1.本发明涉及软硬件协同加速技术领域,具体涉及一种基于软硬件协同加速的关系网络推理优化的方法。
背景技术:
2.基于深度学习的卷积神经网络技术广泛应用于图像处理任务中,在大规模标注的imagenet数据集上提出的alexnet、vgg16、resnet等大规模深度模型,展现了较高的识别准确率。然而,在少样本学习应用中,尤其是对新的未知类别分类任务中,需要新的学习模式和方法,包括matching nets、meta nets、maml、 prototypical nets、relation net等少样本学习方法,通过构建多批次的不同类别任务对模型进行训练,引入支持集作为先验知识,用以处理未知类别任务的分类,关系网络相对于其他模型,在ominiglot数据集和miniimagenet数据集上取得了较高的识别准确率。
3.关系网络采用浅层卷积块的设计方式构建了特征提取模块和关系计算模块,通常的推理计算方式采用中央处理器(central processing unit,cpu)或者图形处理器(graphics processing unit,gpu)进行处理,使用cpu处理速度较慢,使用 gpu处理能效不高。关系网络以及少样本学习技术
[4
‑
8]
受限于少量样本在大模型网络的过拟合问题,通常采用浅层卷积块的方式构建特征提取模块和关系计算模块,计算复杂度和模型参数存储量相对较少,适合基于现场可编程门阵列(fieldprogrammable gate array,fpga)处理的加速方式。
[0004]
典型的关系网络推理输入为支持集、测试图像,输出为关系分数,多个支持集的关系分数最终选出测试图像的类别,同一张测试图像在不同的支持集相关的关系计算下会输出不同的结果。根据支持集的类别数(c
‑
way)、每类支持集的数量(k
‑
shot),可以构成不同的c
‑
way k
‑
shot推理任务。关系网络推理计算包括两个模块的卷积计算部分,分别是特征提取模块和关系计算模块,主要由卷积计算、最大池化计算以及全连接计算组成。特征提取模块用于支持集和测试图像的特征提取,对于c
‑
way k
‑
shot模式的支持集特征提取,k为1时,输出为单张图像的卷积输出特征图,k大于1时,则是多张图像的卷积输出特征对应元素累加值。经过特征提取模块提取了支持集特征和测试图像特征后,测试图像特征与支持集特征拼接起来构成输入特征图送入关系计算模块,分别计算特征的相似度为输出值,对于c
‑
way的特征值,选取分数最大的作为该测试图像的类别输出。
[0005]
关系网络的推理计算中存在测试图像与多批次支持集之间的关系计算需求,关系分数的准确率以及置信度依赖于支持集数量的大小。多批次的支持集关系计算引入了非常大的计算、存储开销,基于通用的cpu、gpu处理的关系网络推理计算计算速度慢、能耗较高,需要设计一个高效能的推理计算加速器来提升关系网络推理计算的效能。
技术实现要素:
[0006]
有鉴于此,本发明提供了一种基于软硬件协同加速的关系网络推理优化的方法,
能够解决关系网络推理计算的速度与效能问题,在不降低关系网络推理计算准确率的要求下,采用软硬件协同加速的方式解决处理吞吐量与效能问题。
[0007]
为达到上述目的,本发明的技术方案为:一种基于软硬件协同加速的关系网络推理优化的方法,包括运行在x86/gpu平台的支持集特征提取流程以及运行在fpga芯片的关系网络图像分类推理流程。
[0008]
支持集特征提取流程具体为:
[0009]
接收不同类别的支持集图像数据,支持集是由专家标注的标准数据集,其中的图像数据尺寸一致,且分类标签固定;其中图像数据的类别有c类,每个类别包含k张图像。
[0010]
针对不同类别的支持集进行特征提取,构建不同的特征池,作为离线支持集特征;离线支持集特征包含k个特征池,每个特征池包含c类特征。
[0011]
运行在fpga芯片的关系网络图像分类推理设计采用fpga芯片上构建的测试图像特征提取模块和关系计算模块,具体执行如下流程:
[0012]
接收离线支持集特征存入fpga板卡上的动态随机存取存储器dram。
[0013]
测试图像特征提取模块接收测试图像,并对测试图像进行特征提取,获得测试图像特征。
[0014]
关系计算模块利用测试图像特征以及离线支持集特征,进行关系网络推理计算,获得关系分数。
[0015]
基于fpga的关系网络图像分类推理流程采用多核互联设计,其中关系网络图像分类推理流程中设置m个关系计算模块、n个测试图像特征提取模块、 dram以及控制接口,各模块通过axi互联总线互联。
[0016]
进一步地,利用测试图像特征以及离线支持集特征,进行关系网络推理计算,获得关系分数,具体为:
[0017]
关系网络包括测试特征提取模块和关系计算模块。
[0018]
特征提取模块由4个卷积块和2个最大池化计算层顺次连接组成。
[0019]
关系计算模块由2个卷积块、2个最大池化计算层以及2个全连接计算层顺次连接组成。
[0020]
进一步地,卷积块采用如下流程:
[0021]
卷积块的输入特征图为in,设置卷积块的权重数据w;卷积块的输出特征图为out。
[0022]
卷积块的输入特征图in维度为ih
×
iw
×
ic,其中ih为卷积块的输入特征图高度,iw为卷积块的输入特征图宽度,ic为卷积块的输入特征图通道数;卷积块的权重数据w,维度为oc
×
k2×
ic,其中oc为卷积块的输出特征图通道数, k为卷积核大小;卷积块的输出为输出特征图out,维度为oh
×
ow
×
oc,其中oh为卷积块的输出特征图高度,ow为卷积块的输出特征图宽度。
[0023]
设定pe个处理单元,每个神经元内部按照单指令多数据simd个数据进行并行计算设计;输入特征图调度为pe
×
simd宽度的数据,每个pe计算的输出为一个神经元的计算输出,pe内部采取simd个计算输出。
[0024]
设定5重循环,只对最内层展开,循环从外层至最内层分别为卷积的第一重循环~卷积的第五循环:设定卷积的第一重循环变量为h,卷积的第二重循环变量w,卷积的第三重循环变量c,卷积的第四重循环变量pe,卷积的第五重循环变量为simd。
[0025]
h、w、c、pe以及simd的初值设定为0,每循环一次自加1,h的上限设定为 oh,w的上限设定为ow,c的上限设定为oc,pe的上限设定为pe,simd的上限设定为simd。
[0026]
其中卷积的第五重循环设定为
[0027]
out[w][h][c/pe pe] =in[pe][simd]
×
w[pe][simd]
[0028]
其中in[pe][simd]为卷积块的输入特征图in的第pe行第simd列参数; w[pe][simd]为卷积块的权重数据w的第pe行第simd列参数;out[w][h][c/pe pe] 为卷积块的输出特征图的三维分别为w、h、simd的参数; =符号表示符号左边在原有的基础上增加一个符号右边。
[0029]
进一步地,最大池化计算层具体采用如下流程:
[0030]
池化的输入特征图为in1,设置权重数据w1;输出特征图为out1。
[0031]
池化的输入特征图in1维度为ih1×
iw1×
ic1,其中ih1为池化的输入特征图高度,iw1为池化的输入特征图宽度,ic1为池化的输入特征图通道数;池化的权重数据w1,维度为oc1×
k
12
×
ic1,其中oc1为池化的输出特征图通道数,k1为池化核的大小;池化输出为输出特征图out1,维度为oh1×
ow1×
oc1,其中 oh1为池化的输出特征图高度,ow1为池化输出特征图宽度。
[0032]
设置pool_size为最大池化计算层的的池化大小,max为选取最大值。
[0033]
设定6重循环,只对最内层循环展开,展开式为pe1,循环从外层至最内层分别为池化的第一重循环~池化的第五循环:设定池化的第一重循环变量为h1,池化的第二重循环变量ph,池化的第三重循环变量w1,池化的第四重循环变量 pw,池化的第五重循环变量为c1以及池化的第六重循环变量pe1。
[0034]
h1、ph、w1、pw、c1以及pe1的初值设定为0,每循环一次自加1,h1的上限设定为oh1,ph的上限设定为pool_size,w1的上限设定为ow1,pw的上限设定为pool_size,c1的上限设定为oc1,pe1的上限设定为pe1。
[0035]
其中池化的第六重循环设定为
[0036]
out1[w1][h1][c1/pe1 pe1]=max(in1[pe1],out1[w1][h1][c1/pe1 pe1])
[0037]
其中out1[w1][h1][c/pe1 pe1]表示池化的输出特征图中三维分别为 [w1][h1][c/pe1 pe1]的参数,out1矩阵中初始存负无穷;max()表示取括号中数值的最大值;in1[pe1]表示池化特征图中第pe1行。
[0038]
进一步地,全连接计算层具体采用如下流程:
[0039]
全连接计算层的输入特征图为in2,设置全连接计算层的权重数据w2;全连接计算层的输出特征图为out2。
[0040]
全连接计算层的输入特征图in2维度为ih2×
iw2×
ic2,其中ih2为全连接计算层的输入特征图高度,iw2为全连接计算层的输入特征图宽度,ic2为全连接计算层的输入特征图通道数;全连接计算层的权重数据w2,维度为oc2×
k
22
×
ic2,其中oc2为全连接计算层的输出特征图通道数,k2为全连接计算层的卷积核大小;全连接计算层的输出为输出特征图out2,维度为oh2×
ow2×
oc2,其中 oh2为全连接计算层的输出特征图高度,ow2为全连接计算层的输出特征图宽度。
[0041]
该全连接计算层设定包含3重循环,从外层至内层分别为c循环、pe循环和simd循环,仅对pe循环和simd循环进行展开,设计为包含pe2×
simd2并行度处理模块,每个pe2计算
一个全连接神经元的输出,神经元内部具有 simd2个乘累加单元并行计算。
[0042]
设定c循环的循环变量为c2,pe循环的循环变量为pe2,simd循环的循环变量为simd2。
[0043]
c2、pe2以及simd2的初值设定为0,每循环一次自加1,c2的上限设定为oc2, pe2的上限设定为pe2,simd2的上限设定为simd2。
[0044]
simd循环设定为:
[0045]
out2[c2/pe2 pe2] =in2[pe2][simd2]
×
w2[pe2][simd2]。
[0046]
其中out2[c2/pe2 pe2]为全连接计算层的输出特征图out2第c2/pe2 pe2个参数;in2[pe2][simd2]为全连接计算层的输入特征图in2的第pe2行和第simd2列的参数;w2[pe2][simd2]为全连接计算层的权重数据的第pe2行和第simd2列的参数; =符号表示符号左边在原有的基础上增加一个符号右边。
[0047]
有益效果:
[0048]
本发明实施例提供的一种基于软硬件协同加速的关系网络推理优化的方法,针对关系网络推理计算的高效能处理需求,在不降低关系网络推理计算准确率的要求下,采用软硬件协同加速的方式解决处理吞吐量与效能问题。对于支持集的特征提取采用cpu/gpu的方式构建支持集特征池,供后续fpga推理加速器共享使用,节约结算开销;对于关系网络fpga片上计算单元设计采用高级综合循环优化、异构多核的方式在提升处理能效的同时提升处理吞吐量。。
附图说明
[0049]
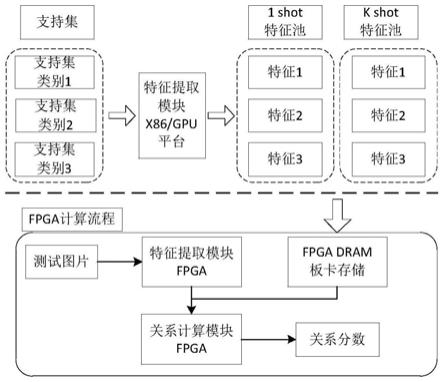
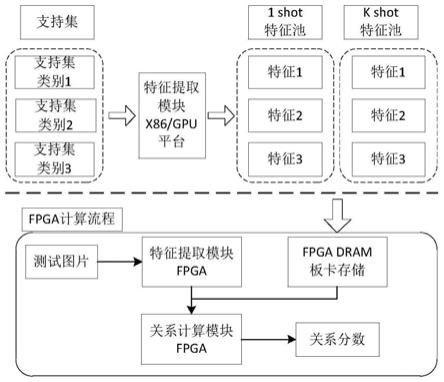
图1为本发明实施方式的基于软硬件协同加速处理的关系网络推理计算流程示意图;
[0050]
图2为关系网络推理计算片上多核互联设计示意图;
[0051]
图3为通用关系网络算法推理计算模块结构示意图;
[0052]
图4为omniglot28片上多核互联设计实例示意图;
[0053]
图5为miniimagenet84片上多核互联设计实例示意图。
具体实施方式
[0054]
下面结合附图并举实施例,对本发明进行详细描述。
[0055]
本发明提供了一种基于软硬件协同加速的关系网络推理优化的方法,其具体步骤包括:包括运行在x86/gpu平台的特征提取流程以及运行在fpga芯片的关系网络图像分类推理流程;
[0056]
特征提取流程具体为:
[0057]
接收不同类别的支持集图像数据,支持集是由专家标注的标准数据集,其中的图像数据尺寸一致,且分类标签固定;其中图像数据的类别有c类,每个类别包含k张图像。
[0058]
针对不同类别的支持集进行特征提取,构建不同的特征池,作为离线支持集特征;离线支持集特征包含k个特征池,每个特征池包含c类特征。
[0059]
关系网络图像分类推理流程采用测试图像特征提取模块和关系计算模块,具体执行如下流程:
[0060]
接收离线支持集特征存入动态随机存取存储器dram。
[0061]
测试图像特征提取模块接收测试图像,并对测试图像进行特征提取,获得测试图像特征。
[0062]
关系计算模块利用测试图像特征以及离线支持集特征,进行关系网络推理计算,获得关系分数。
[0063]
fpga芯片中的关系网络图像分类推理流程采用多核互联设计,其中关系网络图像分类推理流程中设置m个关系计算模块、n个测试图像特征提取模块、 dram以及控制接口,各模块通过axi互联总线互联。
[0064]
针对关系网络推理计算的速度慢、能耗高的问题,采用软硬件协同加速计算的方式提升处理速度与处理效能。通过cpu或者gpu提取可复用的支持集特征供推理计算使用,降低计算开销;采用hls循环优化设计的特征提取模块以及关系计算模块,提升关系网络推理计算的速度与效能;采用异构多核的设计方式综合利用多核的处理能力进一步提升关系网络推理计算速度。具体的基于软硬件协同加速处理的关系网络推理计算流程如图1所示。
[0065]
基于关系网络的c
‑
way k
‑
shot分类推理任务采用x86/gpu平台与fpga平台协同计算的方式进行加速计算。x86/gpu平台用于支持集的特征提取,fpga 平台用于测试图像的特征提取以及支持集特征下的关系计算。支持集一般是由专家标注的标准数据集,其分类标签是固定的(图像数据,图像大小一致),支持集特征可以利用x86或者gpu平台提前计算出支持集特征构成支持集特征池 (已有的特征提取算法,关系网络中的特征提取算法),便于后续计算使用,同时节省计算时间与能耗。对于不同的c
‑
way k
‑
shot任务c图像类别,k每个图像类别的图像数量,可以构建不同的特征池,典型的构建1shot和k shot特征池,在omniglot数据集下k为1、5和20,在miniimagenet数据集下,k为1 和5。
[0066]
关系网络图像分类推理流程
[0067]
关系网络fpga推理计算流程采用离线支持集特征直接缓存到动态随机存取存储器(dynamic random access memory,dram)的方式节约支持集特征的计算时间与能耗,在片上配置特征提取模块和关系计算模块,根据计算速度的要求和片上资源的约束,构建不同大小的计算模块,多个计算模块配置成异构多核的方式协同加速,进一步提升推理计算能力。
[0068]
基于异构多核的片上处理系统设计
[0069]
关系网络fpga推理计算模块流程采用离线支持集特征直接缓存到动态随机存取存储器(dynamic random access memory,dram)的方式节约支持集特征的计算时间与能耗,在片上配置测试图像特征提取模块和关系计算模块,根据计算速度的要求和片上资源的约束,构建不同大小的计算模块,多个计算模块配置成异构多核的方式协同加速,进一步提升推理计算能力。具体的关系网络推理计算片上多核互联设计如图2所示,包括m个关系计算模块、n个测试图像特征提取模块、dram以及控制接口,各模块之间通过axi总线互联,图像数据以及模块控制指令通过控制接口传输给各个模块,输出结果通过控制模块输出。
[0070]
关系网络fpga推理计算模块设计
[0071]
关系网络的推理模块包括特征提取模块和关系计算模块,这两种计算模块均由基本的卷积块组成,卷积块包含一个3
×
3的卷积输出为64个神经元,经过batchnorm和relu,最终得到卷积块的输出。特征提取模块由4个卷积块和 2个最大池化计算组成,关系计算模
块由两个卷积块、2个最大池化计算以及2 个全连接计算组成。全连接1的维度为h
×
8,全连接2的维度为8
×
1,最终输出为关系分数。具体的关系网络推理计算模块结构如图3所示。
[0072]
基于hls循环优化的fpga卷积、池化全连接加速优化设计
[0073]
关系网络采用多个卷积块、最大池化层以及全连接层构成特征提取模块和关系计算模块。本部分采用基于hls的优化手段对卷积、池化、全连接的计算循环进行展开优化,增加计算模块的并行处理能力,从而提升计算模块的吞吐量。对于特征提取模块和关系计算模块的多层计算采用数据流的优化方式构成一个计算单元,简化计算模块的核外调度处理,使得输入为图像或者特征图,输出为特征图或者关系计算分数。
[0074]
(1)卷积块
[0075]
卷积块执行卷积乘累加计算,完成输入特征图与权重数据的卷积乘累加计算,卷积乘累加模块的计算输入为输入特征图,维度为ih
×
iw
×
ic,其中ih 为输入特征图高度,iw为输入特征图宽度,ic为输入特征图通道数;以及权重数据w,维度为oc
×
k^2
×
ic,其中oc为输出特征图通道数,k为卷积核大小。输出为输出特征图,维度为oh
×
ow
×
oc。
[0076]
卷积乘累加计算模块包含多个处理单元(process element,pe),每个神经元内部按照单指令多数据(single instruction multiple data,simd)进行并行计算设计。输入特征图调度为pe
×
simd宽度的数据,每个pe计算的输出为一个神经元的计算输出,pe内部采取simd个计算单元进一步提升并行数,simd相关的数据完成神经元内部的乘累加计算。卷积的权重调度为pe
×
simd宽度的数据,对应相应的输入。具体的卷积乘累加计算如算法1所示,具有5重循环,其中针对pe和simd展开两重循环,对应的并行数为pe
×
simd,每个卷积层可以根据计算量的大小以及前后层的计算输入输出速度进行单独的pe和simd 配置,在提升处理速度的同时尽可能的节约片上资源数量。
[0077]
[0078][0079]
卷积块采用如下流程:
[0080]
卷积块的输入特征图为in,设置卷积块的权重数据w;卷积块的输出特征图为out。
[0081]
卷积块的输入特征图in维度为ih
×
iw
×
ic,其中ih为卷积块的输入特征图高度,iw为卷积块的输入特征图宽度,ic为卷积块的输入特征图通道数;卷积块的权重数据w,维度为oc
×
k2×
ic,其中oc为卷积块的输出特征图通道数, k为卷积核大小;卷积块的输出为输出特征图out,维度为oh
×
ow
×
oc,其中oh为卷积块的输出特征图高度,ow为卷积块的输出特征图宽度。
[0082]
设定pe个处理单元,每个神经元内部按照单指令多数据simd个数据进行并行计算设计;输入特征图调度为pe
×
simd宽度的数据,每个pe计算的输出为一个神经元的计算输出,pe内部采取simd个计算输出。
[0083]
设定5重循环,只对最内层展开,循环从外层至最内层分别为卷积的第一重循环~卷积的第五循环:设定卷积的第一重循环变量为h,卷积的第二重循环变量w,卷积的第三重循环变量c,卷积的第四重循环变量pe,卷积的第五重循环变量为simd。
[0084]
h、w、c、pe以及simd的初值设定为0,每循环一次自加1,h的上限设定为 oh,w的上限设定为ow,c的上限设定为oc,pe的上限设定为pe,simd的上限设定为simd。
[0085]
其中卷积的第五重循环设定为
[0086]
out[w][h][c/pe pe] =in[pe][simd]
×
w[pe][simd]
[0087]
其中in[pe][simd]为卷积块的输入特征图in的第pe行第simd列参数; w[pe][simd]为卷积块的权重数据w的第pe行第simd列参数;out[w][h][c/pe pe] 为卷积块的输出特征图的三维分别为w、h、simd的参数; =符号表示符号左边在原有的基础上增加一个符号右边。
[0088]
(2)全连接计算层
[0089]
全连接计算层执行全连接乘累加计算,完成输入特征图以及权重数据的全连接计算,输出为输出特征图。全连接计算模块的输入特征图、输出特征图跟卷积计算模块保持一致,均为h
×
w
×
c的数据维度。全连接计算可以抽象为 k=1的卷积计算,具体的全连接乘累加计算算法如算法2所示,包含三重循环。该算法对pe循环和simd循环进行展开,设计为包含pe
×
simd并行度处理模块,每个pe计算一个全连接神经元的输出,神经元内部具有simd个乘累加单元并行计算。每个全连接层实例可以根据前后层的输入输出速度进行特定的pe、 simd配置,在满足处理的同时,节约片上资源消耗量。
[0090][0091]
全连接计算层具体采用如下流程:
[0092]
全连接计算层的输入特征图为in2,设置全连接计算层的权重数据w2;全连接计算层的输出特征图为out2。
[0093]
全连接计算层的输入特征图in2维度为ih2×
iw2×
ic2,其中ih2为全连接计算层的输入特征图高度,iw2为全连接计算层的输入特征图宽度,ic2为全连接计算层的输入特征图
通道数;全连接计算层的权重数据w2,维度为oc2×
k
22
×
ic2,其中oc2为全连接计算层的输出特征图通道数,k2为全连接计算层的卷积核大小;全连接计算层的输出为输出特征图out2,维度为oh2×
ow2×
oc2,其中 oh2为全连接计算层的输出特征图高度,ow2为全连接计算层的输出特征图宽度。
[0094]
该全连接计算层设定包含3重循环,从外层至内层分别为c循环、pe循环和simd循环,仅对pe循环和simd循环进行展开,设计为包含pe2×
simd2并行度处理模块,每个pe2计算一个全连接神经元的输出,神经元内部具有 simd2个乘累加单元并行计算。
[0095]
设定c循环的循环变量为c2,pe循环的循环变量为pe2,simd循环的循环变量为simd2。
[0096]
c2、pe2以及simd2的初值设定为0,每循环一次自加1,c2的上限设定为oc2, pe2的上限设定为pe2,simd2的上限设定为simd2。
[0097]
simd循环设定为:
[0098]
out2[c2/pe2 pe2] =in2[pe2][simd2]
×
w2[pe2][simd2]。
[0099]
其中out2[c2/pe2 pe2]为全连接计算层的输出特征图out2第c2/pe2 pe2个参数;in2[pe2][simd2]为全连接计算层的输入特征图in2的第pe2行和第simd2列的参数;w2[pe2][simd2]为全连接计算层的权重数据的第pe2行和第simd2列的参数; =符号表示符号左边在原有的基础上增加一个符号右边。
[0100]
(3)最大池化计算层
[0101]
最大池化计算层完成最大池化计算,针对输入特征图的池化计算功能,输入输出特征图与卷积层、全连接层保持一致,偏于多层网络组合为数据流调度的计算单元。最大池化计算算法如算法3所示,包含6重循环,只对最内层循环展开,展开数为pe,即并行度为pe,每个池化层根据计算需要单独配置。其中pool_size为池化大小,max为选取最大值。输入特征图in的数据经过输入调度满足伪代码6重循环的计算要求。
[0102]
[0103][0104]
即最大池化计算层具体采用如下流程:
[0105]
池化的输入特征图为in1,设置权重数据w1;输出特征图为out1。
[0106]
池化的输入特征图in1维度为ih1×
iw1×
ic1,其中ih1为池化的输入特征图高度,iw1为池化的输入特征图宽度,ic1为池化的输入特征图通道数;池化的权重数据w1,维度为oc1×
k
12
×
ic1,其中oc1为池化的输出特征图通道数,k1为池化核的大小;池化输出为输出特征图out1,维度为oh1×
ow1×
oc1,其中 oh1为池化的输出特征图高度,ow1为池化输出特征图宽度。
[0107]
设置pool_size为最大池化计算层的的池化大小,max为选取最大值。
[0108]
设定6重循环,只对最内层循环展开,展开式为pe1,循环从外层至最内层分别为池化的第一重循环~池化的第五循环:设定池化的第一重循环变量为h1,池化的第二重循环变量ph,池化的第三重循环变量w1,池化的第四重循环变量 pw,池化的第五重循环变量为c1以及池化的第六重循环变量pe1。
[0109]
h1、ph、w1、pw、c1以及pe1的初值设定为0,每循环一次自加1,h1的上限设定为oh1,ph的上限设定为pool_size,w1的上限设定为ow1,pw的上限设定为pool_size,c1的上限设定为oc1,pe1的上限设定为pe1。
[0110]
其中池化的第六重循环设定为
[0111]
out1[w1][h1][c1/pe1 pe1]=max(in1[pe1],out1[w1][h1][c1/pe1 pe1])
[0112]
其中out1[w1][h1][c/pe1 pe1]表示池化的输出特征图中三维分别为 [w1][h1][c/pe1 pe1]的参数,out1矩阵中初始存负无穷;max()表示取括号中数值的最大值;in1[pe1]表示池化特征图中第pe1行。
[0113]
针对omniglot和miniimagenet两个不同大小的数据集构建关系网络推理任务,其输入图像维度分别为28
×
28
×
1和84
×
84
×
3,全连接中的h分别为64 和576。由于两个数据集输入大小以及内部配置的差异,导致具体的各个模块计算量也不同,因此针对omniglot数据集和miniimagenet数据集分别设计不同的加速器进行推理加速。
[0114]
实施例1:omniglot28关系网络推理设计
[0115]
omniglot28片上多核设计如图4所示,包含控制接口、axi(advanced extensible interface)互联、dram以及计算模块。计算模块包括特征提取模块以及4个关系计算模块。控制接口完成主机的控制指令传输、数据传输功能,对具体的关系计算和特征提取模块进行控制。多个计算模块共享使用一个dram 的4g内存空间,多个计算模块可以同时并行运行,利用多核能力提供更高的运算吞吐量。
[0116]
omniglot28加速器配置如表1所示,为了描述简便,将特征提取模块和关系计算模块的pe、simd配置放在一个表格进行描述。特征提取模块包括cnv1 至cnv4部分,关系计算模块包括cnv5至fc2部分。通过设置pe和simd的大小可以控制每个模块的并行粒度,进而控制其吞吐量,但是受限于浮点数据的 32位宽度和pe、simd带来的大线宽、大规模计算矩阵导致其在vivado综合时,时序难以收敛,故采用多核的方式进一步利用资源提升吞吐量。omniglot28加速器的特征提取模块设计速度为2198.39fps,关系计算模块设计速度为7430.56 fps。
[0117]
表1 omniglot28加速器配置
[0118][0119]
实施例2:miniimagenet84关系网络推理设计
[0120]
miniimagenet84片上多核互联设计如图5所示,包含一个特征提取模块和两个关系计算模块构成的异构多核加速片上系统。
[0121]
miniimagenet84加速器配置如表2所示,为了描述简便,将特征提取模块和关系计算模块的pe、simd配置放在一个表格进行描述。特征提取模块包括cnv1 至cnv4部分,关系计算模块包括cnv5至fc2部分。通过设置pe和simd的大小可以控制每个模块的并行粒度,进而控制其吞吐量。miniimagenet84加速器的特征提取模块设计速度为221.02 fps,关系计算模块设计速度为642.78 fps。
[0122]
表2 miniimagenet84加速器配置
[0123][0124]
综上,以上仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。