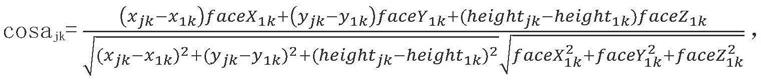1.本发明涉及人工智能机器人领域,具体涉及一种无唤醒机器人判断动作执行人是否为机器人的方法。
背景技术:
2.服务型机器人主要用于和用户进行沟通交流,然后实现特定功能。在一般情况下,语音输入唤醒词,如你好xx等现实生活中使用频率较低的词语,来唤醒机器人后,用户才能与机器人对话,但每次语音输入唤醒词不贴合现实生活以及使用较繁琐,因此无唤醒机器人相较有唤醒机器人显得更智能化。但无唤醒机器人在语音对话过程中无法判断用户是与机器人交流还是和身边人交流,因此无法给出响应的回复。
技术实现要素:
3.为了解决现有技术中存在的上述技术问题,本发明提出了一种无唤醒机器人判断动作执行人是否为机器人的方法,结合视觉、声源角度等信息,判断用户语音输入对话后,动作执行人是否为机器人,其具体技术方案如下:
4.一种无唤醒机器人判断动作执行人是否为机器人的方法,包括以下步骤:
5.步骤1,无唤醒机器人通过视觉模块和语音模块采集图像识别人物信息和用户语音输入信息,即视觉信息和语音声源信息,视觉信息包括人物信息和微动作信息,语音声源信息包括声源定位信息和语义理解信息;
6.步骤2,根据声源定位信息,判断出语音说话人;
7.步骤3,在确定语音说话人后,判断语音说话人的脸部朝向;
8.步骤4,根据语义理解源信息,提取动作执行人及意图,同时结合说话人的脸部朝向,识别微动作信息,判断说话人语音中的动作执行人是否为机器人。
9.进一步的,所述步骤1,具体包括:
10.步骤1.1,构建坐标系:机器人身高heightr,以机器人所在位置的地面为原点,机器人水平方向分别有x轴和y轴,机器人右向为x轴正方向,机器人正前方为y轴正方向,机器人垂直方向为z轴,上方为z轴正方向;
11.步骤1.2,通过机器人视觉模块获取人物水平位置状态信息和身高,构建表示人物信息的集合s;
12.步骤1.3,构建机器人专属意图集合y={专属意图1,专属意图2,专属意图3,
…
,专属意图n};
13.步骤1.4,构建提示对方要与其对话的微动作集合x={微动作1,微动作2,微动作3,
…
,微动作m},机器人视觉模块在用户语音输入过程中识别微动作,并明确该微动作的被执行人;
14.步骤1.5,机器人语音模块根据采集的语音声源信息,进行声源定位和语音语义理解。
15.进一步的,所述步骤1.2,具体为:机器人通过其视觉模块采集周边人物身高height,水平位置状态信息x,y,分别表示人物的水平位置x轴正方向坐标和y轴正方向坐标,脸部朝向向量(facex,facey,facez),以及信息id,id是周边人物的唯一标志,且同一人物,id不变且为正数;则构建人物信息集合为s={id,x,y,height,facex,facey,facez};所述机器人采集视觉信息的时间频率为f,即一秒时间内生成的信息数量,语音输入开始至语音输入结束持续时间为t秒,在t秒内生成的信息总量为集合e={s1,s2,s3,
…
,s
tf
},在集合e中共有tf个人物信息集合s。
16.进一步的,所述声源定位即获取开始说话时声源输入水平角度θ,0<=θ<2π,如人物在机器人正右方,θ=0;如人物在机器人右前方,如人物在机器人正前方,如人物在机器人左前方,如人物在机器人正左方,θ=π;如人物在机器人左后方,如人物在机器人正后方,如人物在机器人右后方,
17.所述语音语义理解即提取出相关动作执行人及其意图。
18.进一步的,所述步骤2,具体包括:
19.步骤2.1,当语音模块检测到有人开始说话,语音模块下发开始说话时声源输入水平角度θ;
20.步骤2.2,构建初始以原点为起点,指向x轴正方向,再逆时针水平旋转θ角度的单位向量具体为:
21.当θ=0时,
22.当时,
23.当时,
24.当时,
25.当θ=π时,
26.当时,
27.当时,
28.当时,
29.步骤2.3,提取开始说话时周边每个人物的信息集合s={id,x,y,height,facex,facey,facez},构建起点为原点,即机器人所在位置为原点,周边人物所在位置为终点的向量计算周边每个人物所对应的与之间的夹角:
[0030][0031]
计算周边每个人物所对应的夹角α,并选取α的最小值,即min(α)所对应的人物id为开口说话的人物id,同时记录该id。
[0032]
进一步的,所述步骤3,具体包括:
[0033]
步骤3.1,提取从开始说话至说话结束时间段内,机器人周边所有人物的集合e,设机器人周边拥有p个人物,设说话的人物所对应的集合为e1,其余人物所对应的集合分别为e2,e3,
…
,e
p
,同时建立集合e的下标与所对应人物的id一对一映射表q,即不同集合e的下标对应不同id,不同id对应不同集合e的下标;设集合e
i
中共有n个元素,采集频率相同,周边每个人物所对应的集合e中均有n个元素,第一个元素为s
i1
,第二个元素为s
i2
,
…
,第k个元素为s
ik
,
…
,第n个元素为s
in
,设s
ik
中人物所在位置的x轴坐标为x
ik
,y轴坐标为y
ik
,人物身高为height
ik
,脸部朝向向量为则说话人物脸部朝向向量为
[0034]
步骤3.2,设以集合e
i
所对应人物所在位置为起点,以集合e
j
所对应周边人物所在位置为终点的向量为则以说话人物所在位置为起点,以集合e
j
所对应周边人物所在位置为终点的向量为
[0035]
步骤3.3,设以集合e
i
所对应人物所在位置为起点,以机器人所在位置为终点的向量为则以说话人物所在位置为起点,以机器人所在位置为终点的向量为
[0036]
步骤3.4,计算第k个时刻向量与向量之间的夹角a
jk
以及向量与向量之间的夹角b
k
,k=1,2,
…
,n,表达式为:
[0037][0038][0039][0040][0041]
得到第k个时刻a
jk
的最小值,j=2,3,
…
,p,并将a
jk
的最小值与b
k
比较大小,即min(b
k
,min(a
jk
));再构建集合r,集合r中共有n个元素,第一个元素为r1,第二个元素为r2,
…
,第k个元素为r
k
,
…
,第n个元素为r
n
,若min(b
k
,min(a
jk
))=min(a
jk
),则根据映射表q,r
k
为min(a
jk
)中相对应j所对应人物id;若min(b
k
,min(a
jk
))=b
k
,则r
k
=0,id为正数,因此设0为机器人所对应的id;
[0042]
步骤3.5,计算集合r中相同元素出现的次数,若0出现的次数最多,则判断为开口说话的人物脸部朝向机器人,否则判断为开口说话的人物脸部不朝向机器人。
[0043]
进一步的,所述步骤4,具体包括:
[0044]
输入语音中的动作执行人明确为机器人名称,则判断动作执行人为机器人;
[0045]
输入语音中的动作执行人明确为非机器人名称,则判断动作执行人不是机器人;
[0046]
输入语音中的动作执行人明确为第一人称代词,则判断动作执行人不是机器人;
[0047]
输入语音中的动作执行人明确为第二人称代词,则根据开口说话人物脸部是否朝向机器人判断动作执行人是否为机器人,若开口说话人物脸部朝向机器人,则判断动作执行人为机器人,否则判断动作执行人不是机器人;
[0048]
输入语音中的动作执行人明确为第三人称代词,则判断动作执行人不是机器人;
[0049]
输入语音中的动作执行人缺失,则根据开口说话人物脸部是否朝向机器人判断动作执行人是否为机器人,若开口说话人物脸部朝向机器人,则判断动作执行人为机器人,否则判断动作执行人不是机器人;
[0050]
输入语音中的动作执行人缺失或为第二人称代词,但视觉模块检测到说话人做出提示对方要与其对话的微动作集合中的至少一种微动作,则根据集合微动作被执行人判断是否与机器人对话,若微动作被执行人是机器人,则判断为与机器人对话;微动作被执行人并非为机器人,则判断为并非与机器人对话;此时无论开口说话的人物脸部是否朝向机器人,同时语音输入过程中对机器人执行微动作,此时即使开口说话的人物脸部并不朝向机器人,也判断动作执行人为机器人;
[0051]
输入语音的意图为机器人专属意图集合中的一个元素,且输入语音中的动作执行人缺失或为第二人称代词,则可判断为与机器人对话,此时即使开口说话的人物脸部并不朝向机器人,也判断动作执行人为机器人;
[0052]
其余情况均判断为动作执行人并非机器人。
[0053]
本发明基于视觉、声源定位角度和语义理解信息,可有效判断动作执行人是否为机器人,从而进行响应回复。
附图说明
[0054]
图1是本发明实施例的应用场景结构示意图;
[0055]
图2是本发明的方法流程示意图;
[0056]
图3是本发明的构建的坐标系示意图;
[0057]
图4是本发明的机器人逆时针水平旋转θ角度时的单位向量坐标系示意图;
[0058]
图5是本发明的机器人所在位置与周边人物所在位置的角度坐标系示意图;
[0059]
图6是本发明的判断动作执行人的脸部朝向流程示意图。
具体实施方式
[0060]
为了使本发明的目的、技术方案和技术效果更加清楚明白,以下结合说明书附图,对本发明作进一步详细说明。
[0061]
如图1所示,本发明的一种无唤醒机器人判断动作执行人是否为机器人的方法,所述无唤醒机器人结合视觉、声源角度等信息进行识别,判断用户语音输入对话后,动作执行人是否为机器人,具体的,包括如下步骤:
[0062]
步骤1,如图2所示,无唤醒机器人通过视觉模块和语音模块采集图像识别人物信息和用户语音输入信息,即视觉信息和语音声源信息,视觉信息包括人物信息和微动作信息,语音声源信息包括声源定位信息和语义理解信息,具体的包括以下子步骤:
[0063]
步骤1.1,如图3所示,构建坐标系:机器人身高heightr,以机器人所在位置的地面为原点,机器人水平方向分别有x轴和y轴,机器人右向为x轴正方向,机器人正前方为y轴正方向,机器人垂直方向为z轴,上方为z轴正方向。
[0064]
步骤1.2,获取人物水平位置状态信息和身高,构建表示人物信息的集合:机器人通过其视觉模块采集周边人物身高height,水平位置状态信息x,y,分别表示人物的水平位置坐标,脸部朝向向量(facex,facey,facez),以及信息id,id是周边人物的唯一标志,对于同一人物,id是不变的,为方便运用,本发明实施例的id设为正数;则人物信息集合s={id,x,y,height,facex,facey,facez};机器人采集视觉信息的时间频率为f,即一秒时间内生成的信息数量,语音输入开始至语音输入结束持续时间为t秒,在该t秒内生成的信息总量为集合e={s1,s2,s3,
…
,s
tf
},在集合e中共有tf个集合s。
[0065]
步骤1.3,构建机器人专属意图集合y={专属意图1,专属意图2,专属意图3,
…
,专属意图n},如餐厅服务机器人专属意图y={盛饭,拿筷子,倒水}。
[0066]
步骤1.4,构建提示对方要与其对话的微动作集合x={微动作1,微动作2,微动作3,
…
,微动作m},如x={拍肩,抬肘轻击},且视觉模块能在用户语音输入过程中可识别微动作,并且能明确该微动作的被执行人。
[0067]
步骤1.5,通过机器人语音模块进行声源定位和语音语义理解并获取对应信息,所述声源定位即获取开始说话时声源输入水平角度θ,0<=θ<2π,如人物在机器人正右方,θ=0;如人物在机器人右前方,如人物在机器人正前方,如人物在机器人左前方,如人物在机器人正左方,θ=π;如人物在机器人左后方,如人物在机器人正后方,如人物在机器人右后方,以计算周边哪个用户在语音输入。
[0068]
所述语音语义理解即提取出相关动作执行人及其意图,如小明去倒水,动作执行人为小明,意图为倒水。
[0069]
步骤2,根据声源定位信息,判断出语音说话人,具体包括以下子步骤:
[0070]
步骤2.1,当语音模块检测到有人开始说话,语音模块下发开始说话时声源输入水平角度θ。
[0071]
步骤2.2,如图4所示,构建初始以原点为起点,指向x轴正方向,再逆时针水平旋转θ角度的单位向量具体为:
[0072]
当θ=0时,
[0073]
当时,
[0074]
当时,
[0075]
当时,
[0076]
当θ=π时,
[0077]
当时,
[0078]
当时,
[0079]
当时,
[0080]
步骤2.3,如图5所示,提取开始说话时周边每个人物的信息集合s={id,x,y,height,facex,facey,facez},构建起点为原点,即机器人所在位置为原点,周边人物所在位置为终点的向量计算周边每个人物所对应的与之间的夹角:
[0081][0082]
计算周边每个人物所对应的夹角α,并选取α的最小值,即min(α)所对应的人物id为开口说话的人物id,同时记录该id。
[0083]
步骤3,如图6所示,在确定语音说话人后,判断语音说话人的脸部朝向,具体包括以下子步骤:
[0084]
步骤3.1,提取从开始说话至说话结束时间段内,机器人周边每个人物的集合e,设机器人周边拥有p个人。为方便计算,设说话的人物所对应的集合为e1,其余人所对应的集合分别为e2,e3,
…
,e
p
,同时建立集合e的下标与所对应人物的id一对一映射表q,即不同集合e的下标对应不同id,不同id对应不同集合e的下标;设集合e
i
中共有n个元素,因采集频率相同,周边每个人物所对应的集合e中均有n个元素,第一个元素为s
i1
,第二个元素为s
i2
,
…
,第k个元素为s
ik
,
…
,第n个元素为s
in
,设s
ik
中人物所在位置的x轴坐标为x
ik
,y轴坐标为y
ik
,人物身高为height
ik
,脸部朝向向量为则说话人物脸部朝向向量为
[0085]
步骤3.2,设以集合e
i
所对应人物所在位置为起点,以集合e
j
所对应周边人物所在位置为终点的向量为则以说话人物所在位置为起点,以集合e
j
所对应周边人物所在位置为终点的向量为
[0086]
步骤3.3,设以集合e
i
所对应人物所在位置为起点,以机器人所在位置为终点的向量为则以说话人物所在位置为起点,以机器人所在位置为终点的向量为
[0087]
步骤3.4,计算第k个时刻向量与向量之间的夹角a
jk
以及向量与向量之间的夹角b
k
,k=1,2,
…
,n,表达式为:
[0088][0089][0090]
[0091][0092]
得到第k个时刻a
jk
(j=2,3,
…
,p)的最小值,并将a
jk
的最小值与b
k
比较大小,即min(b
k
,min(a
jk
));再构建集合r,集合r中共有n个元素,第一个元素为r1,第二个元素为r2,
…
,第k个元素为r
k
,
…
,第n个元素为r
n
,如min(b
k
,min(a
jk
))=min(a
jk
),那么根据映射表q,r
k
为min(a
jk
)中相对应j所对应人物id;如min(b
k
,min(a
jk
))=b
k
,那么r
k
=0,因约定周边人物的id为正数,因此假设0为机器人所对应的id。
[0093]
步骤3.5,计算集合r中相同元素出现的次数,若0出现的次数最多,则判断为开口说话的人物脸部朝向机器人,否则判断为开口说话的人物脸部不朝向机器人。
[0094]
步骤4,根据语义理解源信息,提取动作执行人及意图,同时结合说话人的脸部朝向,识别微动作信息,判断说话人语音中的动作执行人是否为机器人,具体包括:
[0095]
输入语音中的动作执行人明确为机器人名称,则判断动作执行人为机器人,如机器人名称为小之,语音输入“小之去倒杯水”。
[0096]
输入语音中的动作执行人明确为非机器人名称,则判断动作执行人不是机器人,如机器人名称为小之,语音输入“小明去倒杯水”。
[0097]
输入语音中的动作执行人明确为第一人称代词,如“我”,则判断动作执行人不是机器人,如语音输入“我去倒杯水”。
[0098]
输入语音中的动作执行人明确为第二人称代词,如“你”,则根据开口说话人物脸部是否朝向机器人判断动作执行人是否为机器人,若开口说话人物脸部朝向机器人,则判断动作执行人为机器人,否则判断动作执行人不是机器人,如语音输入“你去倒杯水”。
[0099]
输入语音中的动作执行人明确为第三人称代词,如“他”,则判断动作执行人不是机器人,如语音输入“他去倒杯水”。
[0100]
输入语音中的动作执行人缺失,则根据开口说话人物脸部是否朝向机器人判断动作执行人是否为机器人,若开口说话人物脸部朝向机器人,则判断动作执行人为机器人,否则判断动作执行人不是机器人,如语音输入“去倒杯水”。
[0101]
输入语音中的动作执行人缺失或为第二人称代词,但视觉模块检测到说话人做出提示对方要与其对话的微动作集合x中的至少一种微动作,则根据集合x微动作被执行人判断是否与机器人对话,若微动作被执行人是机器人,则判断为与机器人对话;微动作被执行人并非为机器人,则判断为并非与机器人对话。此时无论开口说话的人物脸部是否朝向机器人,如语音输入“去倒杯水”,同时语音输入过程中拍机器人肩,此时即使开口说话的人物脸部并不朝向机器人,也判断动作执行人为机器人。
[0102]
输入语音的意图为机器人专属意图集合y中的一个元素,且输入语音中的动作执行人缺失或为第二人称代词,则可判断为与机器人对话,如餐厅服务机器人专属意图y={盛饭,拿筷子,倒水},语音输入“去倒杯水”,此时即使开口说话的人物脸部并不朝向机器人,也判断动作执行人为机器人。
[0103]
其余情况均判断为动作执行人并非机器人。
[0104]
以上所述,仅为本发明的优选实施案例,并非对本发明做任何形式上的限制。虽然前文对本发明的实施过程进行了详细说明,对于熟悉本领域的人员来说,其依然可以对前述各实例记载的技术方案进行修改,或者对其中部分技术特征进行同等替换。凡在本发明
精神和原则之内所做修改、同等替换等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。