征选取:选取相关系数高的特征作为预测海浪高度的输入特征;
[0134]
s102,cpso算法的确定:按照粒子群行为特征建立混沌模型,解决粒子群过早收敛问题;
[0135]
s103,cpso
‑
bp模型的实现:cdw为bp模型进行初始化阶段的优化;
[0136]
s104,cpso
‑
bp模型的寻优:在cpso
‑
bp模型中,cpso在解空间中寻找最优的粒子对bp网络的初始权值和阈值进行优化;
[0137]
s105,cpso
‑
elm模型的实现:使用cpso算法优化过的参数作为elm网络的初始权值和阈值传入elm网络;
[0138]
s106,浪高预测:利用cpso
‑
bp模型或cpso
‑
elm模型进行海洋预警领域的浪高预测。
[0139]
如图2所示,本发明实施例提供的海洋浪高预测系统包括:
[0140]
特征选取模块1,用于选取相关系数高的特征作为预测海浪高度输入特征;
[0141]
cpso算法确定模块2,用于按照粒子群行为特征建立混沌模型,解决粒子群过早收敛问题;
[0142]
cpso
‑
bp模型实现模块3,用于通过cdw为bp模型进行初始化阶段的优化;
[0143]
cpso
‑
bp模型寻优模块4,在cpso
‑
bp模型中,用于通过cpso在解空间中寻找最优的粒子对bp网络的初始权值和阈值进行优化;
[0144]
cpso
‑
elm模型实现模块5,用于使用cpso算法优化过的参数作为elm网络的初始权值和阈值传入elm网络;
[0145]
浪高预测模块6,用于利用cpso
‑
bp模型进行海洋预警领域的浪高预测。
[0146]
下面结合实施例对本发明的技术方案作进一步描述。
[0147]
1、海浪高度预测关系到海洋预警和海上工程的安全及时开展。传统浪高预测方法包括物理模型和经验模型。物理模型通过力学分析对真实海况进行模拟,物理模型能够得到较为准确预测效果,但由于海洋环境的复杂性,物理模型在建模过程中需要使用到大量的计算资源,算法的运行时间较长。经验模型建立不需要任何物理参数,模型训练速度快,但是预测的准确率较低。而在海洋预警中,浪高预测的准确性和预测速度都至关重要。
[0148]
不同于传统预测方法,近年来出现的极限学习机(elm)、反向传播神经网络(bp)等深度学习方法能够在较短的时间内构建海浪高度预测模型。这些方法对浪高变化趋势进行建模,使用合理的参数和足够多的实际数据,不仅可以增加预测的准确性,还能提高海洋浪高预测速度,更适用于海洋预警领域的浪高预测问题。
[0149]
bp神经网络结构简单,模型训练速度快,通过bp神经网络反向传播降低误差,训练出的模型准确性较高,适合用来解决大数据量、大范围的预测问题,但bp神经网络在训练过程中容易陷入局部最优解。为了解决bp神经网络易于陷入局部最优解的问题,引入混沌粒子群算法(chaotic particle swarm optimization,cpso)优化bp神经网络,组成cpso
‑
bp模型。利用cpso的全局搜索能力优化模型训练效果,保证模型训练速度和稳定性的同时提升网络的预测准确性。
[0150]
本发明内容如下:
[0151]
(1)选取bp神经网络作为进行海洋浪高预测的模型。研究对比了bp神经网络与elm模型的结构差异,并指出了bp神经网络进行浪高预测的优势。
[0152]
(2)描述了cpso
‑
bp模型的核心算法。描述了cpso
‑
bp和cpso
‑
elm两种海洋浪高预测模型的结构,描述了混沌学习算法、pso算法和bp神经网络,以及三者的结合方式。
[0153]
2、cpso
‑
bp浪高预测算法的理论基础
[0154]
随着研究的深入,出现了各种各样的神经网络模型,其中最具代表性的是极限学习机(elm)和反向传播(bp)神经网络模型。elm在训练过程中不进行反向传播,拥有较快的训练速度,但在预测性能上有所欠缺。
[0155]
bp神经网络通过逐层调整参数使误差减小,以此来优化模型的预测性能。相比elm,bp神经网络需要使用更长的时间进行训练,但其对参数的优化效果更好,能够得到较为准确的预测效果。bp神经网络在训练过程容易陷入局部最优解,为了解决bp神经网络易于陷入局部最优解的问题,引入cpso优化bp神经网络,组成cpso
‑
bp模型。利用cpso的全局搜索能力优化模型训练效果,保证模型训练速度和稳定性的同时提升网络的预测准确性。
[0156]
31极限学习机原理
[0157]
elm是一种前馈神经网络,其网络训练速度极快。elm在确定了网络中输入层、隐藏层的权值和阈值之后,可自行计算更新输出层的阈值和与之相连节点的权值。图3为elm的拓扑结构示意图。
[0158]
假设有n个样本(x
i
,t
i
),其中x
i
=[x
i1 x
i2 ... x
in
]
t
∈r
n
,t
i
=[t
i1 t
i2 ... t
im
]
t
∈r
m
。则一个只有一个隐藏层,且每个隐藏层节点数为l的网络可由公式(7)表示。
[0159][0160]
其中,g(x)为激活函数,β
i
为输出权重,w
i
=[w
i,1 w
i,2 ... w
i,n
]
t
为输入权重,b
i
是第i个隐藏层神经元的阈值。
[0161]
输出和目标值之间的误差由以下公式计算:
[0162][0163]
elm旨在使ε值为0,即存在β
i
、w
i
和b
i
,使:
[0164][0165]
将上式转化为矩阵表示:
[0166]
hβ=t
ꢀꢀꢀ
(4)
[0167]
其中,h是隐藏层的输出,t为期望的输出,β为输出权值。
[0168]
h可表示为:
[0169][0170]
β可表示为:
[0171][0172]
t可表示为:
[0173][0174]
为了得到最优的网络,我们希望得到和使得:
[0175][0176]
这等价于最小损失函数:
[0177][0178]
在elm中,一旦w
i
和b
i
被确定,输出矩阵就被确定了。并且输出权重也可以被确定,计算公式如下:
[0179][0180]
其中,h
是矩阵h的moore
‑
penrose逆矩阵。
[0181]
elm不需要通过反向传播对网络中的权值和阈值进行修改,训练速度较bp网络更快。elm的权值和阈值在设定后便不再进行更新。这和bp神经网络的反向传播不断更新网络权值和阈值的策略不一样,elm不进行反向传播,这虽然减少了运算量和运算时间,但网络预测的准确性无法保证。elm比传统的学习算法的运算速度更快,本发明将使用cpso分别优化elm与bp神经网络来探究cpso算法的优化能力。
[0182]
3.2 bp神经网络原理
[0183]
bp神经网络是一种运用范围广的经典神经网络结构,通过反向传播调整参数来学习训练模型。bp神经网络包括输入层、隐藏层以及输出层三大结构。输入层和输出层是单一结构,隐藏层的结构不固定。
[0184]
3.2.1 bp神经网络结构
[0185]
bp神经网络的每个输入神经元点和每一个隐藏层神经元连接,每个隐藏层神经元点和每一个输出层神经元连接,每两个神经元连接的路线包含神经网络的权值,每个隐藏层神经元和输出层神经元包含神经网络的阈值。权值为每一项的权重,阈值为偏差的校正参数。输入神经元传递初始数据给神经网络,输入神经元中不包含阈值。bp网络包含正向和反向两大训练步骤。正向传播时,数据进入输入神经元,经一系列包含连接权值和阈值的非线性函数运算后,运算的结果由输出神经元传出。如果结果不满足收敛条件,则反向传播进行误差的降低操作。通过计算结果与期望值的差计算损失值,沿bp神经网络训练方向的相反方向,回传损失值,通过重新计算每一条路径的权值和阈值,以降低损失值至理想效果,当误差足够小并满足训练要求时,停止bp神经网络训练。bp神经网络的结构灵活,可以模拟复杂的非线性函数,在实际应用中效果良好,受到广泛运用。
[0186]
图4为一个n维的bp神经网络结构。其中,x1,x2,...,x
n
为输入数据,w1,w2,...,w
n
为各路径的权值。
[0187]
bp神经网络神经元的权值以及输入数据可以通过矩阵的方式来表示:
[0188][0189]
一个神经元节点接收到所有的输入后,会通过激活函数对其进行分析、映射,用α
来表示所有输入值经过不同权重的加权后的值。
[0190]
α=∑ω
i
x
i
ꢀꢀꢀ
(12)
[0191]
bp神经网络中各个路径的阈值由θ表示,激活函数y=f(α,θ)。
[0192]
如图4所示,bp神经网络输出节点的值y可表示为:
[0193][0194]
bp神经网络本身存在一些结构性的问题:(1)b外网络需要通过反向传播逐代更新网络的权值和阈值,多次反同传描会大大增加网络的训练时间,当网络结构复杂时,这种情况尤为明显。(2)如果初始值在解空间分布过于密集,有可能使bp神经网络过早收敛,陷入局部最优解。(3)对学习率敏感学习率越小网络收敛效果越好,但会在很大程度上增加网络的训练时间。
[0195]
3.3 pso算法原理
[0196]
bp神经网络对初始参数十分敏感,好的初始参数不仅能减少bp神经网络的反向传播次数,还能提高bp神经网络模型的预测效果。粒子群算法(pso)是一种启发式算法,pso算法将现实世界中的个体看作是解空间中的一个个随机分布的粒子,粒子群中的各个粒子以不同的速率朝向理论上的最优值移动以找到全局最优解。本发明通过混沌学习算法改进pso的寻优能力来优化bp神经网络的初始参数,算法中的每一个粒子代表一组bp神经网络的初始化参数,每个粒子包含bp网络的一个初始权值、初始阈值和适应度值。
[0197]
3.31 pso算法介绍
[0198]
pso算法使用一组位置随机的向量进行初始化,粒子在一个m维空间内进行搜索,每一个向量被称之为粒子。粒子群由n个粒子构成,则第i个粒子的初始位置表示为:
[0199]
x
i
=(x
i1,
x
i,2
,...x
i,n
),i∈[1,m]
ꢀꢀꢀ
(14)
[0200]
这些粒子以一定的速度映射到解空间,通过不断地更新轮次以达到用户设置的适应度(fitness),以此来寻找最佳的解向量。在轮次(iter)更新过程中,算法参考当前最优解和整个粒子群中的最优解来决定更新速率,当前适应度最高的粒子记作p
i
,整个粒子群中的最优解记作p
g
。
[0201]
x
i
的适应度值fitness(x
i
)通过如下公式计算:
[0202][0203]
适应度值越高则粒子的优化效果越好,p
i
为p
i
的第i个子项。
[0204]
第i个粒子的当前最优解表示为:
[0205]
p
i
=(p
i1
,p
i2
,...p
in
),i∈[1,m]
ꢀꢀꢀ
(16)
[0206]
全局最优解表示为:
[0207][0208]
pso通过在不同轮次改变每个粒子的速度,使粒子向靠近p
i
和p
g
的方向更新从而得到最优解。
[0209]
第i个粒子的速度通过以下等式对速度进行更新:
[0210]
[0211]
在速度更新之后,第i个粒子的位置通过以下等式对速度进行更新:
[0212][0213]
其中,x
i
是粒子i的位置,v
i
代表粒子i的速率,v
i
∈(v
min
,v
max
),v
min
和v
max
在[0,1]之内;ω∈r,它被称之为惯性权重系数,λ∈r被称为限制因子,它被用来调整ω∈r,以此来限制速率;r1和r2为(0,1)区间内的随机实数。当达到最大轮次或收敛至符合适应度要求时,计算终止。
[0214]
惯性权重系数ω有以下等式设定:
[0215]
ω=ω
max
‑
[(ω
max
‑
ω
min
)/iter
max
]
×
iter
ꢀꢀꢀ
(20)
[0216]
其中,ω
max
为初始权重,ω
min
是最终权重,随着权重逐次减小。iter
max
是迭代的最大轮次,iter是当前迭代轮次。
[0217]
3.3.2 pso算法流程
[0218]
pso算法由以下基本流程组成:
[0219]
(1)分析问题,针对问题对粒子进行编码。
[0220]
(2)将编码粒子生成形成种群,计算粒子适应度,将每个粒子按照适应度值高低进行排序,并按照得分由高到低选出优胜粒子群及临时粒子群。
[0221]
(3)将选出的优胜子群体及临时子群体作为新的中心,生成相应数量的新粒子群。生成的新粒子群与选出的优胜子群体构成新的优胜粒子群和临时粒子群
[0222]
(4)将整个种群中的所有粒子进行趋同运算,并将粒子群的中得分最高的粒子的适应度值作为整个粒子群的得分。当种群收敛或超过迭代的最大次数时,则不再继续进行趋同操作。否则,继续进行趋同和异化运算。
[0223]
(5)结束趋同操作后,在粒子群中进行异化运算。如果新的临时粒子群中出现了得分更高的粒子群,就用得分更高的临时粒子替换之前的优胜粒子群的分较低的粒子,将替换下来的粒子丢弃,再随机生成新的粒子来补齐临时粒子群。异化完成后,若未达到结束条件,则继续执行趋同异化的过程。
[0224]
(6)算法结束,找到全局最优的粒子。
[0225]
3.4混沌学习算法原理
[0226]
混沌现象的行为复杂且随机,但有一定的内在规律。混沌学习算法的思想是把一个初始的混沌向量从问题空间映射到解空间,对不同初始值,混沌学习算法将计算出不同的解。混沌学习算法不易过早收敛,具有高速、精确、全局渐进收敛等的特性。使用pso算法优化bp神经网络具有一定局限性,pso算法的初始粒子过于集中或在进化过程中有可能取得更高适应度的粒子被淘汰将会导致粒子群过早收敛。为了解决这一问题,本发明引入混沌学习算法对pso算法进行优化,通过在pso算法的初始化、趋同和异化阶段加入混沌学习算法使pso算法在初始阶段能都随机分布在问题空间,而在趋同异化阶段让更具潜力的粒子能够得到保留,以解决过早收敛问题。
[0227]
对于如下优化问题:
[0228]
minf(x) x
i
∈[a
i
,b
i
];i=1,2,3,...,n;x=(x1,x2,...,x
m
)
ꢀꢀꢀ
(21)
[0229]
其中a
i
和b
i
是x
i
的下限和上限,m为x的维数。
[0230]
混沌映射通过以下模型优化:
[0231]
x
n 1
=μx
n
(1
‑
x
n
),n=0,1,2,...,n;0<x0<1
ꢀꢀꢀ
(22)
[0232]
其中μ为控制参数,μ值不同,会影响当m趋于无穷时,该模型的稳定解x
m
的值,μ值不同,系统的混沌程度不同。当μ=4,系统接近于完全随机。
[0233]
对于模型中的x
m
分别赋予n个初始值,生成混沌变量使用以下公式将初始值映射到混沌空间,生成混沌变量:
[0234][0235]
变异过程加入一个小的扰动。为进化后的向量赋予一个小的扰动,这个扰动可能使生成的向量得到更好的结果,当生成的向量无法向更好的方向进化之时,算法结束。
[0236]
粒子群优化算法分为两种状态:探索状态和开发状态。处于探索状态时,传统粒子群算法用随机的方式去搜索问题空间,但这时粒子可能经过变异,而陷入局部最优解;处于开发状态时,粒子群向最优区域聚合。
[0237]
这两个状态之间界限模糊。正是因为启发式算法随机的特性导致探索状态和开发状态之间无法有一个明确界限,导致了粒子群过早收敛。这可以通过引入混沌学习算法来加以解决。
[0238]
将混沌理论引入pso算法中,本发明考虑从初始化、趋同和变异阶段对pso算法的粒子参数进行优化,以达到对算法整体效果的优化,具体做法为:
[0239]
对初始向量进行混沌初始化。在pso优化算法中,通过控制初始参数恰当地控制全局搜索和局部进化是高效寻找最优解的关键,pso算法的性能很大程度上依赖于初始参数。通过混沌算法优化pso初始参数,使初始参数充分充满整个问题空间。具体做法为:在pso算法生成初始向量之后,使用混沌算法对生成的初始向量进行混沌初始化,利用混沌算法的特性对于初始向量的每一个x
m
分别赋予n个初始值,生成混沌变量
[0240]
混沌动态权重调整:在进化过程中,随着迭代次数的增加,动态调整混沌算法中的权重,使向量更快更准地向全局的最优区域进化。
[0241]
公式的前半部分表示之前速度值的影响,初始速度对进化方向起着导向作用;后半部分表示惯性权重ω是控制先前速度对当前速度影响的模数。因此,在pso中全局搜索与局部进化的平衡是由ω值所决定的,适当控制惯性权重对准确、高效地找到最优解至关重要。自适应惯性权重系数的确定如下:
[0242][0243]
其中,ω
max
和,ω
min
分别为权重系数ω的最大值和最小值,随着进化过程推进,ω逐渐减小。f是当前粒子的适应度,f
av
为粒子群整体的适应度平均值,f
min
为粒子群中的最小适应度。由上式可知,ω受f影响较大,ω的值随f变化。目标值较低的粒子将得到保护,超过均值的粒子将被破坏。也就是说,好的粒子倾向于通过局部搜索对结果进行挖掘,而不好的粒子倾向于通过大幅度的修改来调整。这为保持种群多样性和保持良好的收敛能力提供了一个很好的途径。
[0244]
混沌加速度系数:本发明引入混沌算法使在逐代进化时粒子的加速度系数趋于稳定。它增加了带时间的加速度系数c1和c2,考虑了粒子之间的相关性。当一开始设置大值c1,小值c2,允许粒子在搜索空间内移动,而不是向p
g
移动。小值c1和大值c2能使粒子在优化的后期收敛到全局最优解。时变加速度系数c1和c2由下面两个公式计算:
[0245][0246][0247]
其中,c
1i
和c
2i
是加速系数c1和c2的初始值,且c
1f
和c
2f
是加速系数的最终值。混沌动态权重和混沌加速度系数对pso算法中的趋同和异化过程起到调整作用,随着轮次的增大,轮次和当前轮次的差与最大轮次的比值将会随着轮次的增大而减小,这使得在进化初期,粒子可以拥有较大的加速度,而在进化后期趋于稳定。通过在pso算法中引入混沌学习算法增大pso的初始种群搜索范围,提高pso算法的稳定性。
[0248]
4、cpso
‑
bp浪高预测模型实现
[0249]
在第三章分别从bp网络、pso算法和混沌学习算法三个模块对cpso
‑
bp模型的理论基础进行了介绍。本发明基于第三章介绍的理论基础,从特征选取、模型实现方法详细介绍了cpso
‑
bp模型的实现步骤。并进一步分析了cpso
‑
bp的寻优过程,介绍了与cpso
‑
bp模型进行对比的cpso
‑
elm模型的实现方法。
[0250]
41特征选取
[0251]
在选择输入特征时,需要确定每个特征与海浪高度的相关性,为了选择更有效的输入特征,需要对每个输入参数与海浪高度之间的相关系数进行分析,选取相关系数高的特征作为预测海浪高度的输入特征。备选的神经网络输入特征有:平均海平面(mean sea level,msl)、10米风速u分量(u10)、10米风速v分量(v10)、平均海波方向(mean wave direction,mwd)、平均海波周期(meanwave period,mwp)五项特征。
[0252]
本发明通过皮尔逊相关系数r
x,y
计算各个变量与海浪高度(sea wave height,swh)的相关性,以相关性作为参考选取神经网络的输入特征。皮尔逊相关系数r
x,y
用来定量分析变量间的相关性,r
x,y
∈[
‑
1,1],当|r
x,y
|接近于1,两者相关性高,当|r
x,y
|接近于0,两者相关性低。r
x,y
的正负代表两个变量的相关性正负。可以根据以下公式进行计算:
[0253][0254]
|r
x,y
|>0.8时,两个变量高度相关;当|r
x,y
|∈[0.3,0.5))时,两个变量低度相关;当|r
x,y
|<0.3时,两个变量弱相关。swh与不同输入特征的相关系数如表1所示:
[0255]
表1 swh与各项特征的皮尔逊相关系数
[0256][0257]
从表1中可以看出v10和mwp的皮尔逊相关系数绝对值大于0.5。mwp为平均波周期,但mwp是根据波浪产生后的海浪波动周期进行计算。作为后验数据,不适合用来作为浪高预测神经网络的输入。同时u10和v10分别为精度和纬度上的风速分量,其相关性不适合单独拿出来作为海浪高度预测的参数。通过特征融合,计算观测点风速值uv用作网络的输入,uv可由以下公式进行计算:
[0258][0259]
如图5所示,特征融合后的新特征uv与swh具有最高的相关性,且与mwp不同,uv不
具有后验性,可以作为输入特征。
[0260]
因为偶然因素的存在,还需进行显著性分析,以保证各参数与swh的高度相关性。本发明选用p值(pvalue)来分析各参数的显著性。当原假设成立时,p值代表极端情况的发生几率。p值越小表示极端情况发生的几率越小,p值越大表示极端情况发生的几率大。因此,p值的大小表示各参数的显著性。当p值小于0.05时,表示该变量具有显著性;当p值小于0.001时,表示该变量具有高显著性;只有当显著性高且相关系数高时,将这个参数用作输入特征才有意义。好的输入拥有高相关性且p值一般小于0.1,具有越小的p值才可以认为两组数据有明显关系。
[0261]
swh与不同输入特征的显著性如表2所示,msl与uv具有高显著性,出现极端情况的几率低,适合用于作为网络输入特征值。u10和v10显著性过高,不适合作为网络的输入特征值,究其原因是因为他们分别是经线和纬线方向的风力分量,不能完整地代表风力大小,融合后的uv代表风力大小,所以使用融合后的uv作为输入参数更加合适。
[0262]
表2 swh与各输入特征的p值
[0263][0264]
图6以渤海121
°
e,40
°
n站点为例绘制2020全年的uv、u10、v10和swh曲线图,数据来源为era5数据集,本发明将在第五章对该数据集进行详细说明。如图6所示,可以从swh曲线中看到,渤海海域2月和11月浪高总体较高,出现了极大值,4月、7月和9月总体浪高较低,出现了极小值。图中uv曲线在2月和11月同样出现了极大值,4月、7月和9月出现了极小值,与swh曲线的趋势高度一致;而u10曲线的极大值在4月、10月和11月出现,极小值在2月、9月和11月出现;v10曲线的极大值在2月、5月、8月和11月出现,极小值在1月、4月和11月和12月出现,与swh曲线的趋势相似度低。综上所述,uv曲线和swh曲线具有高度相似性,uv和swh存在相同的变化趋势;而u10曲线和v10曲线与swh曲线差异较大,u10和v10的变化趋势与swh存在明显差异,不适合作为预测模型的输入特征。
[0265]
综上所述,uv和msl与swh具有高度相关性,本发明选用uv和msl作为网络的输入特征进行浪高。
[0266]
4.2cpso算法介绍
[0267]
粒子群优化算法分为两种状态:探索状态和开发状态。处于探索状态时,传统粒子群算法用随机的方式去搜索问题空间,但这时粒子可能经过变异,而陷入局部最优解;处于开发状态时,粒子群向最优区域聚合。
[0268]
这两个状态之间界限模糊。正是因为启发式算法随机的特性导致探索状态和开发状态之间无法有一个明确界限,导致了粒子群算法过早收敛。这可以通过引入混沌学习算法来加以解决。
[0269]
混沌行为是高度非线性的,但是每一种高度混沌模型都会呈现一定的行为特征。在特定环境下,混沌算法得以应用。所以当使用粒子群算法进行求解时,可以按照其粒子群行为特征建立其混沌模型,来解决粒子群过早收敛的问题。
[0270]
对粒子群进行位置初始化,第i个粒子的初始位置表示为:
[0271]
x
i
=(x
i,1
,x
i,2
,...x
i,n
),i∈[1,m]
ꢀꢀꢀ
(29)
[0272]
在生成初始向量之后,使用混沌算法对生成的初始向量进行混沌初始化。利用混
沌算法的特性对于初始向量的每一个x
i
分别赋予n个初始值,生成混沌变量通过如下公式可以将初始值从问题空间映射到混沌空间:
[0273][0274]
找到当前最优解和整个粒子群中的最优解来决定更新速率,当前适应度最高的解记作p
i
,整个粒子群中的最优解记作p
g
。
[0275]
第i个粒子的当前最优解表示为:
[0276]
p
i
=(p
i1
,p
i2
,...p
in
),i∈[1,m]
ꢀꢀꢀ
(31)
[0277]
全局最优解表示为:
[0278][0279]
pso通过在不同轮次改变每个粒子的速度,使解朝向趋于p
i
和p
g
的方向更新从而得到最优解。
[0280]
第i个粒子通过以下等式对速度进行更新:
[0281][0282]
其中,c1是局部加速系数,c2是整体加速系数,ω∈r,它被称之为惯性权重系数r1和r2为(0,1)区间内的随机实数。小值c1和大值c2能使粒子在优化的后期收敛到全局最优解。局部加速系数由以下公式计算:
[0283][0284]
整体加速系数由以下公式计算:
[0285][0286]
其中,c
1i
和c
2i
是加速系数c1和c2的初始值,且c
1f
和c
2f
是加速系数的最终值。
[0287]
自适应惯性权重系数可由以下公式计算:
[0288][0289]
其中,ω
max
和ω
min
分别为权重系数ω的最大值和最小值,随着进化过程推进,ω逐渐减小。f是当前粒子的适应度,f
av
为粒子群整体的适应度平均值,f
min
为粒子群中的最小适应度。
[0290]
第i个粒子通过以下等式对速度进行更新:
[0291][0292]
其中,x
i
是粒子i的位置,v
i
代表粒子i的速率,v
i
∈(v
min
,v
max
),v
min
和v
max
在[0,1]之内;λ∈r被称为限制因子,它被用来调整ω∈r,以此来限制速率。当达到最大轮次或收敛至符合适应度要求时,计算终止。
[0293]
cpso算法详细流程如algorithm1所示。
[0294]
algorithm 1
[0295][0296][0297]
4.3 cpso
‑
bp模型的实现方法
[0298]
本节介绍cdw如何为bp模型进行初始化阶段的优化。
[0299]
(1)确定bp网络模型结构。
[0300]
通过特征选取,本发明选择uv和msl作为输入特征值。确定网络输入节点数s
i
为2,隐藏层节点数s
o
为1,将隐藏层节点数s
l
设置为5。图7为本发明采用的bp神经网络结构。每个粒子的维数n可通过以下公式计算:
[0301]
n=s
i
×
s
l
s
l
×
s
o
s
l
s
o
q,q=1
ꢀꢀꢀ
(38)
[0302]
其中,q为每个粒子的适应度值,将其放在每个粒子的最后一维构成一个22维的粒子x
i
;s
i
×
s
l
为输入层到隐藏层的权值的数量,s
l
为隐藏层的阈值的数量。由公式(41)可确定粒子的维数n=22。
[0303]
(2)设置cpso初始参数。
[0304]
设置限制因子λ=0.92,自适应惯性权重因子的最大值ω
max
=0.9和最小值ω
min
=0.4,设置加速系数初始值c
1i
=c
2i
=0.5,设置加速系数最终值c
1f
=c
2f
=2.5。
[0305]
(3)根据bp网络模型的结构,生成cpso算法中的初始向量,并生成混沌向量。
[0306]
将输入层到隐藏层的权值和隐藏层的阈值作为cpso矩阵中的元素,cpso中的每一个粒子都表示bp网络的初始参数。对种群x初始化,模型随机产生一个大小m为2000的粒子群,初始种群的第i个粒子由以下公式计算:
[0307]
x
i
=(x
i,1
,x
i,2
,...x
i,m
),i=1,2,...,22
ꢀꢀꢀ
(39)
[0308]
然后,为x
i
中每一个参数加入一个微小的扰动,由此生成初始混沌向量,第i个初始混沌向量由以下公式计算:
[0309][0310]
(4)通过适应度的大小来对种群中的每一个粒子进行打分。
[0311]
每一个粒子的适应度为均方差的倒数,通过适应度的大小来对种群中的每一个粒子进行打分,将各个粒子的得分设为向量的最后一项,适应度与bp网络模型的权值和阈值一起作为该粒子的参数,以确定一个粒子的结构。第i个粒子的适应度由以下公式计算:
[0312][0313]
通过得到的适应度值对每个粒子进行排序,排名前五的粒子作为优胜粒子,排名次五的粒子作为临时粒子。
[0314]
(5)为粒子群按照适应度值进行排序,再对粒子群进行寻优,生成新的粒子群。
[0315]
按照适应度得分,排序最靠前的5个粒子作为优胜粒子,记作i=1,2,...,5,在这五个粒子之后排名次五粒子作为临时粒子,记作i=1,2,...,5。然后以这十个被选出来的优胜粒子和临时粒子作为新的中心,与随机矩阵相加19次,分别生成19个新的粒子。可表示为随机生成一个22维矩阵y=[y
1 y
2 ... y
22
],其中。将分别与矩阵y相加,将相加后的新矩阵归一化到与y相同的区间。相加后的新矩阵可由以下公式计算:
[0316][0317]
其中,l
manx
可由以下公式计算:
[0318]
l
max
={max||x
i
y
i
|,i=1,2,...,22},n=1,2,...,19
ꢀꢀꢀ
(43)
[0319]
每一个优胜粒子和临时粒子与之后生成的19个z
n
组成一个新的粒子群。从而产生5个新的优胜粒子群,记作以及5个新的临时粒子群,记作
[0320]
(6)混沌趋同和混沌异化操作。
[0321]
将五个优胜粒子和五个临时粒子分别作为中心,生成10个新的粒子群,将新生成的粒子按照适应度值进行重新排序。
[0322]
混沌趋同:当子群体进行趋同操作时,种群会以自己内部得分最高的个体为中心,生成新的子群体,如果新的子群体中有比自己得分高的,那么则以新的优胜个体为中心继续趋同操作。更新计算粒子的适应度f的平均值f
av
和适应度f的最小值f
min
,更新权重系数
ω。
[0323]
混沌异化:更新自适应惯性权重系数ω、局部加速系数c1和整体加速系数c2。将更新后的值代入公式36可计算出粒子进行混沌化后的速度,接下来通过公式40可计算出粒子新位置。根据粒子的新位置重新计算粒子坐标和适应度f,当出现f值更高的粒子,就用这一粒子生成新的粒子群,将适应度值低的粒子淘汰,直到粒子群成熟,所有个体收敛。
[0324]
如果异化后的粒子群仍未收敛,则重复该步骤直至网络收敛。
[0325]
(7)将适应度最高的个体x
best
=[x
1 x
2 ... x
22
]作为bp神经网络的输入。
[0326]
将x
best
中x1,x2,...,x
10
作为网络输入层到隐藏层的连接权值,记作将x
best
中x
11
,x
12
,...,x
15
作为神经隐藏层到输出层的连接权值,记作w2=[x
11
,x
12
,...,x
15
]
t
;将x
best
中x
16
,x
17
,...,x
20
作为隐藏层中各个节点的阈值,记作b1=[x
16
,x
17
,...,x
20
]
t
将x
best
中x
21
作为输出层中各个节点的阈值,记作b2=[x
21
]
t
。将w=[w1,w2]
t
和b=[b1,b2]
t
分别作为bp网络的初始权值和阈值,形成初始cpso
‑
bp模型。
[0327]
(8)训练预测模型,进行仿真预测(见图8)。
[0328]
4.4 cpso
‑
bp模型的寻优过程
[0329]
在cpso
‑
bp模型中,cpso在解空间中寻找最优的粒子对bp网络的初始权值和阈值进行优化。cpso通过趋同和异化运算来发掘适应度更高的粒子。在进行趋同运算之前,cpso先根据适应度值将所有粒子进行排序,从排名靠前的粒子中找到最优粒子和临时粒子。再由最优粒子和临时粒子为中心,生成新的粒子群,对每个新生成的粒子群进行排序,进行趋同和异化操作。当异化过程不再产生适应度值更高的粒子,即找到最优粒子时,不再对粒子群进行更新,算法结束。
[0330]
在cpso的优化过程中,在选取5个优胜粒子和5个临时粒子之后,分别以它们为中心生成了5个优胜粒子群和5个临时粒子群。以cpso算法真实流程为例子,图9为5个优胜粒子群的趋同过程适应度得分,图10为5个临时粒子群的趋同过程适应度得分。通过图9和图10可以看出,每个粒子群适应度得分在经过一定次数的变化之后趋于一个稳定值,这说明粒子群已经成熟,适应度得分不再变化。当每个粒子群经过趋同运算,每个粒子群的最终得分为其内部得分最高的粒子的适应度值。在进行最优粒子群更新之后,进入异化阶段。
[0331]
图11为优胜粒子群经过变异后的趋同过程适应度得分图,图12为临时粒子群经过变异后的趋同过程适应度得分图。从图11可以看出,在经过异化之后没有产生适应度值高于优胜粒子的粒子,所以适应度得分不再变化。从图12可以看出,在五个临时粒子群中,在变异之后有子种群1、子种群3和子种群5产生了适应度得分更高的个体。
[0332]
对比图9和图10中的粒子得分,可以看到优胜粒子群中的子种群2,子种群3和子种群4的适应度值得分低于临时粒子群中的子种群1、子种群2和子种群5的适应度值得分。所以,由临时粒子群中的子种群1、子种群2和子种群5取代优胜粒子群中的子种群2,子种群3和子种群4作为新的优胜粒子群进入异化阶段。然后将优胜粒子群被替换的三个粒子群淘汰,再在临时粒子群中随机生成三个新的粒子群,进入异化阶段。图11中的粒子群适应度得分没有发生改变,这是因为在进入异化阶段之前它们已经找到了最优解,所以再进入趋同阶段粒子群不再发生变化。对比图11和图12可以看出,在经过4次趋同运算之后粒子群的适应度得分不再变化,说明此时所有的粒子群已经成熟,满足算法停止条件,cpso算法寻优至
此结束。将cpso找到的适应度值最高的粒子的值传入bp神经网络作为初始权值和阈值。
[0333]
4.5cpso
‑
elm模型实现
[0334]
cpso
‑
elm模型的形式与cpso
‑
bp模型类似。cpso在算法策略上不变,在cpso算法运行结束后将算法寻找到的最优解传入elm作为其初始权值和阈值。
[0335]
elm在确定了输入层到隐藏层各个节点的权值和隐藏层的阈值之后,elm就能自行确定隐藏层神经元到输出层神经元的权值。通过41节的特征选取,本发明选择uv和msl作为输入特征值,通过训练bp神经网络对swh进行预测。输入神经元个数s
i
为2,输出层节点数s
o
为1,将隐藏层节点个数s
l
设置为5,elm的网络结构如图3所示。每个粒子的维数n,通过以下公式计算:
[0336]
n=s
i
×
s
l
s
l
q,q=1
ꢀꢀꢀ
(44)
[0337]
其中,q为每个粒子的适应度值,将其放在每个粒子的最后一维构成一个16维的粒子r
i
;s
i
×
s
l
为输入层到隐藏层的权值数量;s
l
为隐藏层神经元的阈值数量。由公式47可确定粒子的维数n=16。
[0338]
cpso
‑
elm模型的基本思想是将使用cpso算法优化过的参数作为elm网络的初始权值和阈值传入elm网络。其优化策略和cpso
‑
bp模型一样,都试图通过优化神经网络参数来对预测的效果进行优化。
[0339]
图13为cpso
‑
elm模型的预测流程图。
[0340]
46首先,介绍了bp神经网络的输入特征选取工作,对海浪高度的各个特征进行分析,最终选取uv和msl作为bp神经网络的输入特征。接下来对cpso
‑
bp模型的工作流程进行了详细的介绍。并介绍了作为对照的cpso
‑
elm模型的工作流程。
[0341]
5、实验结果与分析
[0342]
在cpso
‑
bp浪高预测模型的基础上,本发明选取标准bp神经网络(st
‑
bp)与cpso
‑
elm与cpso
‑
bp的预测结果进行比较,通过仿真结果分对比析cpso
‑
bp模型进行海洋预警领域浪高预测的优势。
[0343]
本发明首先介绍了实验数据集和评估指标,为接下来的实验结果分析做准备。接着从预测结果的准确度和模型的性能两大方面进行比较。通过多项指标对st
‑
bp、cpso
‑
elm与cpso
‑
bp三个模型进行评估,逐一比较了三个模型的精确度、泛化能力、预测稳定性和及时性。
[0344]
51实验准备
[0345]
本发明使用黄海和渤海两大海域海洋浪高数据,数据来源为来自欧洲中期天气预报中心(european centre for medium
‑
rangeweatherforecasts,ecmwf)的era5数据集。era5是ecmwf对全球气象数据通过将模型数据与来自世界各地的观测数据结合起来进行再分析得到的第五代数据集,era5数据集使用卫星观测拥有极高的空间分辨率,数据集提供大气的每小时估值,并采用一致的不确定性表示方法,数据规范可靠。
[0346]
本发明选取黄海和渤海区域各六个观测站点,总计12个观测点的数据。渤海站点分布如图14(a)所示,黄海站点分布如图14(b)所示,图14中有效波高平均态数据来自era5,为1981年
‑
2010年的平均。黄海海浪高度数据的观测点分别在黄海海域的345
°
n、355
°
n、365
°
n的122
°
e和123
°
e处。渤海海浪高度数据的观测点分别在渤海海域的38
°
n、39
°
n、40
°
n的120
°
e和121
°
e处。
[0347]
12个观测点在每日采集4次数据,由0:00开始,每间隔6小时采集一次数据,本发明使用数据集的时间跨度为:2020年1月1日至2020年12月31日。每个观测点数据量为1464组,代表各个观测点各时间点的海浪高度,每个海域六个观测点共8784组。两大海域数据总计17568组。
[0348]
渤海和黄海一年之内的观测点数据如图14所示,图15是渤海六个站点的2020年度浪高图,图16是黄海六个站点的2020年度浪高。
[0349]
从图15可以看出渤海海域总体海浪趋势平稳,六个站点的年度观测值进行平滑处理后的曲线各个季节的变化率较小,海况较为稳定。6月
‑
11月的海浪高度较其他月份更低。在120
°
e,40
°
n站点,2月中旬和11月中旬出现了持续数日的大浪,12月底出现了一个浪高的最高点。从图16看出,黄海海域2020年的浪高总体平稳,在12月出现全年浪高的最高点。这可能是由于黄海海域在2020年面临了突发气候事件,这造成了图中海浪高度曲线发生较大的波动。就整体而言,虽然渤海海域在2月中旬和11月中旬出现了两个月的海浪高度突变,黄海海域12月浪高较其他月份变化明显,但两大海域2020年海浪高度呈现一定周期性,总体呈现一定规律。
[0350]
53评测指标
[0351]
本发明选取mae、mape、rmse、nse和r2这5个指标作为验证模型误差的指标,从不同方面对实验误差进行验证,以下是对这些指标的详细说明:
[0352]
平均绝对误差(mae),用来比较预测结果和真实值的吻合度,取值范围在[0, ∞),mae值越接近0,说明模型越接近真实值;当mae值为0时,表示模型能够对真实值进行完美预测。mae可由以下公式计算:
[0353][0354]
平均绝对百分比误差(mape)对预测模型进行评估,当mape越接近于0,模型预测效果越好;当mape大于100%,模型预测效果不可靠。可由以下公式计算:
[0355][0356]
均方根误差(rmse)取值范围在[0, ∞),rmse能够直观地表示误差的数量级,例如:当rmse=1,说明回归效果比真实值相差1。rmse可由以下公式计算:
[0357][0358]
纳什效率系数(nse)取值范围为(
‑
∞,1],用于评估模型预测结果的好坏。nse越靠近1,模型的质量越好,可信度越高。nse越接近0,预测结果可信。nse远远小于0时,模型预测结果不可靠。nse可由以下公式计算:
[0359][0360]
回归系数r2反映变量间的相关程度。r2取值为[0,1],r2越接近于1,模型的预测准确度越好;r2越接近于0,模型的预测准确度越差。当r2<0.3,认为模型是不可靠的;当r2>0.6,认为模型有一定预测能力;当r2>0.7,认为模型能够进行较为准确的预测;当r2>0.8,认为模型具有较好的预测能力。r2可由以下公式计算:
[0361][0362]
53实验结果分析
[0363]
本节使用cpso
‑
bp与未经cpso优化的st
‑
bp模型和cpso
‑
elm模型进行仿真实验。通过对比三个模型的预测结果的各项指标,来比较cpso算法优化bp模型的效果。
[0364]
531预测精度分析
[0365]
表3三种型初始参数
[0366][0367]
本发明使用matlab进行仿真,实验中使用的计算机配置为:windows 10操作系统,硬盘大小为1t,matlab版本为r2018a。如表3所示,使用的elm和bp神经网络均使用2个输入神经元,5个隐藏层神经元和1个输出神经元的神经网络结构。学习率η均取005,收敛误差ε设置为0001。cpso
‑
elm和cpso
‑
bp两个模型中作为对照,将粒子群大小均设置为2000,优胜粒子群的个数n
s
和临时粒子群的个数n
t
设置为5,迭代次数阈值iter置为10。表3是四种模型的初始化参数。
[0368]
每片海域六个站点,每个站点收集12个月,每日4个数据,数据集共计16768组数据。三个模型均为以黄海12月为预测集,其他11个月为训练集进行训练的预测模型的预测结果。将两个海域前8384组数据作为模型的训练集,将后400组数据作为测试集进行实验。
[0369]
图17、图18、图19分别为st
‑
bp、cpso
‑
elm和cpso
‑
bp模型在实验中的训练集和测试集实际数据与预测值的回归趋势线和回归散点分布图。预测回归趋势的斜率越接近于1,说明模型的训练效果越好;越接近于0,模型的训练效果越差。在散点分布图中,散点分布越集中且越靠近回归趋势线,模型的预测越准确。
[0370]
图17、图18、图19通过计算r2对三种模型的泛化能力进行评估,r2越接近于1,模型的泛化能力越高;越接近于0,模型的预测泛化能力越低。
[0371]
如图17,st
‑
bp训练阶段的r2为07479,测试阶段的r2为0.7464,测试阶段的预测准确度较训练阶段无明显下降,模型有一定泛化能力。测试集趋势分布线为y=07454x 01989,分布线的斜率较接近于1,预测较为准确性。
[0372]
如图18,cpso
‑
elm训练阶段的r2为08519,测试阶段的r2为07560,模型预测效果较好,测试阶段的r2较训练阶段的r2有所下降,模型泛化能力较强。测试集趋势分布线为y=07560x 01919,分布线的斜率较st
‑
bp的预测趋势分布线的斜率更接近于1,cpso
‑
elm的泛化能力和预测能力较st
‑
bp好。
[0373]
如图19,cpso
‑
bp训练阶段的r2为08713,测试阶段的r2为08529,模型预测效果较好,测试阶段的r2较训练阶段有所下降,cpso
‑
bp模型的r2在训练阶段和测试阶段均大于08,cpso
‑
bp模型具有极强的泛化能力。测试集趋势分布线为y=08508x 02034,分布线的斜率接近于1,其斜率比st
‑
bp模型,cpso
‑
elm模型更接近于1,cpso
‑
bp的泛化和预测能力较st
‑
bp和cpso
‑
elm更好。
[0374]
cpso
‑
bp模型在训练和测试阶段的预测准确性都高于其他两个模型,其r2在训练
和预测阶段也高于其他两个模型,说明cpso模型的泛化能力要好于st
‑
bp和cpso
‑
elm模型。同时,cpso
‑
bp在训练阶段和预测阶段的r2值高于cpso
‑
elm在训练阶段和预测阶段的r2值,说明cpso算法优化的bp网络的预测效果要好于优化elm的效果。经过cpso对初始参数的改进,两个模型的泛化能力得到了显著提升。从总体看来,cpso算法对bp神经网络和elm的预测效果都起到了提升的作用。虽然每个cpso优化算法在每一次的初始化阶段产生的粒子位置随机,其趋势线和r2会有所变化,综合比较之下cpso
‑
bp模型的预测效果最好,cpso
‑
elm模型次之。
[0375]
表4 st
‑
bp预测结果评价指标表
[0376][0377]
表5 cpso
‑
elm预测结果评价指标表
[0378][0379]
表6 cpso
‑
bp预测结果评价指标表
[0380][0381]
5.3.2预测结果与实际数据对比
[0382]
图20、图21分别为渤海海域和黄海海域的仿真数据对比图。将渤海和黄海两个海域前11个月的数据分别作为实验的训练集,将12月的数据作为测试集,分别对st
‑
bp、cpso
‑
elm和cpso
‑
bp三个模型进行训练,对比三者的预测效果。通过将st
‑
bp、cpso
‑
elm和cpso
‑
bp三个模型的预测曲线和真实数据曲线放在同一张图中,可以更直观地看出三个模型的预测效果和预测误差。将渤海和黄海两个海域前11个月的数据分别作为实验的训练集,将12月的数据作为测试集,分别对st
‑
bp、cpso
‑
elm和cpso
‑
bp三个模型进行训练,对比三者的预测效果。
[0383]
如图20、图21所示,在对渤海12月浪高的预测中,cpso
‑
bp模型的预测曲线与黄渤海的真实值曲线最为接近,st
‑
bp和cpso
‑
bp模型也有较好的预测效果;在对黄海12月浪高的预测中,三个模型的预测曲线与真实值都出现了一定偏差,cpso
‑
bp模型的预测曲线走势最接近真实浪高曲线,st
‑
bp和cpso
‑
elm模型的预测曲线都出现了较大偏差。cpso通过对粒子群算法初始化阶段和趋同阶段的位置更新策略进行了优化,使初始化粒子群时能够更充分地充满整个解空间,以确保粒子群向更优的方向进化。从图20和图21中可以看出,cpso
‑
bp模型的预测曲线最贴近真实浪高数据。综合看来,cpso
‑
bp预测曲线在对渤海海域海洋浪
高预测拟合程度最好,cpso算法和bp神经网络的结合能够得到较好的预测结果。
[0384]
5.4预测性能分析
[0385]
5.4.1预测误差分析
[0386]
从图15可以看出渤海海域总体海浪趋势平稳,海况较为稳定。但2月中旬和11月中旬出现了持续数日的大浪。从图16看出,黄海海域和黄海海域2020年的浪高变化较为平稳。就整体而言,两大海域2020年海浪高度呈现一定周期性,总体呈现一定规律。渤海海域在2月中旬、11月中旬和12月出现了浪高的海浪高度突变,黄海海域在12月出现了。所以在误差分析实验中,除了将前11个月作为训练集,12月作为测试集,同时将渤海2月和11月数据分别作为测试集,其他11个月的数据作为训练集对模型进行预测。同样,对于黄海也将2月、11月和12月分别作为测试集,其他11个月作为训练集对模型进行验证。
[0387]
表4、表5和表6分别表示st
‑
bp、cpso
‑
elm和cpso
‑
bp三种模型的预测结果的mae、mape、rmse、nse四个指标的值和它们平均值。通过对四个评价指标的平均值进行对比可以看出,cpso
‑
elm的mae、mape、rmse三项指标的平均值均小于cpso
‑
bp和st
‑
bp各项指标的平均值,cpso
‑
elm的nse指标的平均值大于cpso
‑
bp和st
‑
bp的nse指标的平均值,说明cpso
‑
bp的预测效果优于cpso
‑
elm和st
‑
bp。cpso
‑
elm各项指标的平均值与cpso
‑
bp各项指标的平均值接近,cpso
‑
elm的预测效果虽然不如cpso
‑
bp,但已十分接近cpso
‑
bp的预测效果。总体而言,cpso
‑
bp具有最好的预测效果和泛化能力,cpso
‑
elm次之。
[0388]
图22为对渤海的三个模型浪高预测结果平均值的对比柱状图,图23为对黄海的三个模型浪高预测结果平均值的对比柱状图。从图22中可以看出,cpso
‑
bp对渤海的预测结果的mae、mape、rmse三项指标在三个模型中是最低的,这说明cpso
‑
bp的预测误差是三个模型中是最低的;cpso
‑
bp对渤海的预测结果的nse指标在三个模型中是最高的,这说明cpso
‑
bp模型的预测效果是三个模型中预测效果最好的。从图23中可以看出,cpso
‑
bp对黄海的预测结果的mae和mape两项指标在三个模型中是最低的,st
‑
bp对黄海的预测结果的rmse指标在三个模型中是最低的,这可能是由于2020年黄海12月的浪高出现了异常的变化,导致cpso
‑
bp和cpso
‑
elm的预测结果不稳定,但在海况不稳定的情况下cpso
‑
bp的预测性能仍较cpso
‑
elm更好,cpso
‑
bp模型的预测泛化能力更强;cpso
‑
bp对黄海的预测结果的nse指标在三个模型中是最高的,这说明cpso
‑
bp模型的预测效果是三个模型中预测效果最好的。总而言之,cpso
‑
bp在稳定海况的海域中预测效果最好,在不稳定海况仍有较强泛化能力。
[0389]
542预测稳定性分析
[0390]
表4、表5、表6展示了预测结果的四项评估指标。cpso
‑
bp模型预测结果的mae、mape、rmse的平均值在三个模型中都是最小的。虽然在具体的预测中存在cpso
‑
elm的误差小于cpso
‑
bp的情况,但总体看来cpso
‑
bp的预测效果最为理想。
[0391]
神经网络类模型优化过程存在一定随机性,同一模型在对于同一个月的预测可能会出现差异,如出现反常气候,将使预测值出现偏差,偏差越大说明该模型的仿真效果越差,偏差越小说明该模型的仿真效果越好。表7是三个模型预测结果的四个指标的方差,通过对比各项指标的方差,可以比较三个模型的预测稳定性。
[0392]
表7为三个预测模型的预测结果各项指标的方差。从表中可以看出cpso
‑
elm在mae和nse指标的方差最低,但三个模型在mae指标的方差均在同一数量级;cpso
‑
bp在mape和rmse两项指标的方差最低,且在mape项的方差比另外两个模型的方差低一个量级。综合看
来,cpso
‑
bp模型和cpso
‑
elm模型具有相似的稳定性,两个模型的稳定性都比st
‑
bp更好。
[0393]
表7三个模型每项指标的预测方差
[0394][0395]
图24为三个模型预测结果的四项指标方差对比柱状图。从图中可直观地看出cpso
‑
bp的mape和rmsw两项指标的方差要远远低于st
‑
bp和cpso
‑
bp;三个模型mae和nse两项指标的方差在相同数量级。总体而言,cpso
‑
bp模型拥有最好的稳定性。
[0396]
进行准确且快速的预测是训练网络模型的目标。如表8所示,三种模型的预测结果和预测时间均存在一定的不稳定性。为了更深入地对比三种模型的准确性和及时性,分别对每种模型进行10次训练以预测12月的海浪高度,将每次的预测结果的r2和运行时间记录下来,分别求出每一项的平均值和方差以验证三个模型的预测准确性和稳定性。
[0397]
如表8,st
‑
bp的预测精确度平均值为07368,cpso
‑
elm的精确度平均值为07888,cpso
‑
bp的预测精确度平均值为08393;cpso
‑
bp的平均运行时间为8070秒,cpso
‑
elm的平均运行时间为5710秒。综合看来,cpso
‑
bp的预测效果最好,cpso
‑
elm的预测效果次之。bp网络本身运行时间极快,相对于cpso
‑
elm和cpso
‑
bp可以忽略不计,在三个模型中其平均运行时间最快。cpso算法的寻优过程中需要进行逐代的优化操作,这使cpso算法提升了bp神经网络的预测精确度和泛化能力的同时,也增加了bp网络的运行时间。cpso
‑
bp的预测速度与cpso算法的迭代次数,初始参数,样本数量等因素有关。由于elm神经网络比bp运行速度更快,使得cpso
‑
bp模型的运行速度要快于cpso
‑
elm模型,cpso
‑
bp的预测结果比cpso
‑
elm更为准确,但反向传播使网络的运行时间更长,但提升了cpso
‑
bp模型的准确性。如表8,st
‑
bp的预测精确度平均值为07368,cpso
‑
bp的预测精确度平均值为08393,cpso
‑
bp模型大大改进了st
‑
bp模型的预测效果。综合而言,cpso
‑
bp模型取得了最准确的预测结果,虽然增加了模型的运行时间,计算速度仍较物理模型更快,能都在保证及时性的同时,做到更准确的预测。
[0398]
综合而言,cpso
‑
bp对于渤海和黄海海域的预测准确度较st
‑
bp和cpso
‑
elm更好,且cpso
‑
bp的稳定性和泛化能力更好。cpso
‑
bp模型十次实验结果的平均运行时间与cpso
‑
elm在同一量级,但预测效果较cpso
‑
elm更好,cpso
‑
bp能够在保证预测及时性的同时,提高预测模型的预测能力和泛化能力。
[0399]
表8三种模型的预测精度及运行时间
[0400][0401]
55本发明介绍了实验相关的准备,介绍了本发明采用的数据集,并通过数据集分
析了两个目标海域数据当年的浪高情况。之后给出了用于评估实验结果的五个指标的计算公式及详细说明。接下来对实验结果进行了详细的分析。首先,根据预测效果的趋势分布图,通过st
‑
bp、cpso
‑
elm和cpso
‑
bp模型的r2,比较三个模型的预测准确性和泛化能力;接着,将三个模型的预测效果和实际结果进行对比,进一步比较了三个模型的预测性能;然后,对比各个模型在对黄渤海2月、11月和12月的4项指标来分析模型的预测效果;最后,通过比较三个模型的4项预测指标的方差和三个模型进行10次预测的测试集r2对比三个模型的预测稳定性,通过三个模型10次预测平均预测时间对比了三个模型的预测及时性。
[0402]
海浪高度预测关系到海洋预警和海上工程的安全及时开展。传统浪高预测方法包括物理模型和经验模型。物理模型通过力学分析对真实海况进行模拟,物理模型能够得到较为准确预测效果,但由于海洋环境的复杂性,物理模型在建模过程中需要使用到大量的计算资源,算法的运行时间较长。经验模型建立不需要任何物理参数,模型训练速度快,但是预测的准确率较低。而在海洋预警中,浪高预测的准确性和预测速度都至关重要。
[0403]
机器学习方法能够在较短的时间内构建海浪高度预测模型。相对于传统浪高预测物理模型,使用深度学习方法进行浪高预测有着准确性高、成本低、运行速度快的优点。在海洋预警中的浪高预测问题上,非常适合使用深度学习方法进行浪高预测。
[0404]
本发明旨在结合bp神经网络和cpso算法构建一个准确高效的海浪高度预测模型。通过混沌粒子群优化算法的寻优能力,来弥补神经网络固有的不足,得到一个较传统物理方法更为高效的模型,在保证预测准确率的情况下,使资源和建模时间的消耗降低。
[0405]
本发明使用一个基于混沌粒子群优化算法优化的bp神经网络模型(cpso
‑
bp)用于进行海洋浪高预测。通过逐代筛选,找到一个最优的粒子,并将cpso算法的结果传递给bp神经网络。将cpso算法的计算结果作为bp神经网络的初始权值和阈值,形成cpso
‑
bp模型,通过使用训练后的cpso
‑
bp网络进行海洋浪高预测任务,使网络的预测性能得到提升。
[0406]
本发明实验使用中期天气预报中心2020年的渤海和黄海各6个站点每6小时记录一次的浪高数据。通过对浪高数据各个参数与浪高之间的相关系数进行计算和分析,选取了模型的输入特征。分别使用st
‑
bp、cpso
‑
elm、cpso
‑
bp模型使用前11个月的数据进行训练,用第12个月的数据作为测试集来评估三个模型的浪高预测效果。通过对三个模型预测结果的回归曲线、预测曲线和各个实验指标的对比,从预测准确性、及时性、鲁棒性和泛化能力角度,分析了cpso
‑
bp模型在解决海洋预警领域浪高预测问题上的优势。本发明对cpso
‑
bp海洋浪高预测模型的研究,对今后海洋浪高预测相关问题的研究具有一定意义的参考作用和应用价值。
[0407]
在上述实施例中,可以全部或部分地通过软件、硬件、固件或者其任意组合来实现。当使用全部或部分地以计算机程序产品的形式实现,所述计算机程序产品包括一个或多个计算机指令。在计算机上加载或执行所述计算机程序指令时,全部或部分地产生按照本发明实施例所述的流程或功能。所述计算机可以是通用计算机、专用计算机、计算机网络、或者其他可编程装置。所述计算机指令可以存储在计算机可读存储介质中,或者从一个计算机可读存储介质向另一个计算机可读存储介质传输,例如,所述计算机指令可以从一个网站站点、计算机、服务器或数据中心通过有线(例如同轴电缆、光纤、数字用户线(dsl)或无线(例如红外、无线、微波等)方式向另一个网站站点、计算机、服务器或数据中心进行传输)。所述计算机可读取存储介质可以是计算机能够存取的任何可用介质或者是包含一
个或多个可用介质集成的服务器、数据中心等数据存储设备。所述可用介质可以是磁性介质,(例如,软盘、硬盘、磁带)、光介质(例如,dvd)、或者半导体介质(例如固态硬盘solid state disk(ssd))等。
[0408]
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,都应涵盖在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。