技术特征:
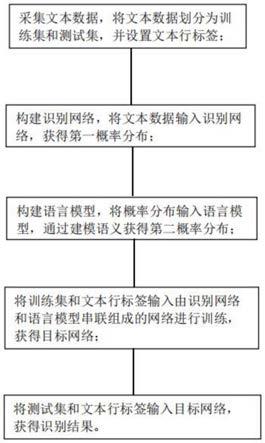
1.一种文本识别中识别网络与语言模型的联合优化方法,其特征在于,包括:采集文本数据,将所述文本数据划分为训练集和测试集,并设置文本行标签;构建识别网络,将所述文本数据输入所述识别网络,获得第一概率分布;构建语言模型,将所述概率分布输入所述语言模型,通过建模语义,获得第二概率分布;将所述训练集和所述文本行标签输入识别网络和语言模型串联组成的网络进行训练,获得目标网络;将所述测试集和所述文本行标签输入所述目标网络,获得识别结果。2.根据权利要求1所述的文本识别中识别网络与语言模型的联合优化方法,其特征在于,采集所述文本数据包括采集文本语料合成数据、现有文本行数据、待测文本行数据;将所述文本数据划分为训练集和测试集包括,将所述文本语料合成数据以及所述现有文本行数据作为训练集,所述待测文本行数据作为测试集。3.根据权利要求2所述的文本识别中识别网络与语言模型的联合优化方法,其特征在于,设置所述文本行标签包括基于所述文本语料合成数据的文本语料和单字数据,合成联机和脱机文本行的同时返回标签信息;基于所述现有文本行数据,读取记录的文本行标签。4.根据权利要求1所述的文本识别中识别网络与语言模型的联合优化方法,其特征在于,所述文本识别网络采用ctc识别网络或attention识别网络;采用所述ctc识别网络,对于需要识别的输入x,输出为概率分布p
ctc
;所述概率分布p
ctc
表示为:其中net
ctc
表示基于ctc的识别神经网络,t为时间点数量,n
cls
为字符类别数;采用所述attention识别网络,对于需要识别的输入,输出为概率分布p
attn
:其中,net
attn
表示基于attention的识别神经网络,t为时间点数量,n
cls
为字符类别数。5.根据权利要求1所述的文本识别中识别网络与语言模型的联合优化方法,其特征在于,获得所述第二概率分布还包括,针对不同的文本类别,初始化不同的可学习嵌入;基于所述可学习嵌入构建可微分的预测嵌入;构建transformer编码层;基于所述transformer编码层构建基于transformer编码器的语言模型,将所述可微分的预测嵌入作为所述语言模型的输入,获得建模语义后的特征;基于所述建模语义后的特征,通过分类器获得所述第二概率分布。6.根据权利要求5所述的文本识别中识别网络与语言模型的联合优化方法,其特征在于,所述可学习嵌入为针对ctc识别网络的第一可学习嵌入或针对attention识别网络的第二可学习嵌入;所述第一可学习嵌入表示为:
所述第二可学习嵌入表示为:其中,d
emb
为嵌入的维度。7.根据权利要求5所述的文本识别中识别网络与语言模型的联合优化方法,其特征在于,所述可微分的预测嵌入为针对ctc识别网络的第一可微分预测嵌入或针对attention识别网络的第二可微分预测嵌入;所述第一可微分预测嵌入表示为:所述第二可微分预测嵌入表示为:8.根据权利要求5所述的文本识别中识别网络与语言模型的联合优化方法,其特征在于,构建所述transformer编码层包括,基于输入特征f1,经过多头注意力层获得特征f2,对所述特征f2进行归一化操作并通过两层全连接层组成的网络,获得目标输出f4;所述特征f2表示为:f2=multihead(q,k,v)=concat(head1,head2,...,head
h
)w
o
其中head
i
为:其中attention为:q,k,v均等于f1;且d
k
=d
v
=d
emb
/h;对所述特征f2进行归一化操作并通过两层全连接层组成的网络,获得目标输出f4表示为:f3=layernorm(f2 f1)f4=layernorm(ffn(f3) f3)其中,layernorm为层归一化操作,ffn为两层全连接层组成的网络。9.根据权利要求6所述的文本识别中识别网络与语言模型的联合优化方法,其特征在于,基于所述transformer编码层构建基于transformer编码器的语言模型,针对不同的识别网络,将所述第一可学习嵌入或所述第二可学习嵌入作为所述语言模型的输入,获得建模语义后的特征;基于所述建模语义后的特征,通过分类器获得所述第二概率分布;基于所
述第二概率分布,获得每个时间点的预测结果,将所述预测结果去除连续重复的预测和空类别,获得识别结果。10.根据权利要求4所述的文本识别中识别网络与语言模型的联合优化方法,其特征在于,获得所述目标识别网络还包括基于自适应的梯度下降法,将所述训练集和所述文本行标签输入所述文本识别网络进行训练;对于采用所述ctc识别网络的情况,根据标签计算的ctc损失p
ctc
的ctc损失相加获得第一总损失l
ctc
;或者对于采用所述attention识别网络的情况,根据标签计算的交叉熵损失p
attn
的交叉熵损失相加获得第二总损失l
attn
。
技术总结
本发明公开了一种文本识别中识别网络与语言模型的联合优化方法,包括:采集文本数据,将文本数据划分为训练集和测试集,并设置文本行标签;构建识别网络,将文本数据输入识别网络,获得第一概率分布;构建语言模型,将概率分布输入语言模型,通过建模语义,获得第二概率分布;将训练集和文本行标签输入由识别网络和语言模型串联组成的网络进行训练,获得目标网络;将测试集和文本行标签输入目标网络,获得识别结果。本发明利用识别网络和语言模型的联合优化,大大提升了识别的精度,并且适用于不同机制的识别网络。该方案在各个公开的数据集上达到了较高的准确率,具有极高的实用性和应用价值。用价值。用价值。
技术研发人员:彭德智 金连文 李鸿亮 谢灿宇
受保护的技术使用者:华南理工大学珠海现代产业创新研究院
技术研发日:2021.09.03
技术公布日:2021/11/28
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。