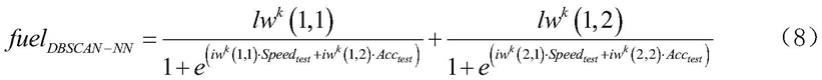技术特征:
1.一种根据不同工况的数据簇建立柴油车辆油耗与排放模型方法,s1、选择建立车辆速度与加速度车辆油耗与nox排放的模型,共采集了n组数据,n根据不同驾驶循环下的训练数据个数而定;其特征在于:s2、将模型的输入为[speed acc],模型的输出为[fuel no
x
],其中speed为车辆速度,acc为车辆加速度,fuel为车辆的油耗,no
x
为车辆的氮氧化物排放;s3、定义eps邻域:车辆输入数据集中的数据点[speed
q acc
q
]属于输入数据集,且d
ist
([speed
p acc
p
],[speed
q acc
q
])≤eps
ꢀꢀꢀꢀꢀꢀꢀꢀ
(1)其中,p代表数据点的序号,表明第p个数据;d
ist
([speed
p acc
p
],[speed
q acc
q
])表示两个数据点[speed
p acc
p
]与[speed
q acc
q
]之间的欧式距离,其中q代表数据点的序号,表明第q个数据,若满足上式,则表明数据点[speed
q acc
q
]在数据点[speed
p acc
p
]的eps邻域内;s4、基于公式(1)得到:n
eps
([speed
p acc
p
])={[speed
q acc
q
]∈输入数据集|d
ist
([speed
p acc
p
],[speed
q acc
q
])≤eps}
ꢀꢀꢀ
(2)n
eps
([speed
p acc
p
])为车辆输入数据集中在数据点[speed
p acc
p
]的eps邻域内所有数据点的集合;s5、定义核心数据点minpt为设定的邻域密度阈值,若存在数据点]speed
p acc
p
]满足:|n
eps
([speed
p acc
p
])|≥minpts
ꢀꢀꢀꢀꢀ
(3)公式(3)为数据点[speed
p acc
p
]是一个核心数据点的判断条件,其中|n
eps
([speed
p acc
p
])|表示数据点[speed
p acc
p
]的eps邻域内全部数据点个数;s6、定义密度直达给定车辆的输入数据集,若存在数据点[speed
q acc
q
]∈|n
eps
([speed
p acc
p
])|且数据点[speed
p acc
p
]满足式(2)(3),即数据点[speed
q acc
q
]在数据点[speed
p acc
p
]的eps邻域内且数据点[speed
p acc
p
]为核心数据点,则称数据点[speed
q acc
q
]是从数据点[speed
p acc
p
]密度直达的;s7、定义密度可达给定车辆的输入数据集,若存在数据点链([speed
p acc
p
],[speed
q acc
q
],
…
,[speed
i acc
i
]),对于每个相邻数据点之间都是密度直达,则称数据点[speed
i acc
i
]从数据点[speed
p acc
p
]是密度可达的;s8、定义簇,给定车辆的输入数据集,若数据集中具有非空子集,且满足以下条件,则称非空子集为簇:(1)对任意数据点[speed
q acc
q
],若核心数据点[speed
p acc
p
]在某一特定非空子集内且对象[speed
q acc
q
]是从核心数据点[speed
p acc
p
]密度可达的,则数据点[speed
q acc
q
]也属于该特定非空子集;(2)对任意数据点[speed
p acc
p
]在某一特定非空子集内,[speed
q acc
q
]在该相同的特定非空子集内,数据点[speed
p acc
p
]和数据点[speed
q acc
q
]是密度相连的;s9、定义噪声点,若数据点[speed
p acc
p
]不属于任何簇,则数据点[speed
p acc
p
]为噪声
点:[speed
p acc
p
]、[speed
q acc
q
]、[speed
i acc
i
]为核心数据点;[speed
l acc
l
][speed
j acc
j
]密度直达的关系为:[speed
l acc
l
]由[speed
p acc
p
]密度直达,[speed
q acc
q
]由[speed
p acc
p
]密度直达,[speed
i acc
i
]由[speed
q acc
q
]密度直达,[speed
j acc
j
]由[speed
i acc
i
]密度直达;密度可达的关系为:[speed
i acc
i
]由[speed
p acc
p
]密度可达,[speed
j acc
j
]由[speed
p acc
p
]密度可达,[speed
j acc
j
]由[speed
q acc
q
]密度可达;其中i、j、l分别指第i个数据、第j个数据和第l个数据;s10、基于数据之间的密度,将数据集划分为不同的数据簇:c
k
,(c
k
∈输入数据集,k∈k)
ꢀꢀꢀ
(5)其中,c为数据簇,k为数据簇的序号,k为数据一共聚类的簇数,c
k
表明为第k个数据簇;s11、对于不同数据簇,使用单隐含层双节点结构神经网络建模,采用下式作为隐含层节点的激活函数:其中为第k个数据簇对应神经网络的隐含层节点的第n个输出,为第k个数据簇对应神经网络的隐含层节点的第m个输入;s12、采用线性激活函数:作为输出层的激活函数,其中为第k个数据簇对应神经网络的输出层节点的输出,为第k个数据簇对应神经网络的输出层节点的第n个输入;s13、使用matlab中工具箱训练神经网络即获得第k个数据簇对应神经网络的隐含层权重参数lw
k
与第k个数据簇对应神经网络的输入层权重参数iw
k
的具体数值,具体获得方法如下描述,具体步骤以及每一步程序语句与语句含义如下:设置训练函数:trainfcn='trainbr';设置单隐含层双节点的结构:hiddenlayersize=2;定义神经网络整体框架:net1=fitnet(hiddenlayersize,trainfcn);设置最大训练次数:net1.trainparam.epochs=1000;设置训练目标最小误差:net1.trainparam.goal=0.00001;设置学习速率:net1.trainparam.lr=0.1;训练该神经网络:[net,tr]=train(net1,input_train,output_train);输出隐含层的权重矩阵具体数值:lw=net.lw{2,1};输出输入层的权重矩阵具体数值:iw=net.iw{1,1};s14、使用dbscan聚类后再建立的神经网络的输出为:
fuel
dbscan
‑
nn
代表先使用dbscan聚类后再建立的单隐含层双节点神经网络的输出油耗,no
x,dbscan
‑
nn
代表先使用dbscan聚类后再建立的单隐含层双节点神经网络的输出no
x
,其中lw
k
代表第k簇数据对应的神经网络的隐含层权重矩阵,其中iw
k
代表第k簇数据对应的神经网络的输入层权重矩阵,lw
k
(1,1)为第k簇数据对应神经网络的隐含层矩阵的第一行第一个数,lw
k
(1,2)为第k簇数据对应神经网络的隐含层矩阵的第一行第二个数,lw
k
(2,1)为第k簇数据对应神经网络的隐含层矩阵的第二行第一个数,lw
k
(2,2)为第k簇数据对应神经网络的隐含层矩阵的第二行第二个数,iw
k
(1,1)为第k簇数据对应神经网络的输入层矩阵的第一行第一个数,iw
k
(1,2)为第k簇数据对应神经网络的输入层矩阵的第一行第二个数,iw
k
(2,1)为第k簇数据对应神经网络的输入层矩阵的第二行第一个数,iw
k
(2,2)为第k簇数据对应神经网络的输入层矩阵的第二行第二个数;s15、当新来一组输入测试数据[speed
test acc
test
],其中speed
test
为速度的测试数据,acc
test
为加速度的测试数据;遍历新数据[speed
test acc
test
]与数据集中的每个数据[speed
i acc
i
]的距离,其中1≤i≤n,当i从1到n时,即为计算[speed
test acc
test
]与数据集中每个数据都根据上式计算距离,然后找出最小的d
test
=min(d
test,i
),1≤i≤n,此时对应的第i个数据点[speed
i acc
i
]属于哪个数据簇c
k
,那么数据点[speed
test acc
test
]就使用数据簇c
k
对应的神经网络获得预测输出。2.根据权利要求书1所述的根据不同工况的数据簇建立柴油车辆油耗与排放模型方法,其特征在于:建立了双隐含层四节点的神经网络:使用matlab中工具箱训练神经网络即获得隐含层权重参数lw与输入层权重参数iw的具体数值,具体步骤以及每一步程序语句与语句含义如下:设置每层的训练函数:trainfcn='trainbr';设置双隐含层四节点的结构:hiddenlayersize=[4 4];定义神经网络整体框架:net1=fitnet(hiddenlayersize,trainfcn);设置最大训练次数:net1.trainparam.epochs=1000;设置训练目标最小误差:net1.trainparam.goal=0.00001;设置学习速率:net1.trainparam.lr=0.1;训练该神经网络:[net,tr]=train(net1,input_train,output_train);输出第一个隐含层的权重矩阵具体数值:lw1=net.lw{2,1};输出第二个隐含层的权重矩阵具体数值:lw2=net.lw{3,2};输出输入层的权重矩阵具体数值:iw=net.iw{1,1};其神经网络的输出显示表达式为:
其中lw1代表第一层隐含层的权重矩阵,lw2代表第二层隐含层的权重矩阵,iw代表输入层权重矩阵,lw1(1,1)为神经网络的第一个隐含层矩阵的第一行第一个数,lw1(1,2)为神经网络的第一个隐含层矩阵的第一行第二个数,lw1(1,3)为神经网络的第一个隐含层矩阵的第一行第三个数,lw1(1,4)为神经网络的第一个隐含层矩阵的第一行第四个数,lw1(2,1)为神经网络的第一个隐含层矩阵的第二行第一个数,lw1(2,2)为神经网络的第一个隐含层矩阵的第二行第二个数,lw1(2,3)为神经网络的第一个隐含层矩阵的第二行第三个数,lw1(2,4)为神经网络的第一个隐含层矩阵的第二行第四个数,lw1(3,1)为神经网络的第一个隐含层矩阵的第三行第一个数,lw1(3,2)为神经网络的第一个隐含层矩阵的第三行第二个数,lw1(3,3)为神经网络的第一个隐含层矩阵的第三行第三个数,lw1(3,4)为神经网络的第一个隐含层矩阵的第三行第四个数,lw1(4,1)为神经网络的第一个隐含层矩阵的第四行第一个数,lw1(4,2)为神经网络的第一个隐含层矩阵的第四行第二个数,lw1(4,3)为神经网络的第一个隐含层矩阵的第四行第三个数,lw1(4,4)为神经网络的第一个隐含层矩阵的第四行第四个数,lw2(1,1)为神经网络的第二个隐含层矩阵的第一行第一个数,lw2(1,2)为神经网络的第二个隐含层矩阵的第一行第二个数,lw2(1,3)为神经网络的第二个隐含层矩阵的第一行第三个数,lw2(1,4)为神经网络的第二个隐含层矩阵的第一行第四个数,lw2(2,1)为神经网络的第二个隐含层矩阵的第二行第一个数,lw2(2,2)为神经网络的第二个隐含层矩阵的第二行第二个数,lw2(2,3)为神经网络的第二个隐含层矩阵的第二行第三个数,lw2(2,4)
为神经网络的第二个隐含层矩阵的第二行第四个数,lw2(3,1)为神经网络的第二个隐含层矩阵的第三行第一个数,lw2(3,2)为神经网络的第二个隐含层矩阵的第三行第二个数,lw2(3,3)为神经网络的第二个隐含层矩阵的第三行第三个数,lw2(3,4)为神经网络的第二个隐含层矩阵的第三行第四个数,lw2(4,1)为神经网络的第二个隐含层矩阵的第四行第一个数,lw2(4,2)为神经网络的第二个隐含层矩阵的第四行第二个数,lw2(4,3)为神经网络的第二个隐含层矩阵的第四行第三个数,lw2(4,4)为神经网络的第二个隐含层矩阵的第四行第四个数,iw(1,1)为输入层矩阵的第一行第一个数,iw(2,1)为输入层矩阵的第二行第一个数,iw(3,1)为输入层矩阵的第三行第一个数,iw(4,1)为输入层矩阵的第四行第一个数,iw(1,2)为输入层矩阵的第一行第二个数,iw(2,2)为输入层矩阵的第二行第二个数,iw(3,2)为输入层矩阵的第三行第二个数,iw(4,2)为输入层矩阵的第四行第二个数,fuel
nn
代表使用双隐含层四节点的神经网络的输出油耗,no
x,nn
代表使用双隐含层四节点的神经网络的输出no
x
。
技术总结
一种根据不同工况的数据簇建立柴油车辆油耗与排放模型方法,属于汽车控制技术领域。本发明的目的是将数据聚类与神经网络结合的建模方法,先使用聚类算法根据车辆不同工况下的数据内部特点,将车辆数据聚类成不同的数据簇,然后使用每个工况对应的数据簇建立专属神经网络模型的根据不同工况的数据簇建立柴油车辆油耗与排放模型方法。本发明的步骤是:确定模型的输入和输出,分别定义Eps邻域、核心数据点、密度直达、密度可达、簇、噪声点,将数据集划分为不同的数据簇,对于不同数据簇,使用单隐含层双节点结构神经网络建模。本发明提高了针对性(仅针对特定工况),因此不需要为了满足全面性而牺牲精度,神经网络模型的精度也得到了提高。了提高。
技术研发人员:刘迪 邓诺 胡云峰 宫洵 孙耀 张辉 郭洪艳 陈虹
受保护的技术使用者:吉林大学
技术研发日:2021.09.16
技术公布日:2021/11/30
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。