1.本发明涉及深度学习领域,尤其涉及了基于人脸识别系统的人脸图像质量标注方法及装置。
背景技术:
2.人脸图像质量分析(face image quality analysis,fiqa)是人脸识别系统投入实际使用中必不可少的前端处理模块。
3.它通过滤除不合适的抓拍人脸,可保证进入后续人脸识别流程人脸图像的优质性,从而减少误报(即抓拍人脸匹配到错误的底库照片)以及通过推出最优帧人脸从而节省后续人脸识别所需消耗的算力。
4.目前人脸质量分析最大问题在于质量分标签的制定。与图像质量分析(image quality analysis)任务不同,它除去要考虑图像本身存在的噪声、编解码以及失焦等问题,更重要的还要考虑其识别目标(人脸)的质量。影响人脸质量的因素通常包括:人脸姿态、遮挡程度、模糊程度以及曝光程度等。抛却稍微更为客观的图像本身质量不谈,上述关于人脸质量的因素实际上很难去获得所谓的真值(ground truth);此时若还要同时考虑多个因素,对质量标签的制定是一个很大的挑战。
5.基于人工的质量标签制作方法(简称人工法)依赖于人为主观判定,通过人的大脑直接综合分析上述各个因素,给出最终的质量分标签;但由于所需考虑的因素过多以及没有客观标准,会发生即便是同一个样本,同一标注人员也会在不同标注回合中给出不同标注分数的现象。因此,数据需要反复的清洗造成消耗人力过大成了人工标注法的最大缺陷。若每个因素单独采用人工判定,从而避免主观性过多的问题,仍需要大量人力来完成多个单任务训练数据的制作,而后续如何对各个因素进行综合也需要大量尝试和思索。实际业务逻辑中,人脸质量通常是作为人脸识别系统的前端处理模块存在,其作用是减少识别系统的误报以及算力。
6.基于此前提,机器标注法给出的结果除去有着更为客观的优点,与人脸识别系统识别能力也更为耦合。当前的机器标注法通常是将同一id(identity)的人脸抓拍样本与其参考照(底库)人脸特征向量的相似度或其函数映射作为该抓拍样本的质量分标签,从而产生客观且高效的质量分标注流程。
7.例如现有技术中专利申请号为:cn202010822252.8;专利申请日为:2020
‑
11
‑
20;专利申请名称为:一种人脸图像质量评分标注方法及装置,该方法包括:将集内待测人脸图像和集外噪声人脸图像经过人脸识别网络,得到相应的人脸特征向量;其中,每个人至少包含一张参考图;根据第i个人的参考图特征和其他不同人的参考图特征,计算示性函数;基于所述示性函数,计算第i个人的第k张待测图的质量值;对所述质量值做线性变换,得到第i个人的第k张待测图的最终标签值;利用所述最终标签值进行人脸质量评估模型训练。该方法综合考虑了人脸特征的类内和类间距离,对用于质量评价任务的人脸图像训练样本进行打标签的任务。
8.通过将待标注样本与类内参考照人脸特征向量的相似度以及待标注样本与类外参考照人脸特征向量的相似度用softmax函数结合起来,给出人脸质量分样本标注分数。
9.但该方法对于质量分低(如遮挡,模糊人脸)的样本不能给出准确的标注;当该类样本与本人相似度高,同时与他人相似度低时,会得出较高的分数;而这样的标注分数对于后续质量分模型的训练来说是不正确的。
10.该方法对每个类的类内样本质量分布完整性要求较高,因此需要提前筛选出合适的类别,并且必须要求类内样本有至少一张参考照,增加了数据收集的困难程度。
技术实现要素:
11.本发明针对现有技术中数据收集的困难程度大的问题,提供了基于人脸识别系统的人脸图像质量标注方法及装置。
12.为了解决上述技术问题,本发明通过下述技术方案得以解决:
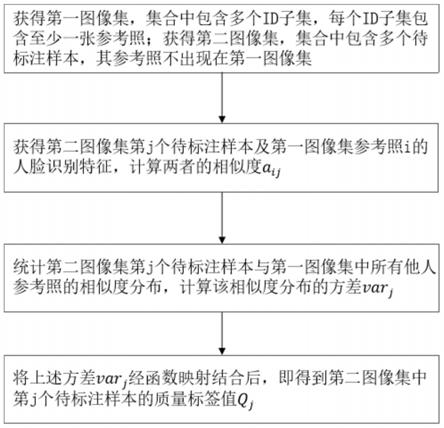
13.基于人脸识别系统的人脸图像质量标注方法,其方法包括;
14.图像集的获取,通过获取第一图像集和第二图像集;
15.人脸特征向量的获取,将第一图像集合第二图像集输入至人脸识别网络,从而获取人脸特征向量;
16.图像集相似度的计算,第二图像集中第j个待标注人脸与第一图像集子集i参考照的相似度的计算;
17.图像集相似度方差的计算,第二图像集第j个待标注人脸与第一图像集中所有子集的相似度进行相似度方差的计算;
18.人脸图像质量分标签值的确定,依据图像相似度的方差,确定人脸图像质量分数。
19.通过利用方差来反映待标注样本质量的好坏,与人脸识别系统识别能力耦合,且通过只考虑与他人相似度分布,标注结果也更为客观;不要求待标注样本需要有本人参考照,降低了数据收集的困难程度。
20.作为优选,第一图像集包括至少一个id子集,每个id子集包含至少一张参考图,各个id子集之间样本身份互不重叠;第二图像集包含多个待标注的样本,各待标注样本的参考照不出现在第一图像集中。
21.作为优选,图像集相似度的计算,将人脸识别特征向量与参考照人脸识别特征做向量内积,得到相似度值a
ij
,
[0022][0023]
公式1中,v
j
表示的是第二图像集第j个待标注人脸的人脸特征向量。v
i
表示的id子集i中参考照的人脸特征向量;||||表示对该向量取模;当向量除去本身模值后,即为归一化向量。
[0024]
作为优选,图像集相似度方差的计算,统计第二图像集第j个待标注人脸与第一图像集中所有id子集参考照的相似度,计算相似度分布的方差var
j
;
[0025]
[0026]
公式2中,a
sj
为第二图像集第j个待标注人脸与第一图像集合id子集s中参考照的相似度;为第二图像集第j个待标注人脸与id子集s(s=1,2...,n)参考照相似度分布的均值,n为第一图像集id子集的总数量。
[0027]
作为优选,人脸图像质量分值的确定依据线性结合的方法确定人脸质量分q
j
;
[0028]
q
j
=alpha*var
j
ꢀꢀꢀ
公式3
[0029]
公式3中,alpha为缩放因子。
[0030]
为了解决上述技术问题,提出了基于人脸识别系统的人脸图像质量标注装置,通过人脸图像质量标注方法实现的人脸图像质量标注装置;其包括图像收集单元、特征提取单元、第一计算单元和分数融合单元;
[0031]
图像收集单元,用于收集人脸识别系统中的第一图像集和第二图像集;
[0032]
特征提取单元,用于针对图像收集单元获取的图像集,基于人脸识别网络得到图像集中各样本的人脸特征向量;
[0033]
第一计算单元,用于针对每个待标注样本,计算其特征向量与第一图像集中参考照特征向量相似度分布的方差;
[0034]
分数融合单元,用于针对每个待标注样本,基于一定函数映射,映射第一计算单元输出分数,得到该样本的最终质量分标签值。
[0035]
作为优选,第一图像集包括至少一个id子集,每个id子集包含至少一张参考图,各个id子集之间样本身份互不重叠;第二图像集包含多个待标注的样本,各待标注样本的参考照不出现在第一图像集中。
[0036]
本发明由于采用了以上技术方案,具有显著的技术效果:本发明利用方差来反映待标注样本质量的好坏,与人脸识别系统识别能力耦合,且通过只考虑与他人相似度分布,标注结果也更为客观;不要求待标注样本需要有本人参考照,降低了数据收集的困难程度。
[0037]
通过本发明设计的人脸图像质量标注识别装置其标注效率高,标注质量准。
附图说明
[0038]
图1是本发明的方法流程图。
[0039]
图2是本发明的装置示意图。
[0040]
图3是本发明的相似度分布图。
[0041]
图4是本发明的人脸质量样本示意图。
具体实施方式
[0042]
下面结合附图1至附图4与实施例对本发明作进一步详细描述。
[0043]
实施例1
[0044]
基于人脸识别系统的人脸图像质量标注方法,其方法包括;
[0045]
图像集的获取,通过获取第一图像集和第二图像集;
[0046]
人脸特征向量的获取,将第一图像集和第二图像集输入至人脸识别网络,从而获取人脸特征向量;
[0047]
图像集相似度的计算,第二图像集中第j个待标注人脸与第一图像集子集i参考照的相似度的计算;
[0048]
图像集相似度方差的计算,第二图像集第j个待标注人脸与第一图像集中所有子集的相似度进行相似度方差的计算;
[0049]
人脸图像质量分标签值的确定,依据图像相似度的方差,确定人脸图像质量分数。
[0050]
通过利用方差来反映待标注样本质量的好坏,与人脸识别系统识别能力耦合,且通过只考虑与他人相似度分布,标注结果也更为客观;不要求待标注样本需要有本人参考照,降低了数据收集的困难程度。
[0051]
第一图像集包括至少一个id子集,每个id子集包含至少一张参考图,各个id子集之间样本身份互不重叠;第二图像集包含多个待标注的样本,各待标注样本的参考照不出现在第一图像集中。
[0052]
图像集相似度的计算,将人脸识别特征向量与参考照人脸识别特征做向量内积,得到相似度值a
ij
,
[0053][0054]
公式1中,v
j
表示的是第二图像集第j个待标注人脸的人脸特征向量。v
i
表示的id子集i中参考照的人脸特征向量;||||表示对该向量取模;当向量除去本身模值后,即为归一化向量。
[0055]
图像集相似度方差的计算,统计第二图像集第j个待标注人脸与第一图像集中所有id子集参考照的相似度,计算相似度分布的方差var
j
;
[0056][0057]
公式2中,a
sj
为第二图像集第j个待标注人脸与第一图像集合id子集s中参考照的相似度;为第二图像集第j个待标注人脸与id子集s(s=1,2...,n)参考照相似度分布的均值,n为第一图像集id子集的总数量。
[0058]
人脸图像质量分值的确定依据线性结合的方法确定人脸质量分q
j
;
[0059]
q
j
=alpha*var
j
ꢀꢀꢀ
公式3
[0060]
公式3中,alpha为缩放因子。
[0061]
实施例2
[0062]
在实施例1基础上,基于人脸识别系统的人脸图像质量标注方法实现的人脸图像质量标注装置;其包括图像收集单元、特征提取单元、第一计算单元和分数融合单元;
[0063]
图像收集单元,用于收集人脸识别系统中的第一图像集和第二图像集;
[0064]
特征提取单元,用于针对图像收集单元获取的图像集,基于人脸识别网络得到图像集中各样本的人脸特征向量;
[0065]
第一计算单元,用于针对每个待标注样本,计算其特征向量与第一图像集中参考照特征向量相似度分布的方差;
[0066]
分数融合单元,用于针对每个待标注样本,基于一定函数映射,映射第一计算单元输出分数,得到该样本的最终质量分标签值。
[0067]
实施例3
[0068]
在上述实施例基础上,在人脸识别系统的识别流程中,对于一张抓拍图,
[0069]
首先会计算其与数量为n的底库集中各个底库(i=1,2,...,n)的相似度,并最终分配给相似度最大的底库i;
[0070]
此时若分配正确,即抓拍图与底库为同一人,称为召回;
[0071]
若分配错误,即抓拍图与分配的底库并非同一人,称为误报。
[0072]
评价人脸识别系统的标准是召回率要大,误报率要小。
[0073]
反映到人脸向量特征上就是说,同一id下(类内)的人脸特征向量之间的距离要尽量近,不同id之间(类间)人脸特征向量间的距离要尽量远。以人脸识别任务损失函数arcface为例:
[0074][0075]
公式4中,n代表所有类的数量;θ
yi
为当前样本向量特征与类内(同一类)样本向量特征之间的夹角,θ
j
为当前样本向量特征与类间(不同类)样本向量特征之间的夹角;s和m分别为缩放因子和margin常数。上述损失函数的决策边界为:
[0076]
s(cos(θ
yi
m)
‑
cosθ
j
)=0
ꢀꢀꢀ
公式5
[0077]
公式5中,cosθ
yi
代表当前样本与类内样本特征向量之间的余弦距离值,也称相似度;cos(θ
yi
m)则为加入margin后当前样本与类内样本特征向量之间的余弦距离值;cosθ
j
代表当前样本与类间样本特征向量之间的相似度;对于每一个样本,损失函数的目标是让cos(θ
yi
m)>cosθ
j
。
[0078]
对于容易训练的(人脸质量分数高)优质样本来说,它的人脸特征明显,更易与其它类区分开来,应当更靠近类中心,也即cosθ
yi
值的会更大,同理cos(θ
yi
m)会大,因此cosθ
j
的上界也随之更大。统计完所有样本的cosθ
j
值,其分布近似服从高斯分布。当其人脸质量越好(越容易训练),其cosθ
j
分布的上界会更大,其分布的方差因此也会更大。
[0079]
选取2000张样本,共包含优、中、差三档质量档次人脸样本,每质量档次的人脸样本标准如附图4所示。将这三档样本分别统计与他人参考照的相似度分布,得到相应相似度分布后,再具体统计各相似度区间内样本个数占总区间样本个数的百分比,选取的区间长度为0.1。统计结果如附图3所示,其中纵坐标表示的是区间内样本个数占总区间样本个数百分比,横坐标为相似度区间边界值,需要注意的是为了更为直观清楚的展示,横坐标值放大为原来的十倍。
[0080]
附图展示了不考虑相似度正负符号的相似度分布,从图中可以看到各质量档次样本相似度分布不同区间内样本个数百分比占比随着相似度区间右移,逐渐降低;同时随着相似度区间右移,各质量档次之间随着档次的提升,区间内样本个数百分占比相对增加;需要注意的是,与他人相似度的相对分布(考虑相似度正负符号的相似度分布)服从高斯分布,即以均值为中心,两侧成对称性分布。以上统计结果反映了随着质量档次的提升,其相似度分布(相对分布)的方差相应增加;各质量档次相似度分布(相对分布)方差均值分别为0.00823,0.00873以及0.00906。
[0081]
利用该方差来反映待标注样本质量的好坏,与人脸识别系统识别能力耦合,且通过只考虑与他人相似度分布,标注结果也更为客观;另外,该方法不要求待标注样本需要有本人参考照,减少数据收集的困难程度。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。