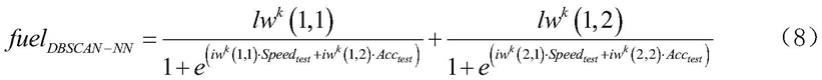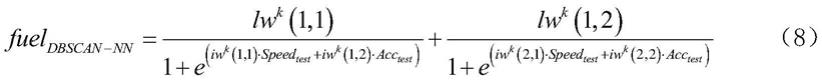
1.本发明属于汽车控制技术领域。
背景技术:
2.现有建立车辆油耗与排放模型的方法可以分为完全通过工作机理分析,建立物理模型的建模,这样建模方法由于需要详细描述燃烧过程、热工转换过程才能达到使用精度,因此模型结构复杂,计算量大,不利于车辆油耗与排放控制使用。第二种是使用数据,基于数据驱动得到的黑箱模型。这样的模型由于是通过车辆的历史数据利用“学习”(例如神经网络)的方法获得,这样的模型为了兼顾车辆的不同工况使用,因此需要复杂的学习结构(例如神经网络结构)。并且由于车辆的工况复杂,所以很多时候需要牺牲“精度”去满足“全面性”,即为了兼顾全部工况而建立一个整体较好,但是每个工况不那么好的模型。
技术实现要素:
3.本发明的目的是将数据聚类与神经网络结合的建模方法,先使用聚类算法根据车辆不同工况下的数据内部特点,将车辆数据聚类成不同的数据簇,然后使用每个工况对应的数据簇建立专属神经网络模型的根据不同工况的数据簇建立柴油车辆油耗与排放模型方法。
4.本发明的步骤是:s1、选择建立车辆速度与加速度车辆油耗与nox排放的模型,共采集了n组数据,n根据不同驾驶循环下的训练数据个数而定;s2、将模型的输入为[speed acc],模型的输出为[fuel no
x
],其中speed为车辆速度,acc为车辆加速度,fuel为车辆的油耗,no
x
为车辆的氮氧化物排放;s3、定义eps邻域:车辆输入数据集中的数据点[speed
q acc
q
]属于输入数据集,且d
ist
([speed
p acc
p
],[speed
q acc
q
])≤eps
ꢀꢀꢀꢀꢀꢀꢀꢀ
(1)其中,p代表数据点的序号,表明第p个数据;d
ist
([speed
p acc
p
],[speed
q acc
q
])表示两个数据点[speed
p acc
p
]与[speed
q acc
q
]之间的欧式距离,其中q代表数据点的序号,表明第q个数据,若满足上式,则表明数据点[speed
q acc
q
]在数据点[speed
p acc
p
]的eps邻域内;s4、基于公式(1)得到:n
eps
([speed
p accp])={[speed
q acc
q
]∈输入数据集|d
ist
([speed
p acc
p
],[speed
q acc
q
])≤eps}
ꢀꢀꢀꢀ
(2)n
eps
([speed
p acc
p
])为车辆输入数据集中在数据点[speed
p acc
p
]的eps邻域内所有数据点的集合;s5、定义核心数据点minpt为设定的邻域密度阈值,若存在数据点[speed
p acc
p
]满足:|n
eps
([speed
p acc
p
])|≥minpts
ꢀꢀꢀꢀꢀꢀ
(3)
公式(3)为数据点[speed
p acc
p
]是一个核心数据点的判断条件,其中|n
eps
([speed
p acc
p
])|表示数据点[speed
p acc
p
]的eps邻域内全部数据点个数;s6、定义密度直达给定车辆的输入数据集,若存在数据点[speed
q acc
q
]∈|n
eps
([speed
p acc
p
])|且数据点[speed
p acc
p
]满足式(2)(3),即数据点[speed
q acc
q
]在数据点[speed
p acc
p
]的eps邻域内且数据点[speed
p acc
p
]为核心数据点,则称数据点[speed
q acc
q
]是从数据点[speed
p acc
p
]密度直达的;s7、定义密度可达给定车辆的输入数据集,若存在数据点链([speed
p acc
p
],[speed
q acc
q
],
…
,[speed
i acc
i
]),对于每个相邻数据点之间都是密度直达,则称数据点[speed
i acc
i
]从数据点[speed
p acc
p
]是密度可达的;s8、定义簇,给定车辆的输入数据集,若数据集中具有非空子集,且满足以下条件,则称非空子集为簇:(1)对任意数据点[speed
q acc
q
],若核心数据点[speed
p acc
p
]在某一特定非空子集内且对象[speed
q acc
q
]是从核心数据点[speed
p acc
p
]密度可达的,则数据点[speed
q acc
q
]也属于该特定非空子集;(2)对任意数据点[speed
p acc
p
]在某一特定非空子集内,[speed
q acc
q
]在该相同的特定非空子集内,数据点[speed
p acc
p
]和数据点[speed
q acc
q
]是密度相连的;s9、定义噪声点,若数据点[speed
p acc
p
]不属于任何簇,则数据点[speed
p acc
p
]为噪声点:[speed
p acc
p
]、[speed
q acc
q
]、[speed
i acc
i
]为核心数据点;[speed
l acc
l
][speed
j acc
j
]密度直达的关系为:[speed
l acc
l
]由[speed
p acc
p
]密度直达,[speed
q acc
q
]由[speed
p acc
p
]密度直达,[speed
i acc
i
]由[speed
q acc
q
]密度直达,[speed
j acc
j
]由[speed
i acc
i
]密度直达;密度可达的关系为:[speed
i acc
i
]由[speed
p acc
p
]密度可达,[speed
j acc
j
]由[speed
p acc
p
]密度可达,[speed
j acc
j
]由[speed
q acc
q
]密度可达;其中i、j、l分别指第i个数据、第j个数据和第l个数据;s10、基于数据之间的密度,将数据集划分为不同的数据簇:c
k
,(c
k
∈输入数据集,k∈k)
ꢀꢀꢀ
(5)其中,c为数据簇,k为数据簇的序号,k为数据一共聚类的簇数,c
k
表明为第k个数据簇;s11、对于不同数据簇,使用单隐含层双节点结构神经网络建模,采用下式作为隐含层节点的激活函数:其中为第k个数据簇对应神经网络的隐含层节点的第n个输出,为第k个数据簇对应神经网络的隐含层节点的第m个输入;s12、采用线性激活函数:
作为输出层的激活函数,其中为第k个数据簇对应神经网络的输出层节点的输出,为第k个数据簇对应神经网络的输出层节点的第n个输入;s13、使用matlab中工具箱训练神经网络即获得第k个数据簇对应神经网络的隐含层权重参数lw
k
与第k个数据簇对应神经网络的输入层权重参数iw
k
的具体数值,具体获得方法如下描述,具体步骤以及每一步程序语句与语句含义如下:设置训练函数:trainfcn='trainbr';设置单隐含层双节点的结构:hiddenlayersize=2;定义神经网络整体框架:net1=fitnet(hiddenlayersize,trainfcn);设置最大训练次数:net1.trainparam.epochs=1000;设置训练目标最小误差:net1.trainparam.goal=0.00001;设置学习速率:net1.trainparam.lr=0.1;训练该神经网络:[net,tr]=train(net1,input_train,output_train);输出隐含层的权重矩阵具体数值:lw=net.lw{2,1};输出输入层的权重矩阵具体数值:iw=net.iw{1,1};s14、使用dbscan聚类后再建立的神经网络的输出为:使用dbscan聚类后再建立的神经网络的输出为:fuel
dbscan
‑
nn
代表先使用dbscan聚类后再建立的单隐含层双节点神经网络的输出油耗,no
x,dbscan
‑
nn
代表先使用dbscan聚类后再建立的单隐含层双节点神经网络的输出no
x
,其中lw
k
代表第k簇数据对应的神经网络的隐含层权重矩阵,其中iw
k
代表第k簇数据对应的神经网络的输入层权重矩阵,lw
k
(1,1)为第k簇数据对应神经网络的隐含层矩阵的第一行第一个数,lw
k
(1,2)为第k簇数据对应神经网络的隐含层矩阵的第一行第二个数,lw
k
(2,1)为第k簇数据对应神经网络的隐含层矩阵的第二行第一个数,lw
k
(2,2)为第k簇数据对应神经网络的隐含层矩阵的第二行第二个数,iw
k
(1,1)为第k簇数据对应神经网络的输入层矩阵的第一行第一个数,iw
k
(1,2)为第k簇数据对应神经网络的输入层矩阵的第一行第二个数,iw
k
(2,1)为第k簇数据对应神经网络的输入层矩阵的第二行第一个数,iw
k
(2,2)为第k簇数据对应神经网络的输入层矩阵的第二行第二个数;s15、当新来一组输入测试数据[speed
test acc
test
],其中speed
test
为速度的测试数据,acc
test
为加速度的测试数据;遍历新数据[speed
test acc
test
]与数据集中的每个数据[speed
i acc
i
]的距离,其中1≤i≤n,当i从1到n时,即为计算[speed
test acc
test
]与数据集中每个数据都根据上式计算
距离,然后找出最小的d
test
=min(d
test,i
),1≤i≤n,此时对应的第i个数据点[speed
i acc
i
]属于哪个数据簇c
k
,那么数据点[speed
test acc
test
]就使用数据簇c
k
对应的神经网络获得预测输出。
[0005]
本发明建立了双隐含层四节点的神经网络:使用matlab中工具箱训练神经网络即获得隐含层权重参数lw与输入层权重参数iw的具体数值,具体步骤以及每一步程序语句与语句含义如下:设置每层的训练函数:trainfcn='trainbr';设置双隐含层四节点的结构:hiddenlayersize=[4 4];定义神经网络整体框架:net1=fitnet(hiddenlayersize,trainfcn);设置最大训练次数:net1.trainparam.epochs=1000;设置训练目标最小误差:net1.trainparam.goal=0.00001;设置学习速率:net1.trainparam.lr=0.1;训练该神经网络:[net,tr]=train(net1,input_train,output_train);输出第一个隐含层的权重矩阵具体数值:lw1=net.lw{2,1};输出第二个隐含层的权重矩阵具体数值:lw2=net.lw{3,2};输出输入层的权重矩阵具体数值:iw=net.iw{1,1};其神经网络的输出显示表达式为:其神经网络的输出显示表达式为:
其中lw1代表第一层隐含层的权重矩阵,lw2代表第二层隐含层的权重矩阵,iw代表输入层权重矩阵,lw1(1,1)为神经网络的第一个隐含层矩阵的第一行第一个数,lw1(1,2)为神经网络的第一个隐含层矩阵的第一行第二个数,lw1(1,3)为神经网络的第一个隐含层矩阵的第一行第三个数,lw1(1,4)为神经网络的第一个隐含层矩阵的第一行第四个数,lw1(2,1)为神经网络的第一个隐含层矩阵的第二行第一个数,lw1(2,2)为神经网络的第一个隐含层矩阵的第二行第二个数,lw1(2,3)为神经网络的第一个隐含层矩阵的第二行第三个数,lw1(2,4)为神经网络的第一个隐含层矩阵的第二行第四个数,lw1(3,1)为神经网络的第一个隐含层矩阵的第三行第一个数,lw1(3,2)为神经网络的第一个隐含层矩阵的第三行第二个数,lw1(3,3)为神经网络的第一个隐含层矩阵的第三行第三个数,lw1(3,4)为神经网络的第一个隐含层矩阵的第三行第四个数,lw1(4,1)为神经网络的第一个隐含层矩阵的第四行第一个数,lw1(4,2)为神经网络的第一个隐含层矩阵的第四行第二个数,lw1(4,3)为神经网络的第一个隐含层矩阵的第四行第三个数,lw1(4,4)为神经网络的第一个隐含层矩阵的第四行第四个数,lw2(1,1)为神经网络的第二个隐含层矩阵的第一行第一个数,lw2(1,2)为神经网络的第二个隐含层矩阵的第一行第二个数,lw2(1,3)为神经网络的第二个隐含层矩阵的第一行第三个数,lw2(1,4)为神经网络的第二个隐含层矩阵的第一行第四个数,lw2(2,1)为神经网络的第二个隐含层矩阵的第二行第一个数,lw2(2,2)为神经网络的第二个隐含层矩阵的第二行第二个数,lw2(2,3)为神经网络的第二个隐含层矩阵的第二行第三个数,lw2(2,4)为神经网络的第二个隐含层矩阵的第二行第四个数,lw2(3,1)为神经网络的第二个隐含层矩阵的第三行第一个数,lw2(3,2)为神经网络的第二个隐含层矩阵的第三行第二个数,lw2(3,3)为神经网络的第二个隐含层矩阵的第三行第三个数,lw2(3,4)为神经网络的第二个隐含层矩阵的第三行第四个数,lw2(4,1)为神经网络的第二个隐含层矩阵的第四行第一个数,lw2(4,2)为神经网络的第二个隐含层矩阵的第四行第二个数,lw2(4,3)为神经网络的第二个隐含层矩阵的第四行第三个数,lw2(4,4)为神经网络的第二个隐含层矩阵的第四行第四个数,iw(1,1)为输入层矩阵的第一行第一个数,iw(2,1)为输入层矩阵的第二行第一个数,iw(3,1)为输入层矩阵的第三行第一个数,iw(4,1)为输入层矩阵的第四行第一个数,iw(1,2)为输入层矩阵的第一行第二个数,iw(2,2)为输入层矩阵的第二行第二个数,iw(3,2)为输入层矩阵的第三行第二个数,iw(4,2)为输入层矩阵的第四行第二个数,fuel
nn
代表使用双隐含层四节点的神经网络的输出油耗,no
x,nn
代表使用双隐含层四节点的神经网
络的输出no
x
。
[0006]
本发明由于使用聚类算法将车辆建模时候使用的数据按照车辆不同工况数据内部的关系分成专属于每个工况的数据簇,并使用数据簇去建立对应工况的神经网络模型,因此每个神经网络需要描述的工况以及使用的数据减少(仅使用描述特定工况的数据),因此降低了神经网络结构的复杂度。并且由于提高了针对性(仅针对特定工况),因此不需要为了满足全面性而牺牲精度,神经网络模型的精度也得到了提高。
附图说明
[0007]
图1是dbscan聚类算法概念解释图;图2是单隐含层双节点的神经网络结构示意图;图3是双隐含层四节点的神经网络结构示意图;图4.1是us06测试循环中dbscan
‑
nn方法fuel训练效果图;图4.2是us06测试循环中dbscan
‑
nn方法no
x
训练效果图;图4.3是us06测试循环中双隐含层四节点nn方法fuel训练效果图;图4.4是us06测试循环中双隐含层四节点nn方法no
x
训练效果图;图4.5是us06测试循环中dbscan
‑
nn方法与双隐含层四节点nn方法训练效果误差对比图;图5.1是wltc测试循环中dbscan
‑
nn方法fuel训练效果图;图5.2是wltc测试循环中dbscan
‑
nn方法no
x
训练效果图;图5.3是wltc测试循环中双隐含层四节点nn方法fuel训练效果图;图5.4是wltc测试循环中双隐含层四节点nn方法no
x
训练效果图;图5.5是wltc测试循环中dbscan
‑
nn方法与双隐含层四节点nn方法训练效果误差对比图;图6.1是nedc测试循环中dbscan
‑
nn方法fuel训练效果图;图6.2是nedc测试循环中dbscan
‑
nn方法no
x
训练效果图;图6.3是nedc测试循环中双隐含层四节点nn方法fuel训练效果图;图6.4是nedc测试循环中双隐含层四节点nn方法no
x
训练效果图;图6.5是nedc测试循环中dbscan
‑
nn方法与双隐含层四节点nn方法训练效果误差对比图。
具体实施方式
[0008]
商用车作为道路运输的主体拥有率逐年提高。商用车大多以柴油为燃料,柴油商用车优化控制的主要工作是车辆油耗和排放的综合控制,这就需要建立一个适用范围广、精度高的面向控制的柴油车油耗与排放模型。因此,本发明提出了一种利用dbscan算法聚类与nn结合的建模方法。
[0009]
当车辆在道路上运行时,节省油耗是目前对车辆运行优化的主要目的。随着排放法规越来越严格,在进行车辆油耗优化时,需要额外考虑排放的因素。柴油车辆的排放中,nox气体为主要污染物。因此在对车辆进行优化控制时候,需要综合控制柴油车辆的油耗与nox排放。为了对柴油车的油耗与nox排放进行优化控制,需要建立车辆的油耗与nox排放的
模型。在车辆运行时候,动力系统内部首先会在每个运行周期喷油,燃油在动力系统内部的高温高压作用下蒸发,与内部空气混合,燃烧做功并通过曲轴对外输出扭矩,通过传动系统转化为车辆的驱动力矩,驱动车辆运行获得速度与加速度。而动力系统燃烧做工后,将燃烧废气排出,其中包含了nox气体。nox气体的生成主要为动力系统内部空气中的氮气与氧气,在内部高温高压的环境下氮气与氧气发生化学反应,生成nox气体。
[0010]
通过以上分析可知,车辆的速度与加速度与车辆的油耗以及nox气体排放具有直接关系,而且车辆的速度与加速度在车辆运行过程中容易获得,因此选择建立车辆速度与加速度去表示车辆油耗与nox排放的模型。即模型的输入为[speed acc],模型的输出为[fuel n
x
o](后续在描述概念时为了便于区分,会分别将speed、acc、fuel、no
x
加表明数据序号的下角标),其中speed为车辆速度,acc为车辆加速度,fuel为车辆的油耗,no
x
为车辆的氮氧化物排放。若共采集了n组数据(n根据不同驾驶循环下的训练数据个数而定),那么获得的车辆输入数据集。则为了对数据集进行聚类,需要逐步定义以下概念。
[0011]
为了判断每个数据点周围其他数据的数量,定义eps邻域eps为设置的半径范围参数,一个数据点的eps邻域是指以该数据点为中心,以eps为半径包含的区域。
[0012]
对于车辆输入数据集中的数据点[speed
q acc
q
]来说,[speed
q acc
q
]属于输入数据集,且d
ist
([speed
p acc
p
],[speed
q acc
q
])≤eps
ꢀꢀꢀ
(1)其中,p代表数据点的序号,表明第p个数据。d
ist
([speed
p acc
p
],[speed
q acc
q
])表示两个数据点[speed
p acc
p
]与[speed
q acc
q
]之间的欧式距离,其中q代表数据点的序号,表明第q个数据。若满足上式,则表明数据点[speed
q acc
q
]在数据点[speed
p acc
p
]的eps邻域内。
[0013]
基于公式(1),给出下式:n
eps
([speed
p acc
p
])为车辆输入数据集中在数据点[speed
p acc
p
]的eps邻域内所有数据点的集合。
[0014]
为了判断数据聚类的基础核心,定义核心数据点minpt为设定的邻域密度阈值,若存在数据点[speed
p acc
p
]满足:|n
eps
([speed
p acc
p
])|≥minpts
ꢀꢀꢀꢀ
(3)公式(3)为数据点[speed
p acc
p
]是一个核心数据点的判断条件,其中|n
eps
([speed
p acc
p
])|表示数据点[speed
p acc
p
]的eps邻域内全部数据点个数。
[0015]
为了判断数据集中那些数据具有直接的相连的关系,定义密度直达给定车辆的输入数据集,若存在数据点[speed
q acc
q
]∈|n
eps
([speed
p acc
p
])|且数据点[speed
p acc
p
]满足式(2)(3),即数据点[speed
q acc
q
]在数据点[speed
p acc
p
]的eps邻域内且数据点[speed
p acc
p
]为核心数据点,则称数据点[speed
q acc
q
]是从数据点[speed
p acc
p
]密度直达的。
[0016]
为了判断数据集中那些数据具有直接的间接的关系,定义密度可达给定车辆的输入数据集,若存在数据点链([speed
p acc
p
],[speed
q acc
q
],
…
,[speed
i acc
i
]),对于每个相邻数据点之间都是密度直达,则称数据点[speed
i acc
i
]从数
据点[speed
p acc
p
]是密度可达的。
[0017]
为了将数据及聚类,定义簇给定车辆的输入数据集,若数据集中具有非空子集,且满足以下条件,则称这些非空子集为簇:(1)对任意数据点[speed
q acc
q
],若核心数据点[speed
p acc
p
]在某一特定非空子集内且对象[speed
q acc
q
]是从核心数据点[speed
p acc
p
]密度可达的,则数据点[speed
q acc
q
]也属于该特定非空子集。
[0018]
(2)对任意数据点[speed
p acc
p
]在某一特定非空子集内,[speed
q acc
q
]在该相同的特定非空子集内,数据点[speed
p acc
p
]和数据点[speed
q acc
q
]是密度相连的。
[0019]
为了删除数据集中采样时候获得的不正常数据,定义噪声点给定车辆的输入数据集,若数据点[speed
p acc
p
]不属于任何簇,则数据点[speed
p acc
p
]为噪声点。
[0020]
这些概念由图1所示,其中空心点为噪声点,实心点组成数据簇的点。黑色虚线表示为eps邻域,箭头表示从一个点到另外一个点密度直达。[speed
p acc
p
]、[speed
q acc
q
]、[speed
i acc
i
]为核心数据点。[speed
l acc
l
][speed
j acc
j
]
[0021]
密度直达的关系为:[speed
l acc
l
]由[speed
p acc
p
]密度直达,[speed
q acc
q
]由[speed
p acc
p
]密度直达,[speed
i acc
i
]由[speed
q acc
q
]密度直达,[speed
j acc
j
]由[speed
i acc
i
]密度直达。
[0022]
密度可达的关系为:[speed
i acc
i
]由[speed
p acc
p
]密度可达,[speed
j acc
j
]由[speed
p acc
p
]密度可达,[speed
j acc
j
]由[speed
q acc
q
]密度可达。
[0023]
基于以上基本的定义,给定车辆的输入数据集,将其中密度可达的数据点归为一个数据簇,不与任何点密度可达的点作为噪声点删除,这样通过dbscan算法,基于数据之间的密度,将数据集划分为不同的数据簇:c
k
,(c
k
∈输入数据集,k∈k)
ꢀꢀꢀꢀꢀ
(5)其中,c为数据簇,k为数据簇的序号,k为数据一共聚类的簇数,c
k
表明为第k个数据簇。由于数据簇的分类是基于数据内部特性的,因此只有采用模型的输入为[speed acc],模型的输出为[fuel no
x
]这样的对应输入输出数据,才会有唯一对应数据特性的数据集划分的簇数k,并且每个数据簇k中才会有针对输入数据集内数据特性而划分的特定数据。
[0024]
对于不同数据簇,使用单隐含层双节点结构神经网络建模,采用下式作为隐含层节点的激活函数:其中为第k个数据簇对应神经网络的隐含层节点的第n个输出,为第k个数据簇对应神经网络的隐含层节点的第m个输入。
[0025]
采用线性激活函数:作为输出层的激活函数,其中为第k个数据簇对应神经网络的输出层节点的输
出,为第k个数据簇对应神经网络的输出层节点的第n个输入。单隐含层两个节点的神经网络将结构如图2所示,使用matlab中工具箱训练神经网络即获得第k个数据簇对应神经网络的隐含层权重参数lw
k
与第k个数据簇对应神经网络的输入层权重参数iw
k
的具体数值.
[0026]
具体获得方法如下描述,具体步骤以及每一步程序语句与语句含义如下:设置训练函数:trainfcn='trainbr';设置单隐含层双节点的结构:hiddenlayersize=2;定义神经网络整体框架:net1=fitnet(hiddenlayersize,trainfcn);设置最大训练次数:net1.trainparam.epochs=1000;设置训练目标最小误差:net1.trainparam.goal=0.00001;设置学习速率:net1.trainparam.lr=0.1;训练该神经网络:[net,tr]=train(net1,input_train,output_train);输出隐含层的权重矩阵具体数值:lw=net.lw{2,1};输出输入层的权重矩阵具体数值:iw=net.iw{1,1};
[0027]
那么最后先使用dbscan聚类后再建立的神经网络的输出为:那么最后先使用dbscan聚类后再建立的神经网络的输出为:fuel
dbscan
‑
nn
代表先使用dbscan聚类后再建立的单隐含层双节点神经网络的输出油耗,no
x,dbscan
‑
nn
代表先使用dbscan聚类后再建立的单隐含层双节点神经网络的输出no
x
。其中lw
k
代表第k簇数据对应的神经网络的隐含层权重矩阵,其中iw
k
代表第k簇数据对应的神经网络的输入层权重矩阵,lw
k
(1,1)为第k簇数据对应神经网络的隐含层矩阵的第一行第一个数,lw
k
(1,2)为第k簇数据对应神经网络的隐含层矩阵的第一行第二个数,lw
k
(2,1)为第k簇数据对应神经网络的隐含层矩阵的第二行第一个数,lw
k
(2,2)为第k簇数据对应神经网络的隐含层矩阵的第二行第二个数。iw
k
(1,1)为第k簇数据对应神经网络的输入层矩阵的第一行第一个数,iw
k
(1,2)为第k簇数据对应神经网络的输入层矩阵的第一行第二个数,iw
k
(2,1)为第k簇数据对应神经网络的输入层矩阵的第二行第一个数,iw
k
(2,2)为第k簇数据对应神经网络的输入层矩阵的第二行第二个数。
[0028]
当新来一组输入测试数据[speed
test acc
test
](speed
test
为速度的测试数据,acc
test
为加速度的测试数据)时,需要判断使用哪个神经网络进行对应输出的测试。此时遍历新数据[speed
test acc
test
]与数据集中的每个数据[speed
i acc
i
](1≤i≤n)的距离。当i从1到n时,即为计算[speed
test acc
test
]与数据集中每个数据都根据上式计算距离。然后找出最小的d
test
=min(d
test,i
),1≤i≤n。此时对应的第i个数据点[speed
i acc
i
]属于哪个数据簇c
k
,那么数据点[speed
test acc
test
]就使用数据簇c
k
对应的神经网络获得预测输出。
[0029]
为了对比效果,建立了双隐含层四节点的神经网络,其结构如图3所示,使用matlab中工具箱训练神经网络即获得隐含层权重参数lw与输入层权重参数iw的具体数值,具体步骤以及每一步程序语句与语句含义如下:设置每层的训练函数:trainfcn='trainbr';设置双隐含层四节点的结构:hiddenlayersize=[4 4];定义神经网络整体框架:net1=fitnet(hiddenlayersize,trainfcn);设置最大训练次数:net1.trainparam.epochs=1000;设置训练目标最小误差:net1.trainparam.goal=0.00001;设置学习速率:net1.trainparam.lr=0.1;训练该神经网络:[net,tr]=train(net1,input_train,output_train);输出第一个隐含层的权重矩阵具体数值:lw1=net.lw{2,1};输出第二个隐含层的权重矩阵具体数值:lw2=net.lw{3,2};输出输入层的权重矩阵具体数值:iw=net.iw{1,1};
[0030]
其神经网络的输出显示表达式为:其神经网络的输出显示表达式为:其中lw1代表第一层隐含层的权重矩阵,lw2代表第二层隐含层的权重矩阵,iw代表输入层权重矩阵。lw1(1,1)为神经网络的第一个隐含层矩阵的第一行第一个数,lw1(1,2)为
神经网络的第一个隐含层矩阵的第一行第二个数,lw1(1,3)为神经网络的第一个隐含层矩阵的第一行第三个数,lw1(1,4)为神经网络的第一个隐含层矩阵的第一行第四个数。lw1(2,1)为神经网络的第一个隐含层矩阵的第二行第一个数,lw1(2,2)为神经网络的第一个隐含层矩阵的第二行第二个数,lw1(2,3)为神经网络的第一个隐含层矩阵的第二行第三个数,lw1(2,4)为神经网络的第一个隐含层矩阵的第二行第四个数。lw1(3,1)为神经网络的第一个隐含层矩阵的第三行第一个数,lw1(3,2)为神经网络的第一个隐含层矩阵的第三行第二个数,lw1(3,3)为神经网络的第一个隐含层矩阵的第三行第三个数,lw1(3,4)为神经网络的第一个隐含层矩阵的第三行第四个数。lw1(4,1)为神经网络的第一个隐含层矩阵的第四行第一个数,lw1(4,2)为神经网络的第一个隐含层矩阵的第四行第二个数,lw1(4,3)为神经网络的第一个隐含层矩阵的第四行第三个数,lw1(4,4)为神经网络的第一个隐含层矩阵的第四行第四个数。lw2(1,1)为神经网络的第二个隐含层矩阵的第一行第一个数,lw2(1,2)为神经网络的第二个隐含层矩阵的第一行第二个数,lw2(1,3)为神经网络的第二个隐含层矩阵的第一行第三个数,lw2(1,4)为神经网络的第二个隐含层矩阵的第一行第四个数。lw2(2,1)为神经网络的第二个隐含层矩阵的第二行第一个数,lw2(2,2)为神经网络的第二个隐含层矩阵的第二行第二个数,lw2(2,3)为神经网络的第二个隐含层矩阵的第二行第三个数,lw2(2,4)为神经网络的第二个隐含层矩阵的第二行第四个数。lw2(3,1)为神经网络的第二个隐含层矩阵的第三行第一个数,lw2(3,2)为神经网络的第二个隐含层矩阵的第三行第二个数,lw2(3,3)为神经网络的第二个隐含层矩阵的第三行第三个数,lw2(3,4)为神经网络的第二个隐含层矩阵的第三行第四个数。lw2(4,1)为神经网络的第二个隐含层矩阵的第四行第一个数,lw2(4,2)为神经网络的第二个隐含层矩阵的第四行第二个数,lw2(4,3)为神经网络的第二个隐含层矩阵的第四行第三个数,lw2(4,4)为神经网络的第二个隐含层矩阵的第四行第四个数。iw(1,1)为输入层矩阵的第一行第一个数,iw(2,1)为输入层矩阵的第二行第一个数,iw(3,1)为输入层矩阵的第三行第一个数,iw(4,1)为输入层矩阵的第四行第一个数。iw(1,2)为输入层矩阵的第一行第二个数,iw(2,2)为输入层矩阵的第二行第二个数,iw(3,2)为输入层矩阵的第三行第二个数,iw(4,2)为输入层矩阵的第四行第二个数。fuel
nn
代表使用双隐含层四节点的神经网络的输出油耗,no
x,nn
代表使用双隐含层四节点的神经网络的输出no
x
。
[0031]
us06循环工况中的训练结果dbscan nn(单隐含层双节点)首先dbscan算法将数据划分为两簇,每簇数据对应神经网络结构数据如下第一簇输入层权重:隐含层权重:第二簇输入层权重:隐含层权重:
nn(双隐含层四节点)nn(双隐含层四节点)
[0031]
wltc循环工况中的训练结果dbscan nn(单隐含层双节点)首先dbscan算法将数据划分为两簇,每簇数据对应神经网络结构数据如下第一簇输入层权重:隐含层权重:第二簇输入层权重:隐含层权重:nn(双隐含层四节点)nn(双隐含层四节点)
[0032]
nedc循环工况中的训练结果dbscan nn(单隐含层双节点)首先dbscan算法将数据划分为两簇,每簇数据对应神经网络结构数据如下第一簇输入层权重:隐含层权重:第二簇输入层权重:
隐含层权重:nn(双隐含层四节点)nn(双隐含层四节点)time=1.902834s
[0033]
积极效果分析为了证明本发明的积极效果,选取常用的车辆测试工况:us06工况、wltc工况与nedc工况进行测试,并选用精度评价标准均方差(r2)作为精度评价指标。本专利的积极效果从以下一点进行证明:使用先进行数据聚类然后建立单隐含层双节点的神经网络模型效果与直接建立的双隐含层四节点的神经网络模型效果基本相同,但是单隐含层双节点的神经网络模型会远远简单于双隐含层四节点的神经网络模型。模型的简单化会为后续控制器的设计带来极大的便利,比如降低车辆运行控制时的计算负担,提高控制器的响应速度。
[0034]
首先结合图1与图2可以看出,使用单隐含层双节点的神经网络的结构要远远简单于使用双隐含层四节点的神经网络。并且从公式(8)(9)与(11)(12)对比可以看出,单隐含层双节点神经网络输入到输出的显式计算要远远简单于双隐含层四节点神经网络输入到输出的显式计算。
[0035]
us06工况测试曲线中,油耗的建模效果可以从图4.1与图4.3对比看出,可以看出聚类 单隐含层双节点神经网络建模(r2=0.9584)与双隐含层四节点神经网络建模(r2=0.974),以本专利提出的方法为基本,计算得到r2相差为1.6%,因此可以判定为效果基本一样,nox排放的建模效果可以从图4.2与图4.4对比,可以看出聚类 单隐含层双节点神经网络建模(r2=0.9344)与双隐含层四节点神经网络建模(r2=0.9797),以本专利提出的方法为基本,计算得到r2相差为4.8%,因此可以判定为效果基本一样。结合误差曲线4.5可以看出,本专利提出的方法建模误差与双隐含层四节点神经网络建模建模误差虽然在部分区域会各有增加或者减小,但是整体误差效果基本相同。并结合公式(8)(9)与(11)(12)对比可以看出,单隐含层双节点神经网络输入到输出的显式计算要远远简单于双隐含层四节点神经网络输入到输出的显式计算。且从us06循环工况中的训练结果中可以发现,本专利确实可以通过数据聚类后建立两个简单地神经网络模型获得和一个复杂的神经网络模型基本一样的效果。
[0036]
wltc工况测试曲线中,油耗的建模效果可以从图5.1与图5.3对比看出,可以看出聚类 单隐含层双节点神经网络建模(r2=0.9095)与双隐含层四节点神经网络建模(r2=0.9444)以本专利提出的方法为基本,计算得到r2相差为3.8%,因此可以判定为效果基本一样。nox排放的建模效果可以从图5.2与图5.4对比,可以看出聚类 单隐含层双节点神经网络建模(r2=0.9113)与双隐含层四节点神经网络建模(r2=0.9592),以本专利提出的方法为基本,计算得到r2相差为4.8%,因此可以判定为效果基本一样。
[0037]
结合误差曲线5.5可以看出,本专利提出的方法建模误差与双隐含层四节点神经网络建模建模误差虽然在部分区域会各有增加或者减小,但是整体误差效果基本相同。并结合公式(8)(9)与(11)(12)对比可以看出,单隐含层双节点神经网络输入到输出的显式计算要远远简单于双隐含层四节点神经网络输入到输出的显式计算。且从wltc循环工况中的训练结果中可以发现,本专利确实可以通过数据聚类后建立两个简单地神经网络模型获得和一个复杂的神经网络模型基本一样的效果。
[0038]
nedc工况测试曲线中,油耗的建模效果可以从图6.1与图6.3对比看出,可以看出聚类 单隐含层双节点神经网络建模(r2=0.9361)与双隐含层四节点神经网络建模(r2=0.969),以本专利提出的方法为基本,计算得到r2相差为3.5%,因此可以判定为效果基本一样。nox排放的建模效果可以从图6.2与图6.4对比,可以看出聚类 单隐含层双节点神经网络建模(r2=0.9565)与双隐含层四节点神经网络建模(r2=0.9141),以本专利提出的方法为基本,计算得到r2相差为4.4%,因此可以判定为效果基本一样。。
[0039]
结合误差曲线6.5可以看出,本专利提出的方法建模误差与双隐含层四节点神经网络建模建模误差虽然在部分区域会各有增加或者减小,但是整体误差效果基本相同。并结合公式(8)(9)与(11)(12)对比可以看出,单隐含层双节点神经网络输入到输出的显式计算要远远简单于双隐含层四节点神经网络输入到输出的显式计算。且从nedc循环工况中的训练结果中可以发现,本专利确实可以通过数据聚类后建立两个简单地神经网络模型获得和一个复杂的神经网络模型基本一样的效果。
[0040]
通过不同工况的驾驶测试循环下的曲线与训练结果都可以得出相同结论,证明了本发明的有效性。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。