1.本发明涉及一种快速检测与识别少样本目标的方法和系统。
技术背景
2.随着人工智能技术的长足发展,深度学习方法以其强大的表示学习的能力,使得在图像识别任务上计算机视觉能比人类视觉取得更优秀的成绩。早在2016年ilsvrc竞赛的图像识别错误率已经达到约2.9%,远远超越了人类的5.1%。
3.但这些深度学习方法往往依托于强大的gpu并行计算能力以及海量的带标签数据资源,而在某些情况下,比如由于数据样本标注难度、成本的限制,对大量这类数据样本进行标注用于深度神经网络的训练是不切实际的。另一方面,企业自主研发的、涉及商业秘密的技术操作等图像数据因存在知识产权保护等问题,往往很难采集到样本,同样地,对于一些珍稀物种,其本身可获取的样本量也是极其小的,若要采用传统的深度神经网络对它们进行智能识别,难度很大。相比之下,人类则非常擅长根据少量的样本识别出新类别的样本,因此,在深度学习领域让计算机也具备这种与人类相似的认知能力,越发“智能”,其研究意义极其深远。
技术实现要素:
4.本发明要克服现有技术的上述缺点,提出一种快速检测与识别少样本目标的方法和系统。
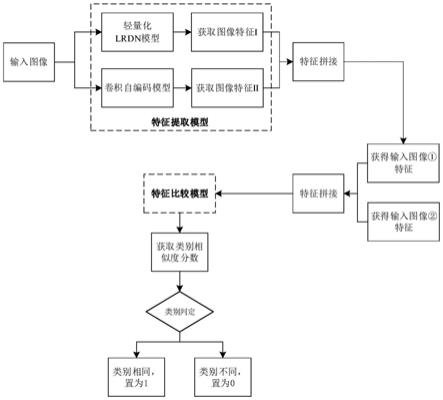
5.本发明首先将所有待检测的图像进行预处理,并按图像类别的比例划分训练集、支持集和测试集。然后通过设计lrdn网络和卷积自编码网络完成特征提取模型的设计,利用预激活的方式构建特征比较模型,两个网络的结合将构成一个端到端训练的模型。特征提取网络将输入图像从图像空间转换到特征表示空间,而特征比较网络则负责将两张图像的特征表示映射为二者属于同一类别的相似度分数,最后完成目标的检测与识别。
6.为了实现上述目的,本发明采用以下技术方案:
7.一种快速检测与识别少样本目标的方法,包括如下步骤:
8.步骤一,图像样本预处理;
9.将所有待检测的图像进行图像增强、去噪后统一缩放为36
×
36,并按图像类别的比例划分为训练集t、支持集s和测试集c。同时要求训练集中的图像类别标签与支持集、测试集中的图像类别标签无交集,而允许测试集中的图像类别与支持集中的图像类别有相同的标签空间。
10.步骤二,设计特征提取模型;
11.一张经过预处理的rgb图像分别利用lrdn网络和卷积自编码网络提取其特征,然后将两个网络的输出进行拼接,作为输入图像的特征表示,使得特征提取模型的输出既具有可重构性又具有可分辨性。对于lrdn网络和卷积自编码网络的设计如步骤(一)和步骤(二)所示。
12.(一)设计lrdn网络;
13.首先,利用1层标准卷积和1层改进的深度可分离卷积提取输入图像的浅层特征。其中,本发明对传统深度可分离卷积操作的改进有:第一,在深度卷积前增加一层1
×
1卷积的“扩张”层,目的是为了提升通道数,获得更多特征。第二,最后不采用relu激活函数,而是直接线性输出,目的是防止relu破坏特征。
14.然后,将浅层特征作为深度特征提取模块的输入,利用lrdb中的局部密集连接、特征复用、下采样操作与残差融合结构获取图像的各项细节特征。其中,对于lrdn模型,深层特征提取模块是其核心部分,而深层特征提取模块由3个lrdb组成。每个lrdb通常包含一个24层的密集连接块、一个下采样过渡块以及一个带池化的恒等连接。而对于模型中的最后一个lrdb,通常直接利用1
×
1conv对该密集块的输出特征进行压缩、整理,然后在倒数第二个lrdb输出的深层特征与压缩后的特征之间加入残差连接,获取最终的深层特征。
15.最后,利用全局平均池化聚合特征图,输出特征向量f1。
16.(二)设计卷积自编码网络;
17.利用标准卷积的思想,将32组“relu 1
×
1conv relu 3
×
3conv”设置为一个正向block,将32组“relu 1
×
1反卷积 relu 3
×
3反卷积”设置为一个反向block,其中1
×
1卷积的作用是为了对输入的特征进行整理、压缩。然后将3个正向block进行串接,同时在每个正向block之间添加一层2
×
2的最大池化层进行下采样,同样地,将3个反向block进行串接,同时在每个反向block之间添加一层2
×
2的最大反池化层进行下采样。在网络的学习过程中,将最后一个正向block的输出作为第一个反向block的输入,将最后一个反向block的输出作为全局平均池化层的输入,利用全局平均池化聚合特征图,最终得到与f1维度相同的输出特征向量f2。
18.步骤三,设计特征比较模型;
19.将两张图像的特征表示进行拼接作为特征比较模型的输入,然后利用一层2
×
2的最大池化层对输入进行下采样。将32组“batch normalization relu 1
×
1conv batch normalization relu 3
×
3conv”设置为一个单元,然后把3个单元进行串接,每个单元之间同样添加一层2
×
2的最大池化层进行下采样。把最后一个单元的输出作为全连接层的输入,再把全连接层的输出映射到sigmoid函数中,将表征两个输入图像特征的相似度分数归一化到区间[0,1]。
[0020]
步骤四,检测与识别目标;
[0021]
假定每一类待识别图像的数量是相等的,若某类图像的数量不足,则通过随机旋转、颜色变换等方法进行数据增强。在模型的训练阶段,把训练集t表示为:
[0022]
t={(x
i
,y
i
)},i∈[1,n]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0023]
其中,x
i
表示待识别的图像;y
i
表示待识别图像的标签值;n表示训练集中某类图像的数量。
[0024]
接着从训练集t中选取每种对应类别的m张图像组成查询集q,即有:
[0025]
q={(x
j
,y
j
)},j∈[1,m]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0026]
紧接着将图像集x
i
和图像集x
j
分别输入到特征提取模型f中,可得二者的特征表示分别为f(x
i
)和f(x
j
),在两个数据集中任选两张图像的特征表示进行拼接,得:
[0027]
λ={[f(x
i
),f(x
j
)]}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0028]
然后把式(3)的值输入特征比较模型h中,进一步得到特征比较模型的输出,即两张图像属于同一类别的相似度分数为:
[0029]
ω=h(λ)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0030]
最后把两个输入图像特征的相似度分数归一化到区间[0,1],若二者属于同一类别,则其分数值置为1,否则为0。
[0031]
在模型的测试阶段,利用特征提取模型获得支持集s和测试集c中每一张图像的特征表示后,在两个数据集中分别任选一张图像的特征表示进行两两拼接,进而利用特征比较模型获取二者之间的相似度分数。对于每一张测试图像,选择与之分数最高的特征拼接组合,该组合中支持集所属的类别即为该测试图像的类别。
[0032]
本发明还包括实施上述一种快速检测与识别少样本目标的方法的系统,包括依次连接的图像样本预处理模块、特征提取模型设计模块、特征比较模型设计模块、检测与识别目标模块。
[0033]
本发明的优点是:
[0034]
本发明基于轻量化卷积神经网络和预激活,提出了一种快速检测与识别少样本目标的方法。其突出特点有:其一,模型整体结构简单、鲁棒性强,能很好地应用于目标样本量较小情况下的检测与识别。其二,利用轻量型的lrdn模型和卷积自编码网络组建特征提取网络,以分别提取输入图像的特征,使得模型的输出既具有可重构性又具有可分辨性。其三,利用预激活的方式设计特征比较模型,使之学习到的度量准则能够很好地约束数据集内以及数据集之间的类别相似度。
附图说明
[0035]
图1是本发明的技术路线图。
具体实施方式
[0036]
为了验证本发明提出的方法的可行性和优越性,现结合应用场景对本发明做进一步的阐述:
[0037]
一种快速检测与识别少样本目标的方法,包括如下步骤:
[0038]
步骤一,图像样本预处理;
[0039]
将所有待检测的图像进行图像增强、去噪后统一缩放为36
×
36,并按图像类别的比例划分为训练集t、支持集s和测试集c。同时要求训练集中的图像类别标签与支持集、测试集中的图像类别标签无交集,而允许测试集中的图像类别与支持集中的图像类别有相同的标签空间。
[0040]
步骤二,设计特征提取模型;
[0041]
一张经过预处理的rgb图像分别利用lrdn网络和卷积自编码网络提取其特征,然后将两个网络的输出进行拼接,作为输入图像的特征表示,使得特征提取模型的输出既具有可重构性又具有可分辨性。对于lrdn网络和卷积自编码网络的设计如步骤(一)和步骤(二)所示。
[0042]
(一)设计lrdn网络;
[0043]
首先,利用1层标准卷积和1层改进的深度可分离卷积提取输入图像的浅层特征。
其中,本发明对传统深度可分离卷积操作的改进有:第一,在深度卷积前增加一层1
×
1卷积的“扩张”层,目的是为了提升通道数,获得更多特征。第二,最后不采用relu激活函数,而是直接线性输出,目的是防止relu破坏特征。
[0044]
然后,将浅层特征作为深度特征提取模块的输入,利用lrdb中的局部密集连接、特征复用、下采样操作与残差融合结构获取图像的各项细节特征。其中,对于lrdn模型,深层特征提取模块是其核心部分,而深层特征提取模块由3个lrdb组成。每个lrdb通常包含一个24层的密集连接块、一个下采样过渡块以及一个带池化的恒等连接。而对于模型中的最后一个lrdb,通常直接利用1
×
1conv对该密集块的输出特征进行压缩、整理,然后在倒数第二个lrdb输出的深层特征与压缩后的特征之间加入残差连接,获取最终的深层特征。
[0045]
最后,利用全局平均池化聚合特征图,输出特征向量f1。
[0046]
(二)设计卷积自编码网络;
[0047]
利用标准卷积的思想,将32组“relu 1
×
1conv relu 3
×
3conv”设置为一个正向block,将32组“relu 1
×
1反卷积 relu 3
×
3反卷积”设置为一个反向block,其中1
×
1卷积的作用是为了对输入的特征进行整理、压缩。然后将3个正向block进行串接,同时在每个正向block之间添加一层2
×
2的最大池化层进行下采样,同样地,将3个反向block进行串接,同时在每个反向block之间添加一层2
×
2的最大反池化层进行下采样。在网络的学习过程中,将最后一个正向block的输出作为第一个反向block的输入,将最后一个反向block的输出作为全局平均池化层的输入,利用全局平均池化聚合特征图,最终得到与f1维度相同的输出特征向量f2。
[0048]
步骤三,设计特征比较模型;
[0049]
将两张图像的特征表示进行拼接作为特征比较模型的输入,然后利用一层2
×
2的最大池化层对输入进行下采样。将32组“batch normalization relu 1
×
1conv batch normalization relu 3
×
3conv”设置为一个单元,然后把3个单元进行串接,每个单元之间同样添加一层2
×
2的最大池化层进行下采样。把最后一个单元的输出作为全连接层的输入,再把全连接层的输出映射到sigmoid函数中,将表征两个输入图像特征的相似度分数归一化到区间[0,1]。
[0050]
步骤四,检测与识别目标;
[0051]
假定每一类待识别图像的数量是相等的,若某类图像的数量不足,则通过随机旋转、颜色变换等方法进行数据增强。在模型的训练阶段,把训练集t表示为:
[0052]
t={(x
i
,y
i
)},i∈[1,n]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0053]
其中,x
i
表示待识别的图像;y
i
表示待识别图像的标签值;n表示训练集中某类图像的数量。
[0054]
接着从训练集t中选取每种对应类别的m张图像组成查询集q,即有:
[0055]
q={(x
j
,y
j
)},j∈[1,m]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0056]
紧接着将图像集x
i
和图像集x
j
分别输入到特征提取模型f中,可得二者的特征表示分别为f(x
i
)和f(x
j
),在两个数据集中任选两张图像的特征表示进行拼接,得:
[0057]
λ={[f(x
i
),f(x
j
)]}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0058]
然后把式(3)的值输入特征比较模型h中,进一步得到特征比较模型的输出,即两张图像属于同一类别的相似度分数为:
[0059]
ω=h(λ)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0060]
最后把两个输入图像特征的相似度分数归一化到区间[0,1],若二者属于同一类别,则其分数值置为1,否则为0。
[0061]
在模型的测试阶段,利用特征提取模型获得支持集s和测试集c中每一张图像的特征表示后,在两个数据集中分别任选一张图像的特征表示进行两两拼接,进而利用特征比较模型获取二者之间的相似度分数。对于每一张测试图像,选择与之分数最高的特征拼接组合,该组合中支持集所属的类别即为该测试图像的类别。
[0062]
本发明还包括实施上述一种快速检测与识别少样本目标的方法的系统,包括依次连接的图像样本预处理模块、特征提取模型设计模块、特征比较模型设计模块、检测与识别目标模块。
[0063]
图像样本预处理模块包括:将所有待检测的图像进行图像增强、去噪后统一缩放为36
×
36,并按图像类别的比例划分为训练集t、支持集s和测试集c。同时要求训练集中的图像类别标签与支持集、测试集中的图像类别标签无交集,而允许测试集中的图像类别与支持集中的图像类别有相同的标签空间。
[0064]
特征提取模型设计模块包括:一张经过预处理的rgb图像分别利用lrdn网络和卷积自编码网络提取其特征,然后将两个网络的输出进行拼接,作为输入图像的特征表示,使得特征提取模型的输出既具有可重构性又具有可分辨性。对于lrdn网络和卷积自编码网络的设计如步骤(一)和步骤(二)所示。
[0065]
(一)设计lrdn网络;
[0066]
首先,利用1层标准卷积和1层改进的深度可分离卷积提取输入图像的浅层特征。其中,本发明对传统深度可分离卷积操作的改进有:第一,在深度卷积前增加一层1
×
1卷积的“扩张”层,目的是为了提升通道数,获得更多特征。第二,最后不采用relu激活函数,而是直接线性输出,目的是防止relu破坏特征。
[0067]
然后,将浅层特征作为深度特征提取模块的输入,利用lrdb中的局部密集连接、特征复用、下采样操作与残差融合结构获取图像的各项细节特征。其中,对于lrdn模型,深层特征提取模块是其核心部分,而深层特征提取模块由3个lrdb组成。每个lrdb通常包含一个24层的密集连接块、一个下采样过渡块以及一个带池化的恒等连接。而对于模型中的最后一个lrdb,通常直接利用1
×
1conv对该密集块的输出特征进行压缩、整理,然后在倒数第二个lrdb输出的深层特征与压缩后的特征之间加入残差连接,获取最终的深层特征。
[0068]
最后,利用全局平均池化聚合特征图,输出特征向量f1。
[0069]
(二)设计卷积自编码网络;
[0070]
利用标准卷积的思想,将32组“relu 1
×
1conv relu 3
×
3conv”设置为一个正向block,将32组“relu 1
×
1反卷积 relu 3
×
3反卷积”设置为一个反向block,其中1
×
1卷积的作用是为了对输入的特征进行整理、压缩。然后将3个正向block进行串接,同时在每个正向block之间添加一层2
×
2的最大池化层进行下采样,同样地,将3个反向block进行串接,同时在每个反向block之间添加一层2
×
2的最大反池化层进行下采样。在网络的学习过程中,将最后一个正向block的输出作为第一个反向block的输入,将最后一个反向block的输出作为全局平均池化层的输入,利用全局平均池化聚合特征图,最终得到与f1维度相同的输出特征向量f2。
[0071]
特征比较模型设计模块包括:将两张图像的特征表示进行拼接作为特征比较模型的输入,然后利用一层2
×
2的最大池化层对输入进行下采样。将32组“batch normalization relu 1
×
1conv batch normalization relu 3
×
3conv”设置为一个单元,然后把3个单元进行串接,每个单元之间同样添加一层2
×
2的最大池化层进行下采样。把最后一个单元的输出作为全连接层的输入,再把全连接层的输出映射到sigmoid函数中,将表征两个输入图像特征的相似度分数归一化到区间[0,1]。
[0072]
检测与识别目标模块包括:假定每一类待识别图像的数量是相等的,若某类图像的数量不足,则通过随机旋转、颜色变换等方法进行数据增强。在模型的训练阶段,把训练集t表示为:
[0073]
t={(x
i
,y
i
)},i∈[1,n]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0074]
其中,x
i
表示待识别的图像;y
i
表示待识别图像的标签值;n表示训练集中某类图像的数量。
[0075]
接着从训练集t中选取每种对应类别的m张图像组成查询集q,即有:
[0076]
q={(x
j
,y
j
)},j∈[1,m]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0077]
紧接着将图像集x
i
和图像集x
j
分别输入到特征提取模型f中,可得二者的特征表示分别为f(x
i
)和f(x
j
),在两个数据集中任选两张图像的特征表示进行拼接,得:
[0078]
λ={[f(x
i
),f(x
j
)]}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0079]
然后把式(3)的值输入特征比较模型h中,进一步得到特征比较模型的输出,即两张图像属于同一类别的相似度分数为:
[0080]
ω=h(λ)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0081]
最后把两个输入图像特征的相似度分数归一化到区间[0,1],若二者属于同一类别,则其分数值置为1,否则为0。
[0082]
在模型的测试阶段,利用特征提取模型获得支持集s和测试集c中每一张图像的特征表示后,在两个数据集中分别任选一张图像的特征表示进行两两拼接,进而利用特征比较模型获取二者之间的相似度分数。对于每一张测试图像,选择与之分数最高的特征拼接组合,该组合中支持集所属的类别即为该测试图像的类别。
[0083]
本说明书实施例所述的内容仅仅是对发明构思的实现形式的列举,本发明的保护范围不应当被视为仅限于实施例所陈述的具体形式,本发明的保护范围也及于本领域技术人员根据本发明构思所能够想到的等同技术手段。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。