1.本发明属于疑似污染工业企业识别领域,具体涉及一种基于公开数据的疑似污染工业企业识别方法。
背景技术:
2.近年来土壤污染问题逐渐凸显。从污染分布情况看,南方土壤污染重于北方;镉、汞、砷、铅4种无机污染物含量分布呈现从西北到东南、从东北到西南方向逐渐升高的态势。贾丽等(2020)在查阅大量的文献数据后认为我国土壤重金属污染中镉为主导污染因子,砷元素及铜、锌元素易超标,汞、镍基本不超标,与调查公报的结果相似。何凤芹等(2020)对珠江三角洲地区某市的133个典型农田土壤样点进行icp
‑
ms测定,发现超标率达12.8%,主要超标元素为镉、砷、铜、镍。陈雅丽等(2019)对3041个表层土壤样样品进行主成分分析和相关分析等定性源解析和rf等定量源解析方法,结果表明广东地区土壤重金属的主要污染源为工业活动(主要针对cd、as、pb、hg)和土壤母质(主要针对cu、zn、cr、ni),使用化肥等农业活动和交通排放对某些重金属元素也有贡献。土壤重金属污染来源主要可分为自然因素和人为因素两大类。其中冶矿产业、工矿企业、城市建设、车辆交通、垃圾处理及农业生产等多种人为因素是引起土壤重金属污染的主要原因,特别是污染工业企业,不仅污染强度高,污染元素也多,对土壤产生了较大的污染。可见,工业企业污染是造成土壤污染的重要因素之一。然而,企业污染状况及用地调查对专业、技术要求较高,需要花费大量的人力和物力。
3.因此,在现有统计数据的基础上,对众多工业企业进行初步筛选,获得污染可能性处于较高水平的工业企业名录,有助于更加精准快速地开展企业污染状况和用地调查,为我国的土壤污染防治和可持续发展提供依据。因此,提供一种基于数据挖掘技术和机器学习分类模型来识别污染可能性较高的工业企业具有重要的理论和实践意义。
技术实现要素:
4.本发明的目的在于解决现有重点行业企业用地调查中存在的问题,并提供一种基于公开数据的疑似污染工业企业识别方法。
5.本发明所采用的具体技术方案如下:
6.本发明提供了一种基于公开数据的疑似污染工业企业识别方法,具体如下:
7.s1:获取待研究区的工业企业信息、土壤环境重点监管企业信息、全口径涉重金属重点行业企业清单、重点排污单位名录、工商要素补充数据、企业poi数据和环境要素栅格数据;
8.s2:将步骤s1中的全口径涉重金属重点行业企业清单、土壤环境重点监管企业信息和重点排污单位名录的特征信息转换为结构化数据;根据工商要素补充数据和企业poi数据建立基于企业名称的模糊匹配,使得步骤s1中每个工业企业信息与其地理位置信息相对应,得到含经纬度信息的企业基本信息关联数据;同时,将企业poi数据的gcj
‑
02坐标系转换为wgs
‑
84坐标系;
9.s3:为步骤s2中的企业基本信息关联数据添加环境信息,构建包含环境因子的工业企业数据集;
10.s4:对步骤s3中的工业企业数据集,通过关联土壤环境重点监管企业信息、全口径涉重金属重点行业企业清单和重点排污单位名录,得到疑似污染工业企业数据集;同时,选取野外实地调研采样并测试化验后土壤重金属含量低于标准值的工业企业作为无污染工业企业数据集;根据疑似污染工业企业数据集和无污染工业企业数据集,建立训练数据集和测试数据集;
11.s5:基于步骤s4中的训练数据集和测试数据集,利用支持向量机和随机森林两种机器学习方法对所述工业企业数据集进行分类,建立支持向量机模型和随机森林模型;根据支持向量机模型和随机森林模型,对所述工业企业数据集进行分类,根据两个模型的分类结果,得到待研究区的疑似污染工业企业名单,实现对疑似污染工业企业的识别。
12.作为优选,所述步骤s1中,工业企业信息包括企业名称、成立年份和调查年份,土壤环境重点监管企业信息、全口径涉重金属重点行业企业清单和重点排污单位名录均包括企业名称及其所属地市,工商要素补充数据包括企业名称、经营范围和注册地址,企业poi数据包括企业名称及其经纬度信息,环境要素栅格数据包括年平均降水、气压、相对湿度、气温、风速、土壤类型、土壤质地、土地利用现状、水系分布和人口密度分布。
13.作为优选,步骤s1中,所述土壤环境重点监管企业信息、全口径涉重金属重点行业企业清单和重点排污单位名录均以pdf、word或图片格式存在。
14.作为优选,所述步骤s2中,将全口径涉重金属重点行业企业清单、土壤环境重点监管企业信息和重点排污单位名录中的非结构化数据,通过光学字符识别技术将其识别为基于office open xml标准的压缩文件格式,以转换为结构化数据。
15.进一步的,所述非结构化数据是指以pdf、word或图片格式存在的信息数据。
16.作为优选,所述步骤s2中,模糊匹配方法是通过匹配高德地图poi,使用结构化查询语言,将每个工业企业的名称和city字段精确匹配到高德地图poi以及国家企业信用信息公示系统的名称和city字段。
17.作为优选,所述步骤s3中,环境因子包括年平均降水、气压、相对湿度、气温、风速、土壤类型、土壤质地、土地利用现状、水系分布和人口密度。
18.作为优选,所述步骤s3具体如下:
19.将所述企业基本信息关联数据导入arcgis 10.2中,根据待研究区域的地理边界信息,筛选地理位置发生偏移的企业,结合工业企业信息对其进行修正;其次,将环境要素栅格数据导入arcgis 10.2中,利用“extract multi value to points”工具将包含要素信息的面状数据赋值给各工业企业点;然后,利用“near”工具计算工业企业点到最近水系的距离;最后将各项环境信息整理后导出企业属性表格,得到所述工业企业数据集。
20.作为优选,所述步骤s4中,标准值为gb36600—2018建设用地土壤污染风险管控标准中的筛选值。
21.作为优选,所述步骤s5中,将支持向量机模型和随机森林模型均判断为疑似污染的工业企业作为疑似污染工业企业,将支持向量机模型和随机森林模型均判断为无污染的工业企业作为无污染工业企业,其余工业企业作为污染可能性一般的工业企业。
22.本发明相对于现有技术而言,具有以下有益效果:
23.本发明基于政府调查并公开的工业企业数据,并利用模糊匹配、数据挖掘、机器学习等方法进行疑似污染工业企业的识别,主要采用svm和rf算法建立疑似污染工业企业分类模型,进而对我国重点行业企业污染用地筛选与调查起到一个指向性的作用。本发明扩展了传统的工业企业污染状况筛选与调查的分析方法和思路,对工业企业污染的治理管控工作具有重要的理论与实践意义,并存在推广应用价值。
附图说明
24.图1是实施例中研究区工业企业分布图(1998
‑
2014年);
25.图2是实施例中研究区疑似污染和无污染工业企业分布示意图;
26.图3是实施例中基于工业企业识别结果对研究区工业企业污染分级的示意图。
具体实施方式
27.下面结合附图和具体实施方式对本发明做进一步阐述和说明。本发明中各个实施方式的技术特征在没有相互冲突的前提下,均可进行相应组合。
28.本发明提供了一种基于公开数据的疑似污染工业企业识别方法,具体如下:
29.s1:基于公开网页端获取待研究区的工业企业信息、土壤环境重点监管企业信息、全口径涉重金属重点行业企业清单、重点排污单位名录、工商要素补充数据、企业poi(point of interest,poi)数据和环境要素栅格数据。
30.其中,工业企业信息包括企业名称、成立年份和调查年份,土壤环境重点监管企业信息、全口径涉重金属重点行业企业清单和重点排污单位名录均包括企业名称及其所属地市,工商要素补充数据包括企业名称、经营范围和注册地址,企业poi数据包括企业名称及其经纬度信息,环境要素栅格数据包括年平均降水、气压、相对湿度、气温、风速、土壤类型、土壤质地、土地利用现状、水系分布和人口密度分布。土壤环境重点监管企业信息、全口径涉重金属重点行业企业清单和重点排污单位名录均以pdf、word或图片格式存在。
31.s2:将步骤s1中的全口径涉重金属重点行业企业清单、土壤环境重点监管企业信息和重点排污单位名录的特征信息转换为结构化数据。具体方法如下:将全口径涉重金属重点行业企业清单、土壤环境重点监管企业名单和重点排污单位名录中以非结构化文档数据pdf、word或图片格式存在信息,使用光学字符识别(optical character recognition,ocr)技术将其识别为基于office open xml标准的压缩文件格式,转换为结构化数据。
32.随后根据工商要素补充数据和企业poi数据建立基于企业名称的模糊匹配,使得步骤s1中每个工业企业信息与其地理位置信息相对应,得到含经纬度信息的企业基本信息关联数据。同时,将企业poi数据的gcj
‑
02坐标系转换为wgs
‑
84坐标系。
33.其中,模糊匹配方法是通过匹配高德地图poi,使用结构化查询语言,将每个工业企业的名称和city字段精确匹配到高德地图poi以及国家企业信用信息公示系统的名称和city字段。
34.s3:为步骤s2中的企业基本信息关联数据添加环境信息,构建包含环境因子的工业企业数据集。其中,环境因子包括年平均降水、气压、相对湿度、气温、风速、土壤类型、土壤质地、土地利用现状、水系分布和人口密度。
35.该步骤的具体操作如下:
36.将企业基本信息关联数据导入arcgis 10.2中,根据待研究区域的地理边界信息,筛选地理位置发生偏移的企业,结合工业企业信息对其进行修正。其次,将环境要素栅格数据导入arcgis 10.2中,利用“extract multi value to points”工具将包含要素信息的面状数据赋值给各工业企业点。然后,利用“near”工具计算工业企业点到最近水系的距离。最后将各项环境信息整理后导出企业属性表格,得到工业企业数据集。
37.s4:参考中华人民共和国生态环境部发布的《关于进一步明确重点行业企业用地调查相关要求的通知》和《污染地块土壤环境管理办法》,从事过有色金属冶炼、石油加工、化工、焦化、电镀、制革等行业生产经营活动,以及从事过危险废物贮存、利用、处置活动的用地为疑似污染场地。
38.因此,对步骤s3中的工业企业数据集,通过关联土壤环境重点监管企业信息、全口径涉重金属重点行业企业清单和重点排污单位名录,得到疑似污染工业企业数据集。同时,选取野外实地调研采样并测试化验后土壤重金属含量低于标准值的工业企业作为无污染工业企业数据集。根据疑似污染工业企业数据集和无污染工业企业数据集,建立训练数据集和测试数据集。
39.其中,标准值可以采用gb36600—2018建设用地土壤污染风险管控标准中的筛选值。
40.s5:基于步骤s4中的训练数据集和测试数据集,利用支持向量机(support vector machine,svm)和随机森林(random forest,rf)两种机器学习方法对工业企业数据集进行分类,建立支持向量机模型和随机森林模型。根据支持向量机模型和随机森林模型,对工业企业数据集进行分类,根据两个模型的分类结果,得到待研究区的疑似污染工业企业名单,实现对疑似污染工业企业的识别。
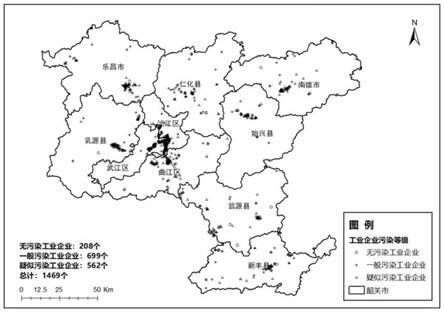
41.其中,svm处理分类问题的重要步骤是:根据特定的样本类别,假设权重向量为w
i
,偏置为b
i
。当需要对分类样本x进行分类时,支持向量机会评估样本的映射函数。如果映射函数满足(w
i
·
x) b
i
≥(w
‑1·
x) b
‑1条件,则可以完成分类样本的分配,并赋值为1,将其分类为正类,否则将其分类为负类,并赋值
‑
1。此方法通过与单个超平面(w,b)处理二分类问题具有高度的一致性,其中w=w1‑
w
‑1,b=b1‑
b
‑1。
42.rf釆用分类回归树作为元分类器,通过bagging方法生成相互之间有差异的不同训练样本集。其本质是一个树型分类器{h(x,β
k
),k=1,2,
……
,ntree}的集合,其中元分类器h(x,β
k
)是用分类回归树算法生成充分生长、没有剪枝的分类回归树;x是输入向量,β
k
是独立同分布的随机向量,决定了单棵树的生长过程。对于分类问题,釆用简单多数投票法的结果作为输出;对于回归问题,采用单棵树输出结果的简单平均作为输出。
43.在实际应用时,根据两个模型的分类结果,对疑似污染工业企业识别的规则可以采用如下方法:将支持向量机模型和随机森林模型均判断为疑似污染的工业企业作为疑似污染(或污染可能性极大)工业企业,将支持向量机模型和随机森林模型均判断为无污染的工业企业作为无污染(或污染可能性较小)工业企业,其余工业企业作为污染可能性一般的工业企业。
44.实施例
45.本实施例中选取我国广东省韶关市作为研究区,如图1所示,为研究区工业企业分布图(1998
‑
2014年)。基于该研究区,使用本发明的方法进行分析识别疑似污染工业企业的
具体步骤如下:
46.s1:基于公开网页端获取研究区工业企业信息、土壤环境重点监管企业信息、全口径涉重金属行业企业清单、重点排污企业名录、工商要素补充数据、企业poi数据和环境要素栅格数据。其中,工业企业信息来源于中国工业企业数据库、土壤环境重点监管企业名单、全口径涉重金属重点行业企业清单和重点排污单位名录由广东省生态环境厅发布,以上数据均包括企业名称及其所属地市;工商要素补充数据的分类符合国民经济行业分类标准gb/t 4752
‑
2011;企业poi数据包括企业名称及其gcj
‑
02经纬度信息,基于高德地图api下载;工商要素补充数据包括企业名称、经营范围、成立年份和注册地址;环境要素栅格数据包括从中国区域地面气象要素驱动的数据集获取了1979年~2018年的年平均降水、气压、相对湿度、气温、风速等气象数据,从中国科学院资源环境科学与数据中心下载的中国土壤类型空间分布数据、中国土壤质地空间分布数据、土地利用现状1km遥感监测数据、中国人口空间分布1km公里网格数据。
47.s2:将s1中的非结构化数据进行结构化处理,使用ocr技术将pdf和jpg格式的数据识别为基于office open xml标准的压缩文件格式,提取转换的过程中还需要对数据表格中的名称进行规范化处理,例如:删除冗余字符,将名称中的英文格式括号修改为中文格式后并进行拆分等。同时需要删除表格中的多余维度和重复记录,并对同一指标进行合并处理。最后判断同一来源数据是否多期、不同期数据指标是否一致,完成非结构化数据的最终清洗工作(即实现s1中的非结构化数据的结构化处理)。
48.基于企业名称的模糊匹配方法通过匹配高德地图poi,使用结构化查询语言,将每个工业企业的名称和city字段精确匹配到高德地图poi以及国家企业信用信息公示系统的名称和city字段,同时将gcj
‑
02坐标系转换为wgs
‑
84坐标系。
49.s3:根据工业企业污染的常见途径,参考《在产企业地块风险筛查与风险分级技术规定》和《关闭搬迁企业地块风险筛查与风险分级技术规定》,初步筛选与企业污染相关的11个要素:年平均降水、气压、相对湿度、气温、风速5个气象要素;土壤类型、土壤质地、水系分布4个水文土壤因子和土地利用类型、人口密度2个经济社会要素。
50.基于匹配后的坐标信息,使用空间分析技术为疑似污染工业企业数据添加环境要素信息。具体步骤为:首先,将企业数据表格导入arcgis 10.2中,根据韶关市的地理边界信息,筛选处地理位置偏移较大的企业,并结合企业信息对其进行修正;其次,将11个环境要素栅格数据导入arcgis 10.2中,利用“extract multi value to points”工具将包含要素信息的面状数据赋值给各工业企业点;然后利用“near”工具计算企业点到最近水系的距离;最后将各项要素信息整理之后,导出工业企业属性表格,建立包含气象、土壤和人口分布等自然地理社会因子的工业企业数据集。
51.s4:将通过关联土壤环境重点监管企业信息、全口径涉重金属行业企业清单、重点排污单位名录等数据,得到疑似污染工业企业数据集,同时选取野外实地调研采样并测试化验后土壤重金属含量低于建设用地土壤污染风险筛选值的工业企业作为无污染工业企业数据集,随后通过疑似污染和无污染工业企业数据集建立训练数据集和测试数据集。
52.具体的筛选过程为:参考中华人民共和国生态环境部发布的《关于进一步明确重点行业企业用地调查相关要求的通知》和《污染地块土壤环境管理办法》,从事过有色金属冶炼、石油加工、化工、焦化、电镀、制革等行业生产经营活动,以及从事过危险废物贮存、利
用、处置活动的用地为疑似污染场地。通过关联土壤环境重点监管企业信息、全口径涉重金属行业企业清单、重点排污单位名录等数据,可以得到疑似污染工业企业数据集;同时选取野外实地调研采样并部分进行测试化验重金属含量低于标准值的工业企业作为无污染工业企业数据集。
53.s5:利用s4中建立的训练数据集和测试数据集建立机器学习模型,利用svm和rf对研究区内所有的工业企业数据集进行分类,获得疑似污染工业企业名单。具体如下:
54.svm使用r语言中的e1071包实现,模型最终选取营业状态、企业规模、轻重工业、年末从业人数、资产总计、成立时长、年平均降水量、年平均气压、年平均风力、年平均温度、年平均相对湿度、土壤砂粒含量、黏粒含量、粉粒含量、所在地区人口数、距最近水系的最小距离、土地利用类型这17个因子。模型建立结果:训练集准确率83.7%,kappa值0.656,验证集准确率71.4%,kappa值:0.429。将建立的模型运用到研究区(1998
‑
2014)工业企业汇总数据集中,可以得到研究区疑似污染工业企业数量为919个,占比62.1%。
55.rf使用r语言中的caret包,通过factor函数将定性变量“企业规模”、“轻重工业”、“土地利用类型”转化成因子型变量。利用createdatapartition函数,运用留出法抽样将数据的80%划分为训练集,20%划分为测试集。利用caret包中的preprocess函数分别对训练集和测试集数据进行标准化处理,所得结果存为新的变量。建模得到训练集的正确率为100%,kappa系数为1,验证集的正确率为70.37%,kappa系数为0.2752;分别利用网格调参法和随机调参法对模型进行优化,两种优化方法所得到的优化结果相同,优化后训练集的正确率为98.23%,kappa系数为0.9617,验证集的正确率为77.78%,kappa系数为0.5031。将优化后的模型运用到研究区(1998
‑
2014)工业企业汇总数据集中,得到研究区无污染工业企业552个,占总调查工业企业37.3%,疑似污染工业企业929个,占比62.7%。
56.通过两种建模结果的比较可知,在对已知集的预测中,svm模型预测的准确率为80.0%,rf模型预测的准确率为82.9%,svm模型对于疑似污染工业企业预测的准确度略低于rf模型,svm模型与rf模型预测结果的相同率为74.3%(如表1所示),预测结果的相似度较高。在对未知集中的1341个工业企业的预测中,预测结果的相似度为51.1%。如图2所示,将svm和rf两种方法都判断为疑似污染工业企业判断为疑似污染(或污染可能性极大)工业企业,将两种模型都判断为无污染的工业企业判断为无污染(或污染可能性较小)工业企业,其余的工业企业均判断为污染可能性一般的工业企业。如图3所示,该研究区最终共获得疑似污染工业企业562家,无污染工业企业208家,污染可能性一般的工业企业699家。
57.表1 svm与rf预测结果的混淆矩阵
[0058][0059]
由此可见,本发明基于公开的工业企业统计数据和机器学习分类方法,扩展了疑似污染工业企业分类的方法和思路,为进一步进行重点行业企业用地调查提供重要的参考依据。
[0060]
以上所述的实施例只是本发明的一种较佳的方案,然其并非用以限制本发明。有关技术领域的普通技术人员,在不脱离本发明的精神和范围的情况下,还可以做出各种变化和变型。因此凡采取等同替换或等效变换的方式所获得的技术方案,均落在本发明的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。