1.本发明涉及数据服务管理技术领域,特别是一种面向数据中台的服务感知与资源调度系统及方法。
背景技术:
2.随着电力企业信息化程度的提高和业务量的爆炸增长,相关电力系统的数据数量以及种类相比以往增加许多,于是这些海量数据需要进行统一、高效的管理管控。目前来看,现有的数据服务管理技术与机制还存在许多问题与缺陷,比如一体化平台的建设需要数据管理技术作为支撑,现有管理体系的服务水平已达瓶颈,急需新的管理机制来突破现存障碍、数据溯源问题困难等问题需要重点解决。
3.为了提高前台数据分析的效率和应用的广泛性,阿里巴巴提出了数据中台的概念。数据中台是一个十分智能的数据处理平台。此平台功能包括技术的承接、规范定义的构建与完善、引领业务发展方向等。数据中台服务是基于全业务统一数据中心的全业务、全类型数据的业务服务化能力框架,主要包括多维度模型数据和统一服务,并配套技术组件、数据管理和数据在线开发工具的支撑,为全业务统一数据中心分析域和处理域的各类应用提供一系列数据服务。基于企业多维融合模型数据,借助企业统一分析服务和统一数据访问组件,构建企业统一数据服务能力
123]
。操作人员可以根据使用需要来提炼数据,从而达到良好的效果。而在数据生产提炼加工的过程中会伴生一种数据——元数据,元数据又被称作数据中的数据,这种数据在实际生产环境中非常重要。如果对元数据的控制和管理十分熟悉,就可以使系统中的数据的源头更加明确,并且系统运行的也会十分稳定。如果要对元数据进行有效的管理就一定要记录数据产生的过程中所涉及的每个因素,其中就包括数据服务的生命周期等信息。目前来说数据中台的业务统一和数据共享等技术可以为之后绝大部分大型企业的数据管理模式提供参考价值。当前数据中台的技术已经非常先进和成熟,值得在许多大型企业推广相关业务。另一方面,作为许多大型企业的技术支持,数据中台与许多因素有着不可分割的关系,数据中台与这些因素协同发展尤为重要。
4.数据中台的提出解决了传统数据中心易产生数据孤岛、数据统一性低、模型重复建设和数据治理水平低下等难题。以数据中台作为载体和平台,其中的数据服务管理显得尤为重要。数据服务管理机制中需要提供对数据服务的全生命周期监控和管理功能,如此以来相关工作人员可以使用web管理系统,在管理员权限下,对数据服务进行相关的操作。数据服务管理组件是所有数据服务运行的平台,是数据服务完成其生命周期的支撑。
5.传统的数据中台实现的数据服务管理技术中存在无法对服务进行监控分析、服务调度粒度粗、调度算法智能程度低等缺陷,使得数据管理服务处理效率低下,并且无法全动态地监控服务的全周期。
技术实现要素:
6.本发明的目的在于提供一种面向数据中台的服务感知与资源调度系统及方法,用
于对数据中台开放的服务进行监控、维护,对用户的任务请求进行管理、分析、编排等,提高数据中台上数据服务管理的质量和效率,提供友好、便捷的数据服务。
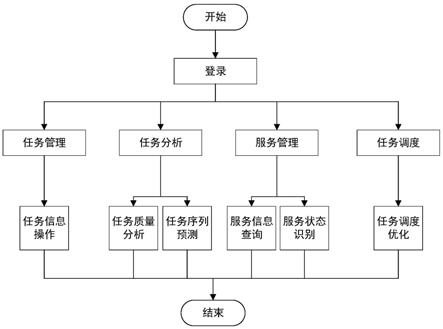
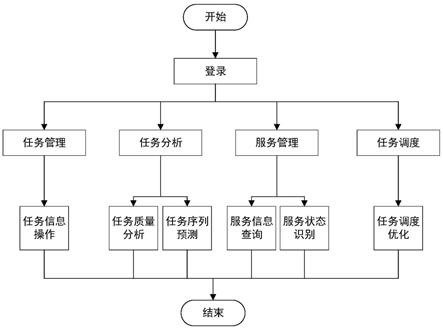
7.实现本发明目的的技术解决方案为:一种面向数据中台的服务感知与资源调度系统,包括任务管理模块、任务分析模块、服务管理模块和调度优化模块,其中:
8.服务管理模块,首先为数据中台开放的数据服务建立全生命周期模型,并且建立softmax多分类模型,对数据服务进行动态监控和维护;
9.任务管理模块,感知用户的任务请求相关信息,同时将任务请求阻断并将相关信息存储到数据库和zookeeper中;
10.任务分析模块,建立多元线性回归模型对任务进行质量分析,使用apriorall序列挖掘算法进行任务序列的预测;
11.调度优化模块,查看当前任务的调度序列,并根据用户偏好的调度策略来选择相应的调度算法,对当前任务调度序列进行优化,以达到资源利用的最大化。
12.一种面向数据中台的服务感知与资源调度方法,包括以下步骤:
13.步骤1、在服务管理模块中构建数据服务全生命周期模型;
14.步骤2、服务管理模块利用softmax多分类模型实时监控并维护数据服务的运行状态;
15.步骤3、任务管理模块动态感知用户的任务请求相关信息,同时将其阻断并存入数据库和zookeeper中;
16.步骤4、任务分析模块对感知到的用户任务请求进行质量分析和请求序列预测;
17.步骤5、调度优化模块按照用户偏好的调度策略选择相应调度算法,对感知到的任务请求进行序列优化并放行。
18.本发明与现有技术相比,其显著优点为:(1)对数据服务全生命周期建模,提出了基于机器学习方法的数据服务全生命周期管理及监控分析技术,实现服务的高可用和高效率;(2)提出了基于遗传算法和蚁群算法的结合算法、优先级调度算法和高响应比优先调度算法的结合算法的数据服务自动调度技术和优化方案,在不同调度策略下,达到资源的高效利用目的,显著提高了数据中台上数据服务管理的质量和效率,并提供友好、便捷的数据服务。
附图说明
19.图1是本发明面向数据中台的服务感知与资源调度系统中的系统操作流程图。
20.图2是本发明中数据服务全生命周期模型图。
21.图3是本发明中apriorall算法实现流程图。
22.图4是本发明中softmax多分类模型图。
23.图5是本发明中加权高响应比优先调度算法流程图。
24.图6是本发明中遗传
‑
蚁群组合算法流程图。
具体实施方式
25.本发明一种面向数据中台的服务感知与资源调度系统,以数据中台为载体,提出新的数据服务管理模型。首先对数据服务全生命周期建模,提出了基于机器学习方法的数
据服务全生命周期管理及监控分析技术,实现服务的高可用和高效率;其次提出了基于遗传算法和蚁群算法的结合算法、优先级调度算法和高响应比优先调度算法的结合算法的数据服务自动调度技术和优化方案,在不同调度策略下,达到资源的高效利用目的,显著提高数据中台上数据服务管理的质量和效率。
26.本发明一种面向数据中台的服务感知与资源调度系统,包括任务管理模块、任务分析模块、服务管理模块和调度优化模块,其中:
27.服务管理模块,首先为数据中台开放的数据服务建立全生命周期模型,并且建立softmax多分类模型,对数据服务进行动态监控和维护;
28.任务管理模块,感知用户的任务请求相关信息,同时将任务请求阻断并将相关信息存储到数据库和zookeeper中;
29.任务分析模块,建立多元线性回归模型对任务进行质量分析,使用apriorall序列挖掘算法进行任务序列的预测;
30.调度优化模块,查看当前任务的调度序列,并根据用户偏好的调度策略来选择相应的调度算法,对当前任务调度序列进行优化,以达到资源利用的最大化。
31.进一步地,服务管理模块中,为数据中台开放的数据服务建立全生命周期模型,包括生成态、实施态、运行态、冻结态和撤销态,其中:
32.生成态为服务的初始状态,开发人员在此阶段设定服务基本信息;
33.实施态为服务的前期状态,在此阶段由运维工作者配置服务的参数;
34.运行态为服务的中期状态,服务正常开放工作;
35.冻结态为服务的后期状态,在此阶段服务暂停对外开放,并将剩余任务处理完成;
36.撤销态为服务的终止状态,为开发人员之后的服务设计开发与实施工作提供参考;
37.数据服务的全生命周期管理,一方面要实时分析数据服务质量,另一方面要实时监控数据服务当前所处的运行阶段,后期在资源受限状态下对服务资源进行调度,优化资源分配。
38.进一步地,服务管理模块中,建立softmax多分类模型,对数据服务进行动态监控和维护,具体为:根据数据服务当前运行参数,包括每秒钟作出的响应次数,服务状态活跃度和服务部署时间,动态识别数据服务运行状态,监控并维护数据服务的运行。
39.进一步地,所述的任务管理模块,具体作用为:使用基于注解的、对http请求无侵入的方式动态感知用户的任务请求相关信息,包括主机地址、端口、url、接口类型,同时将任务请求阻断并将相关信息存储到数据库和zookeeper中。
40.进一步地,所述的任务分析模块,具体作用为:构建多元线性回归模型,用响应时间、运行时间、优先级、丢包率这些历史数据训练模型,然后实时分析任务质量,得到量化后的任务质量值,对数据服务是否需要进行改善作出分析,进一步改善服务质量;使用apriorall序列挖掘算法,从历史任务请求序列中挖掘出高频序列,再分析当前任务请求序列,从而预测出接下来可能发生的任务请求,据此提前进行下级资源调度。
41.进一步地,所述的调度优化模块,具体作用为:用户查看当前任务的调度序列,根据用户偏好的调度策略,包括优先级、时间资源、计算资源和存储资源,从加权高响应比优先调度算法、遗传
‑
蚁群组合算法中选择相应的调度算法,对当前任务调度序列进行优化
并,以达到资源利用的最大化。
42.本发明一种面向数据中台的服务感知与资源调度方法,包括以下步骤:
43.步骤1、在服务管理模块中构建数据服务全生命周期模型;
44.步骤2、服务管理模块利用softmax多分类模型实时监控并维护数据服务的运行状态;
45.步骤3、任务管理模块动态感知用户的任务请求相关信息,同时将其阻断并存入数据库和zookeeper中;
46.步骤4、任务分析模块对感知到的用户任务请求进行质量分析和请求序列预测;
47.步骤5、调度优化模块按照用户偏好的调度策略选择相应调度算法,对感知到的任务请求进行序列优化并放行。
48.进一步地,步骤2所述服务管理模块利用softmax多分类模型实时监控并维护数据服务的运行状态具体为:
49.softmax模型为:
[0050][0051]
式中,k为softmax多分类的种类数目,k=5,即对应服务状态全生命周期管理的5个状态;x为训练数据,i为训练数据编号,θ为模型参数;
[0052]
softmax多分类器的交叉熵损失函数j(θ)为:
[0053][0054]
式中,m为训练数据的数量,y为训练数据标签列向量,j为训练数据对应的实际服务状态类别,k为服务状态总数;p为测试结果与实际结果相同的概率,具体表示为:
[0055][0056]
采用梯度下降优化算法最小化损失函数,用tensorflow库中的gradientdescentoptimizer优化器,得出模型参数θ;
[0057]
根据训练出的模型和给定的数据服务运行状态参数,识别出当前服务所处的运行状态。
[0058]
进一步地,步骤4所述任务分析模块对感知到的用户任务请求进行质量分析和请求序列预测,具体如下:
[0059]
(1)任务质量分析
[0060]
首先对任务质量qos进行量化,把任务质量量化到0.0到10.0之间的数字,其中[0.0
‑
5.9)代表服务质量低下,[6.0
‑
8.0)代表服务质量良好,[8.0
‑
10.0]代表服务质量优秀,经过量化的服务质量是一个生命周期数据服务的标签;
[0061]
采用机器学习中的线性回归分析方法建立qos和任务运行特征参数之间的回归模型,如下式所示:
[0062]
qos=θ0response_time θ1cycling_time θ2priority θ3packet_loss b
[0063]
上式中,是一个列向量,即回归模型的参数,其中b是偏置参数,[θ0,θ1,θ2,θ3]是权重参数,response_time是任务的响应时间,cycling_time是任务的周转时间,priority是任务的优先级,packet_loss是任务的丢包率;
[0064]
回归模型的优化目标函数如下式所示:
[0065][0066]
在目标函数中,为采集得到的训练数据矩阵;y为训练数据标签列向量,即经过量化的数据服务质量;min为取最小函数;
[0067]
采用梯度下降优化法对该回归分析模型进行训练得到模型参数采用tensorflow库中的gradientdescentoptimizer优化器,针对未标注的数据服务即测试数据集,把这些未标注的数据服务的运行特征参数输入到回归模型中,得到每一个未标注的数据服务的qos预测值,进一步对数据服务是否需要进行优化作出智能分析;
[0068]
(2)任务请求序列预测
[0069]
采用基于序列挖掘的任务预测算法,依据用户历史任务请求记录,挖掘高频任务;通过当前序列与高频序列的匹配,进一步预测下一阶段可能的任务,根据提前发现的任务进行下级资源调度,实现数据服务管理的数据服务;
[0070]
任务预测算法选用apriorall算法,首先挖掘历史任务请求序列中达到最小支持度的不同长度的序列,称为大序列;然后在大序列中寻找最大序列,最大序列表示不包含在任何其他序列中的大序列;找到最大序列集后,将最大序列集里的序列以支持度和长度从高到低排序,然后以当前任务的序列去和最大序列集的序列匹配,如果当前任务序列包含在一个最大序列中,那么匹配成功,输出匹配成功的最大序列中当前任务序列之后的序列作为预测到的任务序列。
[0071]
进一步地,步骤5所述的调度优化模块按照用户偏好的调度策略选择相应调度算法,对感知到的任务请求进行序列优化并放行,具体如下:
[0072]
1)偏好任务优先级和时间资源的调度策略,对应加权高响应比优先调度算法,本算法将优先级调度算法、高响应比优先调度算法结合,以优先级为权值,建立加权响应比概念,该概念定义为优先级与响应比的乘积;根据任务的优先级和预计运行时间两个特征参数对服务序列进行优化,每次选出最大加权响应比的任务先调度执行,从而形成一个侧重时间资源和优先级的调度优化策略的任务调度序列;
[0073]
2)偏好计算资源和存储资源的调度策略,对应遗传
‑
蚁群组合算法,本算法综合了遗传算法和蚁群算法,先执行遗传算法,然后将遗传算法的结果映射为蚁群的初始信息素分布,再利用蚁群算法的特性得出最优结果,最终得到一个侧重计算资源和存储资源的调度优化策略的任务调度序列。
[0074]
下面结合附图及具体实施例对本发明做进一步详细描述。
[0075]
实施例
[0076]
本发明面向数据中台的服务感知与资源调度系统包括任务管理模块、任务分析模块、调度优化模块和服务管理模块,其中:
[0077]
服务管理模块下,首先对数据中台上的数据服务进行全生命周期建模,生命周期
模型中个状态具体为:
[0078]
生成态:服务的初始状态,开发人员在此阶段设定服务基本信息;
[0079]
实施态:为服务的前期状态,在此阶段一般由运维工作者配置服务的参数;
[0080]
运行态:服务的中期状态,服务正常开放工作,是生命周期中的“鼎盛”时期;
[0081]
冻结态:服务的后期状态,在此阶段,服务暂停对外开放,并会将剩余任务处理完成;
[0082]
撤销态:服务的终止状态,可为开发人员在之后的服务设计开放与实施工作上提供一定的参考。
[0083]
数据服务的全生命周期管理,不仅要实时分析数据服务质量,还要实时监控数据服务当前所处的运行阶段,以便后期在资源受限状态下采用进化算法对服务资源进行调度,优化资源分配,实现敏捷、友好的数据服务支撑。
[0084]
其次,在本模块下,可以查看当前数据服务的列表和各服务的相关信息,并且可以识别每个服务当前的运行状态。
[0085]
根据调研分析阶段抽取的数据服务的每个状态对应的刻画每个状态的运行参数(例如每秒钟作出的响应次数,服务状态活跃度,服务部署时间等),本发明把机器学习方法的softmax多分类器应用到数据服务状态全生命周期管理中,用于识别数据服务状态。
[0086]
softmax模型为:
[0087][0088]
式中,k为softmax多分类的种类数目,本课题中对应的k=5,即对应服务状态全生命周期管理的5个状态;x为训练数据,θ为模型参数。softmax多分类器还需要给出其交叉熵损失函数,公式为:
[0089][0090]
其中,
[0091][0092]
这里采用梯度下降优化算法来最小化损失函数,用tensorflow库中的gradientdescentoptimizer优化器,得出模型参数θ。根据训练出的模型和给定的数据服务运行状态参数,可以识别出当前服务所处的运行状态。
[0093]
任务管理模块下,可以查看到系统感知到的任务请求的列表以及各任务请求的相关信息,并且可以对任务进行简单的操作。本模块功能采用开源微服务任务调度框架——宜信公司的sia
‑
task调度框架中的基于注解的方式感知任务。本项目使用springboot框架进行开发。首先将任务抓取器的相关maven依赖包导入项目。然后,据此制定项目的开发规范章程,在控制层的方法上添加抓取任务的相关注解。引入相关依赖和注解后,本方法便可以在任务进行http请求之后自动获取其主机ip地址、端口、url、接口类型等信息。此方法总
体流程为先对http请求进行拦截和阻断,然后将相关信息存入zookeeper和数据库中,并显示在前端页面上。最后,经过对任务的信息展示、质量分析、任务序列预测和调度序列优化等工作之后,按优化后的序列放行。此方式对http方法请求无侵入,安全性较高。
[0094]
任务分析模块下,可以查看当前任务请求的列表。可以对任务进行质量分析,并且可以根据当前任务请求的序列预测接下来可能会发生的任务请求的序列。其中:
[0095]
任务质量分析为:首先需对任务质量(qos)进行量化。把任务质量量化到0.0到10.0之间的数字,其中[0.0
‑
5.9)代表服务质量低下,[6.0
‑
8.0)代表服务质量良好,[8.0
‑
10.0]代表服务质量优秀。经过量化的服务质量就是一个生命周期数据服务的标签。
[0096]
本模块采用机器学习中的线性回归分析方法建立qos和任务运行特征参数之间的回归模型,如下式所示:
[0097]
qos=θ0response_time θ1cycling_time θ2priority θ3packet_loss b
[0098]
上式中,是一个列向量,即回归模型的参数,其中b是偏置参数,[θ0,θ1,θ2,θ3]是权重参数。该线性回归模型还需要给出其优化目标函数,如下式所示:
[0099][0100]
在回归模型目标函数中,为采集得到的训练数据矩阵,y为训练数据标签列向量,即经过量化的数据服务质量。采用梯度下降优化法对该回归分析模型进行训练得到模型参数这里采用tensorflow库中的gradientdescentoptimizer优化器。针对未标注的数据服务(即测试数据集),把这些未标注的数据服务的运行特征参数输入到该回归模型中,得到每一个未标注的数据服务的qos预测值。
[0101]
如果预测出的数据任务质量在[0.0,5.9)范围内,则说明该数据服务的qos低下,需要对其进行优化。
[0102]
通过建立机器学习中的线性回归模型,可以预测数据服务的qos,进一步对数据服务是否需要进行改善作出智能分析,进一步改善服务质量,从而提供高效稳定友好的数据服务。
[0103]
任务序列预测是指依据历史任务序列,发现任务组合的高频序列。通过当前序列与高频序列进行匹配来进行任务预测。本项目采用基于序列挖掘的任务预测算法,依据用户历史任务请求记录,挖掘高频任务;依据高频任务进一步预测下一阶段可能的任务,可根据提前发现的任务进行下级资源调度,实现数据服务管理的自动化和便捷化,提供友好、敏捷的数据服务。
[0104]
本模块功能选用apriorall算法。首先挖掘历史任务请求序列中达到最小支持度的的不同长度的大序列。最小支持度通常是人为设定的。然后在大序列中寻找最大序列,最大序列表示不包含在任何其他序列中的大序列。
[0105]
找到最大序列集后,将最大序列集里的序列以支持度和长度从高到低排序,然后以当前任务的序列去和最大序列集的序列匹配,如果当前任务序列包含在某个最大序列中,那么匹配成功,输出最大序列中当前任务序列之后的序列作为预测到的任务序列。
[0106]
调度优化模块下,可以查看当前任务的调度序列,并且可以根据用户偏好的调度策略(优先级、时间资源、计算资源和存储资源)来选择相应的调度算法(加权高响应比优先调度算法,遗传
‑
蚁群组合算法),对当前任务调度序列进行优化,以达到资源利用的最大
化。
[0107]
其中加权高响应比优先调度算法参考了操作系统中的作业和任务的调度算法。选用优先级调度算法(hpf)、高响应比优先调度算法(hrrn)。将二者结合为“加权高响应比优先调度算法”。hpf算法的基本思想为,每次优先调度执行优先级最高的任务。hrrn算法的基本思想为每次优先调度执行最高响应比的作业。响应比的定义为周转时间与执行时间的比值。加权高响应比优先调度算法综合前两种算法,以优先级为权值,建立“加权响应比”概念,定义为优先级与响应比的乘积。本算法根据任务的优先级和预计运行时间两个特征参数对服务序列进行优化,每次选出最大“加权响应比”的任务先调度执行,从而形成一个侧重时间资源和优先级的调度优化策略的任务调度序列。
[0108]
其中遗传
‑
蚁群组合算法综合了遗传算法和蚁群算法的优势。前者效率高,后者求解精度高。将二者巧妙结合,便同时提高了算法的时间效率以及求解精度。先执行遗传算法,然后将遗传算法的结果映射为蚁群的初始信息素分布。在此基础上,利用蚁群算法的特性得出最优结果。算法细节如下:
[0109]
任务基本数据初始化:将任务的cpu占用(计算资源)和内存占用(存储资源)作为任务的两个特征数据来进行调度。
[0110]
遗传算法的参数初始化:将需要调度优化的任务个数作为种群规模。设定种群发展的代数,个体发生交叉和变异的概率等。
[0111]
遗传算法的种群初始化:设定新旧种群,将需要调度优化的任务的个数定义作为个体dna长度,基因型便为任务调度序列。同时初始化适应度矩阵、累积矩阵和目标函数。其中目标函数作为计算个体适应度的函数,具体约束规则为:如果两个任务的cpu占用比之和不到100%,本文中认为和越小,越可能再容纳一个新的任务一起执行,这两个任务一起执行的概率越大,则两任务“距离”越小;如果两个任务的cpu占用之和大于100%且小于200%,本文中认为和越接近100%,越需要和较小任务结合,一起执行概率越小,则两任务“距离越大”,反之和越接近200%,两任务“距离”越小。存储资源的计算方式同理。以此目标函数约束方式来计算个体的适应度。
[0112]
遗传算法的选择事件:依据计算的累积矩阵来选择要交叉的个体。
[0113]
遗传算法的交叉事件:对于满足交叉概率的两个个体,在随机选中的区域进行交叉。
[0114]
遗传算法的变异事件:对于满足变异概率的个体,将随机选中的dna区域的序列变为逆序。
[0115]
蚁群算法的参数初始化:将需要调度的任务作为蚁群要遍历的城市。按遗传算法目标函数的约束规则来设定各个城市(任务)之间的距离。
[0116]
蚁群算法个体信息初始化:确定蚁群的个体数量,每个个体出发的城市。
[0117]
蚁群算法中用遗传算法的结果初始化信息素:设定任意两个城市之间信息素为某定值,然后遗传算法的最后一代个体的基因型每有相邻的两个任务,就把这两个任务(城市)之间的信息素乘一个权值(1.005),以此来实现两个任务(城市)相邻的频率越高,信息素越高。
[0118]
蚁群算法中蚂蚁对下一个城市的选择方式:通过信息素和距离计算计算概率,以轮盘赌注的方式进行选择。
[0119]
蚁群算法的计算当前最优路径:在本代蚁群中,所有蚂蚁遍历所有城市(任务)后,计算每个蚂蚁走过的距离,距离最短的路径最最优路径。
[0120]
蚁群算法的更新信息素方式:使用蚁周系统(ant
‑
cycle)模型。公式如下:
[0121]
t
ij
(t 1)=(1
‑
r)
×
t
ij
(t) q/l
k
[0122]
其中r、q为常数,设为r=0.5、q=1.0,l
k
为蚂蚁走过的总长度。(1
‑
r)
×
t
ij
(t)为对所有路径上的信息素做衰减,q/l
k
为新增信息素,距离越长,信息素浓度越低。
[0123]
综上所述,本发明首先为数据中台开放的服务建立生命周期模型,利用softmax多分类模型动态识别并维护服务运行状态。然后任务管理模块通过基于注解的、对http方法请求无侵入的方式感知用户的任务请求相关信息,同时将其阻断并存入zookeeper和数据库中。接下来任务分析模块使用多元线性回归模型对任务质量进行分析,使用序列挖掘算法,通过分析历史任务请求序列和当前任务请求序列预测下一阶段可能请求的任务,据此可提前进行下级资源调度。最后调度优化模块根据用户偏好的调度策略(优先级、时间资源、计算资源和存储资源等)来选择相应的调度算法(加权高响应比优先调度算法,遗传
‑
蚁群组合算法),对当前任务调度序列进行优化并放行,以达到资源利用的最大化。本发明能可显著提高数据中台上数据服务管理的质量和效率,提供友好、便捷的数据服务。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。