1.公开了与削波信号的重构(包括大规模多输入多输出(mimo)系统中削波信号的重构)相关的实施例。
背景技术:
2.削波是一种失真形式,其限制高于或低于特定阈值的信号值。在实际中,由于系统限制(例如,为了避免过调制音频发射机),削波可能是必需的。在离散系统中,它可能是由于数据分辨率限制而无意引起的(例如当样本超过可以表示的最大值时),或者当对信号值受限的过程进行仿真时有意地引起的。
3.削波是非线性操作,并且引入了原始信号中不存在的频率分量。在数字域中,当这些新的分量的频率超过奈奎斯特极限时,这些分量被反映到基带中,从而导致混叠。
4.大规模mimo系统现在是一种成熟的技术,其形成了第五代(5g)3gpp移动网络的骨干。在使用大规模mimo的情况下,基站(bs)的天线数量与传统多天线系统相比增加了几个数量级,其目标是实现显著的增益,例如,更高的容量和能效。
5.在传统的多天线bs中,每个射频(rf)端口都连接到一对高分辨率模数转换器(adc)(通常,同相和正交信号分量以超过10比特的分辨率被量化)。将这种架构扩展到具有数百或数千个有源天线元件的大规模mimo将导致令人望而却步的高功耗和硬件成本。adc的硬件复杂性和功耗在量化比特数方面大致呈指数增长。因此,将功耗和系统成本保持在理想限度内的有效解决方案是降低adc的精度(例如,高到8比特)。降低所采用的adc的分辨率的附加动机是限制必须通过连接rf组件(也称为无线电单元(ru))和基带处理单元(bbu)的链路所传输的数据量,基带处理单元(bbu)可以位于远离ru的地方。
6.adc可以被建模为两个过程:采样和量化。采样将连续的时变电压信号转换为离散时间信号——即,实数序列。量化将每个实数替换为来自离散值的有限集范围的近似值,并在输入超出支持范围时执行削波,以将输出限制在该范围。由这种削波引入的误差被称为过载失真。在支持范围的极限内,量化器的可选输出值之间的间距量被称为其粒度,并且由该间距引入的误差被称为粒度失真。量化器的设计通常要确定粒度失真和过载失真之间的适当平衡。对于给定支持数量的可能输出值,减少平均粒度失真可能涉及增加平均过载失真,反之亦然。
技术实现要素:
7.存在某些挑战。例如,过载失真会通过破坏数字信号所代表的数据来严重影响数字信号的质量。事实上,即使是非常低百分比的削波样本也会导致显著的过载失真。在多用户mimo(mu
‑
mimo)系统中,过载失真会导致不准确的信道状态信息(csi),并且其恶化了bs处和/或由bs提供网络接入的用户设备(ue)处的数据估计。
8.本公开提出利用被包含在来自adc转换的削波样本中的信息来提高接收机性能,例如通过减少adc由于其数据分辨率限制而导致的削波失真。这提供了优于已有解决方案
的优势,由于已有解决方案丢弃了削波样本中的信息,因此已有解决方案执行效果欠佳。
9.因此,在一个方面中,提供了一种用于通过利用削波样本和未削波样本之间的相关性来重构削波样本并因此减少过载失真的方法。在一个实施例中,该方法包括:接收信号y,并对y进行采样,从而产生样本集。该方法还包括:量化样本集中的每个样本,以产生量化接收信号r,其中,量化样本集中的每个样本包括对样本中的至少m个样本进行削波,其中,m>0,使得r包括m个削波样本。该方法还包括:获取表示削波样本和未削波样本的信息,以及使用y的概率密度函数和表示削波样本和未削波样本的信息来获取y中未知样本的概率密度函数g(x),该未知样本已经以量化的接收向量r为条件进行了削波。该方法还包括:通过针对r中的每个削波样本值将削波样本值替换为与该削波样本值相对应的期望值来修改r,其中,该期望值基于g(x),从而产生经重构的接收信号。
10.在另一方面中,提供了一种接收机装置,其被配置为:对接收信号y进行采样,从而产生样本集;量化样本集中的每个样本,以产生量化接收信号r,其中,量化样本集中的每个样本包括对样本中的至少m个样本进行削波,其中,m>0,使得r包括m个削波样本;获取表示削波样本和未削波样本的信息;使用y的概率密度函数和表示削波样本和未削波样本的信息来获取y中未知样本的概率密度函数g(x),该未知样本已经以量化的接收向量r为条件进行了削波;以及通过针对r中的每个削波样本值将削波样本值替换为与该削波样本值相对应的期望值来修改r,其中,该期望值基于g(x),从而产生经重构的接收信号。
附图说明
11.本文中所包含并形成说明书一部分的附图示出了各种实施例。
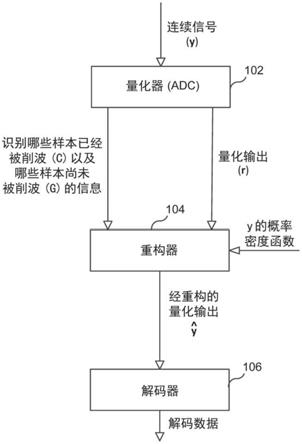
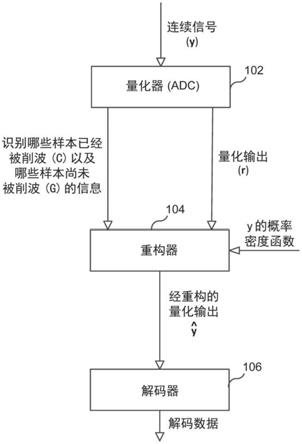
12.图1示出了根据实施例的削波感知(ca)接收机。
13.图2a是示出了根据实施例的由ca
‑
mmse接收机提供的改进的曲线图。
14.图2b是示出了根据实施例的由ca
‑
mmse接收机提供的改进的曲线图。
15.图3a是示出了根据实施例的由ca
‑
mmse接收机提供的改进的曲线图。
16.图3b是示出了根据实施例的由ca
‑
mmse接收机提供的改进的曲线图。
17.图4是示出了根据实施例的过程的流程图。
18.图5是示出了根据实施例的过程的流程图。
19.图6是根据实施例的装置的框图。
20.图7是根据实施例的装置的示意性框图。
具体实施方式
21.图1示出了基于最小均方误差(mmse)的削波感知接收机100(ca
‑
mmse接收机100)的组件。ca
‑
mmse接收机100包括量化器102,其接收输入信号y并产生量化输出r。量化器102(例如,adc)还输出信息(c),其指示y的哪些样本已经被削波。例如,集合c表示接收向量r的削波元素的索引。集合g表示接收向量r的未削波元素的索引。
22.ca
‑
mmse接收机100还包括重构器104,其以量化的接收向量r为条件重构削波样本例如,在给定观察到的接收向量和和的情况下,重构器104通过将r中的每个削波样本值替换为与其相对应的期望值来重构削波样
本本这种方法是最优的,因为它最小化了未知接收信号和其估计之间的均方误差。从数学上讲:
[0023][0024]
ca
‑
mmse接收机100还包括解码器106,其对重构器104输出的信息(即,其中,)进行解码。
[0025]
1.1系统模型
[0026]
考虑单小区mu
‑
mimo系统,其包括与k个单天线ue通信的配备有n个天线的bs,并且假设bs和ue完全同步并运行具有通用频率重用的时分双工(tdd)协议。在bs处的nx1接收向量是:
[0027][0028]
其中,h是k个ue和bs之间的nxn小规模信道系数矩阵。此外,x是k个ue同时发送的独立单位功率符号的kx1向量,每个ue的平均发送功率为ρ。最后,n是加性高斯白噪声(awgn)。
[0029]
1.2复值向量的量化
[0030]
每个天线处的接收信号的同相和正交分量由b比特分辨率的adc来单独量化。更准确地说,我们将adc建模为步长为δ的对称均匀量化器,并且每个adc的特征在于由l=2b个量化级别构成的集合其中
[0031][0032]
此外,我们定义了由l 1个量化阈值构成的集合我们定义了由l 1个量化阈值构成的集合使得∞=τ0<τ1<
…
<τ
l
‑1<τ
l
=∞,并且
[0033][0034]
用于控制信号幅度(或等效地,量化步长δ)以在粒度失真和过载失真之间实现适当平衡的实用技术是使用自动增益控制(agc)。接下来,我们定义非线性量化器映射函数,其描述了bs处的2n个b比特adc的联合操作。为方便起见,我们首先定义笛卡尔积并且令y
n
和r
n
分别为n
×
1向量y和r的第n个元素。然后,量化器映射函数可以由函数来描述,该函数以如下方式将接收到的连续值信号y映射到量化输出r:如果如果且则r
n
=l
k
jl
m
。因此,量化接收信号r可以被写为
[0035][0036]
其中,a是缩放接收信号y的自动增益控制(agc)的nxn对角矩阵。此外,和分别
表示信号的实部和虚部。
[0037]
1.3增广(augmented)实值表示
[0038]
由于adc分别量化信号的实部和虚部(或分别量化同相分量和正交分量),因此信道估计和数据检测应允许单独地处理接收信号的实部和虚部。因此,使用以下定义可以方便地将复值问题(1)转换为等效的增广实值表示:
[0039][0040]
则量化后的信号可以被写为
[0041][0042]
为了便于标记,对于文档的其余部分,我们使用了y、r和x以分别表示y
r
、r
r
和x
r
。
[0043]
我们只关注对量化接收信号r的削波样本的重构,而未被削波(即,在量化器的粒度区域内)的样本在量化后保持不变。为了便于标记,我们首先定义量化接收向量r的以下两个索引集,即,和和
[0044][0045]
即,集合表示接收向量r的削波元素的索引,而集合中的索引表示属于量化器的粒度区域的r的元素。然后,我们定义向量和请注意,和分别表示观察到的削波样本的量化接收向量和位于量化器的粒度区域内的向量。另一方面,向量和表示未知的连续信号,它们被量化,从而分别产生向量和
[0046]
接下来,我们介绍所提出的削波恢复接收机,其以量化接收向量r为条件来仅重构削波样本在给定观察到的接收向量和的情况下,所提出的接收机通过将r中的每个削波样本值替换为与其对应的的期望值来重构削波样本这种方法是最优的,因为它最小化了未知接收信号和其估计之间的均方误差。从数学上讲,我们有以下接收机:
[0047][0048]
因此,在确定(2)中的期望时,我们首先需要后验概率密度函数(在图5中,它也表示为g(x),其中,x指的是以为条件的未知连续样本y
c
),该后验概率密度函数产生所有可行值观察量化向量r的概率。接下来,鉴于接收到的连续信号遵循高斯分布这一事实,我们对所提出的接收机给出了更详细的描述。
[0049]
假设向量r的第m个元素已被削波。即,r
m
=l
j
,其中,j∈{0,l一1}。此外,令表示向量的第m个未知连续样本y
m
的估计值(期望)。因此,根据(2)中期望的定义,
我们有:
[0050][0051]
其中,后验是区间[α
′
,β
′
]内的单边截断正态分布。现在,令α
′
m
和β
′
m
分别为向量α
′
andβ
′
的第m个元素。请注意,区间[α
′
m
,β
′
m
]表示在给定其削波观察样本情况下的未知连续值y
m
的可行范围,且因此在此区间内计算其期望值。以向量为条件,未知向量的每个分量可以是(a)左截断,即,α
′
m
=τ0=
‑
∞且β
′
m
=τ1,或(b)右截断,即,α
′
m
=τ
l
‑1且β
′
m
=τ
l
=∞。
[0052]
值得一提的是:接收到的连续向量的元素是相关的,并且因此通过观察也给了我们关于未知削波样本的信息。这种相关性由(3)中的后验p.d.f.的协方差矩阵来捕捉。
[0053]
表达式(3)中的积分不能以闭合形式来求值,因此我们可以借助数值积分来实现估计器。然而,对于大量削波样本,这变得不切实际。因此,接下来我们提供了低复杂度的迭代算法来逼近(3)中的均值e{y
c
|r
c
,r
g
}。该算法依赖于单边截断正态分布的个闭合形式一维条件的期望,其中,m表示削波样本的基数。
[0054]
具体地,这个过程的第j次迭代返回向量并且其如下所示:
[0055][0056][0057][0058]
迭代地重复该过程,直到数量低于常数δ或已超过最大迭代次数j为止。接下来,我们针对上述期望值来生成闭合形式表达式。
[0059]
为了方便标记,我们定义向量其中,向量的第i个元素已被移除。然后,迭代算法的每个期望由以下闭合形式表达式给出,其是单变量截断正态分布的平均值(参见n.l.johnson、s.kotz、n.balakrishnan,“continuous univariate distributions”,第2版,第1卷,1994年,威利):
[0060][0061]
其中,且此外,是标准正态分布的概率密度函数,是其累积分布函数,并且erfc(
·
)是互补误差
函数。参数和由以下公式给出
[0062][0063][0064]
其中,(n一1)
×
(n
‑
1)矩阵∑
‑
i
‑
i
是通过从∑中移除第i行和第i列而形成的,而(n
‑
1)
×
1向量σ
‑
i
是∑在移除第i个元素之后的第i列,并且(n
‑
1)
×
1平均向量μ
‑
i
是从μ中移除第i个元素之后得到的。此外,方差σ
ii
对应于协方差矩阵∑的第i个对角元素。最后,参数μ和∑分别由以下公式给出
[0065][0066][0067]
其中,和
[0068]
关于计算复杂度,迭代算法需要对简单的闭合形式公式进行求值。主要的计算负担是由于计算在(5)和(6)中出现的m个逆矩阵。
[0069]
所提出的算法是吉布斯(gibbs)采样器的确定性近似,其中,吉布斯采样器的随机生成的样本由相应的条件分布的均值来代替。值得一提的是,吉布斯采样器的确定性近似也已经用于半监督高光谱解混问题(参见,例如,k.e.themelis和a.a.rontogiannis和k.d.koutroumbas,“a novel hierarchical bayesian approach for sparse semisupervised hyperspectral unmixing”,ieee期刊信号处理,第60卷,第2期,第585~599页,2012年2月)。
[0070]
如果矩阵∑
‑1的第i个对角元素的范数大于其对应行的所有项,则表达式(3)中的映射是中关于范数的缩并(contraction)(并且因此,其收敛到唯一的固定解)。
[0071]
我们现在在大规模mu
‑
mimo上行链路系统上使用所提出的接收机来评估均方误差(mse),其中,bs处的每个rf端口都配备有分辨率有限的adc。选择agc以最小化非量化接收向量y和量化向量r之间的均方误差(mse)。
[0072]
在此基础上,通过假设3比特、4比特和6比特分辨率adc,则在接收向量r中平均分别有10%、2%和0.25%的样本被削波。
[0073]
最后,我们假设信道矩阵h的项是独立的且分布的,并将平均信噪比定义为
[0074]
首先,在图2a和图2b中,我们可视化了削波感知mmse(ca
‑
mmse)接收机对每样本的平均粒度和过载失真的改进。回想一下,ca
‑
mmse仅对削波样本执行重构,而粒度样本保持不变,并且因此对粒度失真没有任何改进。然而,ca
‑
mmse带来了对过载失真的显著改善。例如,在b=4比特(图2a)和高信噪比(snr)(即,20db)的情况下,与不重构量化样本的量化无感知情况(qu)相比,它减少了83%的过载失真。确实,当adc的分辨率增加到b=6比特(图2b)时,则ca
‑
mmse对过载失真的增益增加到95%。原因在于,在具有更高分辨率的adc中,粒度失真更低,并且因此ca
‑
mmse可以以更高的精度来重构削波样本。后一个结果尤为重要,
因为它意味着即使是很小比例的削波样本也可能导致显著的过载失真(回想一下当b=6比特时,削波样本的百分比非常低,即,0.25%)。此外,请注意,(对削波样本和位于粒度区域内的样本这二者都进行重构的)量化感知mmse(qa
‑
mmse)的过载失真类似于ca
‑
mmse的过载失真,这指示后者对削波样本重构的效率。
[0075]
最后,请注意,在b=4比特和高snr的情况下,qa
‑
mmse产生比ca
‑
mmse低37%的粒度失真,而当adc的分辨率增加到b=6比特时,正如预期的那样,其粒度增益可以忽略不计。尽管qa
‑
mmse在粒度失真上优于ca
‑
mmse,但它并没有对数据估计产生相当大的改进。原因在于,过载失真相对于每样本的粒度失真占主导地位,并且因此对过载失真进行补偿更为重要。
[0076]
我们现在将注意力转向迭代算法的收敛性,并确认采用ca
‑
mmse接收机100而不是计算成本更高的qa
‑
mmse(即,是足够的。在图3a和图3b中,估计符号的mse被示出为不同数量的bs天线的平均snr和adc分辨率的函数。更确切地说,我们将由迭代算法实现的ca
‑
mmse与基于吉布斯采样(gs
‑
ac
‑
mmse)和qa
‑
mmse的削波感知接收机进行比较。我们注意到,如果b=4比特(图3a),则ca
‑
mmse在仅15次迭代之后收敛到gs
‑
ac
‑
mmse。然而,请注意,当bs天线数量相对较少时,ca
‑
mmse会更快地收敛到gs
‑
ca
‑
mmse。原因在于,在n=16的情况下,要估计的削波样本比在n=64.的情况下要少得多。因此,bs天线数量越少,迭代ca
‑
mmse接收机就越快。同样,当adc中的比特数较多时,收敛更快。因此,在b=6比特(图3b)的情况下,收敛在5次迭代处就已经发生了。
[0077]
此外,值得一提的是,在15次迭代之后,ca
‑
mmse几乎与最佳qa
‑
mmse接收机相同,确认了采用ca
‑
mmse并仅重构削波样本就足够了,而在量化器的粒度区域内的未削波样本可以保持不变。这个结果尤为重要,因为它意味着我们可以通过采用较低复杂度的接收机来实现几乎最佳的性能。
[0078]
图4是示出了根据实施例的过程400的流程图。过程400可以从步骤s402开始。
[0079]
步骤s402包括:接收机100接收信号y。
[0080]
步骤s404包括:接收机100对y进行采样,从而产生样本集,然后量化样本集中的每个样本,以产生量化接收信号r,其中,量化样本集中的每个样本包括对样本中的至少m个样本进行削波,其中,m>0,使得r包括m个削波样本。
[0081]
步骤s406包括:接收机100获取表示削波样本和未削波样本的信息。例如,获取削波样本和/或未削波样本的列表。
[0082]
步骤s412包括:接收机100使用y的概率密度函数和表示削波样本和未削波样本的信息来获取y中的未知样本的概率密度函数g(x),该未知样本已经根据接收到的量化向量r进行削波,其中,x=(x1,...,x
m
)表示在被削波到向量r
c
之前的未知值。
[0083]
步骤s414包括:接收机100通过针对r中的每个削波样本值将削波样本值替换为与该削波样本值相对应的期望值来修改r,其中,该期望值基于g(x),从而产生经重构的接收信号。
[0084]
过程400还可以包括步骤s408、s410和s416。步骤s408和s410分别包括:接收训练数据,以及使用所接收的训练数据获取y的概率密度函数。步骤s416包括:对进行解码。
[0085]
图5是示出了根据实施例的用于实现步骤s414的过程500的流程图。过程500可以
从步骤s501开始。
[0086]
步骤s501包括:初始化y中已经被削波的样本的期望值,即,μ
(0)
=(μ
1(0)
,μ
2(0)
,...μ
m(0)
)。这里的初始值等于它们对应的削波值。
[0087]
即,在步骤s501中,初始化第一向量μ
(0)
,其中,第一向量由值μ
1(0)
,μ
2(0)
,μ
3(0)
,...,μ
m(0)
组成。
[0088]
步骤s502包括定义终止条件δ和j。
[0089]
步骤s504包括设置j=1。
[0090]
步骤s506包括确定μ
(j)
,其是期望值的向量。确定μ
(j)
包括:对于i=1至m,计算向量的每个元素μ
i(j)
,其中,m等于削波样本总数。即,确定μ
(j)
包括计算:
[0091]
μ
1(j)
=e(x1|μ
2(j
‑
1)
,μ
3(j
‑
1)
,...,μ
m(j
‑
1)
)
[0092]
μ
2(j)
=e(x2|μ
1(j)
μ
3(j
‑
1)
,...,μ
m(j
‑
1)
)
[0093][0094]
μ
m(j)
=e(x
m
|μ
1(j)
,μ
2(j)
,
…
,μ
m
‑
1(j)
).
[0095]
e(x1|μ
2(j
‑
1)
,μ
3(j
‑
1)
,...,μ
m(j
‑
1)
)是基于)是基于的第一削波样本的期望值;e(x2|μ
1(j)
,μ
3(j
‑
1)
,...,μ
m(j
‑
1)
)是基于的第二削波样本的期望值;
…
;以及e(x
m
|μ
1(j)
,μ
3(j)
,
…
,μ
m(j)
)是基于)是基于的第m个削波样本的期望值。
[0096]
确定μ
(j)
之后,在步骤s508中确定是否:
[0097]
||μ
(j)
‑
μ
(j
‑
1)
||<δ或j=j。
[0098]
如果||μ
(j)
‑
μ
(j
‑
1)
||<δ或j=j为真,则过程进行到步骤s510,否则过程进行到步骤s509,在步骤s509中,j递增1。在步骤s509之后,过程返回到步骤s506。
[0099]
步骤s510包括设置例如,作为确定||μ
(1)
‑
μ
(0)
||小于δ的结果,将r中第一削波样本值替换为μ
1(1)
,将r中第二削波样本值替换为μ
2(1)
,...,以及将r中第m个削波样本值替换为μ
m(1)
。
[0100]
图6是根据一些实施例的接收机装置600的框图。接收机装置600可以用于实现接收机100。如图6所示,接收机装置600可以包括:处理电路(pc)602,其可以包括一个或多个处理器(p)655(例如,通用微处理器和/或一个或多个其他处理器,例如,专用集成电路(asic)、现场可编程门阵列(fpga)等),这些处理器可以共同位于单个壳体或单个数据中心中,或者可以在地理上分布(即,接收机装置600可以是分布式计算装置);网络接口648,包括发射机(tx)645和接收机(rx)647,用于使装置600能够向连接到网络110(例如,互联网协议(ip)网络)的其他节点发送数据和从该其他节点接收数据,网络接口648连接到网络110;以及本地存储单元(也称为“数据存储系统”)608,其可以包括一个或多个非易失性存储设
备和/或一个或多个易失性存储设备。在pc 602包括可编程处理器的实施例中,可以提供计算机程序产品(cpp)641。cpp 641包括计算机可读介质(crm)642,该计算机可读介质(crm)642存储包括计算机可读指令(cri)644在内的计算机程序(cp)643。crm 642可以是非暂时性计算机可读介质,例如,磁介质(例如,硬盘)、光介质、存储设备(例如,随机存取存储器、闪存)等。在一些实施例中,计算机程序643的cri 644被配置为使得当由pc 602执行时,cri使装置600执行本文中描述的步骤(例如,本文中参考流程图描述的步骤)。在其他实施例中,装置600可被配置为在不需要代码的情况下执行本文描述的步骤。即,例如,pc 602可以仅由一个或多个asic组成。因此,本文描述的实施例的特征可以以硬件和/或软件方式来实现。
[0101]
图7是根据一些其他实施例的接收机装置600的示意性框图。接收机装置600包括一个或多个模块700,每个模块以软件实现。模块700提供本文中描述的装置600的功能(例如,上述步骤,例如关于图4和/或图5)。
[0102]
尽管本文描述了本公开的各种实施例,但应当理解,其仅以示例而非限制的方式提出。因此,本公开的宽度和范围不应当受到上述示例性实施例中任意一个的限制。通常,除非明确给出和/或从其所处的上下文中暗示不同的含义,否则本文中使用的所有术语将根据其在相关技术领域中的普通含义来解释。除非另有明确说明,否则对“一/一个/所述元件、设备、组件、装置、步骤等”的所有引用应被开放地解释为指代元件、设备、组件、装置、步骤等中的至少一个实例。除非本文中另有指示或以其他方式和上下文明确冲突,否则上述要素以其所有可能变型进行的任意组合都被包含在本公开中。
[0103]
附加地,尽管上文描述的且附图中示出的处理被示为一系列步骤,但其仅用于说明目的。因此,可以想到可增加一些步骤、可省略一些步骤、可重排步骤顺序、以及可并行执行一些步骤。即,除非必须明确地将一个步骤描述为在另一个步骤之后或之前和/或隐含地一个步骤必须在另一个步骤之后或之前,否则本文所公开的任何方法的步骤不必以所公开的确切顺序执行。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。