基于fpga的低延时非极大值抑制方法与装置
技术领域
1.本发明属于目标检测技术领域,本发明涉及一种基于fpga的低延时非极大值抑制方法与装置。
背景技术:
2.基于神经网络的目标检测算法由于其精度高成为目标检测主流算法,而现场可编程门阵列(field
‑
programmable gate array,fpga)平台由于灵活性高、成本低等优势成为常用的算法部署平台。
3.然而,针对目标检测算法的低延时硬件实现研究,通常着眼于加速神经网络部分,而忽略了后处理部分的优化。其中,非极大抑制(non
‑
maximum suppression,nms)算法是常见的后处理算法,传统的nms算法步骤见图1。由于传统的nms算法需要多次整体排序,而排序算法难以通过并行化、流水线等常用方法进行优化,因此其实现效率低、耗时久。
4.fast nms是一种优化算法速度的代表性算法,其相较于传统的nms算法利用矩阵运算优化排序算法,从而可以更好的利用图形处理器的并行特性,得到速度的提升。然而,该算法在硬件上将消耗大量的计算资源,且不同输入图片的每次排序对应的排序矩阵大小均不同,因此难以在fpga平台部署。
5.专利《基于fpga的点云网络的非极大值抑制方法》、《一种基于非极大值抑制算法的fpga加速方法》提出了基于fpga实现的nms算法加速。然而两个发明均针对点云网络技术领域,仍然采用传统的nms算法,主要通过并行流水计算加速。因此该加速方法每得到一个回归框仍需要对剩余所有候选框的置信度进行排序,仅能够通过增加运算资源加速单次整体排序速度,优化有限。
6.文章《efficient hardware post processing of anchor
‑
based object detection on fpga》提出了目标检测后处理的高效硬件实现,包括解码以及nms算法。然而该实现同样未进行算法层面优化,性能提升主要通过并行计算以及索引变换代替缓存框重排序优化,依旧无法优化启动延时。
7.同时,现有的nms算法并非硬件友好算法,其每次迭代产生一个回归框输出需要经历一次所有候选框排序,导致算法启动需要等待所有候选框计算完成。此外由于候选框数目庞大需要片外缓存,需要多次片内外交互,导致在fpga平台上部署困难且实时性很差。
技术实现要素:
8.本发明针对上述现有的nms算法与装置延时久的问题,提出了一种基于fpga的低延时非极大值抑制方法与装置。省去了现有各nms算法均需要的整体排序步骤,降低启动延时,且其可通过灵活的参数配置满足不同的计算速度与精度要求。该装置采用流水线架构,可与流水线架构的神经网络加速器兼容,缩短了目标检测算法整体延迟。
9.本发明的技术解决方案如下:
10.一种基于fpga的低延时非极大值抑制方法,其特点在于,该方法包括以下步骤:
11.步骤1:根据当前应用场景下目标检测的数据集,初始化数据集所需输出回归框数上限l、交并比(intersection over union,iou)阈值iou_th、置信度阈值conf_th,以及串行的候选框;
12.步骤2:根据初始化参数以及资源限制,计算中间缓存的最大候选框数m
max
、算法实际输出回归框数上限l’;
13.步骤3:获取串行的候选框中第一个候选框,并存储至中间缓存中;
14.步骤4:获取串行的候选框中下一个候选框box
i
,根据中间缓存候选框的置信度从大到小依次计算候选框box
i
与中间缓存候选框之间的iou并更新中间缓存,其中,若iou>iou_th,则根据两者置信度大小删去中间缓存候选框或标记候选框box
i
已覆盖,并根据置信度大小重新排序,得到更新的中间缓存候选框;若iou≤iou_th,则判断候选框box
i
是否已经被缓存或覆盖,并根据置信度大小重新排序,得到更新的中间缓存候选框;直至所有串行的候选框获取完毕;
15.步骤5:输出中间缓存候选框前l’个回归框,作为非极大值抑制计算结果;
16.步骤6:计算在当前应用场景下采用该算法的精度,与精度要求比较,若不满足,降低数据集所需的输出回归框数上限l,返回至步骤2,否则,完成算法以及硬件实现。
17.所述步骤2计算中间缓存的最大候选框数m
max
、算法实际输出回归框数上限l’,具体步骤如下:
18.步骤2
‑
1:根据串行候选框输入的间隔时钟周期数n,得到该输入条件下允许的中间缓存候选框数最大值m
max
‑
time
=n
‑
5;
19.步骤2
‑
2:根据数据集所需输出回归框数上限l、iou
阈值
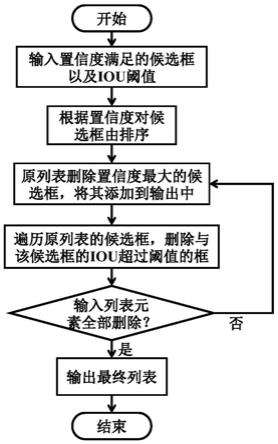
、置信度
阈值
,计算数据集所需中间缓存候选框数m
max
‑
dataset
,具体步骤如下:
20.步骤2
‑2‑
1:寻找m个候选框,要求这m个候选框与另一候选框间iou均超过阈值,且这m个候选框间彼此iou未超过iou阈值,计算m的最大值m
max
‑
single
,
21.步骤2
‑2‑
2:计算数据集所需中间缓存候选框数m
max
‑
dataset
=1 (l
‑
1)
×
m
max
‑
single
;
22.步骤2
‑
3:计算过程中间缓存候选框数取数据集所需中间缓存候选框数与输入条件下允许的中间缓存候选框数最大值中较小值,即m
max
=min(m
max
‑
dataset
,m
max
‑
time
);
23.步骤2
‑
4:单张图最终输出回归框数上限选择该应用场景下的输出回归框数上限与计算过程中间缓存候选框数中较小值,即l’=min(m
max
,l)。
24.所述步骤4中间缓存候选框,具体包括:
25.步骤4
‑
1:设定目前比较的中间缓存候选框地址为0,将输入候选框已缓存、输入候选框已被覆盖的标志置为0;
26.步骤4
‑
2:计算输入候选框与对应地址的中间缓存候选框间的iou,判断是否超过iou阈值;
27.步骤4
‑
3:若iou超过阈值,比较输入候选框与对应地址的中间缓存候选框置信度大小,更新中间缓存候选框,具体步骤如下:
28.步骤4
‑3‑
1:若输入候选框置信度超过对应地址的中间缓存候选框,则判断输入候选框状态,更新中间缓存候选框,具体步骤如下:
29.步骤4
‑3‑1‑
1:若输入候选框已缓存或已被覆盖,则直接删去该中间缓存候选框,将之后地址的中间缓存候选框前移,最后一个中间缓存候选框置为0;
30.步骤4
‑3‑1‑
2:否则用输入候选框替换该中间缓存候选框,将输入候选框已缓存标志置为1;
31.步骤4
‑3‑
2:若输入候选框置信度未超过对应地址的中间缓存候选框,则输入候选框已被覆盖的标志置为1;
32.步骤4
‑
4:若iou未超过阈值,比较输入候选框与对应地址的中间缓存候选框置信度大小,更新中间缓存候选框,具体步骤如下:
33.步骤4
‑4‑
1:若输入候选框置信度超过对应地址的中间缓存候选框,则判断输入候选框状态,更新中间缓存候选框,具体步骤如下:
34.步骤4
‑4‑1‑
1:若输入候选框已缓存或已被覆盖,则无需操作;
35.步骤4
‑4‑1‑
2:否则将输入候选框插入到该候选框之前,将之后地址的中间缓存候选框后移,若缓存候选框数量已达到上限则删去置信度最小的候选框,将输入候选框已缓存标志置为1;
36.步骤4
‑4‑
2:若输入候选框置信度未超过对应地址的中间缓存候选框,则无需操作;
37.步骤4
‑
5:若中间缓存候选框地址已经到达底部,则跳转至步骤5;否则中间缓存候选框地址加一,跳转至步骤4
‑
2。
38.本发明还提供了一种基于fpga的低延时非极大值抑制装置,其特点在于,包括:中间候选框缓存模块、iou计算模块、中间缓存更新逻辑模块与地址控制模块;
39.地址控制模块,负责产生输入候选框的计数信号与当前正在比较的中间缓存候选框地址信号,将其传递至中间候选框缓存模块与中间缓存更新逻辑模块;
40.中间候选框缓存模块,负责缓存中间候选框、根据地址控制模块的当前正在比较的中间缓存候选框地址信号将该候选框信息传递至iou计算模块、根据中间缓存更新逻辑模块产生的更新指令以及当前输入候选框box
i
更新中间缓存候选框;
41.iou计算模块,负责计算中间候选框缓存模块传递的候选框与当前输入候选框box
i
的iou与置信度大小关系,将其传递至中间缓存更新逻辑模块;
42.中间缓存更新逻辑模块,负责根据iou计算模块产生的iou与置信度大小关系以及当前输入候选框box
i
的状态信号,产生更新控制信号与当前输入候选框box
i
的状态信号。
43.所述的更新控制信号包括是否缓存当前输入候选框box
i
、是否删除当前正在比较的中间缓存框;状态信号包括当前输入候选框box
i
是否已经覆盖、是否已经缓存。
44.所述的装置的输入为串行候选框,同一时间最多仅有一个候选框输入,输出为回归框,其中,中间候选框缓存数量等参数根据权利要求2确定,对于单个应用不再更改。
45.解码模块包括解码逻辑以及并
‑
串转换缓存。神经网络加速器讲带编码候选框部分并行输入该模块,解码逻辑将其转化为解码后的部分并行候选框,而后经过并
‑
串转换缓存转化为串行候选框输出至nms模块。
46.nms模块包括中间候选框缓存、iou计算、中间缓存更新逻辑与地址控制。其中,中间候选框缓存数量根据应用场景确定,对于单个应用不再更改。地址控制模块确定当前比较候选框地址,每次从0开始遍历所有中间缓存。单个候选框输入后,与比较候选框分别比
较iou以及置信度,将结果以及此时地址送入中间缓存更新逻辑,其判断此时应当如何更新候选框,并将该信号传递至中间候选框缓存。
47.与现有技术相比,本发明的有益效果为:
48.1)提出的算法省去了现有的nms算法均需要的整体排序步骤,改为每输入一个候选框将其与已输入且保留的候选框比较,得到新的保留候选框。因此该算法可以在单个候选框计算完成后启动,从而降低启动延时;
49.2)提出的算法可通过灵活的参数配置满足不同的计算速度与精度要求。在应用场景单张图候选框数量小或存储资源充足、串行候选框输入时间间隔足够久的条件下,不考虑量化误差可以做到无精度损失加速计算,否则将牺牲精度换取加速;
50.3)提出的装置基于流水线架构,其实现目标检测的后处理的nms算法。当目标检测算法采用该装置以及流水线架构的前端处理时,除最后一个候选框的解码与排序过程,后处理部分其余延时均被前端处理延时覆盖,而现有的nms算法需要等待所有候选框运算完成后才能开始计算,无法实现延时覆盖。此外,该装置无需片外存储,降低了存储开销与通信延时。以上两特性结合,最终采用该装置的nms算法实现在整体目标检测算法中增加的延时为从最后一个候选框输入至回归框结果输出的延时,在数十到数百纳秒级。
51.4)遥感图像技术以及红外图像技术的发展,对目标检测技术在实时性以及精度上有了更高的要求。尤其是在无人驾驶、航空航天等领域,目标检测技术的实时性与精度将直接影响系统的安全性与准确性。本发明降低了整体目标检测算法的延时,从而提升了应用的性能与可靠性。
附图说明
52.图1为传统的nms算法流程图
53.图2为本发明的nms算法流程图
54.图3为采用本发明装置的目标检测算法顶层时序示意图
55.图4为本发明装置的顶层框图
具体实施方式
56.为了使本发明实现的措施、创作特征、达成目的与功效易于明白了解,为解决现有技术中针对现有nms算法的硬件实现延时较高的问题,本发明提出了一种基于fpga的低延时非极大值抑制方法与装置。省去了现有各nms算法均需要的整体排序步骤从而提升启动延时,且可通过灵活的参数配置满足不同的计算速度与精度要求,其流程图见图2。该装置易与流水线架构的神经网络加速器级联,从而显著降低整体系统的延时,其顶层框图见图4。
57.下面将结合附图,进一步阐述本发明在fpga平台上实现的具体步骤。
58.此处实施基于yolov2
‑
tiny网络,设定非极大值抑制过程中各分类一同比较,单张图最终输出回归框数至多为3个,iou以及置信度阈值为0.4,神经网络加速器输出单个候选框全部参数的平均时间为32个时钟周期,且对精度无硬性要求。
59.本发明主要包括以下步骤:
60.步骤1:根据当前应用场景下目标检测的数据集,初始化数据集所需输出回归框数
上限l、iou阈值iou_th、置信度阈值conf_th,以及串行的候选框,该实施下即有l=3、iou_th=0.4、conf_th=0.4;
61.步骤2:根据初始化参数以及资源限制,计算中间缓存的最大候选框数m
max
、算法实际输出回归框数上限l’,具体步骤如下;
62.步骤2
‑
1:根据串行候选框输入的间隔时钟周期数n,得到该输入条件下允许的中间缓存候选框数最大值m
max
‑
time
=n
‑
5,该实施下即有n=32,从而m
max
‑
time
=27;
63.步骤2
‑
2:根据数据集所需输出回归框数上限l、iou
阈值
、置信度
阈值
,计算数据集所需中间缓存候选框数m
max
‑
dataset
,具体步骤如下:
64.步骤2
‑2‑
1:寻找m个候选框,要求这m个候选框与另一候选框间iou均超过阈值,且这m个候选框间彼此iou未超过iou阈值,计算m的最大值m
max
‑
single
,该实施下即有m
max
‑
single
=5;
65.步骤2
‑2‑
2:计算数据集所需中间缓存候选框数m
max
‑
dataset
=1 (l
‑
1)
×
m
max
‑
single
,该实施下即有m
max
‑
dataset
=11;
66.步骤2
‑
3:计算过程中间缓存候选框数取数据集所需中间缓存候选框数与输入条件下允许的中间缓存候选框数最大值中较小值,即m
max
=min(m
max
‑
dataset
,m
max
‑
time
),该实施下即有m
max
=11;
67.步骤2
‑
4:单张图最终输出回归框数上限选择该应用场景下的输出回归框数上限与计算过程中间缓存候选框数中较小值,即l’=min(m
max
,l),该实施下即有l’=3。
68.步骤3:获取串行的候选框中第一个候选框,并存储至中间缓存中;
69.步骤4:获取串行的候选框中下一个候选框box
i
,根据中间缓存候选框的置信度从大到小依次计算候选框box
i
与中间缓存候选框之间的iou并更新中间缓存,其中,若iou>iou_th,则根据两者置信度大小删去的中间缓存候选框或标记候选框box
i
已覆盖,并根据置信度大小重新排序,得到更新的中间缓存候选框;若iou≤iou_th,则判断候选框box
i
是否已经被缓存或覆盖,并根据置信度大小重新排序,得到更新的中间缓存候选框;直至所有串行的候选框获取完毕。具体步骤如下;
70.步骤4
‑
1:设定目前比较的中间缓存候选框地址为0,将输入候选框已缓存、输入候选框已被覆盖的标志置为0;
71.步骤4
‑
2:计算输入候选框与对应地址的中间缓存候选框间的iou,判断是否超过iou阈值;
72.步骤4
‑
3:若iou超过阈值,比较输入候选框与对应地址的中间缓存候选框置信度大小,更新中间缓存候选框,具体步骤如下:
73.步骤4
‑3‑
1:若输入候选框置信度超过对应地址的中间缓存候选框,则判断输入候选框状态,更新中间缓存候选框,具体步骤如下:
74.步骤4
‑3‑1‑
1:若输入候选框已缓存或已被覆盖,则直接删去该中间缓存候选框,将之后地址的中间缓存候选框前移,最后一个中间缓存候选框置为0;
75.步骤4
‑3‑1‑
2:否则用输入候选框替换该中间缓存候选框,将输入候选框已缓存标志置为1;
76.步骤4
‑3‑
2:若输入候选框置信度未超过对应地址的中间缓存候选框,则输入候选
框已被覆盖的标志置为1;
77.步骤4
‑
4:若iou未超过阈值,比较输入候选框与对应地址的中间缓存候选框置信度大小,更新中间缓存候选框,具体步骤如下:
78.步骤4
‑4‑
1:若输入候选框置信度超过对应地址的中间缓存候选框,则判断输入候选框状态,更新中间缓存候选框,具体步骤如下:
79.步骤4
‑4‑1‑
1:若输入候选框已缓存或已被覆盖,则无需操作;
80.步骤4
‑4‑1‑
2:否则将输入候选框插入到该候选框之前,将之后地址的中间缓存候选框后移,若缓存候选框数量已达到上限则删去置信度最小的候选框,将输入候选框已缓存标志置为1;
81.步骤4
‑4‑
2:若输入候选框置信度未超过对应地址的中间缓存候选框,则无需操作;
82.步骤4
‑
5:若中间缓存候选框地址已经到达底部,则跳转至步骤5;否则中间缓存候选框地址加一,跳转至步骤4
‑
2。
83.步骤5:输出中间缓存候选框前l’个回归框,作为非极大值抑制计算结果;
84.步骤6:计算在当前应用场景下采用该算法的精度,与精度要求比较,若不满足,降低数据集所需的输出回归框数上限l,返回至步骤2,否则,完成算法以及硬件实现。由于该实施无精度要求,即实施完成。
85.本发明已经在fpga上验证实现,通过与一个细粒度流水线架构的yolov2
‑
tiny神经网络的硬件加速器级联,该非极大值抑制算法可以在200mhz时钟下成功运行。本发明延时受控于神经网络加速器输出速度,其整体网络的延时组成见图3。可以看出,除最后一个候选框的解码与排序过程,算法其余延时均被上一级流水线覆盖,而现有的nms算法需要等待所有候选框运算完成后才能开始计算,无法实现延时覆盖,因此本算法为硬件友好的低延时nms算法。从最后一个候选框输入至回归框结果输出的延时为k 5个时钟周期,在本次设定下仅为80ns。
86.本发明装置的顶层框图见图4,装置包括解码模块以及nms模块。
87.解码模块包括解码逻辑以及并
‑
串转换缓存。神经网络加速器讲带编码候选框部分并行输入该模块,解码逻辑将其转化为解码后的部分并行候选框,而后经过并
‑
串转换缓存转化为串行候选框输出至nms模块。
88.nms模块包括中间候选框缓存、iou计算、中间缓存更新逻辑与地址控制。其中,中间候选框缓存数量根据应用场景确定,对于单个应用不再更改。地址控制模块确定当前比较候选框地址,每次从0开始遍历所有中间缓存。单个候选框输入后,与比较候选框分别比较iou以及置信度,将结果以及此时地址送入中间缓存更新逻辑,其判断此时应当如何更新候选框,并将该信号传递至中间候选框缓存。
89.为了验证该算法对精度的影响,分别本次精度测试针对yolov2 tiny网络在kitti数据集下以及yolov3网络在coco2014数据集下,假定单张图最终输出回归框数上限以及计算过程中间缓存候选框数均选择无穷大,测试了目标检测精度,此处以iou阈值为0.5条件下各类别平均准确率(mean average precision,map)为标准,得到结果如表1。其中,由于时间所限,未针对本发明的非极大值抑制算法进行重训练,重训练后或许精度能进一步提升。
90.表1.理想条件下不同非极大值抑制算法对精度的影响
[0091][0092]
可以看出,在假定存储资源无限、前端神经网络加速器低速的理想条件下,本发明的非极大抑制算法几乎无精度损失。
[0093]
此外,为了验证资源限制条件下该算法对精度的影响,针对yolov3网络在coco2014数据集下测试精度。为了更公平比较,计算传统的非极大抑制算法在限定单张图最终输出回归框数上限为3时精度,与本发明在单张图最终输出回归框数上限为3、所需中间缓存候选框数为11时精度,得到结果如表2。
[0094]
表2.限制条件下不同非极大值抑制算法对精度的影响
[0095]
非极大抑制算法传统的非极大抑制算法本发明的非极大抑制算法map@0.545.6645.69
[0096]
可以看出,当对不同的非极大值抑制算法均施加最终输出回归框数限制时,两者精度几乎相同,而最终输出回归框数限制取决于实际应用场景。因此本发明的非极大抑制算法在应用场景单张图候选框数量小或存储资源充足、前端神经网络加速器速度足够低的条件下,不考虑量化误差可以做到无精度损失加速计算,否则将牺牲精度换取加速。
[0097]
本发明方案所公开的技术手段不仅限于上述实施方式所公开的技术手段,还包括由以上技术特征任意组合所组成的技术方案。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。