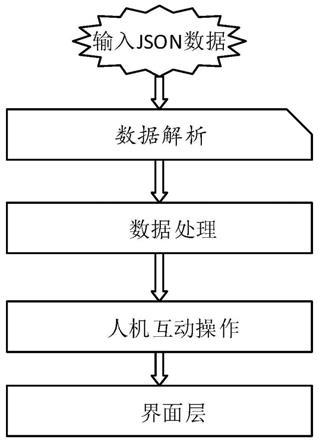
1.本发明涉及网络信息挖掘技术领域,尤其涉及一种复杂网络中有影响力传播者识别方法。
背景技术:
2.复杂网络在现实生活中无处不在,如社交网络、生物分子网络、引文网络、交通运输网络,然而往往只有一部分节点才能对这些网络产生较大影响,若移除这些节点,将会导致这些网络的崩溃。近年来,识别一组有影响力的节点已经引起了复杂网络科学界的广泛关注,对于真实网络应用如信息传播,流行病控制,谣言控制,病毒营销,逮捕犯罪网络的关键嫌疑人、防止电网的灾难性中断和都具有重大意义。
3.大量基于网络的拓扑结构的经典中心性方法用于识别网络中的关键节点,如度中心性(degree centrality)、接近中心性(closeness centrality)、介数中心性(betweenness centrality),特征向量中心性(eigenvector centrality)。度中心性计算节点的直接邻居数量,认为节点的邻居越多,节点也就越重要,但该中心性仅考虑了节点的局部信息。接近中心性计算的是一个节点到其它所有节点的最短距离的倒数,由于考虑了全局信息具有较高的计算复杂度。介数中心性计算经过一个节点的最短路径数量,同样具有较高的计算复杂度。特征向量中心性认为一个节点的邻居节点越重要,则该节点也越重要。kitsak等人认为位于网络核心位置的节点更具有影响力,提出了k
‑
壳分解法,该方法有效地识别了最有影响力的单个节点。k
‑
壳分解法赋予不同传播能力的节点相同的k
‑
壳指标,仅仅考虑了剩余度,而没有考虑连接到已删除节点的连接,是一种粗粒度的中心性方法。基于此,大量的中心性算法被提出用于改进k
‑
shell分解法的性能。利用扩展的h
‑
index,l
ü
等人提出了h
‑
index中心性,一个节点的h
‑
index被定义为,则该节点至少存在个邻居,且每个邻居的度不小于。clusterrank结合了度中心性和聚类系数来判断节点的影响力。近年来,信息熵被提出用于评价网络中节点的重要性。nie等人提出了使用映射熵(mapping entropy,me)来识别网络中的关键节点,考虑了所有节点邻居之间的相关性。结合度、核数和熵,sheikhahmadi等人提出了一个混合方法(mixed core,degree and entropy,mcde)来排序节点。ji等人提出了使用渗流来识别网络中的分散的传播节点。
4.kempe等人证明了影响力最大化问题是一个np
‑
complete问题,提出了贪心爬山算法,但复杂度较高,不适合于大规模网络。基于此,近年来很多研究者又聚焦于启发式算法。chen等人认为当一个节点的邻居被选择为种子节点,则这个节点的度应该被给予一定的折扣,提出了度折扣启发式算法。大量的中心性算法选择的高中心性节点,大都聚集在一起,这可能导致传播影响范围的重叠。基于分散选择节点的思想,曹等人提出了核覆盖算法(core cover algorithm,cca),依此选择最高壳且度最大的节点,并在每一轮覆盖掉邻居节点。由于cca覆盖所有的邻居节点,yang等人提出了邻域核数覆盖和折扣的启发式算法(neighborhood coreness cover and discount heuristic algorithm,nccdh),每轮选择邻域核数最大的节点,且每轮只覆盖同一壳层的邻居节点,其余邻居节点折扣掉相应的k
‑
shell值。基于投票选择策略,zhang等人提出了投票排名算法,赋予每个节点投票分数和投票能力,但该算法只考虑局部信息,且赋予了每个节点相同的投票能力,邻居节点的贡献无法区分。
技术实现要素:
5.本发明旨在至少解决现有技术中存在的技术问题,特别创新地提出了一种复杂网络中有影响力传播者识别方法。
6.为了实现本发明的上述目的,本发明提供了一种复杂网络中有影响力传播者识别方法,包括:
7.s1,将第一判断分数降序排列;第一判断分数包括:h
‑
index;
8.s2,第二判断分数降序排列;第二判断分数包括:voterank;
9.s3,选择第一判断分数最大且第二判断分数最高的节点,并覆盖掉该节点和其邻居节点;若第一判断分数最大且相同的情况下有多个第二判断分数相同的节点,则随机选择一个节点;
10.s4,判断选择的节点数量是否满足所设定值,若是,则执行下一步,若否则执行步骤s3;
11.s5,选择完毕,得到选择的节点集。
12.在本发明的一种优选实施方式中,当第一判断分数为h
‑
index,第二判断分数为voterank时,所述有影响力传播者识别方法包括以下步骤:
13.s1,计算每个节点的h
‑
index值,按h
‑
index值降序排列;
14.s2,根据voterank算法计算每个节点的投票分数,按投票分数降序排列;
15.s3,选择h
‑
index值最大且voterank值最大的节点,并覆盖掉该节点和其邻居节点;若最大且相同的h
‑
index值中有多个voterank值相同的节点,则随机选择一个节点;
16.s4,判断选择的节点数量是否等于所设定的数量,若是,执行下一步骤;若否则跳转执行s3;
17.s5,选择完毕,得到选择的节点集。
18.在本发明的一种优选实施方式中,所述voterank包括:
19.每个节点可以从邻居中获得投票,每个节点v∈v会被赋予一个元组(s
v
,va
v
),s
v
表示节点v从邻居节点获得的投票分数,va
v
表示节点v对邻居节点的投票能力,s
v
可被表示为
[0020][0021]
其中n(v)表示节点v的直接邻居集合,va
i
表示节点i对邻居节点的投票能力。
[0022]
在本发明的一种优选实施方式中,所述h
‑
index包括:
[0023]
节点i的h
‑
index定义为:
[0024][0025]
其中h(
·
)为求节点h
‑
index的函数表示,节点i的邻居节点的度为
[0026]
在本发明的一种优选实施方式中,所述领域h
‑
index包括:
[0027]
节点i的邻域h
‑
index指数定义为:
[0028][0029]
其中n(i)表示节点i的直接邻居集合,即包含的所有邻居节点,h
j
表示节点j的h
‑
index。
[0030]
在本发明的一种优选实施方式中,还包括对性能指标进行展示,其性能指标包括sir和/或平均最短路径l
s
,所述sir包括:
[0031]
首先,设置初始选择的种子节点为感染状态,网络中其他所有的节点为易感状态,在每一时间步,每个感染节点会以β的概率去感染它直接邻居中的易感节点;
[0032]
同时每个感染节点会以γ的概率变为恢复状态,变为恢复状态的节点不会再被感染;其微分方程为
[0033][0034]
感染概率β不能太小也不能太大,如果β过小,则传染病不能成功地感染到整个网络,甚至不能传播;如果β太大,则传染病几乎可以感染整个网络,不同节点之间的影响力就无法区分,对比较无意义。所以β的选取因高于传播阈值β
min
。所述感染率定义为其中s表示易感,i表示感染,r表示恢复。
[0035]
在本发明的一种优选实施方式中,所述sir还包括:
[0036]
感染规模f(t):
[0037][0038]
感染规模f(t
c
):
[0039][0040]
其中,n
i(t)
和n
r(t)
分别表示在t时刻感染节点的数量和恢复节点的数量,n表示网络中节点总数。
[0041]
更大的f(t)表明在t时刻感染的节点更多,影响力更大,则算法性能更好,更短的t表明传播速度更快。
[0042]
在感染过程中,从感染状态变为恢复状态的节点数量在每个时间步逐渐增多,最终达到峰值即稳定状态。
[0043]
在本发明的一种优选实施方式中,所述平均最短路径l
s
包括:
[0044]
选择的节点集s之间平均最短路径长度定义为:
[0045][0046]
其中|s|表示有限集合的基数,即集合s的长度,l
u,v
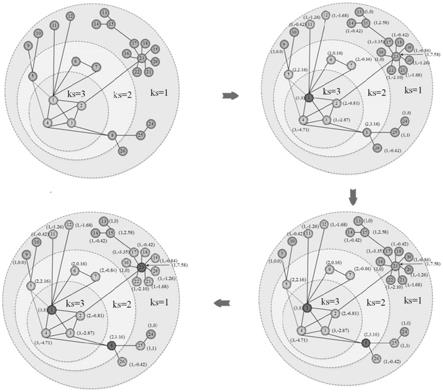
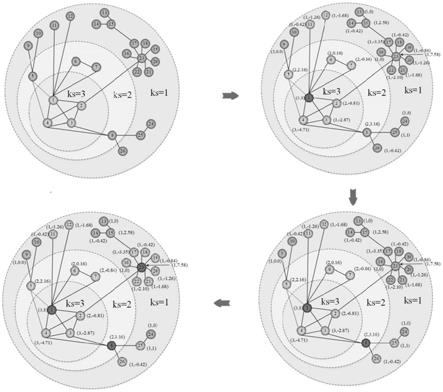
表示节点u到节点v的最短路径长度,一个更大的l
s
表示选择的种子节点更分散,可以使得传播影响最大化。
[0047]
在本发明的一种优选实施方式中,当第一判断分数为k
‑
shell,第二判断分数为voterank时,所述有影响力传播者识别方法包括以下步骤:
[0048]
s1,根据k
‑
shell分解法计算每个节点的k
‑
shell值,按k
‑
shell降序排列;
[0049]
s2,根据voterank算法计算每个节点的投票分数,按投票分数降序排列;
[0050]
s3,选择k
‑
shell值最大且voterank值最高的节点,并覆盖掉该节点和其邻居节点;若最大且相同的k
‑
shell值中有多个voterank值相同的节点,则随机选择一个节点;
[0051]
s4,判断选择的节点数量是否等于所设定的数量,若是,执行下一步骤;若否则跳转执行s3;
[0052]
s5,选择完毕,得到选择的节点集。
[0053]
在本发明的一种优选实施方式中,当第一判断分数为k
‑
shell,第二判断分数为h
‑
index时,所述有影响力传播者识别方法包括以下步骤:
[0054]
s1,根据k
‑
shell分解法计算每个节点的k
‑
shell值,按k
‑
shell降序排列;
[0055]
s2,计算每个节点的h
‑
index值,按h
‑
index值降序排列;
[0056]
s3,选择k
‑
shell值最大且h
‑
index值最高的节点,并覆盖掉该节点和其邻居节点;若最大且相同的k
‑
shell值中有多个h
‑
index值相同的节点,则随机选择一个节点;
[0057]
s4,判断选择的节点数量是否等于所设定的数量,若是,执行下一步骤;若否则跳转执行s3;
[0058]
s5,选择完毕,得到选择的节点集。
[0059]
在本发明的一种优选实施方式中,当第一判断分数为k
‑
shell,第二判断分数为nh
‑
index时,所述有影响力传播者识别方法包括以下步骤:
[0060]
s1,根据k
‑
shell分解法计算每个节点的k
‑
shell值,按k
‑
shell降序排列;
[0061]
s2,计算每个节点的邻域h
‑
index,按h
‑
index值降序排列;
[0062]
s3,选择k
‑
shell值最大且邻域h
‑
index最高的节点,并覆盖掉该节点和其邻居节点;若最大且相同的k
‑
shell值中有多个邻域h
‑
index值相同的节点,则随机选择一个节点;
[0063]
s4,判断选择的节点数量是否等于所设定的数量,若是,执行下一步骤;若否则跳转执行s3;
[0064]
s5,选择完毕,得到选择的节点集。
[0065]
在本发明的一种优选实施方式中,所述k
‑
shell值的节点区分公式包括:
[0066][0067]
其中,k
s
表示距离网络相同的k
‑
shell值,表示网络最大的k
‑
shell值,d
ij
表示节点i到节点j的最短距离,j表示网络核心节点集合,即k
‑
shell值最高的节点;表示具有相同k
‑
shell值的节点集合。
[0068]
综上所述,由于采用了上述技术方案,本发明的有益效果是:
[0069]
1)结合k
‑
shell分解的全局位置信息和voterank方法的局部投票信息,认为位于网络核心位置且最受欢迎的节点最重要,提出了新的kvoterank方法去识别复杂网络中一组最有影响力的节点。
[0070]
2)针对h
‑
index只考虑网络局部信息并且h
‑
index与k
‑
shell都过于粗粒度的问题,受cca方法的启发,以k
‑
shell作为第一判断分数,h
‑
index作为第二判断分数,提出了一种覆盖邻域具有最大h
‑
index节点的khindex方法;利用二阶邻域h
‑
index,进一步提出了扩展方法knhindex去选择复杂网络中一组最有影响力的传播者,新的扩展的knhindex方法进一步考虑了网络局部信息。
[0071]
3)利用h
‑
index作为度和核数的中间态的特点,用h
‑
index近似替代k
‑
shell,将h
‑
index作为第一判断分数,voterank作为第二判断分数,提出了一种新的复杂网络关键节点识别hvoterank方法。
[0072]
4)基于以上对k
‑
shell、h
‑
index和voterank方法的混合邻域覆盖方法kvoterank、khindex、knhindex和hvoterank的测试,提出了改进的k
‑
shell的邻域覆盖的knc方法去识别复杂网络中的一组最有影响力的传播者;同时考虑了网络中的局部和全局信息,解决了k
‑
shell分解法不能区分同一壳层节点及h
‑
index、voterank只考虑局部邻居信息的问题。
[0073]
5)用sir模型和平均最短路径长度对提出的knc方法进行了全面的评估,在jazz等8个真实网络上的进行了仿真实验,证明了所提出的knc方法选择出的初始节点集在不同感染率和不同的初始节点比例下感染规模都优于已有的基线方法,并且选择的初始节点集更分散。
[0074]
本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
[0075]
本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
[0076]
图1是本发明kvoterank算法具体实施例的示意图。
[0077]
图2是本发明sir传播过程示意图。
[0078]
图3是本发明不同初始节点比例的感染规模示意图。
[0079]
图4是本发明感染规模比较示意图。
[0080]
图5是本发明不同感染率的感染规模示意图。
[0081]
图6是本发明初始节点集最短路径长度示意图。
具体实施方式
[0082]
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本发明,而不能理解为对本发明的限制。
[0083]
1.相关工作
[0084]
给定一个网络g(v,e),v和e分别表示节点集和边集,n=|v|表示网络中节点的数量,m=|e|,表示网络中边的数量,其中|
·
|表示集合的基数,用a={a
ij
}表示图g的邻接矩
阵,当a
ij
=1表示节点v
i
和节点v
j
之间有边,反之,a
ij
=0示节点v
i
和节点v
j
之间没有边。n(v)表示节点v的直接邻居数集合。
[0085]
1.1k
‑
shell中心性
[0086]
k
‑
shell方法认为节点的位置比节点的邻居更重要,一个节点位于网络核心位置即使度较小也具有较高的传播影响力。该算法首先移除度为1的节点,移除过程中导致度值减小,继续移除度值等于1的节点,直到网络中没有度为1的节点,所有这些移除的节点被分配为1
‑
壳;接着移除剩余度为2的节点,并迭代移除剩余度值小于等于2的节点,直到所有节点的剩余度都大于2,所有这些移除的节点被分配2壳,重复此过程,直到网络中所有节点都分配了相应的壳。然而,k
‑
shell方法分配大量节点相同的k
‑
shell值,而这些节点有不同的传播能力,是一种粗粒度的方法,同时随着壳层增加,节点聚集程度越高,节点的传播影响范围可能会产生重叠。
[0087]
1.2混合度分解(mixed degree decomposition,mdd)
[0088]
k
‑
shell分解每次仅考虑剩余节点的连接,而完全忽略连接到已删除节点的边,zeng等人提出了混合度分解法(mixed degree decomposition,mdd),同时考虑了节点的剩余度和耗尽度,每个节点的混合度中心性表示为
[0089]
k
m
(v)=k
r
λ*k
e
ꢀꢀꢀ
(1)
[0090]
其中k
r
表示节点的剩余度,即连接到剩余节点的边,k
e
表示节点的耗尽度,即连接到已删除节点的边,λ为取值在0到1之间的可调参数。当λ=1时,则完全考虑了节点的耗尽度,在这种情况下,mdd方法等同于度中心性,当λ=0时,则mdd方法仅考虑剩余度,者中情况下,mdd方法也就等同于k
‑
shell分解法。
[0091]
1.3邻域核数中心性(neighborhood coreness centrality)
[0092]
邻域核数(neighborhood coreness,nc)被bae等人提出,该方法认为一个传播者有更多位于网络核心的邻居时,影响力更大。该方法改善了k
‑
shell方法的简并性,平衡了度和节点的位置关系。定义节点v的邻域核数为
[0093][0094]
其中n(v)表示节点v的直接邻居集合,ks(w)表示邻居节点w的k
‑
shell指标。bae等人还提出了扩展的邻域核数(extend neighborhood coreness,nc ),考虑了节点的二阶邻居,节点v的扩展的邻域核数定义为
[0095][0096]
其中c
nc
(w)表示邻居节点w的邻域核数。
[0097]
1.4改进的k
‑
shell指标
[0098]
考虑目标节点与网络核心位置的距离,liu等人提出了改进的k
‑
shell方法,用于区分同一壳层的节点。该方法认为相同k
‑
shell值的节点距离网络核心位置越近,传播影响越大。相同k
‑
shell值的节点区分公式如下
[0099]
[0100]
其中,k
s
表示距离网络相同的k
‑
shell值,表示网络最大的k
‑
shell值,d
ij
表示节点i到节点j的最短距离,j表示网络核心节点集合,即k
‑
shell值最高的节点。表示具有相同k
‑
shell值的节点集合。
[0101]
1.5h
‑
index
[0102]
迭代的k
‑
壳分解过程需要网络全局的拓扑结构信息,这限制了其应用在大规模网络中,而h
‑
index是考虑了网络部分信息(即邻居的度)的局部度量,h
‑
index最早用于评估研究人员的学术产出数量与学术产出水平。某人的h指数是指在其发表的n篇论文中,有h篇论文分别被引用了至少h次,其余n
‑
h篇的引用次数不超过h次。在网络科学中,定义节点v
i
的h
‑
index为h满足至少h个邻居节点,每个邻居节点的度不小于h。
[0103]
1.6 voterank
[0104]
zhang等人引入voterank方法来识别网络中的一组分散的传播者。在现实生活中,如果a已经支持b,那么a对其他人的支持力就会减弱。voterank根据邻居节点的投票分数一个一个地选择节点,并且当某个节点已被选为最有影响力的节点,则它的邻居节点投票能力会减弱,并且该选择节点不会参与下一轮的投票。voterank方法赋予每个节点一个元组(s
v
,va
v
),其中s
v
表示节点v从邻居节点获得的投票分数,va
v
表示节点v的投票能力。voterank可以由四部分组成:
[0105]
步骤1:初始化。用(0,1)初始化所有的元组,即每个节点的投票分数为0,每个节点的投票能力为1。
[0106]
步骤2:投票。根据邻居节点投票能力的总和,每个节点获得一个投票分数。选择投票分数最高的并且未被选择的节点作为最有影响力的节点。为避免节点被再次选择,节点的投票分数将被置为0。为确保该节点不会参与下次的投票中,该节点的投票能力也置0。
[0107]
步骤3:更新。为了获得更加分散的种子节点集,在步骤2中选择种子节点v后,在下一轮,需要对v的邻居节点的投票能力进行折扣,若u为节点v的邻居节点,则va
u
=va
u
‑
f,(va
u
>0)或者va
u
=0,(va
u
≤0)),其中<k>是网络中节点的平均度,va
u
表示节点u的投票能力。
[0108]
步骤4:重复步骤2和3,直到选择的节点个数满足所设定的数量要求。
[0109]
voterank中心性相比于度中心性、h指数、k
‑
shell等具有较高准确性,但voterank没有考虑网络中节点的位置分布,现实中,即使投票分数较低,位于网络中心的节点也可以产生更大的影响力。
[0110]
2.提出的方法(proposed method)
[0111]
voterank中心性基于投票机制选择一组有影响力的传播者,每个节点可以从邻居中获得投票,每个节点v∈v会被赋予一个元组(s
v
,va
v
),s
v
表示节点v从邻居节点获得的投票分数,va
v
表示节点v对邻居节点的投票能力。s
v
可被表示为
[0112][0113]
其中n(v)表示节点v的直接邻居集合,va
i
表示节点i对邻居节点的投票能力。
[0114]
h
‑
index即h指数被定义为h,则该节点至少存在h个邻居,且每个邻居的度不小于
h。对于网络g(v,e),定义节点i的度为k
i
,其邻居节点的度为其中,表示节点i的第1个邻居节点j1的度,表示节点i的第2个邻居节点j1的度,表示节点i的第k
i
个邻居节点的度。
[0115]
则节点i的h
‑
index定义为
[0116][0117]
其中h(
·
)为求节点h
‑
index的函数表示。
[0118]
受邻域核数中心性nc的启发,这里给出扩展的邻域h指数,考虑了二阶邻域h
‑
index,节点i的邻域h
‑
index指数定义为
[0119][0120]
其中n(i)表示节点i的直接邻居集合,即包含的所有邻居节点,h
j
表示节点j的h
‑
index。
[0121]
knc方法基于两个判断分数,第一判断分数为主要判断条件,第二判断分数为次要判断体条件,每次选择满足第一判断分数最高并且第二判断分数最高的未被覆盖的节点作为种子节点,每轮选择节点后,覆盖其直接邻居节点以分散地选择节点,使其传播影响最大化。本发明专利对knc方法的子方法kvoterank方法进行了主要阐述。
[0122]
voterank中心性没有考虑节点局部信息,没有考虑邻居节点的不同,同时也没有考虑节点的位置信息。受核覆盖算法(core cover algorithm,cca)的启发,提出的kvoterank算法认为位于网络核心位置且最受欢迎(即voterank值最高)的节点具有更大的传播影响力。位于网络核心的节点,即使voterank值较小,也具有较大的影响力。这里给出了kvoterank算法过程。kvoterank算法执行过程分为4个阶段:
[0123]
阶段1:根据k
‑
shell分解法计算每个节点的k
‑
shell值,按k
‑
shell降序排列。
[0124]
阶段2:对于相同的k
‑
shell值根据voterank算法计算每个节点的投票分数,按投票分数降序排列。
[0125]
阶段3:选择voterank值最高的节点,并覆盖掉该节点和其邻居节点。若同一壳中有多个voterank值相同的节点,则随机选择一个节点。
[0126]
阶段4:重复步骤3,直到选择的节点数量满足所设定的数量需求。
[0127]
该算法可以解决k
‑
shell分解法不能区分同一壳节点影响力大小的问题,根据节点的投票分数来区分同一壳层的节点。为了避免影响范围的重叠,在提出的算法的第3阶段分散地选择种子节点,即在每一次选择种子节点后,覆盖掉该节点及其直接邻居。kvoterank算法描述如算法1所示。
[0128]
表1kvoterank算法
[0129][0130]
kvoterank算法的2~4行表示阶段1,进行节点k
‑
shell值的计算,5~8行表示阶段2,进行每个节点voterank分数的计算,9~17行表示阶段3和阶段4,选择最高壳层且投票分数最高的分散的种子节点,即在选择种子节点时,所在的k
‑
shell值为主要判断条件,投票分数为次要判断条件,并且为使得传播范围不重叠,覆盖已选择节点的邻居节点来分散地选择最有影响力的节点。
[0131]
考虑到h
‑
index与voterank同样考虑了邻居节点的信息,都是考虑局部信息的中心性,且h
‑
index指数越大,其社会影响力也越大,结合h
‑
index及k
‑
shell方法,认为位于网络核心位置且h指数最高(影响力大)的节点最有影响力,提出了基于k
‑
shell分解的h
‑
index(khindex)方法,其第一判断分数为k
‑
shell,第二判断分数为h
‑
index。进一步考虑节点的局部信息,以邻域h
‑
index表示半局部信息,相当于考虑节点的4阶邻域,提出基于k
‑
壳分解的邻域h
‑
index的扩展knhindex算法,knhindex方法的第一判断分数为k
‑
shell,第二判断分数为邻域h
‑
index。对于khindex(和knhindex)算法,在阶段2是计算每个节点的h
‑
index(和邻域h
‑
index),阶段3是每轮选择k
‑
shell值最大且h
‑
index(邻域h
‑
index)最高的节点。l
ü
等人指出h
‑
index与度和核数的关系,度为初始状态,h
‑
index为中间状态,核数为稳定状态。因此,knc方法认为将h
‑
index近似替代k
‑
shell,即将h
‑
index作为第一判断分数,voterank分数作为第二判断分数也能选择出高影响力的节点,于是提出了基于h
‑
index的voterank方法命名为hvoterank。由于h
‑
index指数也是一种粗粒度的方法,将h
‑
index作为第一判断分数,voterank作为第二判断分数,每次选择h
‑
index最大且投票分数最高的节点,每轮选择节点后,同样覆盖直接邻居节点以分散地选择节点,算法过程与kvoterank算法类似。表2给出了knc方法的kvoterank、khindex、knhindex和hvoterank 4个子方法的判断分数。
[0132]
表2 knc方法判断分数
[0133]
judgement conditionkvoterankkhindexknhindexhvoterankmain scorek
‑
shellk
‑
shellk
‑
shellh
‑
indexsecond scorevoterankh
‑
indexnh
‑
indexvoterank
[0134]
为了直观地解释所提出的算法,给出kvoterank算法过程图(见图1),简单地可视化了提出的kvoterank算法选择3个最有影响力的种子节点的过程,khindex、hnhindex、hvoterank与kvoterank类似,这里不再给出。
[0135]
根据图1kvoterank算法过程图,首先,计算网络中每个节点的k
‑
shell值,不同的颜色表示节点在不同的壳层。节点集{1,2,3,4}在3
‑
shell,{5,6,7,8}在2
‑
shell,其余节点在3
‑
shell;接着,计算每个节点的投票分数,在图中已标出了每个节点的k
‑
shell值以及voterank分数,表3中给出了所有节点的所在的k
‑
shell值、voterank分数、h
‑
index以及邻域h
‑
index。
[0136]
表3 网络中节点的voterank分数和h
‑
index
[0137][0138]
如kvoterank算法过程图1所示,根据kvoterank算法,首先选择在3
‑
shell以及投票分数最高(为8)的节点1,接着覆盖节点1的直接邻居节点集{2,3,4,5,6,7},这样,第一轮选择结束。接着选择在2
‑
shell的投票分数为3.16的节点8,并覆盖节点8的未覆盖的直接邻居节点{25,26},第二轮选择结束。接着选择在1
‑
shell的投票分数为7.58的节点23,并覆盖其邻居节点{16,17,18,19,20,21,22}。这样3个种子节点(种子节点即选出来的最有影响力的传播者)的选择过程结束,选择的种子节点集为{1,8,23}。对于khindex算法,根据分数表表3,首先选择节点4,随后覆盖其邻居节点{1,2,3,5,8},接着选择随机选择节点6,7中的一个,假设随机选择节点6,覆盖邻居节点7;最后选择节点{15,17,23,25},假设选择节点15,随后覆盖邻居节点{13,14,17},3个种子种子节点选择完成,khindex算法选择出的3个最有影响力的节点为{4,6,15}。对于knhindex和hvoterank算法过程与kvoterank算法类似,区别只在于第一和第二判断分数。
[0139]
这里对k
‑
shell与kvoterank在cenew网络(453个节点)中选择15个节点进行了传播过程的简单测试,结果如sir传播过程图图2所示,其中蓝节点表示易感节点,红色表示感
染节点,绿色表示免疫节点。
[0140]
在图2sir传播过程图中用sir传播模型简单地比较了k
‑
shell分解法与所提出的kvoterank算法,可以看出k
‑
shell算法选择出的初始节点有些彼此聚集在一起,而kvoterank算法选择出的初始节点彼此分散,并且在时间步为10时,kvoterank算法比k
‑
shell方法多感染11个节点。
[0141]
3.数据集
[0142]
为了证明所提出的knc方法的性能的优越性,本实验使用了8个不同类型和大小的真实网络数据集。大部分的数据集来自一个社交图的数据库snap,由斯坦福大学的学院和学生汇编。其中,1)jazz:该数据集录制了1912年至1940年间演出的爵士乐队;2)cenew:cenew数据集是秀丽隐杆线虫代谢网络的边列表。3)crimes:该数据集是一个犯罪网络,节点表示一个人,边表示两个犯罪分子共同参与一个犯罪;4)email:记录了罗维拉大学用户之间邮件交换的关系;5)hamster:定义了“www.hamsterster.com”网站用户之间的友谊和家庭联系;6)ca
‑
grqc:该数据集是一个来自电子打印arxiv的合作网络,涵盖了提交给广义相对论和量子宇宙学类别的论文的作者之间的科学合作。7)condmat:是一个基于1995年至1999年存档的电子版arxiv的浓缩物质部分的合作作者网络。8)enrons:安然电子邮件互动在安然社区,包括关于超过一百万封电子邮件的信息。jazz等8个真实网络的具体拓扑结构信息描述如表4所示。
[0143]
表4 网络拓扑结构
[0144]
networknm<k>k
max
<d><c>β
min
jazz198274227.6971002.2350.61750.0266cenew45320258.942372.6640.6460.0256crimes82914733.554255.040.0080.1960email113354519.622713.6060.25400.0565hamster24261663113.7112733.670.5380.0241ca
‑
grqc4158134226.456816.0490.6650.0589condmat23133934978.0832815.3520.6330.0475enron3369618081110.73213834.0250.7080.0071
[0145]
在表4网络拓扑结构表中,n表示网络中节点的总数,m表示网络中边的数量;表示网络中节点的平均度,k
max
表示网络中节点的最大度,<d>表示网络平均最短路径长度,表示网络的平均聚类系数,i
i
表示节点i的直接邻居之间边的数目;β
min
为传播阈值,这里可由计算得到。其中n(i)表示节点i的直接邻居集合,|n(i)|表示集合n(i)的基数,k表示网络中节点的度,<
·
>为求平均的操作。
[0146]
4.性能指标
[0147]
4.1sir流行病模型
[0148]
易感感染恢复(susceptible
‑
infected
‑
recovered,sir)的传染病模型被用来评估所提出方法的性能。在sir模型中,节点有三种状态,易感(s)、感染(i)和恢复(r)。其中易感状态表示该类节点对疾病和信息是易感的,感染状态表示该类节点已被疾病感染或已被信息激活,恢复状态表示节点已经恢复,并且不会再传递信息或疾病。首先,设置初始选择的种子节点为感染状态,网络中其他所有的节点为易感状态,在每一时间步,每个感染节点会以β的概率去感染它直接邻居中的易感节点。同时每个感染节点会以γ的概率变为恢复状态(γ表示恢复概率),变为恢复状态的节点不会再被感染。其微分方程为
[0149][0150]
感染概率β不能太小也不能太大,如果β过小,则传染病不能成功地感染到整个网络,甚至不能传播;如果β太大,则传染病几乎可以感染整个网络,不同节点之间的影响力就无法区分,对比较无意义。所以β的选取因高于传播阈值β
min
,每个网络的传播阈值已在表4的第8列给出。在本实验中,感染率定义为由于模型中存在随机性,实验结果应通过模拟多次求平均值。
[0151]
其中感染概率β是指在一个时间步,感染节点可以感染邻居中易感节点的概率,λ是指感染率,也就是感染概率与恢复率之比,可以理解为sir模型的感染能力,在有恢复条件下的感染概率。
[0152]
算法性能可以通过测量节点的传播能力来衡量,其传播能力可以通过在时间t的感染规模f(t)和最终感染规模f(t
c
)来表示。感染规模表示了在时刻t选择节点的影响力,定义为
[0153][0154]
其中,n
i(t)
和n
r(t)
分别表示在t时刻感染节点的数量和恢复节点的数量,n表示网络中节点总数,更大的f(t)表明在t时刻感染的节点更多,影响力更大,则算法性能更好,更短的t表明传播速度更快。
[0155]
在感染过程中,从感染状态变为恢复状态的节点数量在每个时间步逐渐增多,最终达到峰值即稳定状态。最终的感染规模f(t
c
),即恢复节点总数所占的比例表明了初始选择的种子节点的最终的影响力,定义为
[0156][0157]
因此,f(t)评估了节点在t时刻的传播影响力,f(t
c
)评估了节点在sir传播过程达到稳定状态时的传播影响力。
[0158]
4.2平均最短路径l
s
[0159]
对于选择的种子节点,若像度中心性或k
‑
shell中心性那样,种子节点彼此聚集在一起,则会使传播影响范围的重叠,所以选择分散的种子节点更容易使传播影响范围扩大。通过测量选择的种子节点之间的平均最短路径l
s
来衡量所选择节点的分散程度,进而比较出不同算法的性能。选择的种子节点集s之间平均最短路径长度定义为
[0160][0161]
其中|s|表示有限集合的基数,即集合s的长度,l
u,v
表示节点u到节点v的最短路径长度,一个更大的l
s
表示选择的种子节点更分散,可以使得传播影响最大化。
[0162]
5.实验结果与分析
[0163]
为了测试所提出的knc方法的kvoterank、khindex、knhindex和hvoterank4种子算法的有效性,根据第5节所提出的性能指标,用sir模型以及平均路径长度在jazz等8个真实网络进行了仿真分析,进一步将kvoterank、khindex、knhindex和hvoterank与degree、k
‑
sehll、nc、nc 、pagerank、h
‑
index以及voterank这7个基线的中心性算法做对比,同时比较提出的4个算法性能。
[0164]
5.1sir模型仿真分析
[0165]
根据不同的初始种子节点规模的情况下的最终感染规模来判断不同算法的性能,鉴于网络不同的规模,在选择初始传播种子节点时采取不同的比例,对于规模较小的网络给予较大的初始比例。对于网络jazz、cenew、crimes、email、hamster、ca
‑
grqc,其初始种子节点比例最大设置为0.03,对于规模较大的网络condmat和enron,初始种子节点比例最大设置为0.003。感染概率β设置为1.5β
min
,每种算法在不同的初始种子节点比例下的最终感染规模f(t
c
)如图3不同初始节点比例图所示。x轴表示不同初始种子节点比例p,y轴表示每种比例下的最终感染规模,不同初始节点比例图图3(a)中的子图单独给出了所提出的kvoterank、khindex、knhindex和hvoterank 4种方法不同初始节点比例的感染规模。实验结果通过300次实验的平均值获得。
[0166]
从不同初始节点比例感染规模图3中可以看出,所提出的4种方法kvoterank、khindex、knhindex和hvoterank在8个网络上都取得了令人满意的效果,证明了提出的方法的优越性。在初始p较小时,提出的4种knc方法与其他基准方法相当,但随着p的增大,所得的4种knc方法最终的感染规模逐渐优于其他基准算法。在所有的8个网络的网络中,所提出的4种方法都表现最好,特别是在网络cenew、hamster和大规模网络enron上,在小规模网络jazz中,knhindex表现稍差,在cenew网络中hvoterank方法表现稍差。例如,在cenew网络中,khindex方法只用了0.02的初始节点比例就感染了超过12%的节点,而基准方法在初始节点比例为0.03时也没有达到此规模。在hamster网络中,提出的kvoterank方法相比与基准方法多感染了约3.5%的节点。而在所有网络中,提出的kvoterank、khindex、knhindex以及hvoterank算法之间性能不相上下,但都优于基准的7种中心性,证明了所提出方法的有效性。
[0167]
为了验证不同算法所选种子节点的传播规模和传播速度,时间步长实验被用来验证不同算法的性能,为保持实验的一致性,设置固定数量初始种子节点比例。对于规模较小
的网络jazz、cenew、crimes、email、hamster、ca
‑
grqc,其初始种子节点比例为0.03,对于规模较大的网络condmat和enron网络,其初始种子节点比例为0.003。实验结果通过1000次实验的平均来获得。f(t)随时间变化的结果如图4感染规模比较图所示,轴表示时间步长,轴表示在时间下的感染规模。
[0168]
从图4初始节点集的感染规模比较图中可以看出,所提出的kvoterank、khindex、knhindex和hvoterank 4个算法相比于degree、k
‑
shell等七个基线算法,总是能达到最高峰,即感染规模最大,并且总是能最快达到稳定状态,即传染速度最快。在jazz、cenew、hamster、ca
‑
grqc、condma和enront网络中,hvoterank表现最好,尤其是在cenew、hamster和enron网络。对于cenew网络,hvoterank相比于最差的k
‑
shell方法高出了约3.5%,相比于最好的h
‑
index高出了2.5%,对于hamster网络,hvoterank相比于最好的voterank方法高出了约3.8%,对于大规模网络enron,hvoterank高出基准方法约0.625%,khindex和knhindex与hvoterank表现相当,kvoterank表现稍差。在crimes网络中kvoterank表现最好,hvoterank在提出的4个方法中表现稍差,但明显优于其他基准方法。在email网络中,所提出的4种knc方法性能基本持平,高于基准方法约2.2%。所有网络中,k
‑
shell方法和nc 表现最差,这可以通过k
‑
shell方法选择的种子节点彼此聚集在一起,导致传播影响范围的重叠来解释。所提出的kvoterank等4种knc方法,总能用最少的时间达到稳定状态,kvoterank等4种方法性能有微小差异但都明显优于其他7个基准方法。
[0169]
除了选择的初始种子节点的比例,传染率也会对节点传播过程产生影响,不同的表示不同的传播能力,设置感染概率设置为,感染率从1.0变化到2.0,观察节点的传播影响力,其不同算法的在不同感染概率下的感染规模如图5所示,实验结果通过300次实验的平均获得。轴表示感染率,轴表示在不同感染率下的感染规模,图5(a)中的子图单独给出了所提出的kvoterank、khindex、knhindex和hvoterank四种方法在jazz网络中同感染概率下的感染规模。
[0170]
观察图5不同感染率的感染规模图,所提出的kvoterank、khindex、knhindex和hvoterank方法在8个网络上表现出了较好的性能,并且都优于其他7个基准方法,尤其在cenew和hamster网络,性能明显优于其他方法,在感染率为2.0时,提出的hvoterank算法在cenew网络可以比基准方法多感染约2.9%,在hamster网络中,kvoterank算法高出基准方法3.5%左右。所有提出的方法在网络jazz和condmat表现稍差。在网络jazz和email中,在感染率较小时,所提出的方法与其他方法相当,随着增大,感染规模逐渐增大,这是因为较小的感染率,消息可能不能成功地传播。实验表明,所提出的knc子方法kvoterank、khindex、knhindex和hvoterank相比于基准方法具有更强的泛化能力。
[0171]
5.2平均路径长度分析
[0172]
k
‑
shell方法倾向于选择单个最有影响力的节点,但若选择一组最有影响力的节点,k
‑
shell方法则表现不佳,这是因为k
‑
shell方法的高壳层的节点彼此聚集在一起,导致传播影响范围的重叠,达不到影响力最大化。一般来说,选择的初始种子节点集越分散越能使传播影响最大化。节点集的平均路径长度用来测量初始感染种子节点集之间的距离。图6给出了网络jazz和crimes不同算法选择的种子节点集之间的最短路径长度,其余的最短路径在表5初始节点集最短路径表中给出。
[0173]
观察图6初始节点集最短路径长度图,可以看出对于网络jazz所提出knc方法选择
的节点平均最短路径较大,但距离小于cca方法,在crimes网络中,kvoterank和knhindex平均最短路径最大,这说明了选择的种子节点越分散,越有可能使传播影响最大化。初始节点集最短路径长度表表5给出了不同网络在不同算法下选择的初始节点集之间的平均最短路径长度。为保持实验的一致性,对于规模小的网络jazz,其初始节点集比例设置为0.3,对于规模较小的网络cenew、crimes、email、hamster和ca
‑
grqc,其初始节点集比例设置为0.03,对于规模较大的网络condmat和enron,其初始节点集比列设置为0.003,表5的第7~10列分别为所提出方法khindex、knhindex、hvoterank和kvoterank选择的初始节点集的平均最短路径长度。
[0174]
表5 初始节点集的平均路径长度
[0175][0176][0177]
从初始节点集最短路径长度表表5可以看出,除网络ca
‑
grqc外,所提出的knc子方法kvoterank、khindex、knhindex和hvoterank平均最短路径长度均明显大于其他基准方法,同时也说明了所提出的方法并不是单纯地选择分散节点,而是根据传播能力选择分散的节点。一般来说,选择的初始种子节点越分散,越能使信息传递到整个网络,所以平均最短路径长度一般作为一个评价指标,但并不能绝对地说明算法性能的好坏。为比较算法执行效率,测试了不同算法的运行时间,运行时间表表6中给出了8个网络中不同方法的运行时间。
[0178]
表6 运行时间(s)
[0179]
methodsjazzcenewemailcrimeshamsterca
‑
grqccondmatenronk
‑
shell0.00200.00400.00800.00500.02300.02400.24140.5446voterank0.00200.00300.00900.00500.05380.06680.26830.8327nc 0.00300.00400.00900.00400.02690.02490.26830.6323h
‑
index0.00900.00700.01800.00600.05680.04990.35610.6462nccdh0.08070.14360.26920.12370.80970.70711.90516.1238cca0.11570.26531.69771.08749.801771.5783231.2250357.7111pagerank0.12770.07980.21340.11170.61140.53352.51616.4447kvr0.08080.13070.40160.15061.21381.722228.593766.4826hvr0.10670.16300.41790.18241.26431.828229.678767.0074khi0.08170.10770.31820.14660.82190.81661.36774.3059knhi0.07780.11370.33210.11760.81340.81521.39334.7010
[0180]
结合之前的对比结果,可以得出,所提出的方法在合理的时间内取得了最好的效果,并且四种方法中,khindex与knhindex较kvoterank与hvoterank运行时间少。所提出的knc方法在所有网络中运行时间不超过70秒,khindex与knhindex运行时间不超过5秒。
[0181]
6.结论
[0182]
本发明专利提出了一种混合的基于k
‑
shell的邻域覆盖knc方法去识别复杂网络中一组最有影响力的节点,同时考虑了网络的全局信息和局部信息。knc方法基于两个判断分数,每轮选择第一判断分数最高并且第二判断分数最高的未被覆盖的节点作为种子节点,第一判断分数为主要分数,第二判断分数为次要分数,并且每轮选择节点后,覆盖其一阶邻居,避免传播影响范围的重叠。首先,k
‑
shell分解法赋予同一壳层节点相同的传播能力,是一种粗粒度的排序方法,而voterank方法赋予每个节点相同的投票能力,是一种考虑局部信息的中心性,针对这些问题提出了基于k
‑
shell分解的kvoterank算法,kvoterank认为位于网络核心位置且最受欢迎的节点最具有传播影响力,即使节点voterank值较小,但位于网络中心,该节点也重要。其次,考虑到h
‑
index也是一种粗粒度的局部信息的方法,并且h
‑
index越大,社会影响力也越大,结合h
‑
index与k
‑
shell,提出了khindex方法,并进一步考虑节点的二阶邻域h
‑
index,提出扩展的knhindex方法,第三,利用h
‑
index作为度和核数的中间状态的特点,用h
‑
index近似替代k
‑
shell,结合h
‑
index和voterank去选择出一组最有影响力的传播者,因而提出了hvoterank方法。提出的kvoterank等4种knc子方法都基于覆盖的思想,以使传播影响最大化。此外,sir模型和平均最短路径长度被用来评估所提出的kvoterank、khindex、knhindex和hvoterank方法与其他已有的degree、k
‑
shell等基准方法。在jazz等8个真实的网络数据集上进行测试结果表明,所提出的kvoterank、khindex、knhindex和hvoterank在不同初始节点比例下的感染规模、不同的感染率下的感染规模和传播速度上都明显优于已有的基准方法,并且所提出knc方法选择的初始节点集更大,意味着选择出来的种子节点更分散,更能产生更大的传播影响。可见,提出的knc方法是合理的、有效的。
[0183]
尽管已经示出和描述了本发明的实施例,本领域的普通技术人员可以理解:在不脱离本发明的原理和宗旨的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由权利要求及其等同物限定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。