技术特征:
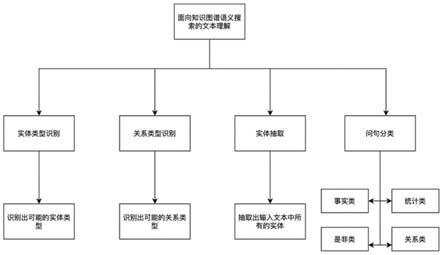
1.一种用于知识图谱语义搜索的文本理解的方法,其特征在于,针对输入的待理解的文本,所述方法包括如下步骤:通过大规模预训练模型获得文本中每个词元的语义信息,生成语义向量;基于所述语义向量,通过卷积神经网络、实体分类用的第一softmax分类器和关系分类用的第二softmax分类器,识别出实体类型和关系类型;基于所述语义向量,通过crf进行序列标注,抽取出实体;基于所述语义向量,通过bi
‑
lstm模型和问句分类用的第三softmax分类器,将文本进行分类;基于识别出的实体类型和关系类型、抽取出的实体、文本的分类结果,检索知识图谱获取信息作为反馈。2.根据权利要求1所述的用于知识图谱语义搜索的文本理解的方法,其特征在于,所述大规模预训练模型使用bert、roberta、erine、albert、gpt中的一种。3.根据权利要求1所述的用于知识图谱语义搜索的文本理解的方法,其特征在于,所述将文本的分类结果包括事实类、统计类、是非类和关系类。4.一种计算机存储介质,其特征在于,所述存储介质中存储有计算机程序,所述计算机程序被执行时实现权利要求1
‑
3中任一所述的方法。5.一种用于知识图谱语义搜索的文本理解的系统,其特征在于,所述系统包括:语义获取模块,用来通过大规模预训练模型获得文本中每个词元的语义信息,生成语义向量;实体分类模块,用来基于所述语义向量,通过卷积神经网络和实体分类用的第一softmax分类器,识别出实体类型;关系分类模块,用来基于所述语义向量,通过卷积神经网络和关系分类用的第二softmax分类器,识别出关系类型;实体抽取模块,用来基于所述语义向量,通过crf进行序列标注,抽取出实体;问句分类模块,用来基于所述语义向量,通过bi
‑
lstm模型和问句分类用的第三softmax分类器,将文本进行分类;检索反馈模块,用来基于识别出的实体类型和关系类型、抽取出的实体、文本的分类结果,检索知识图谱获取信息作为反馈。
技术总结
本发明公开了一种用于知识图谱语义搜索的文本理解的方法,针对输入的待理解的文本,所述方法包括如下步骤:通过大规模预训练模型获得文本中每个词元的语义信息,生成语义向量;基于所述语义向量,通过卷积神经网络、实体分类用的第一softmax分类器和关系分类用的第二softmax分类器,识别出实体类型和关系类型;基于所述语义向量,通过CRF进行序列标注,抽取出实体;基于所述语义向量,通过Bi
技术研发人员:陈运文 王文广 贺梦洁 纪达麒 桂洪冠 金克 冯佳妮 纪传俊
受保护的技术使用者:达观数据(苏州)有限公司
技术研发日:2021.07.30
技术公布日:2021/11/24
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。