1.本技术涉及计算机技术领域,特别涉及一种设备识别方法、装置、设备及存储介质。
背景技术:
2.随着互联网技术的发展,ott(over the top)服务也越来越成熟。ott是互联网公司越过运营商,发展基于开放互联网的各种视频及数据服务业务。用户可以通过ott设备使用上述ott服务,上述ott设备是指一切能承载ott服务的设备,比如智能电视、流媒体盒子等设备。
3.为了更好地管理网络中的ott设备,需要从网络连接的设备中识别出ott设备,进而对这些ott设备采取更有效的管理措施,例如向ott设备推送相应的多媒体资源。相关技术中,基于人工经验确定识别ott设备的数据规则。运营人员基于业务经验和对ott设备的特性理解,设定潜在“ott设备”识别的划分规则,进而对网络中的连接设备进行识别,确定其中的ott设备。
4.相关技术中,识别ott设备的规则有限,ott设备识别的准确率与效率都较低。
技术实现要素:
5.本技术实施例提供了一种设备识别方法、装置、设备及存储介质,有效提升了ott设备识别的准确率与效率。
6.根据本技术实施例的一个方面,提供了一种设备识别方法,所述方法包括:
7.获取待识别设备的设备特征信息;
8.对所述设备特征信息进行特征嵌入处理,生成所述待识别设备的整体特征信息,所述整体特征信息的维度小于或者等于所述设备特征信息的维度;
9.基于所述整体特征信息,确定所述待识别设备的交叉特征信息,所述交叉特征信息表征所述待识别设备的不同设备特征之间的关联性;
10.在所述整体特征信息与所述交叉特征信息符合目标条件的情况下,确定所述待识别设备为互联网服务设备。
11.根据本技术实施例的一个方面,提供了一种设备识别装置,所述装置包括:
12.特征获取模块,用于获取待识别设备的设备特征信息;
13.特征嵌入模块,用于对所述设备特征信息进行特征嵌入处理,生成所述待识别设备的整体特征信息,所述整体特征信息的维度小于或者等于所述设备特征信息的维度;
14.特征交叉模块,用于基于所述整体特征信息,确定所述待识别设备的交叉特征信息,所述交叉特征信息表征所述待识别设备的不同设备特征之间的关联性;
15.设备识别模块,用于在所述整体特征信息与所述交叉特征信息符合目标条件的情况下,确定所述待识别设备为互联网服务设备。
16.根据本技术实施例的一个方面,提供了一种计算机设备,所述计算机设备包括处
理器和存储器,所述存储器中存储有至少一条指令、至少一段程序、代码集或指令集,所述至少一条指令、所述至少一段程序、所述代码集或指令集由所述处理器加载并执行以实现上述设备识别方法。
17.根据本技术实施例的一个方面,提供了一种计算机可读存储介质,所述存储介质中存储有至少一条指令、至少一段程序、代码集或指令集,所述至少一条指令、所述至少一段程序、所述代码集或指令集由处理器加载并执行以实现上述设备识别方法。
18.根据本技术实施例的一个方面,提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中。计算机设备的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行上述设备识别方法。
19.本技术实施例提供的技术方案可以带来如下有益效果:
20.通过特征嵌入的方式,将高维离散的设备特征进行转换为低维稠密的整体特征,在保证设备特征信息完整性的前提下更加高效地表征设备特征并减少运算量,然后确定整体特征中各特征间的交叉特征,充分挖掘待识别设备的特征信息,进而从整体特征与交叉特征两方面去确定待识别设备是否为互联网服务设备,提升识别互联网服务设备的效率的同时,还提升了识别准确率。
附图说明
21.为了更清楚地说明本技术实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本技术的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
22.图1是本技术一个实施例提供的应用程序运行环境的示意图;
23.图2是本技术一个实施例提供的设备识别方法的流程图;
24.图3是本技术另一个实施例提供的设备识别方法的流程图;
25.图4示例性示出了一种互联网服务设备识别模型的结构示意图;
26.图5示例性示出了一种识别互联网服务设备流程的示意图;
27.图6示例性示出了一种互联网服务设备的运营数指标折线图;
28.图7是本技术一个实施例提供的互联网服务设备识别模型的训练方法以及互联网服务设备识别方法的流程图;
29.图8示例性示出了一种评估互联网服务设备识别模型的数据指标折线图;
30.图9例性示出了一种设备识别技术方案的技术架构示意图;
31.图10是本技术一个实施例提供的设备识别装置的框图;
32.图11是本技术一个实施例提供的计算机设备的结构框图。
具体实施方式
33.本技术技术方案涉及人工智能技术领域和区块链技术领域,下面对此进行介绍说明。
34.ai(artificial intelligence,人工智能)是利用数字计算机或者数字计算机控
制的机器模拟、延伸和扩展人的智能,感知环境、获取知识并使用知识获得最佳结果的理论、方法、技术及应用系统。换句话说,人工智能是计算机科学的一个综合技术,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器。人工智能也就是研究各种智能机器的设计原理与实现方法,使机器具有感知、推理与决策的功能。
35.人工智能技术是一门综合学科,涉及领域广泛,既有硬件层面的技术也有软件层面的技术。人工智能基础技术一般包括如传感器、专用人工智能芯片、云计算、分布式存储、大数据处理技术、操作/交互系统、机电一体化等技术。人工智能软件技术主要包括计算机视觉技术、语音处理技术、自然语言处理技术以及机器学习/深度学习等几大方向。
36.机器学习(machine learning,ml)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。机器学习是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域。机器学习和深度学习通常包括人工神经网络、置信网络、强化学习、迁移学习、归纳学习、式教学习等技术。
37.区块链(blockchain)是分布式数据存储、点对点传输、共识机制、加密算法等计算机技术的新型应用模式。区块链本质上是一个去中心化的数据库,是一串使用密码学方法相关联产生的数据块,每一个数据块中包含了一批次网络交易的信息,用于验证其信息的有效性(防伪)和生成下一个区块。区块链可以包括区块链底层平台、平台产品服务层以及应用服务层。狭义来讲,区块链是一种按照时间顺序将数据区块以顺序相连的方式组合成的一种链式数据结构,并以密码学方式保证的不可篡改和不可伪造的分布式账本,即区块链中的数据一旦记录下来将不可逆。
38.为使本技术的目的、技术方案和优点更加清楚,下面将结合附图对本技术实施方式作进一步地详细描述。
39.请参考图1,其示出了本技术一个实施例提供的应用程序运行环境的示意图。该应用程序运行环境可以包括:终端10和服务器20。
40.终端10可以是诸如手机、平板电脑、游戏主机、电子书阅读器、多媒体播放设备、可穿戴设备、pc(personal computer,个人计算机)等电子设备。终端10中可以安装应用程序的客户端。
41.在本技术实施例中,上述应用程序可以是任何能够使用无线网络服务的应用程序。典型地,该应用程序为无线网络管理应用程序,有网络连接需求的设备可通过无线网络管理应用程序中提供的无线网络,与互联网建立连接并使用相应的互联网服务。可选地,上述无线网络管理应用程序支持上亿公共无线网络热点,终端无需输入密码就可一键连接,上述无线网络管理应用程序可通过预设的无线网络标准对这些热点进行全方位的安全、连接速度、网络质量等进行全面评估,确保无僵尸、风险、虚假无线网络。当然,除了无线网络管理应用程序之外,其它类型的应用程序中也能够使用无线网络服务。例如,安全管理类应用程序、社交类应用程序、互动娱乐类应用程序、虚拟现实(virtual reality,vr)类应用程序、增强现实(augmented reality,ar)类应用程序、三维地图程序、军事仿真程序等,本技术实施例对此不作限定。另外,对于不同的应用程序来说,其支持用户创作的内容也会有所不同,且相应的功能也会有所不同,这都可以根据实际需求预先进行配置,本技术实施例对
此不作限定。可选地,终端10中运行有上述应用程序的客户端。在一些实施例中,上述应用程序是基于三维的虚拟环境引擎开发的应用程序,比如该虚拟环境引擎是unity引擎或者unreal引擎,该虚拟环境引擎能够构建三维的虚拟环境动画、虚拟对象动画和虚拟道具动画等,给用户带来更加沉浸式的应用体验。
42.服务器20用于为终端10中的应用程序的客户端提供后台服务。例如,服务器20可以是上述应用程序的后台服务器。服务器20可以是一台服务器,也可以是由多台服务器组成的服务器集群,或者是一个云计算服务中心。可选地,服务器20同时为多个终端10中的应用程序提供后台服务。
43.可选地,终端10和服务器20之间可通过网络30进行互相通信。
44.在介绍本技术提供的方法实施例之前,先对本技术方法实施例中可能涉及的相关术语或者名词进行简要介绍,以便于本技术领域技术人员理解。
45.无线网络,是指无需布线就能实现各种通信设备互联的网络。无线网络技术涵盖的范围很广,既包括允许用户建立远距离无线连接的全球语音和数据网络,也包括为近距离无线连接进行优化的红外线及射频技术。根据网络覆盖范围的不同,可以将无线网络划分为无线广域网(wireless wide area network,wwan)、无线局域网(wireless local area network,wlan)、无线城域网(wireless metropolitan area network,wman)和无线个人局域网(wireless personal area network,wpan)。
46.wifi(wireless
‑
fidelity)是一种允许电子设备连接到一个无线局域网(wlan)的技术。连接到无线局域网通常是有密码保护的;但也可是开放的,这样就允许任何在wlan范围内的设备可以连接上。
47.ott(over
‑
the
‑
top)是指任何用于将数字内容传到电视或类似设备上的设备或者服务。通常归类为ott的设备包括:流媒体盒子(apple tv、amazon fire tv、android tv、samsung allshare cast)、hdmi电视棒(chromecast、roku、amazon fire tv stick)、智能tv(通过类似netflix或hbo go这类的tv应用程序)等。
48.ott设备:是指一切能承载ott服务的设备,比如智能tv等。
49.高清多媒体接口(high definition multimedia interface,hdmi)是一种全数字化视频和声音发送接口,可以发送未压缩的音频及视频信号。hdmi可用于机顶盒、dvd播放机、个人计算机、电视、游戏主机、综合扩大机、数字音响与电视机等设备。hdmi可以同时发送音频和视频信号,由于音频和视频信号采用同一条线材,大大简化系统线路的安装难度。
50.api(application programming interface,应用编程接口)其实就是操作系统留给应用程序的一个调用接口,应用程序通过调用操作系统的api而使操作系统去执行应用程序的命令(动作)。
51.软件开发工具包(software development kit,sdk)是一些被软件工程师用于为特定的软件包、软件框架、硬件平台、操作系统等创建应用软件的开发工具的集合,一般而言sdk即开发平台下的应用程序所使用的sdk。它可以简单的为某个程序设计语言提供应用程序接口api的一些文件,但也可能包括能与某种嵌入式系统通讯的复杂的硬件。
52.hadoop分布式文件系统(hadoop distributed file system,hdfs)是指被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统(distributed file system)。它和现有的分布式文件系统有很多共同点。但同时,它和其他的分布式文件系统
的区别也是很明显的。hdfs是一个高度容错性的系统,适合部署在廉价的机器上。hdfs能提供高吞吐量的数据访问,适合大规模数据集上的应用。hdfs可以实现流的形式访问(streaming access)文件系统中的数据。
53.特征工程(feature engineering)是这样一个过程:将数据转换为能更好地表示潜在问题的特征,从而提高机器学习性能。如果把数据理解为一个n维空间中的向量(n是列数),那么我们可以考虑,能不能创建一个k维(k<n)的子集,完全或几乎完全表示原数据,从而提升机器学习速度或性能。
54.特征选择得到的是原有特征的子集,而特征抽取是将原有特征根据某种函数关系转换为新的特征,并且数据集的维度比原来的低。
55.独热编码(one
‑
hot encoding)是一位有效编码。独热编码方法是使用n位状态寄存器来对n个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。对于每一个特征,如果它有m个可能值,那么经过独热编码后,就变成了m个二元特征。并且,这些特征互斥,每次只有一个激活。
56.nan(not a number,非数)是计算机科学中数值数据类型的一类值,表示未定义或不可表示的值。常在浮点数运算中使用。
57.nan encoding(非数编码),为nan值提供显式编码而不是忽略。nan值可以保存信息,用于对于特征的缺失值处理,包括但不限于“剔除”、“平均值填充”和“缺失标记”等方式,
58.embedding(嵌入)是指将高维原始数据(图像,句子)映射到低维流形,使得高维的原始数据被映射到低维流形之后变得可分,而这个映射就叫嵌入。简单地说,embedding就是把一个东西映射到一个向量。如果两个东西很像,那么它们对应的向量欧式距离很小。embedding就是从原始数据提取出来的特征,也就是那个通过神经网络映射之后的低维向量。
59.合并编码(consolidation encoding),将不同的分类变量映射到同一个变量,拼写错误,略有不同的职位描述,全名与缩写,真实数据很乱,free文本尤其如此。
60.scaling(数据范围缩放处理),将数值变量缩放到一定范围内。
61.有很多处理缺失值的办法和技巧。虽然办法有很多变种,但是两个最主要的处理方法是:删除缺少值的行;填充缺失值。填充缺失值包括均值填充。
62.探索性数据分析(eda,exploratorydata analysis)来识别缺失的值。
63.标准化通过确保所有行和列在机器学习中得到平等对待,让数据的处理保持一致。
64.归一化操作旨在将行和列对齐并转化为一致的规则。例如,归一化的一种常见形式是将所有定量列转化为同一个静态范围中的值(例如,所有数都位于0~1)。
65.z分数标准化是最常见的标准化技术,利用了统计学里简单的z分数(标准分数)思想。z分数标准化的输出会被重新缩放,使均值为0、标准差为1。通过缩放特征、统一化均值和方差(标准差的平方),可以优化神经网络模型,使神经网络模型不会倾向于较大比例的特征。
66.min
‑
max(最小值
‑
最大值)标准化和z分数标准化类似,因为它也用一个公式替换列中的每个值。此处的公式是:m=(x
‑
xmin)/(xmax
‑
xmin)在这个公式中:m是新的值;x是单
元格原来的值;xmin是该列的最小值;xmax是该列的最大值。使用这个公式可以看到,每列所有的值都会位于0~1。
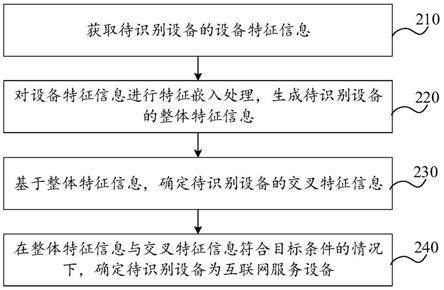
67.请参考图2,其示出了本技术一个实施例提供的设备识别方法的流程图。该方法可应用于计算机设备中,所述计算机设备是指具备数据计算和处理能力的电子设备,如各步骤的执行主体可以是图1所示的应用程序运行环境中的服务器20。该方法可以包括以下几个步骤(210~240)。
68.步骤210,获取待识别设备的设备特征信息。
69.设备特征信息包括待识别设备在至少一个设备特征上的特征信息。可选地,待识别设备包括但不限于无线局域网的连接设备、安装无线网络管理应用程序的设备、调用应用编程接口的待识别设备、使用sdk的设备。
70.获取待识别设备的设备数据。设备数据包括设备运行数据以及设备画像数据。
71.上述设备运行数据是指反映设备运行情况的数据。可选地,设备运行数据包括设备反馈数据,设备反馈数据是指设备返回的设备行为数据。在一种可能的实施方式中,被确定为高概率的ott设备会对其线上行为进行反馈,可将高概率的ott设备反馈回来的数据存储在hdfs上,定时离线或在线统计待识别设备在目标时段内的设备特征信息。可选地,目标时段包括但不限于半年内时间、三个月内时间、一个月内时间、1周内时间、3天内时间。
72.上述设备画像数据是指反映设备属性的数据。基于设备历史运行数据,构建出丰富的设备画像。其中,设备画像数据包括但不限于:设备基础属性数据、设备网络属性数据、设备行为属性数据等。
73.对设备数据进行数据映射处理,生成与设备数据对应的特征值。上述特征值表征待识别设备的至少一种设备特征。上述映射处理是指根据预设函数关系将设备数据映射为特征值。
74.对于至少一种设备特征中的目标设备特征,获取与目标设备特征关联的目标特征数据。
75.确定与目标特征数据对应的目标映射方法。上述目标映射方法是根据目标特征数据从各映射方法中确定的用于处理目标特征数据的映射方法。
76.根据目标映射方法,将目标特征数据映射为表征目标设备特征的特征值。可选地,使用目标映射方法对目标特征数据进行编码,得到目标设备特征的特征值。可选地,使用目标映射方法对目标特征数据进行嵌入处理,得到目标设备特征的特征值,目标设备特征的特征值的维度小于或者等于目标特征数据的维度。
77.基于至少一种设备特征的特征值,得到与设备数据对应的特征值。设备数据对应的特征值包括各个设备特征对应的特征值。
78.基于特征值,生成设备特征向量。可选地,将各个设备特征对应的特征值按照预设位置进行拼接,生成设备特征向量,设备特征向量是设备特征信息的数学表现形式。可选地,设备特征信息包括设备特征的特征值。
79.步骤220,对设备特征信息进行特征嵌入处理,生成待识别设备的整体特征信息。
80.其中,整体特征信息的维度小于或者等于设备特征信息的维度。
81.上述特征嵌入处理是指将高维离散的特征进行映射,得到低维稠密的特征。因此,待识别设备的整体特征信息的维度小于或者等于设备特征信息的维度。
82.在一种可能的实施方式中,对设备特征信息中的数据进行特征嵌入处理,生成待识别设备的整体特征信息。
83.对于任一设备特征,在设备特征信息中提取对应于设备特征的特征值。
84.对设备特征的特征值进行特征值嵌入处理,生成设备特征对应的特征嵌入向量。对设备特征对应的特征嵌入向量进行线性拼接处理,生成待识别设备的整体特征嵌入向量。上述整体特征嵌入向量为整体特征信息的数学表现形式。
85.步骤230,基于整体特征信息,确定待识别设备的交叉特征信息。
86.交叉特征信息表征待识别设备的不同设备特征之间的关联性。
87.利用整体特征信息中各设备特征的特征信息,对各设备特征的特征信息进行交叉分析,挖掘各设备特征的特征信息之间的关联,确定待识别设备的交叉特征信息。
88.在一种可能的实施方式中,对设备特征对应的特征嵌入向量进行特征交叉处理,生成交叉特征值;基于交叉特征值,生成待识别设备的交叉特征嵌入向量。
89.上述特征交叉处理包括对设备特征对应的特征嵌入向量进行乘积处理,得到各设备特征对应的特征嵌入向量之间的向量积。上述乘积处理采用的乘积方式的不同,向量积也不同。可选地,向量积为内积,上述乘积方式为内积对应的乘积方式。可选地,向量积为外积,上述乘积方式为外积对应的乘积方式。
90.步骤240,在整体特征信息与交叉特征信息符合目标条件的情况下,确定待识别设备为互联网服务设备。
91.上述目标条件用于根据整体特征信息与交叉特征信息判断待识别设备是否为互联网服务设备。
92.在一种可能是实施方式中,目标条件包括根据整体特征信息与交叉特征信息确定出待识别设备为互联网服务设备的概率大于或者等于概率阈值,或者互联网服务设备识别模型根据整体特征信息与交叉特征信息输出的模型结果表征待识别设备为互联网服务设备。
93.综上所述,本技术实施例提供的技术方案,通过特征嵌入的方式,将高维离散的设备特征进行转换为低维稠密的整体特征,在保证设备特征信息完整性的前提下更加高效地表征设备特征并减少运算量,然后确定整体特征中各特征间的交叉特征,充分挖掘待识别设备的特征信息,进而从整体特征与交叉特征两方面去确定待识别设备是否为互联网服务设备,提升识别互联网服务设备的效率的同时,还提升了识别准确率。
94.请参考图3,其示出了本技术另一个实施例提供的设备识别方法的流程图。该方法可应用于计算机设备中,所述计算机设备是指具备数据计算和处理能力的电子设备,如各步骤的执行主体可以是图1所示的应用程序运行环境中的服务器20。该方法可以包括以下几个步骤(301~315)。
95.步骤301,获取待识别设备的设备数据。
96.步骤302,对于至少一种设备特征中的目标设备特征,获取与目标设备特征关联的目标特征数据。
97.步骤303,确定与目标特征数据对应的目标映射方法。
98.步骤304,根据目标映射方法,将目标特征数据映射为表征目标设备特征的特征值。
99.可通过特征处理方法,对待识别设备的设备数据进行特征处理,确定待识别设备在各设备特征上的特征信息。可选地,上述特征处理方法包括独热编码、非数编码、合并编码、数据范围缩放处理、安装应用数量嵌入处理。
100.可选地,对于待识别设备是否有hdmi接口这一设备特征,会选择独热编码的特征处理方法。
101.可选地,对于设备特征中的缺失值,可使用缺失值剔除、平均值填充或者缺失标记等方式,实验结果显示在互联网服务设备识别场景,将缺失值转为嵌入值表达的方式,对识别互联网服务设备的效果具有较好的正向收益。
102.可选地,对于设备特征下的变量具有多个取值的情况,可以将其归纳成同一个信息。比如设备系统版本特征的多个取值里包括“4.2”、“4.4”和“5.0”三个,基于经验可以将这三个值归纳为“低版本安卓系统”。实验证明,这种特征归纳的处理方式,比直接将“安卓系统版本”特征one
‑
hot能带来更大的正向收益。
103.可选地,根据数值型的设备特征的分布情况,选择合适的归一化方法来消除特征之间的量纲差异,使数据运算结果更加稳定。比如对于符合或近似符合正态分布的特征,选择高斯归一化进行数据范围缩放处理。
104.可选地,基于list
‑
embedding方式,对待识别设备安装的不同类目应用程序的个数序列进行嵌入提取,比如得到安装社交类型应用的嵌入特征值,获得低维稠密的设备特征。
105.count encoding(频数编码),例如对于设备连接相同无线局域网的次数,可用频数编码来标识设备和当前无线局域网的亲密程度。比如设备近31天连接同一个无线局域网的天数为27。
106.category embedding(类别嵌入)。根据数据分析发现,有许多设备特征都存在较强的稀疏性。为了避免模型过拟合和提高模型稳定性,引入神经网络将高维稀疏分类变量转换为低维稠密的embedding(嵌入)变量。上述神经网络是训练好的神经网络。
107.步骤305,基于至少一种设备特征的特征值,得到与设备数据对应的特征值。
108.步骤306,基于特征值,生成设备特征向量。
109.步骤307,对于任一设备特征,在设备特征向量中提取对应于设备特征的特征值。
110.步骤308,对设备特征的特征值进行特征值嵌入处理,生成设备特征对应的特征嵌入向量。
111.特征嵌入向量包括表征目标设备特征的特征嵌入值,特征嵌入值的数量小于或者等于特征值的数量,表明特征嵌入向量从更低维度表征设备特征。
112.步骤309,对设备特征对应的特征嵌入向量进行线性拼接处理,生成待识别设备的整体特征嵌入向量。
113.整体特征嵌入向量为整体特征信息的数学表现形式。可选地,对设备特征对应的特征嵌入向量中的特征嵌入值与相关系数,或者与特征嵌入值所在维度对应的权重系数线性相乘,再拼接线性相乘后的特征嵌入向量,生成待识别设备的整体特征嵌入向量。
114.步骤310,对设备特征对应的特征嵌入向量进行特征交叉处理,生成交叉特征值。
115.交叉特征值表征待识别设备的各设备特征中两两之间的关联性。
116.对各设备特征对应的特征嵌入向量两两之间进行向量积运算,生成向量积,该向
量积可以是表征待识别设备的各设备特征中两两之间的关联性的交叉特征值。
117.可选地,向量积包括内积和外积
118.步骤311,基于交叉特征值,生成待识别设备的交叉特征嵌入向量。
119.交叉特征嵌入向量为交叉特征信息的数学表现形式。
120.步骤312,对整体特征信息与交叉特征信息进行深度特征提取处理,确定待识别设备为互联网服务设备的概率。
121.步骤313,在概率大于或者等于概率阈值的条件下,确定待识别设备为互联网服务设备。
122.可选地,上述概率阈值是根据实际应用场景确定的阈值,用于区分互联网服务设备与非互联网服务设备。可选地上述概率阈值可根据实际应用场景以及识别设备的反馈信息进行调整或者自主更新。
123.在示例性实施例中,可通过构建基于神经网络的互联网服务设备识别模型实现上述步骤307
‑
312。
124.在一种可能的实施方式中,互联网服务设备识别模型是基于概率神经网络(probabilistic neural network,pnn)训练的神经网络模型。该模型本质上是基于乘法的运算来体现特征交叉的深度神经网络(deep neural networks,dnn)网络结构。pnn与fnn(factorisation
‑
machine supported neural networks,)最大的区别在于:pnn并没有单独使用全连接层来对低阶特征进行组合,而是设计了二阶向量积层对特征进行更细致的交叉运算。下面对pnn进行简单介绍。
125.一、pnn数学原理的核心点包括以下两点:
126.(a)假设有n个field,one
‑
hot向量为x,每个field生成一个embedding向量。
127.(b)pnn模型包括以下关键层:
128.第0层(输入层):离散数据经过相应的数据映射之后作为输入层的输入。
129.第1层(嵌入层):模型从每个类型中的数据学得各类型的嵌入向量表示。
130.第2层(二阶向量积层):将嵌入向量的一阶特征和二阶交叉特征拼接。
131.二、pnn相比其它模型,有以下明显优势:
132.(1)利用二阶向量积层(pair
‑
wisely connected product layer)对特征嵌入向量两两进行向量积,形成的结果作为之后mlp的输入。
133.(2)pnn设计了二阶向量积层来对特征进行组合,包含内积与外积两种操作,增大特征组合交叉的深度。
134.1、对于内积形式的pnn,因为两个向量相乘的结果为标量,可以直接把各个标量“拼接”成一个大向量,就可以作为mlp的输入了。
135.2、对于外积形式的pnn,因为两个向量相乘相当于列向量与行向量进行矩阵相乘,得到的结果为一个矩阵。各个矩阵向之前内积形式的操作一样直接拼接起来维数太多,简化方案是直接对各个矩阵进行求和,得到的新矩阵作为mlp的输入。
136.三、训练pnn的经验积累:对于隐藏层,使用三层200
‑
400
‑
100的结构设计;使用线性整流函数(rectified linear unit,relu)作为激活函数;在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃,这一过程可被称为dropout。
137.在一个示例中,如图4所示,其示例性示出了一种互联网服务设备识别模型的结构示意图。图4中的互联网服务设备识别模型是基于pnn训练的神经网络模型。可将本实施例中的步骤306生成的设备特征向量输入至互联网服务设备识别模型,由互联网服务设备识别模型的输入层执行本实施例中的步骤306,在设备特征向量中提取对应于设备特征的特征值,即图4中的子向量1、子向量2、
…
、子向量n,分别对应于待识别设备的n个设备特征。设备特征向量便是由子向量1、子向量2、
…
、子向量n组合的向量。由特征嵌入层执行本实施例中的步骤308,生成设备特征对应的特征嵌入向量,即图4中的特征嵌入向量1、特征嵌入向量2、
…
、特征嵌入向量n。由二阶向量积层执行本实施例中的步骤309至311,生成待识别设备的整体特征嵌入向量以及交叉特征嵌入向量,并将整体特征嵌入向量与交叉特征嵌入向量进行拼接输入至全连接层1。上述向量乘积方式已在上文做过介绍,这里不再赘述。由全连接层1和全连接层2执行本实施例中的步骤312,对整体特征嵌入向量与交叉特征嵌入向量的拼接向量进行深度特征提取处理,并由输出层输出待识别设备为互联网服务设备的概率。
138.在另一种可能的实施方式中,互联网服务设备识别模型是基于xdeepfm(extreme deep factorization machine,极深因子分解机)模型训练的神经网络模型。该模型本质上是通过理论和实验发现dcn(deep&cross network,深度学习网络)模型的不足,进而提出cin(compressed interaction network,压缩交互网络)模型进行优化。下面对xdeepfm作简要说明。
139.一、xdeepfm数学原理的核心点包括以下三点:
140.将输入的原特征和神经网络中的隐层都分别组织成一个矩阵,分别记为x0和x
k
。其中,x0是m*d维的矩阵,x
k
是h
k
*d维的矩阵。将x
k
的第一列点乘x0的第一列,依次类推,得到计算出一个中间结果z
k 1
,它是一个三维的张量,维度分别为m、h
k
、d。将中间结果z
k 1
作为模型下一层的输入,用h
k
1个尺寸为m*h
k
的卷积核生成下一层隐层的状态,z
k 1
的每一层生成x
k 1
个中间结果中的一行,即featuremap 1、
…
、featuremaph
k 1
,这里的特征图是一个向量,而不是一个矩阵。这里可以用卷积神经网络的特征图进行理解,即通过卷积核来提取特征的过程。只是这里的卷积图有些特殊:将一个m*d的矩阵直接压平成1*d。最终生成x
k 1
个中间结果(x1、x2、
…
、x
k
),分别对中间结果(x1、x2、
…
、x
k
)中的每个特征图都进行sum pooling(求和池化)。这里的sum pooling和max pooling(最大值池化)类似,都是为了保留提取到的高阶特征,求和是为了将特征进行叠加。计算之后串联所有的求和池化结果,通过sigmoid函数(s型生长曲线)输出。
141.二、xdeepfm相比其它模型,有两个明显的优势:一是xdeepfm保留了特征之间的低阶交互和高阶交互的信息。二是xdeepfm保留了隐性特征间交互信息和显性特征交互信息。
142.三、训练xdeepfm的经验积累:对于隐藏层,使用三层200
‑
400
‑
100的结构设计;使用线性整流函数(rectified linear unit,relu)作为激活函数;在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃,这一过程可被称为dropout。
143.在一个示例中,如图5所示,其示例性示出了一种识别互联网服务设备流程的示意图。图5所示识别互联网服务设备流程分为三个部分:原始数据积累部分、数据特征工程部分、模型训练和评估部分。
144.原始数据积累部分:将线上实时请求的日志数据接入hdfs进行存储。考虑到存储成本和后续计算效率,基于hive sql对日志关键信息提取,对于冗余数据进行丢弃。
145.数据特征工程部分:根据存储在hdfs中的原始特征的数据特性,进行合适的特征处理方法。这里选用spark和tensorflow进行特征工程,具体分工如下:非embedding的常规特征工程方法,基于spark计算引擎进行计算,并将结果存储在hdfs;基于embedding的深度学习特征工程方法,基于tensorflow计算引擎进行计算,并将结果存储在hdfs。
146.模型训练和评估部分:首先基于hive sql将特征从hdfs中读出到本地。然后基于tensorflow进行建模。最后基于内置的数学评估方法进行模型评估,评估结果分为两种情况:一是评估指标为正向,则将模型推到线上,进行a/b test。如果a/b test也显示各项业务指标正向,则接入全部流量进行线上正式使用。二是评估指标为负向,则重新对模型进行训练,直到模型效果符合预期。
147.步骤314,向互联网服务设备传输多媒体资源。
148.可选地,多媒体资源包括多媒体广告。
149.步骤315,获取多媒体资源在互联网服务设备上的用户反馈数据。
150.可选地,用户反馈数据包括多媒体广告的曝光率和点击率。
151.在一个示例中,如图6所示,其示例性示出了一种互联网服务设备的运营数指标折线图。图6中广告成功曝光率折线61与广告点击率折线62,示出了不同模型下ott设备识别的业务效果对比结果。从广告成功曝光率折线61来看,本技术实施例提供的互联网服务设备识别模型相比其它技术方案,广告成功曝光率平均提高31.91%;从广告点击率折线62来看,本技术实施例提供的互联网服务设备识别模型相比其它技术方案,广告点击率平均提高204.93%。
152.综上所述,本技术实施例提供的技术方案,构建基于神经网络构建的互联网服务设备识别模型,通过互联网服务设备识别模型将高维离散的设备特征进行线性嵌入处理为低维稠密的整体特征,在保证设备特征信息完整性的前提下更加高效地表征设备特征并减少运算量,然后对整体特征作非线性的向量积处理,得到表征各特征间关联性的交叉特征,充分挖掘待识别设备的特征信息,进而输出待识别设备为互联网服务设备的概率,通过模型输出的概率确定待识别设备是否为互联网服务设备,提升识别互联网服务设备的效率的同时,还提升了识别准确率,提升模型在多场景下的复用性。
153.请参考图7,其示出了本技术一个实施例提供的互联网服务设备识别模型的训练方法以及互联网服务设备识别方法的流程图。该方法可应用于计算机设备中,所述计算机设备是指具备数据计算和处理能力的电子设备,如各步骤的执行主体可以是图1所示的应用程序运行环境中的服务器20。该方法可以包括以下几个步骤(701~714)。
154.步骤701,获取设备日志数据。
155.步骤702,对设备日志数据进行特征提取处理,得到设备特征数据。
156.设备数据包括与至少一种设备特征关联的特征数据。
157.对于至少一种设备特征中的目标设备特征,获取与目标设备特征关联的目标特征数据;确定与目标特征数据对应的目标映射方法;根据目标映射方法,将目标特征数据映射为表征目标设备特征的特征值。
158.使用spark(基于mapreduce算法实现的分布式计算引擎)或hive sql从hdfs中提
取设备历日志数据。主要用处是:构建正负样本集和构建基础画像特征。具体包括如下两个方面。
159.一、设备行为特征提取。使用spark或hive(基于hadoop构建的一套数据仓库分析系统)sql(structured query language,结构化查询语言)从hdfs中提取设备历史行为数据和历史线上反馈数据。主要用处是:构建正负样本集和构建设备基础画像特征。
160.二、设备画像提取。从自建的标签系统,提取出“设备画像”,具体维度如下:设备画像包括:设备基础属性、设备基础属性、地理位置属性、软件使用偏好等。例如,设备基础属性包括年龄、性别等;设备基础属性包括手机品牌、手机rom大小等;地理位置属性包括设备常在地省份、城市等;软件使用偏好包括近一个月使用社交类应用的次数。
161.步骤703,对设备特征数据进行数据清洗拼接处理。
162.原始特征在上报过程中,容易出现字段错位、数据值异常等情况,为了保证后期模型训练的有效性,需要做数据清洗,并对清洗完成的数据进行拼接。
163.步骤704,对清洗拼接后的设备特征数据进行特征提炼处理,生成设备特征向量。
164.原始特征需要经过提炼才能更好的表达隐藏信息。比如使用频率分布代替次数分布。
165.基于至少一种设备特征的特征值,得到与设备数据对应的特征值;基于特征值,生成设备特征向量。设备特征向量是设备特征信息的数学表现形式。
166.将设备运行向量和设备画像向量拼接成一个高维向量,作为模型的输入。具体做法是将所有特征按列拼接成一个高维向量。在特征处理过程中,除了使用常用的特征工厂方法外,本文将对“无线局域网络”和“应用程序”特征进行了合理处理,处理方法为包括:基于mst
‑
cnn深度学习网络,对设备的无线局域网连接轨迹数据进行嵌入处理,捕捉设备连接的无线局域网的特征信息;基于list
‑
embedding(列表嵌入)方式,对设备安装的不同类目应用的流量使用行为序列进行嵌入提取,比如使用社交类型应用的使用轨迹的嵌入特征,获得低维稠密的设备行为特征。
167.步骤705,将各设备的设备特征向量以及设备标签作为训练样本,对互联网服务设备识别模型进行模型训练,得到训练后的互联网服务设备识别模型。
168.基于已有标签的正负样本,使用tensorflow实现pnn算法进行模型训练。在模型训练中,本文积累了如下关键参数的设置经验:
169.对于隐藏层,使用三层200
‑
400
‑
100的结构设计;使用线性整流函数(rectified linear unit,relu)作为激活函数;在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃,这一过程可被称为dropout。
170.步骤706,对训练后的互联网服务设备识别模型进行线下评估。
171.线下模型评估选用业内公认合理指标:auc(area under curve)被定义为roc曲线(receiver operating characteristic curve,受试者工作特征曲线)下与坐标轴围成的面积。选择auc有如下指标优势:
172.auc指标本身和模型预测绝对值无关,只关注排序效果,更加贴近实际业务的需要。
173.auc的计算方法同时考虑了学习器对于正例和负例的分类能力,在样本不平衡的情况下,依然能够对分类器做出合理的评价。
174.步骤707,判断线下评估中模型输出结果是否符合线下评估条件。
175.若是,则执行步骤708,否则从步骤705开始执行。
176.步骤708,对通过线下评估的互联网服务设备识别模型进行线上评估。
177.步骤709,判断线上评估中模型输出结果是否符合线上评估条件。
178.若是,则执行步骤710,否则从步骤705开始执行。
179.首先基于hive sql将特征从hdfs中读出到本地。然后基于tensorflow进行建模。最后基于内置的数学评估方法进行模型评估,评估结果分为两种情况:
180.a)评估指标正向,则将模型推到线上,进行a/b test。如果a/b test也显示各项业务指标正向,则接入全部流量进行线上正式使用。
181.b)评估指标负向,则重新对模型进行训练,直到模型效果符合预期。
182.当模型线下评估和模型线上评估有任何一个不合格时,会对模型重新训练,直到评估的指标均通过为止。模型调整的方向:
183.a)选择不同时间窗口、不同下钻维度的正负样本
184.b)对模型关键参数进行网格搜索,选择效果最优的参数组合
185.在一个示例中,如图8所示,其示例性示出了一种评估互联网服务设备识别模型的数据指标折线图。通过图8中的线下评估中受试者工作特征曲线下面积值折线81与线上评估中受试者工作特征曲线下面积值折线82,可以看出不同识别方案下,互联网服务设备识别效果的对比结果。从线下评估中受试者工作特征曲线下面积值折线81来看,本技术提供的互联网服务设备识别模型相比其它两种技术方案,平均提高21.65%;从线上评估中受试者工作特征曲线下面积值折线82来看,本技术提供的互联网服务设备识别模型相比其它两种技术方案,平均提高22.01%。
186.步骤710,对互联网服务设备识别模型进行固化处理。
187.基于tensorflow的saver()方法固化训练好的模型,共产生4个文件。checkpoint文本文件,记录了模型文件的路径信息列表;model.ckpt.data文件,记录网络权重信息;model.ckpt.index.data和index是二进制文件,保存模型中的变量权重信息。
188.步骤711,将固化后的互联网服务设备识别模型部署至到线上服务中。
189.客户端在调用服务接口时,服务端会调起固化好的模型,然后拉取线上decache中的用户特征和用户实时特征后,返回预测结果。
190.步骤712,线上服务调用互联网服务设备识别模型。
191.步骤713,获取互联网服务设备上的反馈数据。
192.步骤714,根据反馈数据,对互联网服务设备识别模型进行更新。
193.用户在客户端对模型预测结果的反馈,会作为客户端日志进行保存。
194.在一个示例中,如图9所示,其示例性示出了一种设备识别技术方案的技术架构示意图。上述设备识别技术方案包括在线部分和离线部分两部分。
195.在线部分:服务器会定时计算设备的设备特征向量;根据预设条件,定时更新设备特征数据,可根据不同业务的要求,设置数据的更新频率,相同类型但更新频率不一样的数据,会同时存储多份;然后,根据业务需要,对设备特征数据进行过滤和提炼,以保证入模特征数据的质量;在当前业务场景下,产出实时的设备特征向量,并输入到已训练好的互联网服务设备识别模型中;模型自动输出当前设备为互联网服务设备的概率;最后,统计设备对
多媒体广告的反馈数据,记录模型输出“高概率ott设备”对线上ott类型广告的反馈。“对线上ott类型广告的反馈”是指模型输出高概率ott设备,对曝光的ott类型广告的反馈行为,包括:广告是否正常曝光、是否点击广告等。
196.离线部分:
197.存储设备对多媒体广告的历史反馈数据,将“模型输出的高概率ott设备的线上行为数据”存储在hdfs上;然后进行设备日志数据统计,定时离线统计设备在不同时段(近半年、近三个月、近一个月、近1周、近3天)的线上特征;通过深度学习预训练,产出设备运行特征;基于设备运行特征,拼接生成设备运行特征向量。
198.基于存储在相关表中的设备画像数据,进行设备特征提取,构建出丰富的设备画像,具体包括:设备基础属性、设备网络属性、设备行为属性;然后进行基础属性特征提取、设备网络属性特征提取、设备广告反馈特征提取;进一步进行设备在不同周期的画像数据提取;拼接生成设备画像特征向量。
199.对设备运行特征向量以及设备画像特征向量作线形拼接处理,生成设备特征向量;在获取多个设备特征向量后,进行模型训练;作模型线下评估处理;在模型通过线下评估处理后,作模型线上评估处理;在模型通过线上评估处理后,进行模型固化;将固化后的模型步骤在线上服务中。
200.本技术实施例提供的技术方案,具备很强的复用性:首先,更换正样本所属类型,比如“流量作弊高风险设备识别的样本”,然后服务端累计对应日志数据,最后使用相同的特征拼接、特征处理、模型训练的方法产出结果,本技术实施例对此不作限定。
201.综上所述,本技术实施例提供的技术方案,构建基于神经网络构建的互联网服务设备识别模型,通过互联网服务设备识别模型将高维离散的设备特征进行线性嵌入处理为低维稠密的整体特征,在保证设备特征信息完整性的前提下更加高效地表征设备特征并减少运算量,然后对整体特征作非线性的向量积处理,得到表征各特征间关联性的交叉特征,充分挖掘待识别设备的特征信息,进而输出待识别设备为互联网服务设备的概率,通过模型输出的概率确定待识别设备是否为互联网服务设备,提升识别互联网服务设备的效率的同时,还提升了识别准确率,提升模型在多场景下的复用性。
202.此外,通过线上评估与线下评估的方式对互联网服务设备识别模型进行验证,并且使用反馈数据对互联网服务设备识别模型进行更新,进一步提升了互联网服务设备识别模型输出概率的准确性,进而提升互联网服务设备识别的准确性。
203.下述为本技术装置实施例,可用于执行本技术方法实施例。对于本技术装置实施例中未披露的细节,请参照本技术方法实施例。
204.请参考图10,其示出了本技术一个实施例提供的设备识别装置的框图。该装置具有实现上述设备识别方法的功能,所述功能可以由硬件实现,也可以由硬件执行相应的软件实现。该装置可以是计算机设备,也可以设置在计算机设备中。该装置1000可以包括:特征获取模块1010、特征嵌入模块1020、特征交叉模块1030以及设备识别模块1040。
205.特征获取模块1010,用于获取待识别设备的设备特征信息。
206.特征嵌入模块1020,用于对所述设备特征信息进行特征嵌入处理,生成所述待识别设备的整体特征信息,所述整体特征信息的维度小于或者等于所述设备特征信息的维度。
207.特征交叉模块1030,用于基于所述整体特征信息,确定所述待识别设备的交叉特征信息,所述交叉特征信息表征所述待识别设备的不同设备特征之间的关联性。
208.设备识别模块1040,用于在所述整体特征信息与所述交叉特征信息符合目标条件的情况下,确定所述待识别设备为互联网服务设备。
209.在示例性实施例中,所述设备特征信息包括设备特征的特征值,所述特征嵌入模块1020包括:特征值提取单元、特征值嵌入单元以及向量拼接单元。
210.特征值提取单元,用于对于任一设备特征,在所述设备特征信息中提取对应于所述设备特征的特征值。
211.特征值嵌入单元,用于对所述目标设备特征的特征值进行特征值嵌入处理,生成所述目标设备特征对应的特征嵌入向量,所述特征嵌入向量包括表征所述目标设备特征的特征嵌入值,所述特征嵌入值的数量小于或者等于所述特征值的数量。
212.向量拼接单元,用于对所述设备特征对应的特征嵌入向量进行线性拼接处理,生成所述待识别设备的整体特征嵌入向量,所述整体特征嵌入向量为所述整体特征信息的数学表现形式。
213.在示例性实施例中,所述特征交叉模块1030,包括:交叉特征值生成单元以及交叉特征向量生成单元。
214.交叉特征值生成单元,用于对所述设备特征对应的特征嵌入向量进行特征交叉处理,生成交叉特征值,所述交叉特征值表征所述待识别设备的各设备特征中两两之间的关联性。
215.交叉特征向量生成单元,用于基于所述交叉特征值,生成所述待识别设备的交叉特征嵌入向量,所述交叉特征嵌入向量为所述交叉特征信息的数学表现形式。
216.在示例性实施例中,所述设备识别模块1040,包括:特征深度提取单元以及设备识别单元。
217.特征深度提取单元,用于对所述整体特征信息与所述交叉特征信息进行深度特征提取处理,确定所述待识别设备为所述互联网服务设备的概率。
218.设备识别单元,用于在所述概率大于或者等于概率阈值的条件下,确定所述待识别设备为所述互联网服务设备。
219.在示例性实施例中,所述特征获取模块1010,包括:设备数据获取单元、数据映射单元以及设备特征向量生成单元。
220.设备数据获取单元,用于获取所述待识别设备的设备数据。
221.数据映射单元,用于对所述设备数据进行数据映射处理,生成与所述设备数据对应的特征值,所述特征值表征所述待识别设备的所述至少一种设备特征。
222.设备特征向量生成单元,用于基于所述特征值,生成设备特征向量,所述设备特征向量是所述设备特征信息的数学表现形式。
223.在示例性实施例中,所述设备数据包括与所述至少一种设备特征关联的特征数据,所述数据映射单元,包括:特征数据获取子单元、映射方法确定子单元、数据映射子单元以及特征值汇总子单元。
224.特征数据获取子单元,用于对于所述至少一种设备特征中的目标设备特征,获取与所述目标设备特征关联的目标特征数据。
225.映射方法确定子单元,用于确定与所述目标特征数据对应的目标映射方法。
226.数据映射子单元,用于根据所述目标映射方法,将所述目标特征数据映射为表征所述目标设备特征的特征值。
227.特征值汇总子单元,用于基于所述至少一种设备特征的特征值,得到与所述设备数据对应的特征值。
228.在示例性实施例中,所述装置1000还包括:资源传输模块以及数据反馈模块。
229.资源传输模块,用于向所述互联网服务设备传输多媒体资源。
230.数据反馈模块,用于获取所述多媒体资源在所述互联网服务设备上的用户反馈数据。
231.综上所述,本技术实施例提供的技术方案,通过特征嵌入的方式,将高维离散的设备特征进行转换为低维稠密的整体特征,在保证设备特征信息完整性的前提下更加高效地表征设备特征并减少运算量,然后确定整体特征中各特征间的交叉特征,充分挖掘待识别设备的特征信息,进而从整体特征与交叉特征两方面去确定待识别设备是否为互联网服务设备,提升识别互联网服务设备的效率的同时,还提升了识别准确率。
232.需要说明的是,上述实施例提供的装置,在实现其功能时,仅以上述各功能模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将设备的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。另外,上述实施例提供的装置与方法实施例属于同一构思,其具体实现过程详见方法实施例,这里不再赘述。
233.请参考图11,其示出了本技术一个实施例提供的计算机设备的结构框图。该计算机设备可以是服务器,以用于执行上述设备识别方法。具体来讲:
234.计算机设备1100包括中央处理单元(central processing unit,cpu)1101、包括随机存取存储器(random access memory,ram)1102和只读存储器(read only memory,rom)1103的系统存储器1104,以及连接系统存储器1104和中央处理单元1101的系统总线1105。计算机设备1100还包括帮助计算机内的各个器件之间传输信息的基本输入/输出系统(i/o(input/output)系统)1106,和用于存储操作系统1113、应用程序1114和其他程序模块1112的大容量存储设备1107。
235.基本输入/输出系统1106包括有用于显示信息的显示器1108和用于用户输入信息的诸如鼠标、键盘之类的输入设备1109。其中显示器1108和输入设备1109都通过连接到系统总线1105的输入输出控制器1110连接到中央处理单元1101。基本输入/输出系统1106还可以包括输入输出控制器1110以用于接收和处理来自键盘、鼠标、或电子触控笔等多个其他设备的输入。类似地,输入输出控制器1110还提供输出到显示屏、打印机或其他类型的输出设备。
236.大容量存储设备1107通过连接到系统总线1105的大容量存储控制器(未示出)连接到中央处理单元1101。大容量存储设备1107及其相关联的计算机可读介质为计算机设备1100提供非易失性存储。也就是说,大容量存储设备1107可以包括诸如硬盘或者cd
‑
rom(compact disc read
‑
only memory,只读光盘)驱动器之类的计算机可读介质(未示出)。
237.不失一般性,计算机可读介质可以包括计算机存储介质和通信介质。计算机存储介质包括以用于存储诸如计算机可读指令、数据结构、程序模块或其他数据等信息的任何
方法或技术实现的易失性和非易失性、可移动和不可移动介质。计算机存储介质包括ram、rom、eprom(erasable programmable read only memory,可擦除可编程只读存储器)、eeprom(electrically erasable programmable read only memory,电可擦可编程只读存储器)、闪存或其他固态存储其技术,cd
‑
rom、dvd(digital video disc,高密度数字视频光盘)或其他光学存储、磁带盒、磁带、磁盘存储或其他磁性存储设备。当然,本领域技术人员可知计算机存储介质不局限于上述几种。上述的系统存储器1104和大容量存储设备1107可以统称为存储器。
238.根据本技术的各种实施例,计算机设备1100还可以通过诸如因特网等网络连接到网络上的远程计算机运行。也即计算机设备1100可以通过连接在系统总线1105上的网络接口单元1111连接到网络1112,或者说,也可以使用网络接口单元1111来连接到其他类型的网络或远程计算机系统(未示出)。
239.所述存储器还包括计算机程序,该计算机程序存储于存储器中,且经配置以由一个或者一个以上处理器执行,以实现上述设备识别方法。
240.在示例性实施例中,还提供了一种计算机可读存储介质,所述存储介质中存储有至少一条指令、至少一段程序、代码集或指令集,所述至少一条指令、所述至少一段程序、所述代码集或所述指令集在被处理器执行时以实现上述设备识别方法。
241.可选地,该计算机可读存储介质可以包括:rom(read only memory,只读存储器)、ram(random access memory,随机存取记忆体)、ssd(solid state drives,固态硬盘)或光盘等。其中,随机存取记忆体可以包括reram(resistance random access memory,电阻式随机存取记忆体)和dram(dynamic random access memory,动态随机存取存储器)。
242.在示例性实施例中,还提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中。计算机设备的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行上述设备识别方法。
243.应当理解的是,在本文中提及的“多个”是指两个或两个以上。“和/或”,描述关联对象的关联关系,表示可以存在三种关系,例如,a和/或b,可以表示:单独存在a,同时存在a和b,单独存在b这三种情况。字符“/”一般表示前后关联对象是一种“或”的关系。另外,本文中描述的步骤编号,仅示例性示出了步骤间的一种可能的执行先后顺序,在一些其它实施例中,上述步骤也可以不按照编号顺序来执行,如两个不同编号的步骤同时执行,或者两个不同编号的步骤按照与图示相反的顺序执行,本技术实施例对此不作限定。
244.以上所述仅为本技术的示例性实施例,并不用以限制本技术,凡在本技术的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本技术的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。