1.本发明属于表格识别领域,具体涉及一种图片中表格线条的补全方法与图片中表格的识别方法。
背景技术:
2.工业界常用的表格识别方法:
3.1.基于规则的表格识别方法:首先利用ocr技术检测出文本,从文本框的位置信息推导出行列及单元格信息,然后生成电子表格。缺陷:极度依赖ocr检测结果和人工设计的规则,需要做针对性开发,推广性较差。
4.2.基于线条纹理的表格识别方法:运用形态学变换、纹理提取、边缘检测等手段,提取表格线,再由表格线推导出行列及合并单元格信息。缺陷:依赖传统图像处理算法,在鲁棒性方面较欠缺,针对无线表格的行列信息挑战较大。
5.3.基于深度学习的方法:利用神经网络进行端到端的学习表格信息,将表格图片转化为某种结构化描述语言(比如html定义表格结构)。缺陷:表格结构一旦出现错误,无法从中间步骤快速干预修复,只能重新调整模型,不适合工程落地。
技术实现要素:
6.针对现有技术中存在的问题,本发明提供一种图片中表格线条的补全方法,本发明的部分实施例能够具有较高的通用性,适用于全线、少线、无线的电子表格表格,并且对于质量较差的扫描件、手持拍摄图片同样具有较强的抗干扰能力。该系统通过融合线条纹理,文本框位置,文本框语义多模态信息快速重建出表格的结构及文本信息,实现纸质文档一键转化为直接可编辑的电子文档,解决传统方案中识别内容丢失和文档格式不兼容等问题,减少了用户后期重复编辑的时间,大大提升了用户的工作效率。
7.为实现上述目的,本发明采用以下技术方案:
8.一种图片中表格线条的补全方法,所述补全方法包括添加横线和/或竖线,所述添加竖线包括:s11针对识别出表格的目标区域,去除跨列的合并单元格;s12对目标区域进行垂直投影,得到表格列之间的空白区域;s13利用空白区域的边界作为表格竖线。
9.优选地,所述添加横线包括:s21对表格文本内容进行细粒度的分行及分列处理;s22利用强规则判断行是否进行合并;s23利用nlp信息判断是否合并剩余的同列文本框。
10.一种图片中表格的识别方法,所述识别方法包括:s31矫正图片;s32定位图片中的表格区域;s33检测表格中已有的实际线条;s34通过补全方法添加虚拟线条;s35重构单元格。
11.优选地,所述s32还包括:s321使用深度学习目标检测算法定位表格区域;s322判断表格类型;s323过滤噪声表格。
12.优选地,所述s33还包括:s331使用卷积神经网络算法对实际线条进行检测;s332用线条纹理模态使用几何分析得到每条横竖线的位置;s333过滤噪声线条。
13.优选地,所述s35还包括:s351利用表格线条重构出单元格,包括行、列、单元格位置信息;s352利用文本及单元格的相对位置进行内容填充。
14.一种计算机可读存储介质,所述可读存储介质存储有计算机指令,所述指令被处理器运行时实现任一所述的图片中表格的识别方法。
15.一种图片中表格的识别装置,所述识别装置包括:矫正单元,用来矫正图片;定位单元,用来定位图片中的表格区域;检测单元,用来检测表格中已有的实际线条;补全单元,用来通过补全方法添加虚拟线条;重构单元,用来重构单元格。
16.与现有技术相比,本发明的有益效果为:能够充分利用多模态的协同表示高准确率的重构出表格结构;具有通用级别的文档矫正模块;支持透视、倾斜、背景色、印章等表格文档的识别;具有方便的功能拓展能力,具有丰富的参数与脚本,能够快速对接不同的表格识别场景
附图说明
17.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
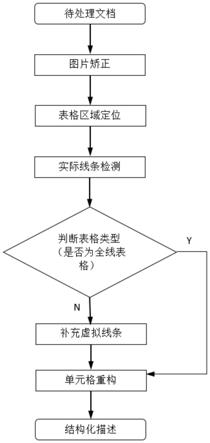
18.图1为实施例中一种基于多模态的通用表格识别系统的处理流程示意图。
具体实施方式
19.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有付出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
20.在本发明的描述中,需要理解的是,术语“纵向”、“横向”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
21.如图1所示,本实施例提供一种基于多模态的通用表格识别系统,主要包括以下几个模块:数据预处理模块、基于图像分割网络的图片矫正模块、基于深度学习的的表格区域检测模块、基于卷积神经网络的实际线条检测模块、ocr识别模块、基于文本位置及nlp语义信息的虚拟线条添加模块及单元格重构模块。
22.该系统充分利用数据的多样性,通过实际线条纹理、文本位置、文本语义等多模态的协同表示,重构出更加准确的表格结构,相对于传统规则及基于深度学习的表格识别方法具有更高的识别准确率、更强的鲁棒性。
23.一种基于多模态的通用表格识别系统,其处理流程如下:
24.1.数据预处理:输入支持docx、doc、pdf、txt、png、jpg、jpeg、tif、tiff、扫描件等多种文档格式,将文档转化为单页图片。
25.2.图片矫正:
26.a)为了提高后处理及ocr识别的质量,对图片进行倾斜矫正。使用深度学习分割网络对文本区域进行像素级分割。
27.b)利用几何方法计算出文本区域的外接四边形,为了得到更多的图片信息,对外接四边形的四条边平移相交于图片边界得到最值。
28.c)然后使用四个点的最值进行透视变换,得到矫正后的图片。
29.3.表格区域定位步骤:
30.a)使用改进版本的轻量级的多尺度深度学习目标检测算法定位表格区域,同时判断出表格类型(全线、少线、无线)
31.b)噪声表格过滤
32.4.实际线条检测步骤:
33.a)使用优化后的卷积神经网络算法对实际线条进行检测
34.b)利用线条纹理模态使用几何分析得到每条横竖线的位置
35.c)噪声线条的过滤
36.5.添加虚拟线条步骤:
37.a)针对少线及无线表格进行加虚拟横线处理
38.i.首先对表格文本内容进行细粒度的分行及分列处理
39.ii.首先利用强规则判断行是否进行合并:比如带百分位的数字不能合并,特定格式的日期需要合并等
40.iii.然后利用nlp信息判断是否合并剩余的同列文本框
41.b)针对少线及无线表格进行加虚拟竖线处理
42.i.竖直方向去除跨列的合并单元格,得到非合并单元格(此处,去除指将合并单元格背景化,比如整个合并单元格区域做暂时性的白色覆盖处理)
43.ii.针对非合并单元格进行垂直投影,得到列之间的空白区域
44.其中,垂直投影的实现步骤包括:
45.1图像二值化,物体为黑,背景为白;
46.2循环各列,依次判断每一行的像素值是否为黑,统计该列所有黑像素的个数。
47.6.单元格重构
48.a)利用表格线条重构出单元格(行、列、单元格位置信息)
49.i.横线个数减一作为表格行数m,竖线个数减一作为表格列数n
50.ii.单元格个数为m*n
51.iii.单元格i*j的位置由第i及i 1的横线位置,第j及j 1的竖线位置构成
52.b)利用文本及单元格的相对位置进行内容填充
53.c)合并单元格重构:利用线条和单元格的位置判断该单元格是否为合并单元格。
54.尽管上述实施例已对本发明作出具体描述,但是对于本领域的普通技术人员来说,应该理解为可以在不脱离本发明的精神以及范围之内基于本发明公开的内容进行修改或改进,这些修改和改进都在本发明的精神以及范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。