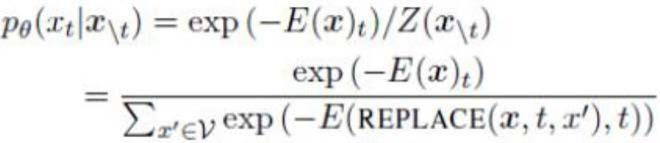基于能量的语言模型
1.相关申请
2.本技术要求美国临时专利申请no.63/070,933的优先权和权益。美国临时专利申请no.63/070,933通过引用整体并入本文。
技术领域
3.本公开一般涉及自然语言处理(nlp)。更具体地,本公开涉及用于训练和使用诸如完形填空(cloze)语言模型的基于能量的语言模型的系统和方法。
背景技术:
4.对预训练文本编码器的早期工作使用语言建模目标。这些方法的缺点是生成的模型是单向的
‑
该模型在产生当前符号(token)的表示时看不到未来符号。因此,当前现有技术预训练方法主要依赖于掩蔽语言建模(mlm)。这些方法选择输入的小子集(通常大约15%),将符号身份或注意力掩蔽为那些符号,然后训练模型以恢复原始输入。虽然生成双向模型,但是这些目标招致大量计算成本。作为一个示例,显著的计算成本能够被部分归因于模型仅从每个示例的15%的符号学习的事实。此外,这些现有方法迄今为止遵循了利用输出柔性最大传递函数(softmax)来估计符号概率并且使用最大似然训练的标准方法,而其他种类的生成模型仍未被探索。
技术实现要素:
5.本公开的实施例的方面和优点将在以下描述中被部分地阐述,或者能够从描述中学习,或者能够通过实施例的实践来学习。
6.本公开的一个示例方面涉及一种用于训练机器学习语言模型的计算机实现的方法。该方法由包括一个或多个计算设备的计算系统获得包括多个正符号的原始语言输入。该方法包括由计算系统生成一个或多个噪声符号。该方法包括由计算系统分别将原始语言输入中的所述多个正符号中的一个或多个替换为一个或多个噪声符号,以形成包括多个更新的输入符号的含噪声的语言输入。该方法包括由所述计算系统利用机器学习语言模型处理含噪声的语言输入以分别为多个更新的输入符号产生多个分值,其中,用于每个更新的输入符号的所述分值指示该更新的输入符号在所述含噪声的语言输入中给定其他更新的输入符号时的似然性。该方法包括由计算系统至少部分地基于所述个分值分别为多个更新的输入符号生成多个预测,其中,由所述机器学习语言模型为每个更新的输入符号产生的所述预测预测这种更新的输入符号是正符号还是噪声符号。该方法包括由计算系统至少部分地基于评估多个预测的损失函数来训练机器学习语言模型。
7.本公开的其他方面涉及各种系统、装置、非暂时性计算机可读介质、用户界面和电子设备。
8.参考以下描述和所附权利要求,本公开的各种实施例的这些和其他特征、方面和优点将变得更好理解。并入本说明书中并构成本说明书的一部分的附图图示了本公开的示
例实施例,并且与描述一起用于解释相关原理。
附图说明
9.在参考附图的说明书中阐述了针对本领域普通技术人员的实施例的详细讨论,其中:
10.图1a描绘根据本公开的示例实施例的采用机器学习语言模型的示例处理中的数据流。
11.图1b描绘根据本公开的示例实施例的用于训练机器学习语言模型的示例处理中的数据流。
12.图2a描绘根据本公开的示例实施例的示例计算系统的框图。
13.图2b描绘根据本公开的示例实施例的示例计算设备的框图。
14.图2c描绘根据本公开的示例实施例的示例计算设备的框图。
15.图3a和图3b示出根据本公开的示例实施例的示例训练算法。
16.在多个图重复的附图标记旨在标识各个实施方式中的相同特征。
具体实施方式
17.概述
18.总体上,本公开涉及用于训练和使用诸如完形填空(cloze)语言模型的基于能量的语言模型的系统和方法。特别地,本公开的一个方面涉及用于在文本上进行表示学习的基于能量的完形填空语言模型。在一些情况下,本文中提供的模型可以被称为“electric(电)”模型。类似于bert模型,本文中提出的示例模型能够是给定其上下文(context)的符号的条件生成模型。然而,本文中提出的示例模型不掩蔽文本或输出在可能在上下文中出现的符号上的完整分布。相反,示例提出的模型将标量能量分值分配到每个输入符号。标量能量分值能够指示符号被赋予上下文的可能性。本公开的另一方面提供用于训练提出的模型以使用基于噪声对比度估计的算法来将低能量分别到一些数据符号并且将高能量分配到其他数据符号的技术。所提出的系统和方法解决bert中的mask符号的预训练/微调差异,并且允许候选符号和上下文在变换器层中而不是仅在输出柔性最大传递函数(softmax)中交互。所提出的模型在被转移到下游任务时表现良好,并且在产生文本的似然性分值方面特别有效:所提出的模型的示例实施方式对比语言模型更好的语音识别n个最好的列表进行重新排名并且比掩蔽语言模型快得多。
19.更特别地,许多最近的语言表示学习方法训练大型神经网络以预测以其左边(“左”语言模型)或两边(“完形填空”语言模型)的上下文为条件的符号的身份。除非明确地另外指示,否则本文中术语“语言模型”的使用旨在包括左语言模型和完形填空语言模型两者。这些现有方法迄今为止遵循了利用输出柔性最大传递函数来估计符号概率并且使用最大似然训练的标准方法,而其他种类的生成模型仍未被探索。
20.相反,本公开提出训练基于能量的模型(ebm),其在一些示例实施方式中可以被称为“electric”,以执行完形填空语言建模。ebm学习能量函数,该能量函数将低能量值分配到数据分布中的输入并且将高能量值分配到其他输入。它们是灵活的,因为它们不必计算归一化概率。例如,electric不使用掩蔽或输出柔性最大传递函数,而是在低能量指示符号
是可能的情况下为每个输入符号产生能量分值。本公开还提供基于噪声对比度估计来有效地近似损失的训练算法(参见gutmann和hyvarinen,噪声对比度估计:用于非归一化统计模型的新估计原理,aistats 2010)。
21.在美国临时专利申请no.63/070,933中,描述示例实验,其评估关于包括glue和squad数据集的示例数据集的electric。在示例实验中,electric大体上优于bert(devlin等,bert:为语言理解而对深度双向变换器进行的预训练,naacl
‑
hlt 2019)。electric的一个关键优点是它能够有效地产生文本的do
‑
log
‑
似然性分值(salazar等,掩蔽语言模型分值,acl 2020年):electric在对语音识别系统的输出重新排序上比gpt
‑
2更好(radford等,语言模型是无监督的多任务学习者,2019),并且在重新排序上相比bert快许多倍。在美国临时专利申请no.63/070,933中提供的结果表明,基于能量的模型是当前用于语言表示学习的标准生成模型的有前途的替代。
22.本公开的系统和方法提供许多技术效果和益处。作为一个示例技术效果和益处,本公开的系统和方法能够更有效地训练语言模型。特别地,(条件)噪声对比度估计损失的使用提供一种有效地训练非归一化模型的方式,并且避免计算完整分布或分区函数的需要,这种计算完整分布或分区函数在计算上可能成本过高。此外,提供示例训练算法,其利用负噪声样本替换多个正输入符号,能够在多个样本上同时学习。这使模型能够更快地并且在更少的训练迭代上学习(例如,收敛)。使用较少的训练迭代来训练模型节省了计算资源,诸如处理器使用、存储器使用、网络带宽等。
23.作为另一示例技术效果和益处,所提出的技术导致改进的模型性能。例如,所提出的模型的一个优点是它们高效地产生do
‑
log
‑
似然性分值的能力,从而导致改进的模型性能(例如,在重新排序任务方面)。这能够对应于改进的自然语言处理性能(例如,改进的语音识别、查询建议等)。
24.现在参考附图,将更详细地讨论本公开的示例实施例。
25.示例模型
26.图1a描绘根据本公开的示例实施例的采用示例机器学习语言模型52的示例过程中的数据流。模型52被提供作为一个示例。模型52能够对给定上下文的符号的概率进行建模。具体地,在一些实施方式中,模型52能够为所有输入符号产生未归一化概率(但没有完整分布)。
27.特别地,模型52可以对在周围上下文x
\t
=[x1,...,x
t
‑1,x
t 1
,...,x
n
]中出现的符号x
t
进行建模p(x
t
|x
\t
)。然而,与bert和许多随后的预训练方法不同,示例模型52不使用掩蔽或柔性最大传递函数层。模型52能够首先使用例如变换器网络将未掩蔽输入x=[x1,...,x
n
]
·
映射成上下文化的向量表示h(x)=[h1,...,h
n
]。该模型能够使用学习权重向量w向给定位置t分配能量e(x)
t
=w
t
h(x)
t
分值。能量函数能够将义在位置t处的可能符号上的分布定义为
[0028][0029]
其中,replace(x,t,x)表示用x替换位置t处的符号,并且v是词汇,例如,通常是词
片段。
[0030]
与使用柔性最大传递函数层产生所有可能符号x
′
的概率的bert不同,候选x作为对变换器的输入而被传递。结果,计算p
θ
成本过高,因为分区函数z
θ
(x
\t
)需要运行变换器|v|次。
[0031]
由于计算精确似然性通常是难以处理的,因此通常不可能利用标准最大似然估计来训练诸如electric的基于能量的模型。相反,本公开的示例实施方式使用(条件)噪声对比度估计(nce)(gutmann和hyvarinen,2010;ma和collins,2018),其提供了一种有效地训练不计算z
θ
(x
\t
)的未归一化模型的方式。
[0032]
nce通过定义二元分类任务来学习模型的参数,其中来自数据分布的样本必须与由噪声分布q(x
t
|x
\t
)生成的样本区分开。首先,未归一化输出能够被定义为
[0033][0034]
在操作上,nce能够被视为如下:
[0035]
正数据点能够是来自数据的文本序列x以及序列中的位置t。
[0036]
除了x
t
之外,负数据点能够是相同的,位置t的符号被替换为从噪声分布q采样的噪声符号
[0037]
能够定义二元分类器,其将数据点为正的概率估计为:
[0038][0039]
二元分类器能够被训练以区分正数据点与负数据点,其中为每n个正数据点采样k个负数据点。
[0040]
正式地,一个示例nce损失是
[0041][0042]
该损失当时被最小化。该特性的结果是模型被训练为自归一化的,使得z
θ
(x
\t
)=1。
[0043]
为了使损失最小化,可以通过如算法1中所示进行采样来近似期望值,如图3a中所示并且也在下面再现。采用该估计损耗的梯度产生无偏估计
[0044][0045]
算法1朴素nce损失估计
[0046]
给定:输入序列x,负样本的数量k,噪声分布q,模型
[0047]
将损失初始化为
[0048]
根据t~unif{1,n},来采样k个负样本。
[0049]
为每个负样本,添加到损失
[0050]
然而,实际上,该算法在计算上成本非常高,由于它需要k 1次正向通过变换器以计算(对正样本一次,对每个负样本一次)。
[0051]
因此,本公开的另一方面提出一种同时将k个输入符号替换为噪声样本的更有效的方法。该方法的一个示例实施方式在算法2中被示出,其在图3b中示出并且也在下面再现。
[0052][0053]
算法2有效nce损失估计
[0054]
给定:输入序列x,负样本的数量k,噪声分布q,模型
[0055]
选择k个唯一随机位置r={r1,
…
,r
k
},其中,每个r
i
是1≤r
i
≤n。
[0056]
将k个随机位置替换为负样本:对于i∈r,
[0057]
对于每个位置t=1到n,如果t∈r,则添加到损失否则
[0058]
该方法对于k个噪声采样和n
‑
k个数据采样仅需要通过变换器一次。然而,注意,该过程仅在以下时下才将真正地最小化
[0059][0060]
为了应用这种效率技巧,能够假设它们近似相等,这是合理的,因为(1)能够选择小k(例如,0.15n)并且(2)q能够被训练成接近数据分布(参见下文)。
[0061]
一些示例噪声分布q能够来自被训练为匹配p
data
的神经网络。特别地,一个示例方法是使用如baevski等.自我注意网络的cloze驱动的预训练,arxiv preprint arxiv:1903.07785(2019)提出的双塔完形填空语言模型,其比左语言模型更准确,因为它对每个符号的两侧都使用上下文。该模型能够在输入序列上运行两个变换器t
ltr
和t
rtl
,一个具有注意掩蔽,因此它从左到右处理序列,而另一个从右到左操作。模型的预测能够来自应用于两个变换器的级联状态的柔性最大传递函数层:
[0062][0063][0064]
在一些实施方式中,能够使用例如对数据的标准最大似然估计来与语言模型同时训练噪声分布。
[0065]
electric的一个示例实现方式的示例概述是:
[0066][0067]
model模型
[0068]
noise dist.噪声分布
[0069]
two
‑
tower cloze lm双塔完形填空lm
[0070]
binary classifier二元分类器
[0071]
其中s=w
t
h(x)
t
是由变换器产生的分值。
[0072]
作为一个示例训练过程,图1b描绘根据本公开的示例实施例的用于训练机器学习语言模型52的示例过程中的数据流。
[0073]
该处理能够包括获得包括多个正符号(例如[the,artist,sold,the,painting])的原始语言输入58。正符号能够以预定序列被排列。例如,原始语言输入58能够从正分布56获得。
[0074]
训练处理能够包括选择多个正符号中的一个或多个以用作一个或多个替换符号。训练处理能够包括生成一个或多个噪声符号。例如,噪声符号能够从噪声分布60中采样或基于其生成,例如,噪声分布60能够在给定来自原始语言输入58的上下文的情况下生成提出的替换符号61。在一个示例中,噪声分布60能够是学习的模型,诸如,例如,双塔完形填空模型。在一个示例中,所提出的替换符号61能够是噪声词汇表中的在给定周围的上下文符号的情况下从噪声分布60接收最大分值q(x
t
|x
\t
)的候选符号。
[0075]
如在54处所示,该处理能够包括分别将原始语言输入58中的一个或多个被替换的符号替换为一个或多个替换噪声符号61以形成包括多个更新的输入符号的噪声语言输入62,该多个更新的输入符号是替换噪声符号61与一些原始语言输入58的正符号的混合。具体地,多个更新的输入符号能够包括一个或多个插入的替换噪声符号和未被选择用作替换符号的多个正符号。例如,含噪声的语言输入包括[shaky,artist,sold,the,farm],其中插入从噪声分布60生成的替换噪声符号“shaky”和“farm”,并且“artist”、“sold”和“the”是原始输入58中剩余的正符号。
[0076]
训练处理能够包括利用机器学习语言模型52处理含噪声的语言输入62,以分别为含噪声的输入62中的多个更新的输入符号产生多个能量分值63。例如,含噪声的语言输入62中的每个符号的能量分值63能够指示给定的周围上下文符号和正分布56的情况下该符号的似然性。
[0077]
二元分类器65能够接收来自噪声分布的分值61和来自机器学习语言模型52的分值63,并且能够生成为更新的输入符号62的多个预测64,例如,由二元分类器65为每个更新的输入符号62产生的预测64能够预测这种更新的输入符号是正符号还是噪声符号。例如,对于符号“shaky”,分类器65已经正确预测这种符号是噪声。同样地,对于符号“artist”,分类器65已经正确预测这种符号是正的。然而,对于符号“farm”,分类器65错误地预测这种符号是正的,而实际上它是噪声。
[0078]
训练过程能够包括至少部分地基于评估由二元分类器65产生的多个预测64的损失函数66来训练机器学习语言模型52,例如,损失函数66能够被用于更新模型52的权重或其他参数的值(例如,使用基于梯度的优化技术)。在一些实施方式中,也能够基于损失函数来更新或训练噪声分布60和/或二元分类器65。例如,能够使用评估噪声分布内的噪声符号的存在的第二损失函数(例如,最大似然估计函数)来训练噪声分布60。图1b所示的处理能够被迭代地执行。
[0079]
在一些实施方式中,在图1b所图示的训练过程之后,机器学习语言模型52能够被微调以执行语言处理任务。作为示例,语言处理任务能够包括问题回答;下一单词或句子完成或预测;翻译;实体识别;语言分类;自然语言理解;输出重新排列;以及其他语言任务。
[0080]
所提出的模型相对于bert的一个示例优点在于,它可以高效地产生文本的伪对数似然(pll)分值。用于electric的示例pll是
[0081][0082]
并且能够被用于重新排列例如nmt或asr系统、查询建议系统、聊天机器人和/或其中所生成的语言输出看起来自然或模仿人类语言特征是有益的其他系统的输出。
[0083]
虽然历史上来自语言模型的对数似然性已经被用于这种重新排列,但是最近的工作已经证明来自掩蔽语言模型的pll执行得更好。然而,从掩蔽语言模型计算pll需要n次通过变换器:一次,每个单词都被掩蔽。salazar等(2020)建议将bert提炼成不使用掩蔽的模型以避免这种成本,但是这种模型在他们的实验中明显地不如常规语言模型。相反,示例提出的模型能够在单次通过中为所有输入符号产生估计概率。
[0084]
示例设备和系统
[0085]
图2a描绘根据本公开的示例实施例的示例计算系统100的框图。系统100包括通过网络180通信地耦合的用户计算设备102、服务器计算系统130以及训练计算系统150。
[0086]
用户计算设备102能够是任何类型的计算设备,诸如,例如,个人计算设备(例如,膝上型或台式计算机)、移动计算设备(例如,智能电话或平板电脑)、游戏控制台或控制器、可穿戴计算设备、嵌入式计算设备或任何其他类型的计算设备。
[0087]
用户计算设备102包括一个或多个处理器112和存储器114。一个或多个处理器112能够是任何合适的处理设备(例如,处理器核、微处理器、asic、fpga、控制器、微控制器等),并且能够是一个处理器或被可操作地连接的多个处理器。存储器114能够包括一个或多个非暂时性计算机可读存储介质,诸如ram、rom、eeprom、eprom、闪存设备、磁盘等及其组合。存储器114能够存储数据116和指令118,其由处理器112执行以使用户计算设备102执行操作。
[0088]
在一些实施方式中,用户计算设备102能够存储或包括一个或多个机器学习模型120。例如,机器学习模型120能够是或否则能够包括各种机器学习模型,诸如神经网络(例如,深度神经网络)或其他类型的机器学习模型,包括非线性模型和/或线性模型。神经网络能够包括前馈神经网络、循环神经网络(例如,长短期记忆循环神经网络)、卷积神经网络或其他形式的神经网络。参考图1讨论示例机器学习模型120。
[0089]
在一些实施方式中,一个或多个机器学习模型120能够通过网络180从服务器计算系统130被接收、被存储在用户计算设备存储器114中,并且然后由一个或多个处理器112使用或否则被实现。在一些实施方式中,用户计算设备102能够实现单个机器学习模型120的多个并行实例(例如,执行跨语言符号的多个实例的并行语言编码/处理)。
[0090]
另外或可替代地,一个或多个机器学习模型140能够被包括在根据客户端
‑
服务器关系与用户计算设备102通信的服务器计算系统130中或否则由其存储和实现。例如,机器学习模型140能够由服务器计算系统140实现为web服务(例如,语言处理服务服务)的一部分。因此,一个或多个模型120能够在用户计算设备102处被存储并且被实现,和/或一个或多个模型140能够在服务器计算系统130处被存储并被实现。
[0091]
用户计算设备102还能够包括接收用户输入的一个或多个用户输入组件122。例如,用户输入组件122能够是对用户输入对象(例如,手指或触控笔)的触摸敏感的触敏组件(例如,触敏显示屏或触摸板)。触敏组件能够用于实现虚拟键盘。其他示例用户输入组件包括麦克风、传统键盘或用户能够通过其提供用户输入的其他装置。
[0092]
服务器计算系统130包括一个或多个处理器132和存储器134。一个或多个处理器132能够是任何合适的处理设备(例如,处理器核、微处理器、asic、fpga、控制器、微控制器等),并且能够是一个处理器或可操作地连接的多个处理器。存储器134能够包括一个或多个非暂时性计算机可读存储介质,诸如ram、rom、eeprom、eprom、闪存设备、磁盘等及其组
合。存储器134能够存储数据136和指令138,其由处理器132执行以使服务器计算系统130执行操作。
[0093]
在一些实施方式中,服务器计算系统130包括一个或多个服务器计算设备或否则由一个或多个服务器计算设备实现。在服务器计算系统130包括多个服务器计算设备的情况下,这种服务器计算设备能够根据顺序计算架构、并行计算架构或其某种组合来操作。
[0094]
如上所述,服务器计算系统130能够存储或否则包括一个或多个机器学习模型140。例如,模型140能够是或否则包括各种机器学习模型。示例机器学习模型包括神经网络或其他多层非线性模型。示例神经网络包括前馈神经网络、深度神经网络、循环神经网络和卷积神经网络。参考图1讨论示例模型140。
[0095]
用户计算设备102和/或服务器计算系统130能够经由与通过网络180通信地耦合的训练计算系统150的交互来训练模型120和/或140。训练计算系统150能够与服务器计算系统130分离,或者能够是服务器计算系统130的一部分。
[0096]
训练计算系统150包括一个或多个处理器152和存储器154。一个或多个处理器152能够是任何合适的处理设备(例如,处理器核、微处理器、asic、fpga、控制器、微控制器等),并且能够是一个处理器或可操作地连接的多个处理器。存储器154能够包括一个或多个非暂时性计算机可读存储介质,诸如ram、rom、eeprom、eprom、闪存设备、磁盘等及其组合。存储器154能够存储数据156和指令158,其由处理器152执行以使训练计算系统150执行操作。在一些实施方式中,训练计算系统150包括一个或多个服务器计算设备或否则由一个或多个服务器计算设备实现。
[0097]
训练计算系统150能够包括模型训练器160,其使用诸如例如误差的向后传播的各种训练或学习技术来训练存储在用户计算设备102和/或服务器计算系统130处的机器学习模型120和/或140。例如,损失函数能够通过模型被反向传播以(例如,基于损失函数的梯度)更新模型的一个或多个参数。能够使用各种损失函数,诸如均方误差、似然损失、交叉熵损失、铰链损失和/或各种其他损失函数。梯度下降技术能够被用于在多次训练迭代中迭代地更新参数。
[0098]
在一些实施方式中,执行误差的向后传播能够包括执行通过时间截断的向后传播。模型训练器160能够执行多种泛化技术(例如,权重衰减、掉队等)以提高被训练的模型的泛化能力。
[0099]
具体地,模型训练器160能够基于训练数据162的集合来训练机器学习模型120和/或140。训练数据162能够包括例如示例输入符号组。
[0100]
在一些实施方式中,如果用户已经提供同意,则训练示例能够由用户计算设备102提供。因此,在这种实施方式中,提供给用户计算设备102的模型120能够由训练计算系统150对从用户计算设备102接收到的用户特定数据进行训练。在一些情况下,该处理能够被称为对模型个性化。
[0101]
模型训练器160包括用于提供所期望的功能性的计算机逻辑。模型训练器160能够以控制通用处理器的硬件、固件和/或软件来实现。例如,在一些实现方式中,模型训练器160包括存储在存储设备上、加载到存储器中并且由一个或多个处理器执行的程序文件。在其他实施方式中,模型训练器160包括存储在诸如ram硬盘或光介质或磁介质的有形计算机可读存储介质中的一个或多个计算机可执行指令组。
[0102]
网络180能够是任何类型的通信网络,诸如局域网(例如,内联网)、广域网(例如,互联网)、或其某种组合,并且能够包括任何数量的有线或无线链路。通常,网络180上的通信能够经由任何类型的有线和/或无线连接、使用各种通信协议(例如,tcp/ip、http、smtp、ftp)、编码或格式(例如,html、xml)和/或保护方案(例如,vpn、安全http、ssl)来承载。
[0103]
图2a图示能够被用于实现本公开的一个示例计算系统。也能够使用其它计算系统。例如,在一些实施方式中,用户计算设备102能够包括模型训练器160和训练数据集162。在这种实施方式中,模型120能够在用户计算设备102处被本地训练并且使用。在一些这种实现方式中,用户计算设备102能够现模型训练器160以基于用户特定数据来使模型120个性化。
[0104]
图2b描绘根据本公开的示例实施例执行的示例计算设备10的框图。计算设备10能够是用户计算设备或服务器计算设备。
[0105]
计算设备10包括多个应用(例如,应用1至n)。每个应用包含其自己的机器学习库和机器学习模型。例如,每个应用能够包括机器学习模型。示例应用包括文本消息应用、电子邮件应用、听写应用、虚拟键盘应用、浏览器应用等。
[0106]
如图2b所图示,每个应用能够与计算设备的多个其它组件通信,诸如,例如,一个或多个传感器、上下文管理器、设备状态组件、和/或另外的组件。在一些实施方式中,每个应用能够使用api(例如,公共api)与每个设备组件通信。在一些实施方式中,每个应用所使用的api专用于该应用。
[0107]
图2c描绘根据本公开的示例实施例执行的示例计算设备50的框图。计算设备50能够是用户计算设备或服务器计算设备。
[0108]
计算设备50包括多个应用(例如,应用1至n)。每个应用与中央智能层通信。示例应用包括文本消息应用、电子邮件应用、听写应用、虚拟键盘应用、浏览器应用等。在一些实施方式中,每个应用能够使用api(例如,跨所有应用的公共api)与中央智能层(以及存储在其中的模型)通信。
[0109]
中央智能层包括多个机器学习模型。例如,如图2c所图示,能够为各个应用提供相应的机器学习模型(例如,模型),并且由中央智能层管理。在其他实现方式中,两个或更多个应用能够共享单个机器学习模型。例如,在一些实施方式中,中央智能层能够为所有应用提供单个模型(例如,单个模型)。在一些实施方式中,中央智能层被包括在计算设备50的操作系统内或否则由计算设备50的操作系统实现。
[0110]
中央智能层能够与中央设备数据层通信。中央设备数据层可以是计算设备50的数据的集中式存储库。如图2c所图示,中央设备数据层能够与计算设备的多个其他组件通信,诸如,例如,一个或多个传感器、上下文管理器、设备状态组件、和/或另外的组件。在一些实施方式中,中央设备数据层能够使用api(例如,私有api)与每个设备组件通信。
[0111]
另外的公开
[0112]
本文中讨论的技术参考服务器、数据库、软件应用和其它基于计算机的系统,以及所采取的动作和发送到这些系统以及来自这些系统的信息。基于计算机的系统的固有灵活性允许组件之间的任务和功能的各种各样的可能配置、组合和划分。例如,本文中讨论的处理能够使用单个设备或组件或者组合工作的多个设备或组件来实现。数据库和应用能够在单个系统上实现或分布在多个系统上。分布组件能够顺序地操作或并行地操作。
[0113]
一个或多个计算机的系统能够被配置为通过将软件、固件、硬件或它们的组合安装在系统上来执行特定操作或动作,该软件、固件、硬件或它们的组合在操作中使或促使系统执行动作。一个或多个计算机程序能够被配置为通过包括指令来执行特定操作或动作,该指令在由数据处理装置执行时使装置执行动作。所描述的技术的实施方式可以包括硬件、方法或处理、或计算机可访问介质上的计算机软件。
[0114]
虽然已相对于本发明标的物的各个特定实例实施例详细描述了本发明主题,但每个示例以解释而非限制本发明的方式被提供。本领域技术人员在理解了上述内容时,能够容易地产生对这些实施例的改变、变化和等效替换。因此,本主题公开不排除包括对本领域普通技术人员显而易见的对本主题的这种修改、变化和/或添加。例如,作为一个实施例的一部分图示或描述的特征能够与另一实施例一起使用,以产出又一实施例。因此,本公开旨在覆盖这样的改变、变化和等效替换。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。