1.本发明涉及自然语言处理技术领域,尤其涉及一种基于非结构化医疗文本提取疾病预后协变量的结构化数据的方法、系统、智能终端和计算机可读存储介质。
背景技术:
2.电子病历是真实世界大数据中质量较高的部分。电子病历从21世纪初开始兴起,其使用率在2008年仅为9%,而到2015年已经上升到96%。由于电子病历代替了传统的手写病历的方式,使得电子病历在各种类型的真实世界数据中所占比例较大,相较互联网等来自多媒体的真实世界数据,电子病历数据的质量更高。截止到2018年,仅上海市卫生健康委员会健康档案数据平台已有超过一千万份住院病历,十亿份急诊病历。电子病历主要包括病例首页、入院记录、出院小结及各类影像学图片等。很多重要的临床信息都被记录在非结构化的文本中,如现病史、体格检查和病程记录等,临床医生花费了大量的时间来记录,这部分信息所占比重大,据专家估计这部分信息占总量的80%以上,但利用率低,无法直接用于数据统计分析。
3.目前自然语言处理技术(natural language processing,nlp)已经被广泛应用于从非结构化的电子病历中提取信息,运用nlp技术将非结构化的文本转换为结构化数据能够有效减少人工阅读文本提取数据的时间,提高了非结构化数据的可用性,从而可以实现大规模文本的自动处理。鉴于电子病历由不同的部分组成,每个部分内容结构不同,数据提取的方法不同。目前国内外,对于如何将医疗文本直接转化为可以用于数据统计分析的结构化数据库的相关方法研究及应用很少,针对中文医疗文本的信息提取研究,命名实体识别方面的工作较多,也有相关专利,而基于此的应用主要集中在基于识别后的实体构建知识图谱,开发医患对话机器等场景。现有技术中还缺少一种关于预后影响因素的结构化数据库的构建方法,这种结构化数据库中数据能够直接用于数据分析,以支持临床预后影响因素分析、预后模型构建等应用场景。而在这一应用场景中,现有的命名实体识别方法是无法直接应用的。
技术实现要素:
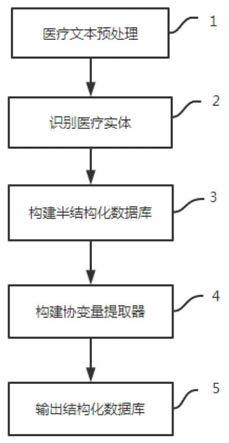
4.为了克服上述技术缺陷,本发明的第一个方面在于提供一种基于非结构化医疗文本提取疾病预后协变量的结构化数据的方法,包括以下步骤:
5.步骤s1:预处理非结构化医疗文本:获取非结构化医疗文本,并通过正则表达式去除非结构化医疗文本中的包含否定词和/或阴性词的文本,然后采用bio标注体系对非结构化医疗文本进行标注;
6.步骤s2:通过ner模型识别医疗实体:所述ner模型为基于ernie预训练模型、膨胀卷积神经网络和条件随机场的医疗实体识别模型,首先将标注后的医疗文本通过 ernie预训练模型转换为字向量,然后将字向量输入到膨胀卷积神经网络中以得到每个字的标签得分,最后将每个字的标签得分(即膨胀卷积神经网络的输出)输入到条件随机场中以得到每
个字的医疗实体类别;
7.以往对于ner模型的研究集中在人名、地名和机构名等方面的研究,对于医疗实体的研究较少,医疗实体具有自身领域独特的特征,分类较多,且同一医疗实体的表述众多,无法通过编写词典库穷尽,因此需要通过深入挖掘上下文之间的关系来找出特定的实体,而深度学习能够通过学习到医疗文本深层次的隐含特征来进行命名实体的识别。现有技术中的word2vec模型不具备根据下游任务微调的能力,该字向量不会随着上下文语境的变化而变化,因此在对于某些类别的实体,用word2vec作为字嵌入层时效果会受到影响。而ernie通过微调,可以自行根据上下文的不同来调整字向量,能够更好的表达其在具体语境中的含义,解决了一词多义的问题,使得ner模型的效果得到提升。在使用同一神经网络时,ernie的效果要好于现有技术中的bert模型,因为ernie在预训练时采用更多的优质的中文语料库有关;而在使用同一预训练模型时,idcnn的效果要优于现有技术中的bilstm模型,且idcnn优于可以并行化训练,速度要明显快于现有技术中的bilstm模型;
8.步骤s3:构建半结构化数据库:根据识别出的医疗实体类别和实体名称,构建半结构化数据库,所述半结构化数据库包括患者编号、医疗实体类别和实体名称;
9.步骤s4:目标医疗实体的存在判断:利用半结构化数据库,训练ernie深度学习模型以构建协变量提取器,向协变量提取器中输入目标医疗实体的标准名称,通过ernie 深度学习模型将目标医疗实体的标准名称与半结构化数据库中的实体名称进行相似度比对,通过逻辑回归函数判断目标医疗实体的标准名称与实体名称是否相似,如果相似,则表示匹配,代表该目标协变量存在于非结构化医疗文本中,则输出结果为“1”,以疾病实体为例,则“1”表示患者患有该医疗实体名称对应的疾病;如果不相似,则表示不匹配,代表该目标协变量不存在于非结构化医疗文本中,则输出结果为“0”,以疾病实体为例,则“0”表示该患者未患有该医疗实体名称对应的疾病;ernie深度学习模型是一个整体,逻辑回归是其中的一步;
10.传统的文本相似度识别模型,首先通过计算出相似度,然后通过设定阈值或者排序来确定文本是否匹配,这种方法往往受人为因素干扰,阈值的大小的设定对结果影响很大。而本研究提出通过监督学习,利用文本相似度匹配这一技术来实现实体的统一,通过比较几种深度学习模型的效果,能够实现较为精确地提取出所需的协变量。此外,本技术中的ernie采用了孪生网络,使得两个实体所处的网络参数共享,不容易造成过拟合,计算量小,耗时短,对计算机的性能要求低,因此取得的效果由于现有技术中的bert 模型;
11.步骤s5:构建结构化数据库:在所述协变量提取器中依次输入目标医疗实体的名称之后,所述协变量提取器就会构建一个结构化数据库,所述结构化数据库包括患者编号、目标医疗实体的标准名称及其对应的输出结果。
12.本技术中的所述“标准名称”主要指国际公认的标准名称和编码字典,例如,国际疾病编码字典icd10。
13.对于目标医疗实体的标准名称是指需要进行结构化处理的目标医疗实体,例如医生想知道哪些人患了心梗,则目标实体的标准名称就是“心肌梗塞”。
14.进一步地,在步骤s4中,所述ernie深度学习模型采用12层transformer,隐藏层大小为768,多头注意力机制为12头,优化器为adam,设置学习率为2e
‑
05,一次训练所选取的样本数(batch size)为32,训练迭代10次。
15.进一步地,在步骤s4中,所述相似度比对的方法包括下述步骤:利用孪生网络结构,首先将目标医疗实体的标准名称与实体名称这两个实体分别送入ernie,ernie的参数对这两个实体共享,得到两个实体的句向量,随后送入汇聚层,采用平均汇聚方式对句向量进行特征提取和压缩,得到u和v,最后将u、v、|u
‑
v|拼接后送入全连接层,将这两个实体进行相似度比对,通过逻辑回归函数判断两个实体是否相似,如果相似,则表示匹配,代表该目标协变量存在于非结构化的原始医疗文本中;如果不相似,则表示不匹配,代表该目标协变量不存在于非结构化的原始医疗文本中。
16.进一步地,所述医疗实体的类别包括疾病实体、药物实体、手术实体、影像学检查实体和症状实体。
17.进一步地,所述非结构化医疗文本为出院小结。
18.本技术的第二个方面提供一种基于非结构化医疗文本提取疾病预后协变量的结构化数据的系统,包括预处理模块、识别模块、半结构化数据库构建模块、比对模块和结构化数据库构建模块;
19.所述预处理模块用于预处理非结构化医疗文本:获取非结构化医疗文本,并通过正则表达式去除非结构化医疗文本中的包含否定词和/或阴性词的文本,然后采用bio标注体系对非结构化医疗进行标注;
20.所述识别模块用于通过ner模型识别医疗实体:所述ner模型为基于ernie预训练模型、膨胀卷积神经网络和条件随机场的医疗实体识别模型,首先将标注后的医疗文本通过ernie预训练模型转换为字向量,然后将字向量输入到膨胀卷积神经网络中以得到每个字的标签得分,最后将每个字的标签得分输入到条件随机场中以得到每个字的医疗实体类别;
21.所述半结构化数据库构建模块用于构建半结构化数据库:根据识别出的医疗实体类别和实体名称,构建半结构化数据库,所述半结构化数据库包括患者编号、医疗实体类别和实体名称;
22.所述比对模块用于判断目标医疗实体是否存在于非结构化医疗文本中:利用半结构化数据库,训练ernie深度学习模型以构建协变量提取器,向协变量提取器中输入目标医疗实体的标准名称,通过ernie深度学习模型将目标医疗实体的标准名称与半结构化数据库中的实体名称进行相似度比对,通过逻辑回归函数判断目标医疗实体的标准名称与实体名称是否相似,如果相似,则表示匹配,代表该目标协变量存在于非结构化医疗文本中,则所述协变量提取器输出结果为“1”,以疾病实体为例,则“1”表示患者患有该医疗实体名称对应的疾病;如果不相似,则表示不匹配,代表该目标协变量不存在于非结构化医疗文本中,则所述协变量提取器输出结果为“0”,以疾病实体为例,则“0”表示该患者未患有该医疗实体名称对应的疾病;
23.所述结构化数据库构建模块用于构建结构化数据库:在所述协变量提取器中依次输入目标医疗实体的名称之后,所述协变量提取器就会构建一个结构化数据库,所述结构化数据库包括患者编号、目标医疗实体的标准名称及其对应的输出结果。
24.本技术的第三个方面提供一种智能终端,包括:
25.存储器,所述存储器用于存储可执行程序代码;以及
26.处理器,所述处理器用于读取所述存储器中存储的可执行程序代码以执行上述基
于非结构化医疗文本提取疾病预后协变量的结构化数据的方法。所述智能终端包括但不限于pc、便携计算机、移动终端等具有显示和处理功能的设备。
27.本技术的第四个方面提供一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序指令,所述计算机程序指令被处理器执行时,实现上述基于非结构化医疗文本提取疾病预后协变量的结构化数据的方法。所述计算机可读存储介质包括但不限于:u盘、移动硬盘、只读存储器(rom,read
‑
onlymemory)、随机存取存储器(ram, randomaccessmemory)、磁碟或者光盘等各种可以存储程序代码的介质。
28.采用了上述技术方案后,与现有技术相比,具有以下有益效果:
29.本发明从不可直接用于统计分析的中文医疗文本中提取出可用于统计分析的结构化数据库,提出了一种协变量提取方法及系统,帮助临床医生从病历文本中提取潜在的疾病预后影响因素,可应用于疾病预后影响因素分析或预测模型构建等场景。可以免除人工提取协变量的过程。本发明基本原理简单、易行、有效,无额外特殊硬件、软件要求,具有较好的兼容移植性,可在各类平台上方便嵌套、开发和维护。适合各类医疗人员,仅需输入协变量的名称即可完成结构化数据的提取。
30.本技术的方法在数据处理的不同阶段,均采用了效果最好的模型进行数据提取,提高了数据库构建的准确率。此外,与人工阅读病历,并手动提取病历信息相比,本技术极大提高了数据库构建的效率。目前世界范围内均在构建医学相关的大型结构化数据库,其中一些公共数据库可供直接分析使用,然而这些数据库的构建过程较为繁琐,很多数据库需要专业人员阅读并手动输入相关信息。而本技术在提取结构化数据的过程中全部由计算机自动化实现,且可以通过协变量提取器根据后续的实际需要提取特定协变量。
附图说明
31.图1为从非结构化医疗文本中提取疾病预后协变量的结构化数据的方法流程图;
32.图2为采用bio标注体系对出院小结中的医疗实体进行标注的示例;
33.图3为ner模型的框架;
34.图4为bert和ernie遮盖模式示意图;
35.图5为用于文本的idcnn模型;
36.图6为无crf层的ner模型的预测结果;
37.图7为有crf层的ner模型的预测结果;
38.图8为正确的医疗实体类别的标注结果;
39.图9为ernie深度学习模型的文本相似度匹配过程原理示意图;
40.图10为缺血性脑卒中患者预后协变量的相关性热力图。
具体实施方式
41.以下结合附图与具体实施例进一步阐述本发明的优点。本领域技术人员应当理解,下面所具体描述的内容是说明性的而非限制性的,不应以此限制本发明的保护范围。
42.实施例 基于电子病历中的出院小结,构建缺血性脑卒中预后影响因素的结构化数据库
43.本实施例中所采用的数据主要来源于上海市长海医院2009至2019年共计6053例
标注体系,b代表一个实体的起始,i代表一个实体除起始意外的后续部分,o代表非实体部分。b和i后面将会跟随该实体所属类别,以“小明突发脑卒中,感觉恶心、呕吐,在进行mri检查后,行动脉取栓术,开始服用阿司匹林。”为例,标注示例见图2。
53.数据标注完成后,我们将数据集按3:1:1的比例随机分成三份,分别为训练集、验证集和测试集,各数据集的实体分布如表2所示。训练集用来训练和拟合ner模型(即 ernie idcnn crf模型),验证集用来调整模型的超参数,测试集用来评估模型的性能。
54.表2 数据集的医疗实体类别分布
55.数据集疾病药物手术影像学检查症状训练集3975230137121441647验证集1517993112839661测试集14371059114821679
56.以某一缺血性脑卒中患者的出院小结为例:
[0057]“出院诊断:1.后循环缺血;2.高血压病3级(很高危组);3.2型糖尿病。住院天数: 10天。入院情况:因“头晕伴视物旋转3小时。”门诊拟“头晕”于2015
‑
08
‑
04收入院。2015
‑8‑
4 头颅ct:脑干、两侧基底节丘脑区及半卵圆中心多发腔隙性脑梗塞,部分软化。诊疗经过:治疗情况:入院后完善检查,行头颅mri检查及脑血管造影。予双抗抗血小板、阿托伐他汀调脂、疏血通及银杏达莫改善循环、长春西汀营养神经治疗。出院情况:患者目前病情稳定,一般情况良好,较入院时有改善”。
[0058]
其中,“后循环缺血”、“高血压病3级(很高危组)”、“2型糖尿病”、“腔隙性脑梗塞”为疾病实体;
[0059]
其中,“阿托伐他汀”、“疏血通”、“银杏达莫”、“长春西汀”为关注的药物实体;
[0060]
其中,“脑血管造影”为手术实体;
[0061]
其中,“ct”为影像学检查实体;
[0062]
其中,“头晕”、“视物旋转”为症状实体。
[0063]
除了对命名实体的类别分为疾病、药物、手术、影像学检查和症状这五类之外,还需要对医疗实体的边界予以区分。如“后循环缺血”中,“后”这个字是疾病实体的开始,“血”这个字是疾病实体的结束。
[0064]
步骤2:识别医疗实体(主体:客户端)
[0065]
在对一定数量的医疗实体进行标注后,通过标注完成的缺血性脑卒中文本构建ner 模型(即预训练字嵌入联合膨胀神经网络联合条件随机场的医疗实体识别模型)进行训练,ner模型基本框架为基于知识增强的语义表示的预训练模型(enhanced representation from knowledge integration,ernie) 膨胀卷积神经网络模型(iterated dilated convolutional neural network,idcnn) 条件随机场(conditional random fields,crf)。即首先将文本信息通过基于知识增强的语义表示的预训练模型(ernie) 转换为字向量,随后输入到膨胀卷积神经网络中,膨胀卷积神经网络的输出再输入到条件随机场中以得到每个字的实体类别。从而识别出疾病实体、药物实体、手术实体、影像学检查实体和症状实体等。神经网络无法直接识别文字,而预训练模型的作用便是将文本里的字转换成神经网络所能识别的字向量,作为模型的初始输入。该步骤旨在基于训练构建的算法模型帮助计算机尽可能全面、准确地自动化获取原始医疗文本中蕴含的具有
潜在实际意义的实体名称。
[0066]
ner模型的框架如图3所示,首先将训练数据以句子为单位分为不同批次,每个批次包含64个句子,每个句子最大字数为128。对于每一个批次:第一步将一个批次的数据输入到预训练模型生成字向量;第二步将字向量输入到膨胀卷积神经网络层,得到每个字的所有标签得分;第三步将每个字的标签得分输入crf层计算网络输出;第四步将错误反馈,更新网络参数。
[0067]
ner模型(即ernie idcnn crf模型)的参数设置如下:学习率为1e
‑
5,dropout 值为0.5,梯度截断值为5,迭代次数100次。
[0068]
预训练模型(ernie)通过在海量的语料库中学习语言内部的语义和语法信息,比将每个字随机初始化生成一个向量的方法更能体现出每个字所带代表的特征。即基于知识增强的语义表示模型(ernie),通过知识增强,利用先验的语义知识来学习文本间的真实语义关系。ernie的模型结构由输入层、基于双向transformer的编码层及基于具体任务的输出层构成。ernie在进行mlm训练时采用三种不同的遮盖模式:第一种模式随机抽取15%的字进行遮盖;第二种模式通过分词获得中文短语,随机抽取部分短语进行遮盖;第三种模式根据先验知识选取语料库中的人名、地名等实体随机遮盖。用来训练的语料库也更多采用优质的中文语料库,如百度百科和中文维基百科等。
[0069]
如图4所示,对于“给予抗炎、止咳化痰对症治疗”这句话,bert训练的方式是遮盖字,“给予抗炎、止咳化[mask]对症[mask]疗”,bert通过局部共现能够训练出“痰”和“治”的文本表示,但是无法学习“化痰”、“治疗”相关的深一层的语义,而ernie通过遮盖词,“给予抗炎、止咳[mask][mask]对症[mask][mask]”,使模型能够建模出“化痰”和“治疗”的关系,学习到“化痰”是“治疗”的一种手段。此外在句子级别的文本关系训练中,ernie 采用对话语言模型,通过随机选择句子对问句或者答句进行替换来多次训练上下文句子的关联性特征。综上,ernie优于bert。
[0070]
cnn来源于感受野机制,如人类视觉系统的某一个神经元,只有当特定的信号出现时,该神经元才会兴奋。一般的cnn由卷积层、汇聚层和全连接层组成。卷积层的作用是用来进行特征提取,可以通过设置不同类型的卷积核来提取各种不同的特征。汇聚层用来进行特征的选择,由于在经过卷积层的特征提取后,只是减少了网络连接而没有减少神经元的个数,因此通过汇聚层可以有限地降低特征的数量。然而对于ner来说,每一个字都需要给出特定的类别标签,且上下文之间高度相关,而一般的cnn在进行卷积操作之后可能只得到原始数据的一小部分信息,而增加卷积核则会使参数过大,给模型的训练带来困难,且进行汇聚层之后也会造成信息的丢失。基于以上几个cnn在处理ner任务的缺点,可以通过在去掉汇聚层和不增加卷积核的情况下通过膨胀卷积核来增加感受野,使每个卷积核都能捕捉到较大范围的信息。在本技术中,如图5所示,a为传统的2层3*3卷积核,感受野为5,即第i层能感受到的上下文距离为2i 1,b为2层的膨胀系数为2的卷积核,感受野为7,即第i层能感受到的上下文距离为2
i 1
‑
1,可以看到传统的卷积核与上下文距离是线性相关,而膨胀的卷积核与上下文距离是指数相关,使得神经网络能够捕捉到长距离的文本关系。
[0071]
如果仅仅通过上一层的神经网络结构可能得到的预测结果如图6所示。图6中的结果显然这是一个错误的结果,“司”应该被标注为“i
‑
药物”,即只有每个实体的第一个字应标注为“b”,而剩余的实体部分都应标注为“i”,且不同类别的“i”不能相互连接,相邻的两
个“i”必须为同一类别。由于上一层的神经网络结构无法利用实体标签之间的关系,即无法排除“b
‑
药物/b
‑
药物”这种不合理的组合,而本技术通过crf能够很好得解决这一类问题,对标签序列之间的关系加以约束,结果如图7所示。
[0072]
crf是一类无向图模型,其中在ner中最常用的是一种线性链结构,用来进行序列标签的分析。对于给定的文字序列x={x1,x2…
,x
n
},x
i
表示第i个字符的特征向量,给定x对应的标签序列y={y1,y2,
…
,y
n
},γ(x)表示x的可能的标签,s表示势函数,θ为模型的参数,有
[0073][0074]
根据维特比算法,利用crf可以学习到上下文标签之间的关系,对输入的文字序列 x={x1,x2…
,x
n
}求得全局最优的标签序列。
[0075]
文本在经过idcnn网络后给每一个字的标注序列都进行了打分,取得分最高的作为预测的医疗实体的类别,正确的医疗实体标注结果应该如图8所示。
[0076]
步骤3:提取实体识别结果,构建脑卒中相关的半结构化数据库
[0077]
ernie idcnn crf模型的作用有两个:1.识别医疗实体;2.提取所有的医疗实体并构建半结构化数据库。通过上一步的实体识别,选择识别效果最优的模型,即 ernie idcnn crf来提取出所有的命名实体,构建出一个半结构化数据集,如表4所示。
[0078]
例如,根据步骤2识别出的医疗实体,为每一个患者构建一个半结构化数据库(表4)。半结构化数据库中,第1列为患者编号,第2至21列为预留的20个疾病列标目,设为“疾病1”、“疾病2”、
……“
疾病20”,第22至41列为预留的20个药物列标目,设为“药物1”、“药物2”、
……“
药物20”,第42至61列为预留的20个手术列标目,设为“手术1”、“手术2”、
……“
手术20”,第62至81列为预留的20个影像学检查列标目,设为“影像学检查1”、“影像学检查2”、
……“
影像学检查20”,第82至101列为预留的20个症状列标目,设为“症状1”、“症状2”、
……“
症状20”。具体每个实体需要预留的列数可以根据需要手动进行调整。
[0079]
表4 半结构化数据库
[0080][0081]
步骤4:构建协变量提取器以进行目标协变量的存在判定和提取(主体:客户端)
[0082]
由于电子病历的非结构化部分是由医生或者护理人员进行记录,医生在定义病人
的疾病、症状等方面都有自己独特的风格和术语,这将导致电子病历记录缺乏规范性和统一性的问题,同一种实体存在多种叫法,以疾病这一类别为例,有的疾病名称有多种叫法,类似心肌梗塞、心肌梗死和心梗等;有的用阿拉伯数字表示(2型糖尿病),有的则用罗马数字表示(ⅱ型糖尿病);有的用疾病的全称(短暂性脑缺血发作),有的用缩写 (tia)。类似的情况在手术、药物、影像学检查和药物等方面均有出现。故通过上一步构建的半结构数据仍然无法满足常规的统计分析需求,因此需要构建一个协变量提取器。本技术所述的协变量提取器是一个基于ernie的集成好的模型,包括ernie模型、深度监督学习和逻辑回归函数。以“心肌梗塞”为例,通过在协变量提取器中输入“心肌梗塞”,系统将自动匹配半结构化数据库中的疾病类别实体,从而判断目标协变量是否存在于非结构化的医疗文本中,如果匹配,则代表存在于非结构化的医疗文本中;如果不匹配,则代表不存在于非结构化的医疗文本中。
[0083]
利用半结构化数据库进行文本相似度匹配模型训练,开发一个协变量提取器。本技术通过训练有监督的深度文本匹配模型(即ernie深度学习模型)来构建一个协变量提取器,其模型的效果最佳。ernie深度学习模型采用12层transformer,隐藏层大小为 768,多头注意力机制为12头,优化器为adam,设置学习率为2e
‑
05,batch size为32,训练迭代10次。ernie深度学习模型的文本相似度匹配过程如图9所示:
[0084]
利用孪生网络结构,首先将两个实体(实体a和实体b)送入ernie,ernie的参数对两个实体共享,得到两个实体的句向量,随后送入汇聚层,采用平均汇聚方式对句向量进行特征提取和压缩,得到u和v,最后将u、v、|u
‑
v|拼接后送入全连接层,将输入的实体(假设为图9中“实体a”)与步骤3中构建的属于疾病类别的半结构化数据库中的医疗实体(假设为图9中“实体b”)进行相似度比对,通过逻辑回归(logistic)函数 (即图9中的分类器)判断两个实体是否相似,如果不相似,则表示不匹配,代表该目标协变量不存在于非结构化的原始医疗文本中,则协变量提取器就输出“0”,以疾病实体为例,则“0”就表示该患者未患有该医疗实体名称对应的疾病;如果相似,则表示匹配,代表该目标协变量存在于非结构化的原始医疗文本中,则协变量提取器就输出“1”,以疾病实体为例,则“1”表示患者患有该医疗实体名称对应的疾病。
[0085]
该协变量提取器模型采用监督学习进行训练,在通过上一步实体识别后得到半结构数据集的基础上,随机抽取了1000例患者的命名实体进行标注。标注示例如表5所示,第一列为数据编号,第二列为实体类别,第三列为病历中抽取的医疗实体,第四列为研究人员进行标注的标准医疗实体,第五列表示实体1与实体2是否匹配。
[0086]
表5 文本相似度匹配正样本
[0087]
no类别实体1实体2是否匹配1疾病脑梗死(大动脉粥样硬化型)脑梗塞是2疾病急性脑梗塞脑梗塞是3疾病高血压病1级极高危高血压是4疾病脑出血(左侧颞叶海绵状血管瘤脑出血是5疾病多发脑供血动脉硬化狭窄脑动脉狭窄是6手术右侧椎动脉夹层动脉瘤介入栓塞术动脉瘤介入栓塞术是7手术左大脑中动脉动脉瘤支架辅助弹簧圈栓塞术支架辅助弹簧圈栓塞术是8手术石侧颈内动脉床突段重度狭窄球囊扩张支架成形术动脉支架成形术是9手术基底动脉药物溶栓动脉溶栓术是10手术右侧侧窦区脑动静脉瘘栓塞术动静脉瘘栓塞术是
11药物谷胱甘肽片谷胱甘肽是12药物阿司匹林肠溶片阿司匹林是13药物左氧氟沙星氯化钠左氧氟沙星是14药物腺苷钴按腺苷钴按是15药物方新诺复方新诺明是16影像学检查头mri增强mri是17影像学检查脑部ct增强ct是18影像学检查头颅ct平扫 增强ct是19影像学检查脑mrimri是20影像学检查颈动脉ct增强ct是21症状肢活动不利肢体功能障碍是22症状言语构音不清构音障碍是23症状瘫痪瘫痪是24症状视力下降视力减退是25症状无力无力是
[0088]
由于本部分研究采用有监督学习,仅仅有正样本是不够的,需要构建负样本(如表6 所示)。本研究采用数据增广技术进行负样本构建和正样本扩充。由于抽取的实体所对应的标准名称具有唯一性,因此将“实体2”这一列随机打乱进行配对,当“实体2”不在是原来的实体时,便可标记为“不匹配”,负样本示例如表6所示。正样本的扩充采用相似传递,即实体a与实体b匹配,实体c与实体b匹配,则实体a与实体c匹配。最后我们将标注的数据集、构建的负样本数据集及扩充的正样本数据集合并,将数据集随机分为训练集、验证集、测试集,比例为3∶1∶1。
[0089]
表6 文本相似度匹配负样本
[0090][0091]
步骤5:输出结构化数据库(主体:客户端)
[0092]
在协变量提取器中依次输入目标医疗实体的名称,协变量提取器就可以自动输出一个结构化数据库,所述结构化数据库包含患者id编号、输入的目标医疗实体的标准名称及输出结果(“0”或“1”)的结构化数据。示例地,如表7所示,第一列为患者编号,后续列标目为输入的目标医疗实体的标准名称及其匹配结果。例如,心肌梗塞对应的一列中,如果输出
结果为“1”,表示患者患有心肌梗塞;如果输出结果“0”,表示该患者未患有心肌梗塞。依次类推,可以识别出患者合并的多种疾病。药物、手术、影像学检查、症状等均可通过上述步骤2至步骤5识别获得。所输出的结构化数据库亦可包括多个实体识别结果。例如,基于非结构化的出院小结文本,通过实体识别后的协变量提取器,采用ernie模型,分别提取了高血压、高脂血症、糖尿病、心功能不全、心房颤动、动脉粥样硬化、动脉支架成形术、动脉取栓术、气管插管、血管造影、静脉溶栓、动脉溶栓术、颅内外血运重建术、去骨瓣减压术、球囊扩张术、swi、dwi、cta、ctp、失语、视物不清、言语障碍、面舌瘫、认知功能障碍、肢体功能障碍、运动障碍、偏瘫、昏迷、低分子右旋糖酐、肝素、疏血通、奥拉西坦、华法林、丁苯酞、依达拉奉、西洛他唑、阿司匹林、血栓通、氯吡格雷和他汀等协变量。
[0093]
表7 结构化数据库
[0094][0095]
本技术的从非结构化医疗文本中提取疾病预后协变量的结构化数据的方法可以被开发为软件,软件的程序代码包括可执行上述方法的指令,方法的具体步骤参见上述内容,此处不再重复赘述。
[0096]
本领域技术人员可以清楚地了解到,为描述的方便和简洁,本技术的从非结构化医疗文本中提取疾病预后协变量的结构化数据的系统的具体工作过程,可以参考本实施例中的上述方法的对应过程,此处不再赘述。
[0097]
本领域内的技术人员应明白,本发明的实施例可提供为计算机程序产品、系统、智能终端或计算机可读存储介质。因此,本发明可采用完全软件实施例、或结合软件和硬件方面的实施例的形式。系统中包含的各个功能模块实现的功能如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(例如个人计算机、服务器或网络设备等)执行本发明的实施例中所述方法的全部或部分步骤。所述计算机可读存储介质包括但不限于u 盘、移动硬盘、只读存储器、随机存储器、磁碟或者光盘等各种可以存储计算机程序代码的介质。
[0098]
效果例 基于上述实施例中获得的结构化数据库,构建缺血性脑卒中患者的预后住院时长的预测模型
[0099]
应用上述实施例中从电子病历中提取的结构化数据构建logistic回归模型来预测住院时长是否大于7天,并将该预测模型与仅从病案首页提取的数据构建的对比预测模型 (作为对比例)进行比较。病案首页部分直接提取包括性别、年龄、入院年份、入院病情等级、出院诊断及手术编码等数据。在对比例中,首先通过检索疾病诊断和手术编码来提取结构化数据,出院诊断采用icd
‑
10,手术采用icd
‑
9,并利用病案首页的数据构建对比预测模型,并进一步与基于实施例中获得的结构化数据库的预测模型进行比较。通过比较上述两个预测模型在测试集中的auc值、灵敏度和特异度来对两个预测模型进行评价。
[0100]
构建预后(住院时长)的预测模型包括以下步骤:
[0101]
1、数据集
[0102]
将上述实施例获得的缺血性脑卒中患者预后协变量及其结构化数据全部纳入数据集,数据集按照4∶1的比例随机划分为训练集和测试集。
[0103]
通过绘制协变量之间的相关性检验的热力图(图10)我们发现,部分变量之间相关性较高。为解决存在多重共线性问题,采用lasso回归对协变量进行了筛选,最终剔除“偏瘫”和“疏血通”两个变量。本研究结局为二分类,即住院时长≤7天或>7天。
[0104]
2、训练预测模型
[0105]
本部分研究中构建了logistic回归模型来预测住院时长是否大于7天。利用之前划分好训练集和测试集,在训练集中进行5折交叉验证,即将训练集划分成5份,对于每1 份,都将作为验证集对模型进行评估,剩余的4份用于模型的训练。
[0106]
二分类logistic回归通过将线性回归的结果映射到sigmoid函数,预估事件出现的概率并完成0~1分类。线性回归为:z
i
=w
·
x
i
b,其中x
i
表示第i个样本的n维特征向量,即w为权重向量,b为偏置常数。sigmoid函数为:则有logistic回归模型的条件概率分布:
[0107][0108][0109]
对于给定的训练集t={(x1,y1),(x2,y2),(x3,y3),...,(x
n
,y
n
)},有似然函数:
[0110][0111]
取对数得到对数似然函数:
[0112][0113]
采用梯度下降法对上式求极大值得到w的估计值,w的估计值与用来估计“0”或“1”有关。
[0114]
研究结果:
[0115]
(一)缺血性脑卒中患者的基本情况
[0116]
最终纳入缺血性脑卒中患者6053人,患者基本情况如表8所示。77.07%的患者住
院时长>7天,其在年龄、入院病情、吸烟史、饮酒史、高血压、高脂血症、糖尿病、心功能不全、房颤、动脉支架成形术、动脉取栓术、血管造影、颅内外血运重建术、球囊扩张术、swi、cta、ctp、失语、视物不清、言语障碍、面舌瘫、肢体功能障碍、运动障碍、昏迷、低分子右旋糖酐、肝素、奥拉西坦、华法林、丁苯酞、依达拉奉、西洛他唑、阿司匹林、血栓通、氯吡格雷和他汀等方面与住院时长≤7天的患者存在统计学差异。
[0117]
表8 缺血性脑卒中患者基本情况
[0118]
[0119]
[0120][0121]
(二)住院时长>7天的相关因素
[0122]
通过多因素logistic回归(表9),我们发现入院时病情急危、患糖尿病,行动脉支架成形术、颅内外血运重建术,做ctp检查、存在言语障碍、面舌瘫、服用西洛他唑、氯吡格雷和他汀等因素与较长的住院时长相关。
[0123]
表9 住院时长>7天的影响因素(协变量)
[0124]
[0125]
[0126][0127]
(三)基于结构化数据库构建的预测模型与基于病案首页数据构建的预测模型的效果比较
[0128]
基于病案首页icd编码提取的协变量数为15个,而使用本技术的从非结构化医疗文本中提取疾病预后协变量的结构化数据的方法(以下简称“nlp技术”)提取的协变量数达到了43个。基于病案首页icd编码及使用本技术的方法提取的协变量例数的比较如表 10所示,除了动脉粥样硬化,利用nlp技术提取的协变量例数均多于利用icd编码从病案首页提取的例数,表明病案首页对于某些患者的疾病及手术可能存在记录不完全的情况。
[0129]
表10 基于病案首页icd编码及nlp技术提取协变量例数比较
[0130][0131][0132]
基于病案首页icd编码及使用本技术的方法构建的logistic回归的预测模型的or 值如表11所示,基于病案首页icd编码的logistic回归的预测模型中,球囊扩张术、入院病情和高脂血症是排名前三的预测因子,而基于使用本技术的方法构建的logistic回归的预测模型中,西洛他唑、颅内外血运重建术和入院病情是排名前三的预测因子,基于nlp技术构建的logistic回归的预测模型纳入了更多有意义的预测因子。
[0133]
表11 基于病案首页及基于nlp技术构建的logistic回归预测模型比较
[0134]
[0135][0136]
此外,通过nlp技术提取协变量构建的住院时长预测模型的auc值均显著高于仅利用病案首页构建的预测模型(表12),差异有统计学意义。说明基于nlp技术提取协变量提供了更多的预后预测信息。
[0137]
表12 基于病案首页及nlp技术构建的预测模型auc值
[0138]
模型病案首页(95%ci)nlp(95%ci)plogistic回归0.684(0.657
‑
0.710)0.776(0.751
‑
0.799)<0.001
[0139]
脑卒中患者住院时长预测模型的比较结果:
[0140]
基于病案首页icd编码的logistic回归的预测模型中,共纳入8个预测因子,预测因子是从挑选的协变量中选出的,通过这些预测因子才能预测住院时长。而基于nlp技术构建的logistic回归的预测模型中,共纳入16个预测因子。此外,基于病案首页icd 编码提取的协变量数为15个,而应用nlp技术提取的协变量数达到了43个。并且,通过nlp技术提取协变量构建的住院时长预测模型的auc值均显著高于仅利用病案首页构建的预测模型,差异有统计学意义。因此,通过nlp技术提取协变量构建的住院时长预测模型预测效果显著高于仅利用病案首页构建的预测模型,反映了nlp提取协变量的有效性和实际应用价值。
[0141]
现有研究表明脑卒中患者中,由于提供急性脑卒中护理、查明脑卒中的原因及预
防脑卒中并发症一般在入院的第一周内完成,因此以往的研究一般将脑卒中患者大于6到8 天的住院时长定义为长时间住院,而长时间住院是住院费用增加的独立影响因素,虽然患者住院时间越长,能够接受治疗的时间越久,但是患者预后不一定好。研究长时间住院(大于7天)的影响因素及预测是否长时间住院有助于合理分配医疗资源,提高床位使用的灵活性,从而降低管理成本和医疗护理成本,并可以依据这些因素为患者制定个性化诊疗途径和规划出院计划,以减少患者住院时长,提高患者及其家属的满意度。通过临床数据来预测患者相关结局(例如住院时长是否大于7天),可以帮助临床决策的优化,改进个性化护理。与现有的各种回归分析模型不同,本技术的临床预测模型具有更好的泛化能力,即较好的预测训练数据以外的新数据。而通过利用海量的电子病历文本的结构化数据提取有用信息,精确估计病人住院时长,更有利于统筹管理医院物资(床位、药物和仪器)及医护人员的分布。
[0142]
针对缺血性脑卒中患者,本技术构建ner模型为最优的实体识别模型进行疾病、药物、手术、影像学检查和症状这5种类型医疗实体的识别,构建半结构化数据库。为了进一步从半结构化数据库中提取出结构化数据,构建匹配效果最优的ernie模型进行文本相似度匹配模型。基于提取的结构化数据,增加信息量,构建住院时长是否大于7天的预测模型,为临床决策及资源配置提供更丰富的信息。
[0143]
应当注意的是,本发明的实施例有较佳的实施性,且并非对本发明作任何形式的限制,任何熟悉该领域的技术人员可能利用上述揭示的技术内容变更或修饰为等同的有效实施例,但凡未脱离本发明技术方案的内容,依据本发明的技术实质对以上实施例所作的任何修改或等同变化及修饰,均仍属于本发明技术方案的范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。