1.本发明涉及分布式机器学习技术领域,具体地说是一种高性能可自适应划分子森林的分布式级联森林方法。
背景技术:
2.深度学习和大数据处理是人工智能领域的一大热门,现有的大部分深度学习技术是通过神经网络模型来实现的,而深度森林是基于树的集成方法,其具有比深度神经网络少得多的超参数,并且其模型复杂性以数据相关的方式自动确定。深度森林计算开销小、模型效果好,超参数少,模型对超参数调节不敏感,相对于其他神经网络模型,更容易进行理论分析,可以适应于不同大小的数据集,模型复杂度可自适应伸缩。深度森林已成为深度学习中的一个研究热点,但是从计算架构来看,任务的规模很大程度上限制了深度森林的表现,任务过大会导致内存很快耗光。
3.深度森林的一个未来研究方向就是研究如何调动更多计算资源,更好利用其自身的高并行性的特点,做任务级的并行。目前已有了一种分布式深度森林方法forestlayer,该方法在各项数据集上的训练效率比原生的深度森林快7x
‑
20x倍。它的主要思想是将随机森林按照一定粒度划分为多个子森林,每个子森林作为并行计算的一个任务。但是子森林划分的粒度对算法效率有着很大的影响,难以保证最佳的粒度划分,划分的粒度越细,训练效率会先增后降,存在无法自适应划分子森林个数的问题。
4.因此,如何进一步的提高深度森林的分布式计算效率,并且有效地解决子森林粒度划分问题是相关领域的一个重点任务。研究一种高性能地可自适应划分子森林的分布式深度森林方法,同时将其应用到复杂的大数据分布式环境,为深度森林在大数据情况下提供一种新颖的分布式计算方法。
技术实现要素:
5.本发明的目的是针对现有技术的不足而提供的一种可自适应划分子森林的分布式级联森林方法,采用分布式级联森林和子森林自适应划分的深度森林方法,通过对树组成的森林来集成并前后串联起来达到表征学习的效果,以更贴合分布式的方式来减少传输的实例,同时能解决子森林自适应划分粒度的问题,并基于spark分布式框架进行仿真,进一步提升深度森林分布式训练的效率,表征学习能力可以通过对高维输入数据的多粒度扫描而进行加强,串联的层数也可以通过自适应的决定,有效地提高了分布式深度森林地并行度,较好的解决了森林粒度划分问题,保证每次子森林进行并行计算时都能得到最大的并行资源,同时减少了采样的特征实例,降低了传输特征的资源消耗,在多节点大数据集下速率提升了1.2~1.5倍,能显著提高用户的体验质量,为相关领域的技术提供技术支撑。
6.本发明的目的是这样实现的:一种可自适应划分子森林的分布式级联森林方法,其特点是采用深度森林算法,通过对树组成的森林来集成并前后串联起来达到表征学习的效果,该表征学习能力可以通过对高维输入数据的多粒度扫描而进行加强,串联的层数也
可以通过自适应的决定,它主要分为多粒度扫描和级联森林两大模块。
7.所述多粒度扫描对原始特征进行多个滑动窗口扫描,生成不同维度的特征实例,将生成的实例数据放入两个随机森林中进行训练,计算出一个类向量,然后再将生成的特征实例和计算的类向量进行聚合,得到最终的特征向量,该特征向量将作为级联森林的输入数据。
8.所述级联森林由多个级联森林层组成,级联森林层又由多个随机森林组成,通过多个随机森林学习多粒度扫描产生的特征向量后,得到新的特征向量,并将新的特征向量作为下一个级联森林层的输入向量。为了降低过度拟合的风险,每个森林产生的类向量通过k折交叉验证生成。在扩展到新的层级之后,需要在验证集上估计整个级联的性能,并且如果没有显着的性能增益,则训练过程将终止。
9.本发明主要包括分布式级联森林和子森林自适应划分两个部分,所述分布式级联森具体包括以下步骤:
[0010]1‑
1:设级联森林表示为f={f1…
f
s
},级联森林f由s个随机森林f组成,总共包含l颗决策树。每个随机森林f表示为f={u1…
u
r
},其中随机森林f由r个子森林u 构成,子森林u
r
包含了q个决策树,则
[0011]1‑
2:对于第t层级联森林f
t
,将大小为n特征空间x并行地无放回的采样s次,生成s个子样本集x
r
,其大小为b,b<<n,且b=n
y
,y∈[0.5,1],并分布式地传给级联森林f中的各个随机森林f。
[0012]1‑
3:随机森林f轮询的自适应划分子森林u
r
,u
r
对子样本集x
r
进行bootstrap(有放回的随机采样)获得大小为n的样本集x
b
。
[0013]1‑
4:在每一个轮次中,子森林u
r
的q个决策树并行的处理样本集x
b
,得到子森林 u
r
的统计结果为ξ(u
r
)。
[0014]1‑
5:将每轮的子森林u
r
统计结果ξ(u
r
)进行聚合,得到整个森林f的统计结果为
[0015]1‑
6:将1
‑
3~1
‑
5步骤并行地在各个森林f中进行处理,最后合并ξ(f)得到级联森林f
t
的统计结果为
[0016]
所述子森林u
r
自适应划分具体包括以下步骤:
[0017]2‑
1:第一层级联森林f1初始化分次数为r,轮询划分子森林u
r
,计算每轮bootstrap 后子森林u
r
的统计值ξ(u
r
)并持续更新类向量vs。
[0018]2‑
2:当类向量vs收敛后,其收敛判断标准为第k轮的平均类向量,相比前w轮平均类向量vavg的误差精度都小于σ时,则停止划分子森林u
r
并记录划分次数r
′
=k。
[0019]2‑
3:若达到r次依然没有收敛同样停止划分,那么r
′
=r;对于一个级联森林f, s个森林f会有s个r
′
,进行取平均得到r是下一层的子森林u
r
划分次数的最大值。
[0020]2‑
4:对于下一层级联森林f
t 1
,同样地进行步骤2
‑
1~2
‑
3步骤的操作,则可达到自
适应划分的目的。
[0021]
本发明与现有技术相比具有以下优点和显著的技术效果:
[0022]
1)有效地提高了分布式深度森林地并行度,针对级联森林中的一个森林来说,现有的分布式深度森林方法forestlayer的并行度为o(r),而此方法的并行度o(t/r);r为子森林个数,t为森林中所有树的个数。只要保证r2<t则并行效率大于forestlayer。
[0023]
2)提供了自适应划分子森林的判别算法,解决森林粒度划分问题,保证每次子森林进行并行计算时都能得到最大的并行资源,同时减少了采样的特征实例,降低了传输特征的资源消耗;
[0024]
3)在多节点大数据集下速率提升了约1.2~1.5倍。
附图说明
[0025]
图1为本发明流程图;
[0026]
图2为分布式级联森林的算法流程图;
[0027]
图3为子森林并行计算流程图;
[0028]
图4为自适应子森林划分的判断算法流程图。
具体实施方式
[0029]
下面以具体实施对本发明作进一步详细描述和说明:
[0030]
实施例1
[0031]
参阅图1,本发明中的分布式级联森林步骤如下:
[0032]
1、搭建多节点的spark高可用集群,采用主从模式在分布式机器上部署,其部署的集群规模为n节点,一个主节点,n
‑
1个从节点。对原始特征z进行多粒度扫描,生成新的特征空间x={x1…
x
n
},包含n个特征实例,x将作为级联森林的输入数据。
[0033]
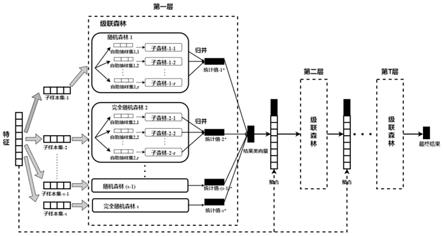
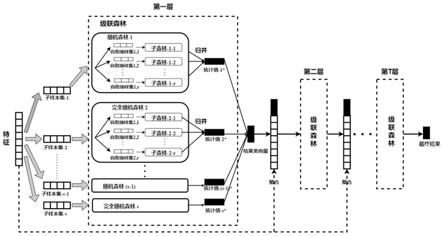
参阅图2,设级联森林表示为f={f1…
f
s
},级联森林f由s个随机森林f组成,总共包含l颗决策树。每个随机森林f表示为f={u1…
u
r
},其中:随机森林f由r个子森林u构成,子森林u
r
包含了q个决策树,则
[0034]
2、对于第t层级联森林f
t
,将大小为n特征空间x并行地无放回的采样s次,生成s个子样本集x
r
,其大小为b,b<<n,并分布式地传给级联森林f中的各个随机森林f。整个级联森林f的输入的特征空间大小为b
×
s,其中b=n
y
,y∈[0.5,1],如果样本总数n=1,000,000,每一次blb二次抽样和重抽样需要最多3981个独立样本,将大幅度减传输的实例样本空间。
[0035]
参阅图3,所述随机森林f轮询的自适应划分子森林u
r
,其划分过程见下述步骤3, u
r
对子样本集x
r
进行bootstrap(有放回的随机采样)获得大小为n的样本集x
b
。在每一个轮次中,子森林u
r
的q个决策树并行的处理样本集x
b
,得到子森林u
r
的统计结果为ξ(u
r
),其次将每轮的子森林u
r
统计结果ξ(u
r
)进行聚合,得到整个森林f的统计算结果为
[0036]
参阅图4,子森林自适应划分步骤如下:
[0037]
1)初始化一个超参数r,作为第一层级联森林f1初始化分次数,然后轮询划分子森
林u
r
,计算每轮bootstrap后子森林u
r
的统计值ξ(u
r
)并持续更新类向量vs。
[0038]
2)设定超参数w和σ,w为类向量收敛判断的比较次数,σ为每轮类向量的误差阈值。当第k轮的平均类向量,相比前w轮平均类向量vs的误差精度都小于σ时,则停止划分子森林u
r
并记录划分次数r
′
=k。若达到r次依然没有收敛同样停止划分,那么r
′
=r;对于一个级联森林f,s个森林f会有s个r
′
,进行取平均得到 r是下一层的子森林u划分次数的最大值。
[0039]
3)对于下一层级联森林f
t 1
,同样地重复上述步骤的操作,则可达到自适应划分的目的。
[0040]
4)将以上2)~3)步骤并行地在各个森林f中进行处理,最后合并ξ(f)得到级联森林f
t
的统计结果为
[0041]
5)对于下一层级联森林f
t 1
,它的输入数据为上一层f
t
的统计结果ξ(f
t
)聚合上特征空间x,并重复2)~3)步骤。每层级联森林的结果扩展到下一层之后,需要在验证集上估计整个级联的性能,并且如果没有显着的性能增益,则训练过程将终止。
[0042]
以上所述仅为本发明的具体实施例,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。