1.本发明属于自然语言处理领域,具体涉及一种用于知识图谱语义搜索的文本理解的方法。
背景技术:
2.所谓语义搜索,是指搜索引擎的工作不再拘泥于用户所输入请求语句的字面本身,而是透过现象看本质,准确地捕捉到用户所输入语句后面的真正意图,并以此来进行搜索,从而更准确地向用户返回最符合其需求的搜索结果。
3.在知识图谱中,可以通过拟人的提问来进行语义搜索,这种场景下,可以类似人一样将所要检索问题描述清楚,通过对问题描述的文本进行解析和理解,并将结果从知识图谱中搜索和匹配,返回用户所需的结果。
技术实现要素:
4.针对现有技术中存在的问题,本发明提供一种用于知识图谱语义搜索的文本理解的方法,本发明的部分实施例能够有助于更好的理解用户的意图,并从知识图谱中搜索符合用户需要的结果返回给用户。
5.为实现上述目的,本发明采用以下技术方案:
6.一种用于知识图谱语义搜索的文本理解的方法,针对输入的待理解的文本,所述方法包括如下步骤:
7.通过大规模预训练模型获得文本中每个词元的语义信息,生成语义向量;
8.基于所述语义向量,通过卷积神经网络、实体分类用的第一softmax分类器和关系分类用的第二softmax分类器,识别出实体类型和关系类型;
9.基于所述语义向量,通过crf进行序列标注,抽取出实体;
10.基于所述语义向量,通过bi
‑
lstm模型和问句分类用的第三softmax分类器,将文本进行分类;
11.基于识别出的实体类型和关系类型、抽取出的实体、文本的分类结果,检索知识图谱获取信息作为反馈。
12.优选地,所述大规模预训练模型使用bert、roberta、erine、albert、gpt中的一种。
13.优选地,所述将文本的分类结果包括事实类、统计类、是非类和关系类。
14.一种计算机存储介质,所述存储介质中存储有计算机程序,所述计算机程序被执行时实现所述的方法。
15.一种用于知识图谱语义搜索的文本理解的系统,所述系统包括:
16.语义获取模块,用来通过大规模预训练模型获得文本中每个词元的语义信息,生成语义向量;
17.实体分类模块,用来基于所述语义向量,通过卷积神经网络和实体分类用的第一softmax分类器,识别出实体类型;
18.关系分类模块,用来基于所述语义向量,通过卷积神经网络和关系分类用的第二softmax分类器,识别出关系类型;
19.实体抽取模块,用来基于所述语义向量,通过crf进行序列标注,抽取出实体;
20.问句分类模块,用来基于所述语义向量,通过bi
‑
lstm模型和问句分类用的第三softmax分类器,将文本进行分类;
21.检索反馈模块,用来基于识别出的实体类型和关系类型、抽取出的实体、文本的分类结果,检索知识图谱获取信息作为反馈。
22.与现有技术相比,本发明的有益效果为:
23.1.通过问句分类实现意图识别,理解用户想要什么样的答案,具体的,本发明通过模型将问题分为事实类、统计类、是非类和关系类等四种类型,但本发明的模型不局限于此四种类型,根据具体情况可以进行细分或调整,比如在电网的专业领域,可以将其分为“检修类”、“运维类”、“财务类”、“党建类”等;
24.2.通过将输入文本片段识别为不同的实体类型或关系类型,来指导语义搜索中更好的检索所需要的信息;
25.3.通过实体抽取方法抽取出输入文本的实体,用以从知识图谱中直接匹配实体;
26.4.本发明使用统一的方法同时完成了四种任务,使得系统更加简洁;
27.5.因这四种任务在一个文本输入中是紧密关联的,其效果要比四种独立的任务更好。
附图说明
28.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
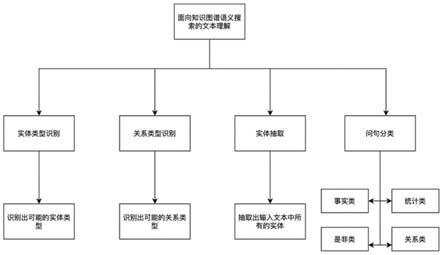
29.图1为本发明实施例的4个下游任务同时进行的流程示意图。
30.图2为本发明实施例的系统架构图。
具体实施方式
31.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有付出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
32.在本发明的描述中,需要理解的是,术语“纵向”、“横向”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
33.如图1
‑
2所示,对输入文本,通过同一个大规模预训练模型获得文本中每个词元(tokens)的语义信息。大规模预训练模型可以使用诸如bert、roberta、erine、albert、gpt
等通用的预训练模型,可以是类似网络结构的专用的预训练模型,比如用金融语料训练的fin
‑
bert、用电网领域语料训练的ele
‑
bert、用船舶领域训练的ship
‑
bert等。
34.在获得语义向量之后,下游任务使用了四个不同的模型来实现文本理解的四个任务。
35.其中实体类型识别和关系类型识别共用了卷积神经网络(cnn),并使用各自的softmax分类器来实现实体类型的分类和关系类型的分类,理解出相应的实体类型和关系类型,并识别出对应的关键文本片段。比如架构图中的例子是,“谁”表征了“人物”这个实体类别,而“扮”和“演”两个词元表征了“<人物,饰演,人物>”的关系。
36.实体识别任务直接在语义向量之后使用crf进行序列标注,实现了实体抽取,抽取出输入文本中的实体以及所对应的实体类型。注意实体抽取和实体类型识别是有区别的,实体抽取是抽取出文本中哪些文本片段是一个实体,以及所对应的实体类型,比如架构图中的“晴雯”是一个“人物”的实体。而实体类型识别要识别的并不是实体,而是有可能表示实体类型的词,比如架构图中的“谁”表示了“人物”这个实体类别。
37.在问句分类中,使用了bi
‑
lstm模型从词元的语义向量中进一步进行理解,获得全局的语义信息,将问句分为不同的类别,比如上述架构图中的四种类别,包括事实类、统计类、是非类和关系类。但本发明不局限于具体的类别,在不同的应用场景中可以调整为适合该场景下的类别。上图中返回的是“事实类”,结果应该返回一个人物的实体,以及实体所对应的各种属性信息。而对于“统计类”,则需调用各种聚合算法来进行统计计算,返回统计结果。比如“福建省有几个地级市?”则需要对福建省的地级市的数量进行计算,返回计算结果。对于“是非类”则返回逻辑判断结果,比如“厦门市是属于福建省的么?”返回结果“是”。对于“关系类”则需要从图谱中获取实体间的关系。比如“福州市和福建省是什么关系?”返回“<地点,省会,地点>”的关系。
38.尽管上述实施例已对本发明作出具体描述,但是对于本领域的普通技术人员来说,应该理解为可以在不脱离本发明的精神以及范围之内基于本发明公开的内容进行修改或改进,这些修改和改进都在本发明的精神以及范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。