1.本文的示例指的是用于在成像空间中定位物体元素的技术(方法、系统等)。
2.例如,一些技术涉及用于(例如,半自动)深度图估计的可接受深度区间的计算,例如,基于3d几何图元(primitive)。
3.示例可以与在多相机系统中获得的2d图像有关。
背景技术:
4.具有来自场景的多个图像允许计算图像的每个像素的深度或视差值。遗憾的是,自动深度估计算法容易出错并且不能提供无错误的深度图。
5.为了纠正这些错误,文献提出了基于网格的深度图精细化,因为网格的距离是可接受深度值的近似值。然而,到目前为止,还没有明确的描述如何计算可接受的深度区间。而且,没有考虑到网格仅部分表示场景,需要特定的方法来避免错误的深度图约束。
6.本示例尤其提出了用于实现该目的的方法。例如,本技术进一步描述了从网格的给定3d几何形状计算一组可接受深度区间(或更一般地,计算候选空间位置的范围或区间)的方法。这样一组深度区间(或候选空间位置的范围或区间)可以消除对应检测问题的歧义,从而提高整体所得深度图质量。此外,本技术进一步示出如何通过所谓的包含体积来补偿3d几何形状中的不准确度以避免错误的网格约束。此外,包含体积也可用于处理遮挡物以防止错误的深度值。
7.通常,示例涉及一种用于在包含至少一个确定物体的空间(例如,3d空间)中定位物体元素(例如,在2d图像中成像的物体的表面部分)的方法,该物体元素与空间的确定2d图像中的特定2d表示元素(例如,像素)相关联。因此可以获得物体元素的深度。
8.在示例中,成像空间可以包含多于一个物体,例如第一物体和第二物体,并且可以请求确定像素(或更一般地,2d表示元素)将与第一成像物体相关联还是与第二成像物体相关联。还可以获得空间中物体元素的深度:每个物体元素的深度将与同一物体的相邻元素的深度相似。
9.上文和下文的示例可以基于多相机系统(例如,立体系统或光场相机阵列,例如用于虚拟电影制作、虚拟现实等),其中每个不同的相机从不同角度获取相同空间(具有相同物体)的相应2d图像(更一般地说,基于预定义的位置和/或几何关系)。通过依赖于已知的预定义位置和/或几何关系,可以定位每个像素(或更一般地定位每个2d表示元素)。例如,可以使用外极几何。
10.还可以重建放置在成像空间内的一个或多个物体的形状,例如,通过定位多个像素(或更一般地定位2d表示元素),以构建完整的深度图。
11.一般而言,处理单元为执行这些方法而浪费的处理能力是不可忽略的。因此,通常要求减少所需的计算工作量。
附图说明
12.本文讨论了以下附图:
13.图1涉及定位技术,尤其涉及深度的定义。
14.图2图示了对现有技术和本示例均有效的外极几何形状。
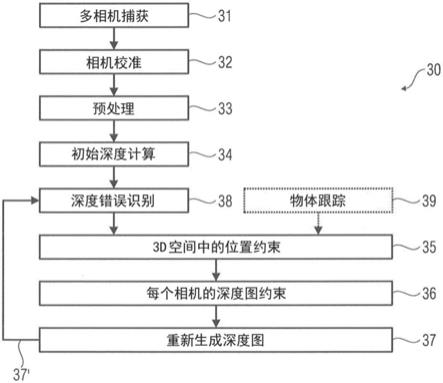
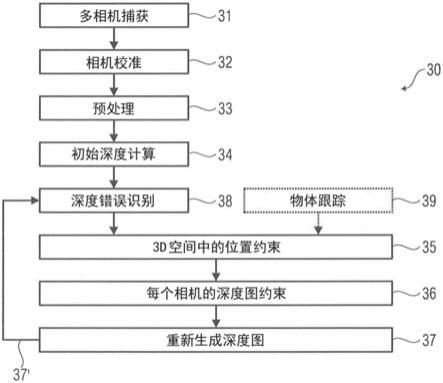
15.图3示出了根据示例的方法(交互式深度图改进的工作流程)。
16.图4至图6图示了技术中的挑战,具体是:
17.图4图示了使用近似表面来近似物体的技术。
18.图5图示了由于对近似表面进行近似而引起的竞争约束;
19.图6图示了为确定可接受的深度区间而遮挡物体的挑战。
20.图7至图38示出了根据本示例的技术,具体是:
21.图7示出了由近似表面引起的可接受的位置和深度值;
22.图8示出了由包含体积引起的可接受的位置和深度值;
23.图9图示了使用包含体积来限制近似表面所允许的可接受深度值;
24.图10图示了处理遮挡物体的构思;
25.图11图示了解决竞争约束的构思;
26.图12和图12a示出了平面近似表面及其与封闭体积近似表面的比较;
27.图13示出了与多个包含体积和一个近似表面相交的可接受的候选位置(射线)的受限范围的示例;
28.图14示出了用于通过容差值推导可接受的深度范围的示例;
29.图15图示了用于计算相似性度量的两个2d图像之间的匹配成本的聚合;
30.图16示出了倾斜平面的实施方式;
31.图17示出了相机坐标系中3d点(x,y,z)与对应像素的关系图;
32.图18示出了通过缩放与缩放中心相关的近似表面来生成包含体积的示例;
33.图19图示了从平面近似表面创建包含体积;
34.图20示出了三角形结构表示的近似表面的示例;
35.图21示出了初始近似表面的示例,其中所有三角形元素已在3d空间中沿其法向量移动;
36.图22示出了重新连接的网格元素的示例;
37.图23示出了复制控制点的技术;
38.图24图示了复制控制点的重新连接,使得源自相同初始控制点的所有控制点都通过网格直接连接;
39.图25示出了原始三角形元素与另一三角形元素相交;
40.图26示出了分解为三个新的子三角形结构的三角形结构;
41.图27示出了排除体积的示例;
42.图28示出了封闭体积的示例;
43.图29示出了排除体积的示例;
44.图30示出了平面排除体积的示例;
45.图31示出了基于图像的渲染或显示的示例;
46.图32示出了确定导致视图渲染(或显示)伪影的像素的示例;
47.图33示出了外极线编辑模式的示例;
48.图34图示了自由外极线编辑模式的原理;
49.图35示出了根据示例的方法;
50.图36示出了根据示例的系统;
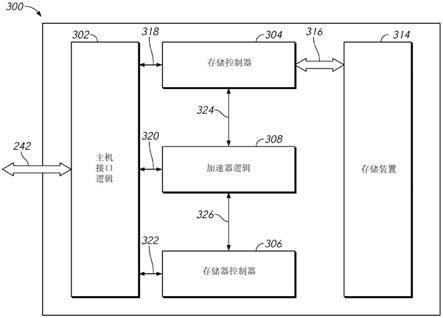
51.图37示出了根据示例的实现(例如,用于利用多相机一致性);
52.图38示出了根据示例的系统;
53.图39示出了根据示例的程序;
54.图40示出了可以避免的程序;
55.图41和图42示出了示例;
56.图43至图47示出了根据示例的方法;
57.图48示出了一个示例。
具体实施方式
58.3.背景
59.数字相机捕获的2d照片可忠实再现场景(例如,空间中的一个或多个物体)。遗憾的是,这种再现仅对单一视点有效。这对于高级应用来说太有限了,例如虚拟电影制作或虚拟现实。相反,后者需要从捕获的材料中生成新颖的视图。
60.以不同的方式可以创建这种新颖的视图。最直接的方法是从捕获的数据创建网格或点云[12][13]。备选地,可以应用基于深度图像的渲染或显示。
[0061]
在这两种情况下,需要针对捕获的场景计算每个视点的深度图。视点对应于已捕获场景的一个相机位置。深度图为所考虑的捕获图像的每个像素分配一深度值。
[0062]
如图1所示,深度值12是物体元素距离13在相机1的光轴15上的投影。物体元素14应被理解为由2d表示元素表示的(理想情况下为0维的)元素(它可能是一个像素,即使它在理想情况下是0维的)。物体元素14可以是固体、不透明物体的表面元素(当然,在透明物体的情况下,物体元素可以根据光学定律被透明物体折射)。
[0063]
为了获得每个像素(或更一般地,每个2d表示元素)的深度值12,存在不同的方法:
[0064]
·
使用有源深度感测设备,例如结构化照明或lidar
[0065]
·
从同一场景的多幅图像计算深度
[0066]
·
两者的结合
[0067]
尽管所有这些方法都有其优点,但从多个图像计算深度的优势在于其低成本、短捕获时间和高分辨率深度图。遗憾的是,它并非没有错误。如果在前面提到的应用之一中直接使用这种错误的深度图,则新颖视图的合成将导致伪影。
[0068]
因此,有必要设计可以以直观且快速的方式校正深度图中的伪影的方法。
[0069]
4.技术领域遇到的问题
[0070]
在以下几个示例中,我们可能会考虑从多个相机位置(具体地,在不同相机之间的已知位置/几何关系下)拍摄(或捕获或获取或成像)的场景的情境。相机本身可以是照片相机、视频相机或其他类型的相机(lidar、红外线等)。
[0071]
此外,单个相机可以移动到多个地方,或可以同时使用多个相机。在第一种情况下,可以捕获静态场景(例如,具有不可移动的物体),而在后一种情况下,还支持获取移动
的物体。
[0072]
可以以任意方式(但在示例中,以彼此已知的位置关系)布置相机。在简单的情况下,两个相机可以彼此相邻布置,具有平行的光轴。在更高级的场景中,相机位置位于规则的2d网格上,并且所有光轴都平行。在最一般的情况下,已知的相机位置在空间中任意定位,并且已知的光轴可以以任何方向定向。
[0073]
拥有来自场景的多个图像,我们可以针对每个2d图像中的每个像素(或更一般的2d表示元素)推导深度值(或更一般地定位每个像素)。
[0074]
为此,我们主要可以区分两种方法,即深度值的手动分配、自动计算和半自动方法。手动分配是一种极端,其中照片被手动转换为3d网格[10]、[15]、[16]。然后可以通过渲染或显示所谓的深度或z通道[14]来计算深度图。虽然这种方法允许完全的用户控制,但要获得精确的逐像素深度图非常麻烦。
[0075]
另一个极端是全自动算法[12][13]。虽然它们有可能计算每个像素的精确深度值,但它们本质上容易出错。换句话说,对于某些像素,计算出的深度值完全是错误的。
[0076]
因此,这些方法都不完全令人满意。需要将自动深度图计算的精度与手动方法的灵活性和控制相结合的方法。此外,所需的方法必须尽可能依赖现有的2d和3d图像处理软件工具。这允许从本领域中已经可用的非常强大的编辑工具中获利,而无需从头开始重新创建所有内容。
[0077]
为此,参考文献[8]指出了使用3d网格精细化深度值的可能性。虽然他们的方法使用针对先前帧或在先前帧内创建的网格,但可以推断,除了使用来自先前帧的网格之外,还可以使用针对当前帧创建的3d网格。然后,参考文献[8]主张通过基于3d网格可用的深度信息限制立体匹配范围来纠正可能的深度图错误。
[0078]
虽然这种方法因此使我们能够使用现有的3d编辑软件进行深度图的交互校正和改进,但它的直接应用是不可能的。首先,由于我们的网格将以手动方式创建,我们需要防止用户必须重新建模整个场景以修复位于图像的精确子部分中的深度图错误。为此,我们将需要特定的网格类型,如第9节所述。其次,参考文献[8]没有解释如何精确限制底层深度估计算法的搜索范围。因此,我们将提出一种如何将3d网格转换为可接受的深度范围的精确方法。
[0079]
5.使用相似度度量的方法
[0080]
从场景的多个图像进行深度计算本质上需要在图像内建立对应关系。然后,这种对应关系允许通过三角测量来计算物体的深度。
[0081]
图2以两个相机(左2d图像22和右2d图像23)的形式描绘了对应示例,其光学中心(或入瞳或节点)分别位于o
l
和o
r
。它们都拍摄物体元素x(例如,图1的物体元素14)的照片。该物体元素x在左相机图像22中的像素x
l
中描绘。
[0082]
遗憾的是,仅从左图像22不可能确定(或以其他方式定位)物体元素x的深度。事实上,所有物体元素x、x1、x2、x3将导致相同的像素(或其他2d表示元素)x
l
。所有这些物体元素都位于右侧相机中的一条线上,即所谓的外极线21。因此,在左视图22和右视图23中识别相同的物体元素允许计算相应的像素的深度。更一般地,通过在右视图23中识别在左2d图像22中的与2d表示元素x
l
相关联的物体元素x,可以定位物体元素x。
[0083]
为了识别这种对应关系,存在大量不同的技术。通常,这些不同的技术有一个共同
点,即它们针对每个可能的对应关系计算一些匹配成本或相似性度量。换句话说,右视图23中外极线21上的每个像素或2d表示元素(以及可能的其相邻像素或2d表示元素)与左视图22中的参考像素x
l
(以及其可能的相邻像素)进行比较。例如,可以通过计算绝对差异的总和[11]或census变换的汉明距离[11]来进行比较。然后将剩余的差异(在示例中)视为匹配成本或相似性度量,成本越大表示匹配越差。因此,深度估计回到了针对每个像素选择深度候选者,以便最小化匹配成本。这种最小化可以针对每个像素独立执行,或可以通过对整个图像执行全局优化来执行。
[0084]
遗憾的是,从这个描述中可以理解,对应关系的确定是一个难以解决的问题。可能有几个相似的物体位于图2所示右视图的外极线上。因此,可能会选择错误的对应关系,导致错误的深度值,从而导致虚拟视图合成中的伪影。仅举个示例,如果基于相似性度量错误地推断左图像视图22的参考像素x
l
对应于物体元素x2的位置,则物体元素x将因此在空间中错误地定位。
[0085]
为了减少这种深度错误,用户必须有可能操纵深度值。一种方法是所谓的2d到3d转换。在这种情况下,用户可以通过工具辅助的方式将深度值分配给不同的像素[1][2][3][4]。然而,这种深度图在多个捕获的视图之间通常不一致,因此不能应用于虚拟视图合成,因为后者需要一组捕获的输入图像和一致的深度图以获得高质量的无遮挡结果。
[0086]
另一类方法包括后滤波操作[5]。在这种情况下,用户在深度图中标记错误区域,并结合一些附加信息,例如像素属于前景区域还是背景区域。基于此信息,然后通过一些滤波消除深度错误。虽然这种方法是直接的,但它示出了几个缺点。首先,它直接在2d空间中操作,使得每个图像的每个深度图都需要单独校正,工作量很大。其次,校正仅是间接的滤波形式,使得无法保证深度图校正成功。
[0087]
因此,第三类方法避免了滤波错误的深度图,而是旨在直接改进初始深度图。这样做的一种方法是在像素级别上简单地限制可接受的深度值。因此,不是在图2中搜索整个外极线21以寻找对应关系,而是仅考虑较小的部分。这限制了混淆对应关系的可能性,从而导致改进的深度图。
[0088]
[8]遵循这样的概念。它假设时间视频序列,其中应该针对时间实例t计算深度图。此外,假设3d模型可用于时间实例t
‑
1。然后将该3d模型用作当前像素深度的近似值,从而减少搜索空间。由于3d模型与应改进深度图的帧属于不同的时间实例,因此他们需要通过执行姿势估计将3d模型与当前帧对齐。虽然这使应用复杂化,但可以理解,通过将姿态估计替换为简单返回3d模型而不是改变其姿态的函数,所述方法非常接近第4节中定义的挑战。遗憾的是,这样的概念丢失了使用手动创建的网格所必需的重要属性。添加这些方法以本示例为准。
[0089]
参考文献[6]明确介绍了一种用于手动用户交互的方法。他们的算法应用图切割算法来最小化全局匹配成本。这些匹配成本由两部分组成:数据成本部分,定义两个对应像素的颜色匹配程度,以及平滑度成本,惩罚具有相似颜色的相邻像素之间的深度跳跃。用户可以通过设置某些像素的深度值或通过请求某些像素的深度值与先前帧中的深度值相同来影响成本最小化。由于平滑成本,这些深度引导也将传播到相邻像素。此外,用户可以提供边缘图(edge map),使得平滑成本就不会应用于边缘。与这项工作相比,我们的方法是互补的。我们不描述如何精确校正特定深度图算法的深度图错误。相反,我们展示了如何从3d
空间中提供的用户输入推导出可接受的深度范围。然后可以在每个深度图估计算法中使用这些对于每个像素可能不同的可接受深度范围,以限制可能的深度候选并因此降低深度图错误的概率。
[0090]
参考文献[7]中介绍了一种改进深度图的替代方法。它允许用户定义不应包含深度跳跃的平滑区域。然后使用该信息来改进深度估计。与我们的方法相比,这种方法仅是间接的,因此不能保证是无错误的深度图。此外,在2d图像域中定义平滑度约束,这使得很难将该信息传播到所有捕获的相机视图中。
[0091]
6.贡献
[0092]
示例中呈现了至少一些贡献:
[0093]
·
我们提供了一种精确的方法,该方法可以针对图像的相关像素推导可接受的深度值范围。通过这些方式,可以使用仅近似描述3d物体的网格来生成高精度和高质量的深度图。换句话说,我们没有坚持3d网格准确地描述3d物体的位置,而是考虑到用户仅能提供粗略的估计。然后将该估计值转换为可接受深度值的区间。独立于应用的深度估计算法,这减少了用于对应确定的搜索空间,从而减少了错误深度值的概率(第10节)。
[0094]
·
如果仅请求用户提供近似的3d网格位置,则可能会错误地解释网格。我们提供了一种如何避免这种情况的方法(第9.3节)。
[0095]
·
所述方法支持场景的部分约束。换句话说,用户不需要针对场景的所有物体给出深度约束。相反,仅针对最困难的物体,才需要精确的深度引导。这明确包括一个物体被另一个物体遮挡的场景。这需要文献中未知的特定网格类型,因此可能是本示例的重要部分(第9节)。
[0096]
·
我们示出了从网格中已知的法向量如何通过考虑倾斜表面来进一步简化深度图估计。我们的贡献可以限制可接受的法向量,从而减少可能的匹配候选,这再次降低了错误匹配的概率,从而获得更高质量的深度图(第11节)。
[0097]
·
我们引入了另一种约束类型,称为排除体积,它明确禁止某些深度值。通过这些方式,我们可以进一步减少可能的深度候选,从而降低错误深度值的概率(第13节)。
[0098]
·
我们对如何基于单个或多个2d图像创建3d几何约束进行了一些改进(第15节)。
[0099]
根据一个方面,提供了一种用于在包含至少一个确定物体的空间中定位与该空间的确定2d图像中的与特定2d表示元素(x
l
)相关联的物体元素的方法,所述方法包括:
[0100]
基于预定义的位置关系推导成像物体元素的候选空间位置的范围或区间;
[0101]
将候选空间位置的范围或区间限制为可接受的候选空间位置的至少一个受限范围或区间,其中限制包括以下至少一项:
[0102]
使用围绕至少一个确定物体的至少一个包含体积来限制候选空间位置的范围或区间;以及
[0103]
使用围绕不可接受的候选空间位置的至少一个排除体积来限制候选空间位置的范围或区间;以及
[0104]
基于相似性度量,在受限范围或区间的可接受的候选空间位置中检索最合适的候选空间位置。
[0105]
在根据示例的方法中,空间可以包含至少一个第一确定物体和一个第二确定物体,
[0106]
其中限制包括将候选空间位置的范围或区间限制为:
[0107]
与第一确定物体相关联的可接受的候选空间位置的至少一个第一受限范围或区间;以及
[0108]
与第二确定物体相关联的可接受的候选空间位置的至少一个第二受限范围或区间,
[0109]
其中限制包括将至少一个包含体积定义为围绕第一确定物体的第一包含体积和/或围绕第二确定物体的第二包含体积,以将候选空间位置的至少一个第一和/或第二范围或区间限制为可接受的候选空间位置的至少一个第一和/或第二受限的范围或区间;以及
[0110]
其中检索包括确定特定2d表示元素与第一确定物体相关联还是与第二确定物体相关联。
[0111]
根据一个示例,基于相似性度量来执行确定特定2d表示元素是与第一确定物体相关联还是与第二确定物体相关联。
[0112]
根据一个示例,基于以下观察来确定特定2d表示元素是与第一确定物体相关联还是与第二确定物体相关联:
[0113]
可接受的候选空间位置的至少一个第一和第二受限范围或区间中的一个为空;以及
[0114]
可接受的候选空间位置的至少一个第一和第二受限范围或区间中的另一个不为空,从而确定特定2d表示元素在可接受的候选空间位置的至少一个第一和第二受限范围或区间中的另一个内。
[0115]
根据一个示例,限制包括使用来自第二相机或2d图像的信息来确定特定2d表示元素是与第一确定物体相关联还是与第二确定物体相关联。
[0116]
根据一个示例,来自第二相机或2d图像的信息包括物体元素的包含在以下项中的先前获得的定位:
[0117]
可接受的候选空间位置的至少一个第一受限范围或区间,以便推断物体元素与第一物体相关联;或者
[0118]
可接受的候选空间位置的至少一个第二受限范围或区间,以便推断物体元素与第二物体相关联。
[0119]
根据一个方面,提供了一种方法,包括:
[0120]
作为第一操作,获取与第二相机位置相关联的位置参数和至少一个包含体积;
[0121]
作为第二操作,针对在第一相机位置获得的第一2d图像的特定2d表示元素执行根据上文和下文中的任何方法的方法,所述方法包括:
[0122]
基于在第一次操作获取的位置参数来分析是否满足以下两个条件:
[0123]
至少一个候选空间位置将遮挡在第二相机位置处获得或能够获得的第二2d图像中的至少一个包含体积,以及
[0124]
至少一个候选空间位置不被第二2d图像中的至少一个包含体积遮挡,
[0125]
因此,如果满足两个条件:
[0126]
抑制执行检索,即使至少一个候选空间位置在第一2d图像的可接受的候选空间位置的受限范围内;和/或
[0127]
从针对第一2d图像的可接受的候选空间位置的受限范围或区间中排除至少一个
候选空间位置,即使至少一个候选空间位置在可接受的候选空间位置的受限范围内。
[0128]
根据一个示例,所述方法可以包括:
[0129]
作为第一操作,获得与第二相机位置相关联的位置参数和至少一个包含体积;
[0130]
作为第二操作,对在第一相机位置处获取的第一2d图像的特定2d表示元素执行根据上文和下文中的任何方法的方法,所述方法包括:
[0131]
基于在第一操作获得的位置参数,分析受限范围的至少一个可接受的候选空间位置是否会被在第二相机位置处获得或能够获得的第二2d图像中的至少一个包含体积遮挡,以便将该可接受的候选空间位置保持在受限范围内。
[0132]
根据一个示例,所述方法可以包括:
[0133]
作为第一操作,针对第二2d图像定位多个2d表示元素,
[0134]
作为第二后续操作,根据上文和下文中的任何方法执行所述方法的推导、限制和检索,用于针对第一确定2d图像的确定2d表示元素确定最合适的候选空间位置,其中第二2d图像和第一确定2d图像是在具有预定位置关系的空间位置处获取的,
[0135]
其中第二操作还包括在先前在第一操作中处理的第二2d图像中寻找与第一确定2d图像的第一确定2d表示元素的候选空间位置相对应的2d表示元素,
[0136]
以便在第二操作中进一步限制可接受的候选空间位置的范围或区间和/或获得关于第一确定2d表示元素的相似性度量。
[0137]
根据一个示例,其中第二操作使得,在观察到先前获得的第二2d图像中的2d表示元素的定位位置将被第二操作中考虑的第一确定2d表示元素的候选空间位置相对于第二2d图像遮挡时:
[0138]
进一步限制可接受的候选空间位置的受限范围或区间,以便从可接受的候选空间位置的受限范围或区间中排除第一确定2d图像的确定2d表示元素的候选空间位置。
[0139]
根据一个示例,在观察到第二2d图像中的2d表示元素的定位位置与第一确定2d表示元素相对应时:
[0140]
针对第一确定2d图像的确定2d表示元素,限制可接受的候选空间位置的范围或区间,以便从可接受的候选空间位置的受限范围或区间中排除比定位位置更远的位置。
[0141]
根据一个示例,一种方法还可以包括,在观察到第二2d图像中的2d表示元素的定位位置与第一确定2d表示元素的定位位置不相对应时:
[0142]
使在第二操作中获得的第一确定2d图像的确定2d表示元素的最合适的候选空间位置无效。
[0143]
根据一个示例,当第二2d图像中的2d表示元素的定位位置到第一确定2d表示元素的候选空间位置之一的距离在最大预定容差距离内时,定位位置对应于第一确定2d表示元素。
[0144]
根据一个示例,所述方法还可以包括,当在第二2d图像中找到2d表示元素时,分析第二2d图像中的第一2d表示元素的定位的置信度值或可靠性值,并且仅在置信度值或可靠性值高于预定置信度阈值或不可靠性值低于预定阈值的情况下使用它。
[0145]
根据一个示例,置信度值可以至少部分地基于定位位置和相机位置之间的距离,并且置信度值随距离越近而增加。
[0146]
根据一个示例,置信度值至少部分地基于物体或包含体积或可接受的空间位置的
受限范围的数量,以便如果在可接受的空间候选位置的范围或区间中发现较少数量的物体或包含体积或可接受的空间位置的受限范围,则增加置信度值。
[0147]
根据一个示例,限制包括定义至少一个近似表面,以便将候选空间位置的至少一个范围或区间限制为可接受的候选空间位置的至少一个受限范围或区间。
[0148]
根据一个示例,定义包括定义至少一个近似表面和一个容差区间,以便将候选空间位置的至少一个范围或区间限制为由容差区间定义的候选空间位置的受限范围或区间,其中容差区间具有:
[0149]
由至少一个近似表面定义的远端;以及
[0150]
基于容差区间定义的近端;以及
[0151]
基于相似性度量,在受限范围或区间的可接受的候选空间位置中检索最合适的候选空间位置。
[0152]
根据一个示例,一种方法可以包括用于在包含至少一个确定物体的空间中定位与该空间的2d图像中的特定2d表示元素相关联的物体元素,所述方法包括:
[0153]
基于预定义的位置关系推导成像物体元素的候选空间位置的范围或区间;
[0154]
将候选空间位置的范围或区间限制为可接受的候选空间位置的至少一个受限范围或区间,其中限制包括:
[0155]
定义至少一个近似表面和一个容差区间,以便将候选空间位置的至少一个范围或区间限制为由容差区间定义的候选空间位置的受限范围或区间,其中容差区间具有:
[0156]
由至少一个近似表面定义的远端;以及
[0157]
基于容差区间定义的近端;以及
[0158]
基于相似性度量,在受限范围或区间的可接受的候选空间位置中检索最合适的候选空间位置。
[0159]
根据一个示例,可以通过使用增加的容差区间来迭代所述方法,以便增加包含物体元素的概率。
[0160]
根据一个示例,可以通过使用减小的容差区间来迭代所述方法,以便降低包含不同物体元素的概率。
[0161]
根据一个示例,其中限制包括定义用于定义容差区间的容差值。
[0162]
根据一个示例,其中限制包括基于定义从至少一个近似表面获得的容差区间值δd,其中是近似表面在候选空间位置的区间与近似表面相交的点处的法向量,并且向量定义确定的相机或2d图像的光轴。
[0163]
根据一个示例,基于以下公式根据至少一个近似表面来定义容差区间值δd的至少一部分:
[0164]
或
[0165][0166]
其中t0是预定的容差值,其中是近似表面在候选空间位置的区间与近似表面相
交的点处的法向量,其中向量定义所考虑的相机的光轴,并且φ
max
限幅和之间的角度。
[0167]
根据一个示例,检索包括:
[0168]
考虑近似表面在近似表面与候选空间位置的范围或区间之间的交点处的法向量
[0169]
基于相似性度量,在受限范围或区间的可接受的候选空间位置中检索最合适的候选空间位置,其中检索包括基于涉及法向量的相似性度量,在受限范围或区间的可接受的候选空间位置中并基于法向量来检索最合适的候选空间位置。
[0170]
根据一个方面,提供了一种用于在包含至少一个确定物体的空间中定位与该空间的确定2d图像中的特定2d表示元素相关联的物体元素的方法,所述方法包括:
[0171]
基于预定义的位置关系推导成像物体元素的候选空间位置的范围或区间;
[0172]
将候选空间位置的范围或区间限制为可接受的候选空间位置的至少一个受限范围或区间,其中限制包括定义至少一个近似表面,以便将候选空间位置的至少一个范围或区间限制为候选空间位置的受限范围或区间;
[0173]
考虑近似表面在近似表面与候选空间位置的范围或区间之间的交点处的法向量
[0174]
基于相似性度量,在受限范围或区间的可接受的候选空间位置中检索最合适的候选空间位置,其中检索包括基于涉及法向量的相似性度量,在受限范围或区间的可接受的候选空间位置中并基于法向量来检索最合适的候选空间位置。
[0175]
根据示例:
[0176]
检索包括处理针对特定2d表示元素((x0,y0),x
l
)的至少一个候选空间位置(d)的相似性度量(c
sum
),
[0177]
其中处理涉及特定2d表示元素(x0,y0)的特定邻域(n(x0,y0))内的其他2d表示元素(x,y),
[0178]
其中处理包括针对其他2d表示元素(x,y)中的每一个,在假设物体在物体元素中的平面表面的情况下,在根据向量定义的预定范围内的多个向量中获得向量以推导出与向量相关联的候选空间位置(d),其中候选空间位置(d)用于确定邻域(n(x0,y0))中每个2d表示元素(x,y)对相似性度量(c
sum
)的贡献。
[0179]
根据一个示例,检索基于以下关系:
[0180][0181]
其中(x0,y0)是特定的2d表示元素,(x,y)是(x0,y0)的邻域中的元素,k是内参相机
矩阵,d是表示候选空间位置的深度候选,是在假设物体在物体元素中的平面表面的情况下,基于特定2d表示元素(x0,y0)的深度候选d来计算特定2d表示元素(x,y)的深度候选的函数。
[0182]
根据一个示例,检索基于评估类型的相似性度量c
sum
(d)
[0183][0184]
其中表示总和或者一般聚合函数。
[0185]
根据一个示例,限制包括在相对于法向量的最大倾斜角内的可接受向量的范围或区间当中,获得在至少一个确定物体与候选空间位置的范围或区间的交点(143)处垂直于至少一个确定物体的向量
[0186]
根据一个示例,限制包括使用根据下式获得垂直于至少一个确定物体的向量
[0187][0188]
其中θ是关于法向量的倾斜角,θ
max
是预定义的最大倾斜角,φ是方位角,并且其中是相对于第三轴(z)平行于并且另外两个轴(x,y)与正交的正交坐标系进行解释的。
[0189]
根据一个示例,限制包括使用来自2d图像的信息来确定特定的2d表示元素是与第一确定物体相关联还是与第二确定物体相关联,
[0190]
还包括找到:
[0191]
在与第一确定2d图像的候选空间位置的范围或区间的交点处与至少一个确定物体垂直的第一向量,以及
[0192]
在与第二2d图像的候选空间位置的范围或区间的交点处垂直于至少一个确定物体的第二向量,以及
[0193]
比较第一向量和第二向量,以便:
[0194]
如果第一向量和第二向量之间的角度在预定阈值内,则使定位有效,和/或
[0195]
如果第一向量和第二向量之间的角度在预定阈值内,则使定位无效,或者根据置信度值选择第一图像或第二图像的定位。
[0196]
根据一个示例,其中仅当近似表面与候选空间位置的范围或区间之间的交点处的近似表面的法向量具有特定方向范围内的预定方向时应用限制。
[0197]
根据本示例的一个方面,提供了一种方法,基于与确定2d图像相关的候选空间位置的范围或区间的方向来计算特定方向范围。
[0198]
根据本示例的一个方面,提供了一种方法,仅当近似表面与候选空间位置的范围或区间之间的交点处的近似表面的法向量与描述候选空间位置的自相机起的路径的向量之间的点积具有预定义的符号时应用限制。
[0199]
根据一个示例,限制包括定义可接受的候选空间位置的至少一个受限范围或区间
的至少一个近似表面定义的末端,其中至少一个近似表面定义的末端位于近似表面和候选空间位置的范围或区间之间的相交处。
[0200]
根据一个示例,近似表面由用户定义。
[0201]
根据一个示例,限制包括沿着候选位置的范围从近侧位置向远侧位置扫描,并且在观察到可接受的候选空间位置的所述至少一个受限范围或区间具有与近似表面相关联的远端时结束。.
[0202]
根据一个示例,根据至少一个近似表面自动定义至少一个包含体积。
[0203]
根据一个示例,通过缩放至少一个近似表面根据至少一个近似表面定义至少一个包含体积。
[0204]
根据一个示例,通过从至少一个近似表面的缩放中心缩放至少一个近似表面,根据至少一个近似表面定义至少一个包含体积。
[0205]
根据一个示例,限制涉及由顶点或控制点、边和表面元素组成的结构形成的至少一个包含体积或近似表面,其中每条边连接两个顶点,并且每个表面元素被至少三条边围绕,并且从每个顶点到结构的任何其他顶点都存在边的连接路径。
[0206]
根据一个方面,提供了一种方法,其中每条边连接到偶数个表面元素。
[0207]
根据一个方面,提供了一种方法,其中每条边连接到两个表面元素。
[0208]
根据一个方面,提供了一种方法,其中结构占据没有边界的封闭体积。
[0209]
根据一个示例,至少一个包含体积由几何结构形成,所述方法还包括通过以下方式定义至少一个包含体积:
[0210]
通过沿元素的法线分解元素来移动元素;以及
[0211]
通过生成附加元素(210bc,210cb)重新连接元素。
[0212]
根据一个方面,提供了一种方法,所述方法还包括:
[0213]
在分解区域内插入至少一个新的控制点;
[0214]
将至少一个新的控制点与分解的元素重新连接以形成更多的元素。
[0215]
根据一个示例,元素是三角形元素。
[0216]
根据一个示例,限制包括:
[0217]
在候选空间位置的范围或区间内从近侧位置到远侧位置搜索范围或区间,并且在检索到近似表面时结束搜索。
[0218]
根据一个示例,至少一个近似表面包含在至少一个物体内。
[0219]
根据一个示例,至少一个近似表面是至少一个物体的粗略近似。
[0220]
根据一个示例,所述方法还包括在观察到在推导期间获得的候选空间位置的范围或区间不与任何近似表面相交时,将可接受的候选空间位置的受限范围或区间定义为在推导期间获得的候选空间位置的范围或区间。
[0221]
根据一个示例,至少一个包含体积是至少一个物体的粗略近似。
[0222]
根据一个示例,检索被应用于可接受的候选位置和/或可接受的法向量的受限范围或区间中的随机子集。
[0223]
根据一个示例,限制包括定义可接受的候选空间位置的至少一个受限范围或区间的至少一个包含体积定义的末端。
[0224]
根据一个示例,包含体积由用户定义。
[0225]
根据一个示例,检索包括基于相似性度量确定特定2d表示元素是否与至少一个确定物体相关联。
[0226]
根据一个示例,2d表示元素中的至少一个是确定2d图像中的像素(x
l
)。
[0227]
根据一个示例,物体元素是至少一个确定物体的表面元素。
[0228]
根据一个示例,成像物体元素的候选空间位置的范围或区间在相对于确定2d表示元素的深度方向上展开。
[0229]
根据一个示例,成像物体元素的候选空间位置的范围或区间沿着相对于确定2d表示元素从相机的节点射出的射线展开。
[0230]
根据一个示例,检索包括沿着从空间的另一2d图像获得的并且与确定2d图像具有预定义的位置关系的受限范围或区间的可接受的候选空间位置测量相似性度量。
[0231]
根据一个方面,提供了一个方面,其中检索包括沿着另一2d图像中的形成与至少一个受限范围相关联的外极线的2d表示元素测量相似性度量。
[0232]
根据一个示例,限制包括找到包含体积、排除体积和/或近似表面中的至少一个与候选位置的范围或区间之间的交点。
[0233]
根据一个示例,限制包括使用包含体积、排除体积和/或近似表面中的至少一个来找到候选位置的受限范围或区间的末端。
[0234]
根据一个示例,限制包括:
[0235]
在候选空间位置的范围或区间内从近侧位置到远侧位置搜索范围或区间。
[0236]
根据一个示例,定义包括:
[0237]
选择空间的第一2d图像和空间的第二2d图像,其中第一2d图像和第二2d图像是在彼此具有预定位置关系的相机位置处获取的;
[0238]
至少显示第一2d图像,
[0239]
引导用户选择第一2d图像中的控制点,其中所选择的控制点是形成近似表面或排除体积或包含体积的结构的元素的控制点;
[0240]
引导用户在第一2d图像中选择性地平移所选择的点,同时限制点沿着第二2d图像中的与点相关联的外极线移动,其中点与点相同的结构的元素的控制点相对应,
[0241]
以便定义结构的元素在3d空间中的移动。
[0242]
根据一个方面,提供了一种用于在包含至少一个确定物体的空间中定位与该空间的确定2d图像中的特定2d表示元素相关联的物体元素的方法,所述方法包括:
[0243]
获得成像物体元素的空间位置;
[0244]
获得成像物体元素的该空间位置的可靠性值或不可靠性值;
[0245]
如果可靠度值不符合预定义的最小可靠度或不可靠度不符合预定义的最大不可靠度,则执行上文和下文的任何方法中的方法,以便精细化先前获得的空间位置。
[0246]
根据一个方面,提供了一种用于在包含至少一个确定物体的空间中精细化先前获得的与该空间的确定2d图像中的特定2d表示元素相关联的物体元素的定位的方法,所述方法包括:
[0247]
图形化显示空间的确定2d图像;
[0248]
引导用户定义至少一个包含体积和/或至少一个近似表面和/或至少一个近似表面;
[0249]
根据上文和下文中的任何方法的方法以精细化先前获得的定位。
[0250]
根据一个示例,一种方法还可包括,在定义至少一个包含体积或近似表面之后,在至少一个包含体积或近似表面与至少一个相机的位置之间自动定义排除体积。
[0251]
根据一个示例,一种方法还可以包括,在定义第一近侧包含体积或近似表面和第二远侧包含体积或近似表面时,自动定义:
[0252]
在第一包含体积或近似表面与至少一个相机的位置之间的第一排除体积;在第二包含体积或近似表面与至少一个相机的位置之间的第二排除体积,其中排除在第一排除体积和第二排除体积之间的非排除区域。
[0253]
根据一个示例,所述方法可以应用于多相机系统。
[0254]
根据一个示例,所述方法可以应用于立体成像系统。
[0255]
根据一个示例,检索包括针对范围或区间的每个候选空间位置选择候选空间位置是否将是可接受的候选空间位置的受限范围的一部分。
[0256]
根据一个方面,可以提供一种用于在包含至少一个确定物体的空间中定位与该空间的确定2d图像中的特定2d表示元素相关联的物体元素的系统,所述系统包括:
[0257]
推导块,用于基于预定义的位置关系推导成像物体元素的候选空间位置的范围或区间;
[0258]
限制块,用于将候选空间位置的范围或区间限制为可接受的候选空间位置的至少一个受限范围或区间,其中所述限制块被配置为:
[0259]
使用围绕至少一个确定物体的至少一个包含体积来限制候选空间位置的范围或区间;和/或
[0260]
使用包括不可接受的候选空间位置的至少一个排除体积来限制候选空间位置的范围或区间;以及
[0261]
检索块,被配置为根据相似性度量在受限范围或区间的可接受的候选空间位置中检索最合适的候选空间位置。
[0262]
根据一个方面,提供一种系统,还包括用于以预定位置关系获取2d图像的第一相机和第二相机。
[0263]
根据一个方面,提供一种系统,还包括至少一个可移动相机,用于从不同位置并以预定位置关系获取2d图像。
[0264]
根据上文或下文中的任一系统,所述系统还可以包括:约束定义器,用于渲染至少一个2d图像以获得用于定义至少一个约束的输入。
[0265]
根据上文或下文中的任一系统,所述系统还可以被配置为执行示例。
[0266]
根据一个方面,可以提供包括指令的非暂时性存储单元,所述指令在由处理器执行时使处理器执行以上或以上的方法。
[0267]
上文和下文中的示例可以指多相机系统。上文和下文中的示例可以涉及立体系统,例如,用于3d成像。
[0268]
上文和下文中的示例可以参考用真实相机拍摄真实空间的系统。在一些示例中,所有的2d图像都是通过真实相机拍摄真实物体获得的唯一真实图像。
[0269]
7.总体工作流程
[0270]
图3描绘了交互式深度图计算和改进(或更一般地用于至少一个物体元素的定位)
的总体方法30。可以在根据本公开的示例中实现以下步骤中的至少一个。
[0271]
第一步骤31可以包括使用多个相机的阵列、或者通过在场景内移动单个相机,从多个视角捕获(空间的)场景。
[0272]
第二步骤32可以是所谓的相机校准。基于对2d图像内的特征点和/或提供的校准图表的分析,校准算法可以针对每个相机视图确定内参参数和外参参数。外参相机参数可以定义所有相机相对于公共坐标系的位置和取向。后者在下文中称为世界坐标系。内参参数包括(优选为所有)相关的内部相机参数,例如焦距和光轴的像素坐标。在下文中,我们提到内参相机参数和外参相机参数为位置参数或位置关系。
[0273]
第三步骤33可以包括预处理步骤,例如以获得高质量的结果,但这与交互式深度图估计没有直接关系。这可以具体包括相机之间的颜色匹配以补偿变化的相机传输曲线、去噪和消除镜头失真。此外,在该步骤33中可以消除由于过度模糊或错误曝光而导致质量不足的图像。
[0274]
第四步骤34可以计算每个相机视图(2d图像)的初始深度图(或更一般地粗略定位)。这里,对于要使用的深度计算程序可以没有限制。该步骤34的目的可以是(自动或手动)识别困难的场景元素,其中自动程序需要用户帮助来递送正确的深度图。第14节讨论了识别这样的深度图错误的示例性方法。在一些示例中,以下讨论的几种技术可以通过改进在步骤34获得的粗略定位结果来操作。
[0275]
在步骤35(例如,第五步骤)中,有可能针对3d空间中的场景物体(例如,手动)生成位置约束。为了减少必要的用户努力,此类位置约束可以限于在步骤38中识别的相关物体,所述相关物体的来自步骤34(或37)的深度值不正确。例如,可以通过使用任何可能的3d建模和编辑软件将多边形或其他几何图元绘制到3d世界空间中来创建这些约束。例如,用户可以定义:
[0276]
‑
围绕物体的至少一个包含体积(inclusive volume)(因此,很有可能在其中定位物体元素);和/或
[0277]
‑
至少一个排除物体,不在所述至少一个排除物体中不搜索物体元素的位置;和/或
[0278]
‑
包含在至少一个确定物体内的至少一个近似表面。
[0279]
例如,这些约束可以是例如在自动系统的帮助下手动创建或绘制或选择的。例如,用户可以定义近似表面,所述方法进而返回包含体积(参见第12节)。
[0280]
用于创建位置约束的基础坐标系可以与用于相机校准和定位的坐标系相同。用户绘制的几何图元给出了物体所在位置的指示,而无需针对场景中的每个物体指示3d空间中的精确位置。在视频序列的情况下,几何图元的创建可以通过随着时间的推移自动跟踪它们而显著加快(39)。第13节给出了有关位置约束概念的更多详细信息。第15节更详细地描述了如何轻松绘制几何图元的示例技术。
[0281]
在步骤36(例如,第六步骤)中,位置约束(包含体积、排除体积、近似表面(surface approximation)、容差值
……
,可以由用户选择)可以转换成针对每个相机视图的深度图约束(或定位约束)。换句话说,候选空间位置(例如,与像素相关联)的范围或区间可以限制为可接受的候选空间位置的至少一个受限范围或区间。这种深度图约束(或位置约束)可以表示为视差图约束。因此,与交互式深度或视差图改进相关,深度图和视差图在概念上是相同
的,并且将被如此对待,尽管它们中的每一个都具有在实施过程中不应混淆的非常具体的含义。
[0282]
在步骤36中获得的约束可能限制可能的深度值(或定位估计),因此减少了要在步骤37处理的相似性度量分析的计算工作量。例如,在第10节中讨论了示例。备选地或附加地,可以限制所考虑物体的可能的表面法线方向(参见第11节)。这两种信息对于消除对应确定问题的歧义可能是有价值的,因此可用于重新生成深度图。与初始深度图计算相比,该程序可以在较小的一组值中搜索可能的深度值,并排除其他可行的解决方案。可以使用与初始深度图计算类似的程序(例如,步骤34的程序)。
[0283]
例如,可以使用依赖于相似性度量的技术来获得步骤37,例如在第5节中讨论的那些。这些方法中的至少一些是本领域已知的。然而,用于计算和/或比较这些相似性度量的程序可以利用在步骤35定义的约束的使用。
[0284]
如步骤37和38之间的迭代37'所识别的,所述方法可以被迭代,例如,通过在步骤37重新生成由步骤36获得的定位,以便在38识别定位错误,其随后可以在步骤35和36的新的迭代中精细化。每次迭代都可以精细化在先前迭代中获得的结果。
[0285]
还可以预见跟踪步骤39,例如,对于移动物体,考虑时间上的后续帧:考虑先前帧(例如,在时刻t
‑
1)获得的约束,以获取在后续帧(例如,在时刻t)处的2d表示元素(例如,像素)的定位。
[0286]
图35示出了用于在包含至少一个确定物体的空间中定位与该空间的确定的2d图像中的特定2d表示元素(例如,像素)相关联的物体元素的更通用方法350。所述方法可以包括:
[0287]
步骤351,基于预定义的位置关系针对成像的空间元素推导候选空间位置的范围或区间(例如,从相机射出的射线);
[0288]
步骤352(可以与方法30的步骤35和/或36相关联),将候选空间位置的范围或区间限制为可接受的候选空间位置的至少一个受限范围或区间(例如,射线中的一个或多个区间),其中限制包括以下至少一项:
[0289]
使用围绕至少一个确定物体的至少一个包含体积来限制候选空间位置的范围或区间;和/或
[0290]
使用包括不可接受的候选空间位置的至少一个排除体积来限制候选空间位置的范围或区间;和/或
[0291]
其他约束(例如近似表面、容差值等,例如具有下面讨论的特征);
[0292]
基于相似性度量在受限范围或区间的可接受的候选空间位置中检索(步骤353,其可以与方法30的步骤37相关联)最合适的候选空间位置。
[0293]
在一些情况下,可以迭代所述方法,以便精细化先前迭代中获得的粗略结果。
[0294]
即使上文和下文的技术主要是在方法步骤方面讨论的,应该理解的是,本示例还涉及一种系统,例如图36中所示的360,该系统被配置为执行诸如示例性方法之类的方法。
[0295]
系统360(可以处理方法30或350的步骤中的至少一个)可以在包含至少一个确定物体的3d空间中定位与空间的确定的2d图像的特定2d表示元素361a(例如,像素)相关联的物体元素。推导块361(可以执行步骤351)可以被配置用于基于预定义的位置关系推导成像空间元素的候选空间位置的范围或区间(例如,从相机射出的射线)。限制块362(可以执行
步骤352)可以被配置用于将候选空间位置的范围或区间限制为可接受的候选空间位置的至少一个受限范围或区间(例如,射线中的一个或多个区间),其中限制块362可以被配置为:
[0296]
使用围绕至少一个确定物体的至少一个包含体积来限制候选空间位置的范围或区间;和/或
[0297]
使用包括不可接受的候选空间位置的至少一个排除体积来限制候选空间位置的范围或区间;和/或
[0298]
使用其他约束(例如近似表面、容差值等)来限制候选空间位置的范围或区间;
[0299]
检索块363(可以执行步骤353或37)可以被配置为用于基于相似性度量在受限范围或区间的可接受的候选空间位置中检索最合适的候选空间位置(363
′
)。
[0300]
图38示出了系统380,其可以是系统360或被配置为执行根据下文或上文示例的技术和/或诸如方法30或350的方法的另一系统的实现的示例。示出了推导块361、限制块362和检索块363。系统380可以处理从根据不同的相机位置获取相同空间的图像的至少第一和第二相机(例如,多相机环境,例如立体视觉系统)获得的数据,或者处理从沿着多个位置移动的一个相机获得的数据。第一相机位置(例如,第一相机的位置或第一时刻处的相机位置)可以被理解为相机提供第一2d图像381a的第一位置;第二相机位置(例如,第二相机的位置或同一相机在第二时刻处的位置)可以被理解为相机提供第二2d图像381b的位置。第一2d图像381a可以被理解为图2的第一图像22,而第二2d图像381b可以被理解为图2的第二图像23。可任选地使用其他相机或相机位置,例如,以提供附加的2d图像381c。每个2d图像可以是位图,例如,或包括多个像素(或其他2d表示元素)的类矩阵表示,每个像素都被分配给一个值,例如强度值、颜色值(例如rgb)等。系统380可以将第一2d图像381a的每个像素与成像空间中的特定空间位置(特定空间位置是由像素成像的物体元素的位置)相关联。为了获得该目标,系统380可以利用第二2d图像381b和与第二相机相关联的数据。具体地,系统380可以被馈入以下至少一项:
[0301]
‑
相机的位置关系(例如,对于每个相机,光学中心o
l
和o
r
的位置,如图2中所示)和/或相机的内部参数(例如焦距),这可能会影响获取的几何形状(这些数据在这里针对第一相机用381a'来表示,针对第二台相机用381b'来表示);
[0302]
‑
获取的图像(例如位图、rgb等)381a和381b。
[0303]
具体地,可以将第一相机的参数381a
′
(无2d图像是绝对必要的)馈入推导块361。因此,推导块361可以定义候选空间位置361
′
的范围,其可以跟随例如从相机射出并且表示对应像素或2d表示元素的射线。基本上,候选空间位置361
′
的范围仅基于几何性质和第一相机内部的性质。
[0304]
限制块362可以进一步将候选空间位置361
′
的范围限制为可接受的候选空间位置362
′
的受限范围。限制块362可以基于从约束定义器364获得的约束364'(近似表面、包含体积、排除体积、容差
……
)仅选择候选空间位置361
′
的范围的子集。因此,可以在范围362'中排除范围361
′
中的一些候选位置。
[0305]
约束定义器364可以允许用户的输入384a控制约束364
′
的创建。约束定义器364可以使用图形用户界面(gui)操作以帮助用户定义约束364
′
。约束定义器364可以被馈入第一2d图像381a和第二2d图像381b,并且在一些情况下,被馈入先前获得的深度图(或其他定位
数据)383a(例如,如在方法30的初始深度计算步骤34中获得的或来自方法30或系统380的先前迭代)。因此,用户在定义约束384b时被可视地引导。下面提供了示例(参见图30至图34和相关文本)。
[0306]
在某些情况下,约束定义器364还可以被馈入来自先前迭代的反馈384b(也参见图3的方法30中的步骤37和38之间的连接)。
[0307]
因此,限制块362可以施加已由用户(例如,以图形方式)引入(如384a)的约束364,以便定义可接受的候选空间位置362
′
的受限范围。
[0308]
因此,可以实施例如步骤37或353或上文和/或下文讨论的其他技术的检索块363可以分析在可接受的候选空间位置362
′
的受限范围内的位置。
[0309]
检索块363可以具体包括估计器385,该估计块可以输出最合适的候选空间位置363'作为估计的定位(例如,深度)。
[0310]
检索块363可以包括相似性度量计算器386,该相似性度量计算器可以处理相似性技术(例如,在第5节中讨论的那些或其他统计技术)。相似性度量计算器386可以被馈入:
[0311]
‑
与第一和第二(381a,381b)相机两者相关联的相机参数(381a
′
,381b');以及
[0312]
‑
第一和第二2d图像(381a,381b),以及,
[0313]
‑
在某些情况下,附加图像(例如381c)以及与附加图像相关联的附加相机参数。
[0314]
例如,检索块363可以通过分析第二2d图像(例如,图2中的23)中的与第一2d图像(例如,22)的特定像素(例如,x
l
)相关联的外极线(例如,21)的那些像素的相似性度量,来确定由第一图像(例如,22)的像素(例如,x
l
)表示的物体元素(例如,x)的空间位置(或至少最合适的候选空间位置)。
[0315]
估计的定位无效器或深度图无效器383(可以基于用户输入383b和/或可以被馈入深度值383a或其他粗略定位值,例如,如在步骤34中获得的或从方法30或系统380的先前迭代中获得的)可用于(383c)对所提供的定位(例如,深度)383a确认有效或确认无效。由于通常可以获得每个估计定位383a的置信度或可靠性或不可靠性值,因此可以分析所提供的定位383a并将其与可能已经由用户输入的阈值c0(383b)进行比较。对于每个近似表面,该阈值c0可以不同。该步骤的目的可以是仅用新的定位估计363
′
精细化那些在先前的定位步骤(34)或方法30或系统380的先前迭代中不正确或不可靠的定位。换句话说,如果所提供的输入值383a不正确或没有足够的置信度,则仅考虑受约束364'影响的定位估计363
′
以用于最终输出387
′
。
[0316]
为此,如果383a的可靠性/置信度不满足用户提供的阈值c0,则定位选择器387可以基于所提供的深度输入383a的有效/无效(383c)来选择获得的深度图或估计的定位363'。附加地或备选地,可以执行新的迭代:粗略或不正确估计的定位可以作为反馈384b反馈到约束定义器364,并且可以执行新的、更可靠的迭代。
[0317]
否则,从检索块363计算或从输入383a复制的深度(或其他定位)被接受并提供(387
′
)作为与第一2d图像的特定2d像素相关联的定位位置。
[0318]
8.示例解决的技术问题的分析
[0319]
参考文献[8]描述了如何使用3d网格精细化深度图的方法。为此,他们计算给定相机的3d网格深度,并使用该信息更新所考虑相机的深度图。图4描绘了相应的原理。它以球体和用户已绘制的近似表面42的形式示出了示例3d物体41。相机44获取球体41,以获得作
为像素矩阵(或其他2d表示元素)的2d图像。每个像素与物体元素相关联并且可以理解为表示一条射线与真实物体41的表面之间的相交:例如,一个像素(表示真实物体41的点43)被理解为与射线45和真实物体41的表面之间的交点相关联。
[0320]
然而,识别点43在空间中的真实位置并不容易。根据由相机44获取的2d图像,特别不容易理解点43可以定位在何处,例如,定位在不正确的位置43
′
或43”。这就是为什么需要使用某种策略来确定成像点(物体元素)的真实位置的原因。
[0321]
根据一个示例,对正确成像位置的搜索可以被限制到候选空间位置的特定可接受范围或区间,并且仅在候选空间位置的可接受范围或区间中,基于两个或多个相机之间的三角测量来处理相似性度量以推导实际空间位置。
[0322]
为了限制对可接受的候选空间位置的搜索,可以使用基于使用近似表面42的技术。近似表面42可以以网格的形式绘制,尽管替代几何图元是可能的。
[0323]
为了计算每个像素的深度值的可接受区间,有必要确定给定的像素是否受到近似表面的影响,如果是,则确定给定的像素受到近似表面的哪部分的影响。换句话说,有必要确定近似表面42的哪个3d点43”'由像素描绘。然后可以将3d点43”'的深度视为该像素的可能深度候选。
[0324]
通过将由像素和相机44的入瞳定义的射线45与近似表面42相交,可以找到由像素实际描绘的近似表面的3d点(例如,43
”′
)。如果存在这样的交点43
”′
,则认为该像素属于近似表面42,因此属于3d物体41。
[0325]
因此,像素的可接受的候选空间位置的范围或区间可以被限制为从点43
”′
开始的近侧区间(点43”'是射线45和近似表面42之间的交点)。
[0326]
射线相交是一个技术概念,可以实现为不同的变型。一种是将场景的所有几何图元与射线45相交,并确定具有有效交点的那些几何图元。备选地,所有近似表面都可以投影到相机视图上。然后每个像素用相关的近似表面来标记。
[0327]
遗憾的是,即使我们已经找到了近似表面42的3d点43
”′
和该3d点43
”′
的与由相机44成像的所考虑像素相对应的深度,我们仍然需要推导所考虑像素的可接受的深度值的可能区间。基本上,即使我们已经找到了可接受的候选空间位置范围的末端43”',我们也没有对可接受的候选空间位置的范围进行足够的限制。
[0328]
虽然参考文献[8]没有提供有关该步骤的任何详细信息,但仍存在需要避免的一些陷阱,以下将对其进行详细说明。
[0329]
首先需要注意的是,与点43”'相对应的深度值不能直接作为像素的深度值。原因是由于时间约束,用户无法或不愿意创建非常精确的网格。因此,近似表面42的点43
”′
的深度与真实物体在点43的深度不同。相反,它仅提供粗略的近似值。如图4中可见,真实物体41的真实深度(对应于点43)与3d网格42的深度(对应于点43”')不同。因此,我们需要设计一种将3d网格42转换为可接受的深度值的算法(参见第10节)。
[0330]
用户仅指示近似的近似表面的事实使得近似表面包含在真实物体内是可取的。偏离该规则的后果如图40所示。
[0331]
在这种情况下,用户针对真实圆柱形物体401绘制粗略的近似表面402。通过这些方式,假设与射线2(405b)相关联的物体元素401
”′
接近近似表面402,因为射线2(405b)与近似表面402相交。然而,这样的结论不必为真。通过这些方式,可能会施加错误的约束,从
而导致深度图中的伪影。
[0332]
因此,以下建议将近似表面包含在物体内。用户可能偏离该规则,并且取决于相机位置,获得的结果仍然是正确的,但错误深度值的风险会增加。换句话说,虽然下面的附图和讨论假设近似表面位于物体内,但如果这不成立,则可以应用相同的方法进行小的修改。
[0333]
但即使当近似表面包含在物体内,仍然存在挑战,因为它们仅粗略地表示物体。其中之一是竞争约束,如图5所示。图5描绘了竞争近似表面的示例。场景由两个3d物体组成,即球体(标记为真实物体41)和作为第二物体41的平面,图中不可见。3d物体41和41a由对应的近似表面42和42a表示。
[0334]
在从相机1(44)获得的2d图像中,与射线1(45)相关联的像素可以通过与近似表面42的相交定位为在第一真实物体41中,这正确地将可接受的空间位置限制为点43”'右侧的射线1(45)中的区间中的位置。
[0335]
然而,存在正确定位与射线2(45a)相关联的像素的问题,该像素实际上代表元素43b(真实物体41的圆周与射线45a之间的交点)。先验是不可能得出正确结论的。事实上,射线2(45a)不与近似表面1(42)相交,但它确实在点43a
”′
处与近似表面2(42a)相交。因此,仅仅使用近似表面导致限制候选空间位置的范围或区间以错误地将从射线2(45a)获得的像素定位成与平面41a(第二物体)相对应,而不是定位到元素43b的实际位置。
[0336]
这些缺陷的原因是近似表面1(42)仅粗略地描述了球体41。因此,射线2(45a)不与近似表面1(41)相交,导致错误地将元素43b定位成与点43a”'相对应。
[0337]
在没有近似表面2(42a)的情况下,属于射线2(45a)的像素2将不受约束。根据使用的深度估计算法和相似性度量,它可能被分配到正确的深度,因为它的相邻像素将具有正确的球体深度,但代价是非常高的计算工作量(因为应该对射线2(45a)中扫描的所有位置的相似性度量进行比较,从而极大地增加了过程)。然而,当近似表面2(42a)就位时,像素2将被强制属于平面41a。结果,推导的可接受深度范围将是错误的,因此计算的深度值也将是不正确的。
[0338]
因此,我们需要提出如何避免由竞争深度约束引起的错误深度值的构思。
[0339]
已经确定了另一个问题,即关于遮挡。需要以特定方式考虑遮挡以得到正确的深度值。这在参考文献[8]中没有考虑。图6示出了真实物体(圆柱体)61,其由六边形近似表面62描述并且由已知彼此位置关系的相机1(64)和相机2(64a)成像。然而,对于两个相机位置之一,圆柱形物体61被绘制为菱形的另一个物体61a遮挡,该遮挡物体缺乏任何近似表面。
[0340]
这种情况具有以下后果:虽然与射线1(65)相关联的像素将被正确地识别为属于近似表面62,但与射线2(65a)相关联的像素将不会被正确识别:与射线2相关联的像素(65a)将仅借助于与物体61的近似表面62相交并且不存在遮挡物体61a的任何近似表面而与物体61相关联。
[0341]
因此,射线2(65a)的可接受深度范围将接近圆柱体61而不是菱形62。因此,自动计算的深度值将是错误的。
[0342]
解决这种情况的一种方法是也创建菱形的另一个近似表面。但这导致需要针对场景中的所有物体手动创建精确的3d重建,这将避免,因为它太耗时。
[0343]
一般而言,无论是否使用近似表面,根据现有技术的技术都可能容易出错(通过错误地将像素分配给虚假物体)或可能需要在候选空间位置的过于扩展的范围内处理相似性
度量。
[0344]
因此,需要减少计算工作量和/或增加定位可靠性的技术。
[0345]
9.交互式深度图改进的包含体积
[0346]
在上文和下文中,为了简洁,经常提到“像素”,即使这些技术可以概括为“2d表示元素”。
[0347]
在上文和下文中,为了简洁,经常提到“射线”,即使这些技术可以概括为“候选空间位置的范围或区间”。候选空间位置的范围或区间可以例如沿着从相机的节点相对于确定的2d图像离开的射线延伸或展开。理论上,在数学观点下,像素理想地与射线(例如,图2中的24)相关联:像素(图2中的x
l
)可以与候选空间位置的范围或区间相关联,这可以理解为从节点(图2中的o
l
)向无限大的锥形或截锥形体积离开。然而,在下文中,“候选空间位置的范围或区间”主要讨论为“射线”,记住其含义可以很容易地进行概括。
[0348]“候选空间位置的范围或区间”可以基于以下讨论的特定约束限制为更有限的“可接受的候选空间位置的范围或区间”(因此例如,通过人类用户的视觉分析或通过自动确定方法排除了被认为是不可接受的一些空间位置)。例如,可以排除不可接受的空间位置(例如,在人眼看来明显不正确的那些空间位置),以减少检索时的计算工作量。
[0349]
这里经常提到“深度”或“深度图”,其中两者都可以概括为“定位”的概念。深度图可以存储为视差图,其中视差与深度的乘法逆元成正比。
[0350]
此处,对“物体元素”的引用可以被理解为“由对应的2d表示元素(例如,像素)成像(与对应的2d表示元素相关联)的物体的一部分”。在一些情况下,“物体元素”可以理解为不透明实体元素的小表面元素。通常,所讨论的技术的目的是在空间中定位物体元素。例如,通过将多个物体元素的定位放在一起,可以重建真实物体的形状。
[0351]
上文和下文讨论的示例可以涉及用于定位物体元素的方法。可以定位至少一个物体的物体元素。在一些情况下,如果在同一成像空间中存在两个物体(彼此不同),则存在确定物体元素是与第一物体还是第二物体相关联的可能性。在一些示例中,可以精细化先前获得的深度图(或以其他方式的粗略定位),例如,通过以比先前获得的深度图中的可靠性更高的可靠性来定位物体元素。
[0352]
在下文和上文的示例中,通常参考位置关系(例如,对于每个相机,光学中心o
l
和o
r
的位置,如图2中所示)。可以理解,“位置关系”还包括所有相机参数,包括外部相机参数(例如,相机的位置、定向等)以及内部相机参数(例如,焦距,这可能影响获取的几何形状,像通常在外极几何中一样)。这些参数(可以是先验已知的)也可以用于定位和深度图估计的计算。
[0353]
当针对第一确定的图像(例如,22)分析相似性度量(例如,在步骤37和/或步骤353或块363)时,可以(例如,通过分析图2的外极线21中的像素)考虑第二2d图像(例如22)。第二2d图像(22)可由第二相机或由同一相机在不同位置(假设成像物体没有移动)获取。图7、图8、图9、图10、图13、图29等为了简明起见仅示出了单个相机,但应理解相似性度量(37、353)的计算将通过使用利用不同的未示出的相机或由同一相机从不同位置(如图2所示)(不同位置具有已知的位置关系,即,已知相机的内部参数和外部参数)获得的第二2d图像来进行。
[0354]
还应注意,在随后的示例中(例如,图11、图12、图12a、图27、图37等)示出了两个相
机。这两个相机可能是用于在外极几何(epi
‑
polar geometry)(如图2所示)中分析相似性度量(例如,在步骤37和/或353处)的那些相机,但这不是完全必要的:还可能存在可用于分析相似性度量的其他(未示出)附加相机。
[0355]
在上文和下文的示例中,经常提到“物体”,意义是它们可以是复数。然而,虽然在一些情况下它们可能被理解为彼此不同和分离,但也可能是它们在结构上彼此连接(例如,通过由相同的材料制成,或通过彼此连接等)。可以理解,在一些情况下,“多个物体”因此可能指同一物体的“多个部分”,因此赋予“物体”一词广义的含义。因此,近似表面和/或包含体积和/或排除体积可以与单个物体的不同部分相关联(每个部分是物体本身)。
[0356]
9.1原理
[0357]
诸如第8节中解释的问题可以借助通过实现包含体积而补充近似表面(例如,以3d网格的形式)来解决。更详细地,可以如下描述两个几何图元。
[0358]
现在参考图7。在与像素(或另一2d表示元素)相关联的射线75(或候选位置的另一范围或区间)与近似表面72相交的情况下,这可以指示对应的3d点73位于相机74的位置和像素射线75与近似表面71的交点73”'之间。
[0359]
在没有附加信息的情况下,3d点(物体元素)73可以位于沿着点73”'(射线75与近似表面72的交点)和相机74的位置之间的射线75的区间75
′
中。这可能导致限制性不够:必须对整个线段长度处理相似性度量。根据此处提供的示例,我们介绍进一步减少可接受深度值的方法,从而提高可靠性和/或减少计算工作量。因此,我们追求的一个目标是在比范围75
′
更受限制的范围内处理相似性度量。在一些示例中,该目标可以通过使用基于约束的技术来实现。
[0360]
优选的基于约束的技术可以是添加包含体积的技术。包含体积可以是封闭体积。它们可以这样被理解:封闭的体积将空间分成两个或多个分隔的子空间,使得在不穿过封闭体积的表面的情况下不存在从一个子空间到另一个子空间的任何路径。包含体积表示封闭体积中可能存在3d点(物体元素)。换句话说,如果射线与包含体积相交,则它定义了可能的3d位置点,如图8所示。
[0361]
图8示出了在近端86
′
和远端86”之间约束射线85的包含体积86。
[0362]
根据一个示例,在包含体积86之外,不可能在射线85上进行定位(并且在步骤37或步骤353或块363中将不尝试分析相似性度量)。根据一个示例,射线85上的定位仅在至少一个包含体积86内是可能的。值得注意的是,包含体积可以自动(例如,从近似表面)和/或手动(例如,由用户)和/或半自动地(例如,由用户在计算系统的帮助下)生成。
[0363]
图9中提供了一个示例。这里,真实物体91由相机94成像。通过射线1(95),特定像素(或更一般的2d表示元素)代表物体元素93(其在物体91的表面与射线1(95)之间的交点处)。我们打算以高可靠性和低计算工作量来定位物体元素93。
[0364]
可以(例如,由用户)定义近似表面1(92),使得近似表面1(92)的每个点都包含在物体91内。可以(例如,由用户)定义包含体积96使得包含体积96围绕真实物体91。
[0365]
首先,推导出候选空间位置的范围或区间:该范围可以沿着射线1(95)展开并且因此包含大量候选位置。
[0366]
此外(例如,在图3中的步骤36或步骤352或块362),候选空间位置的范围或区间可以被限制为可接受的候选空间位置的受限范围或区间,例如,线段93a。线段93a可以具有第
一近端96”'(例如,射线95和包含体积96之间的交点)和第二远端93”'(例如,射线95和近似表面92之间的交点)。线段93a(使用该技术)和线段95a(将在没有包含体积96的定义的情况下使用)之间的比较可允许理解本技术相对于现有技术的优点。
[0367]
最后(例如,在步骤37或353或块363),相似性度量可以仅在线段93a(可接受的候选空间位置的受限范围或区间)内计算,并且物体元素93可以更容易和更可靠地定位(因此排除不可接受的位置,例如相机位置和点96
”′
之间的位置),而不会过度使用计算资源。例如,可以使用如参考图2所解释的相似性度量。
[0368]
在一个变型中,可以不需要近似表面1(92)。在那种情况下,将沿着在射线95与包含体积96的两个交点之间定义的整个线段计算相似性度量,尽管减少了关于线段95a的计算工作量(如在现有技术中)。
[0369]
包含体积可以在一般意义上至少以两种方式使用:
[0370]
·
它们可以围绕近似表面。在这个功能中,它们限制了可接受的3d点,从而限制了由单独近似表面所允许的深度值。这在图9中描绘。近似表面1(92)指定所有3d点(可接受的候选位置)必须位于相机94和像素射线95与近似表面1(92)的交点93
”′
之间。另一方面,包含体积96指定所有点(可接受的候选位置)必须位于包含体积96内。因此,仅图9中的线段93a的粗体位置是可接受的。
[0371]
·
包含体积可以围绕遮挡物体。例如,这在图10中示出(参见后续部分)。六边形近似表面和包含体积限制了圆柱形真实物体的可能位置。围绕菱形的包含体积最终通知深度估计程序,周围包含体积中也可能存在3d点。因此,允许的深度值由两个不相连的区间形成,每个区间由一个包含体积定义。
[0372]
代替使用包含体积围绕近似表面来定义可接受的深度范围,还可以至少部分隐式地获得可接受空间位置的受限范围或区间(例如,用户无需实际消耗包含体积)。这种方法的更多细节将在第10.2节中解释。第10节给出了如何将包含体积和近似表面转换为可接受深度范围的精确程序。
[0373]
可以注意到,可接受的候选空间位置的至少一个受限范围或区间可以是不连续的范围,并且可以包括多个不同和/或不相连的受限范围(例如,每个物体一个受限范围和/或每个包含体积一个受限范围)。
[0374]
9.2通过包含体积处理遮挡物体
[0375]
可以参考图10。这里,第一真实物体91由相机94成像。然而,第二真实物体101存在于前景中(遮挡物体)。旨在定位由与射线2(105)相关联的像素(或更一般地为2d表示元素)表示的元素:先验不知道该元素是真实物体91的元素还是真实遮挡物体101的元素。具体地,定位成像元素可以意味着确定该元素属于真实物体91和101中的哪一个。
[0376]
对于与射线1(95)相关联的像素,可以参考图9的示例,从而得出在区间93a内要检索成像物体元素的结论。
[0377]
然而,对于与射线2(105)相关联的像素,先验地不容易定位成像的物体元素。为了实现这样的目的,可以使用诸如以下的技术。
[0378]
可以(例如,由用户)定义近似表面92,使得近似表面92的每个点都包含在真实物体91内。可以(例如,由用户)定义第一包含体积96,使得第一包含体积96围绕真实物体91。第二包含体积106可以被定义(例如,由用户)使得包含体积106围绕第二物体101。
[0379]
首先,推导出候选空间位置的范围或区间:该范围可以沿着射线2(105)展开并且因此包含大量候选位置(在相机位置和无限之间)。
[0380]
此外(例如,在图3的方法30中的块35和块36和/或在图35的方法350中的352),候选空间位置的范围或区间可以进一步限制为可接受的候选空间位置的至少一个受限范围或区间。可接受的候选空间位置的至少一个受限范围或区间(因此可以排除被认为不可接受的空间位置)可以包括:
[0381]
末端93
”′
和96
”′
之间的线段93a
′
(如图9的示例中所示);
[0382]
末端103
′
和103”之间的线段103a(例如,射线105和包含体积106之间的交点)。
[0383]
最后(例如,在图3中的步骤37或在图35中的353或块362),可以仅在可接受的候选空间位置(线段93a
′
和103a)的至少一个受限范围或区间内计算相似性度量,以便定位(例如,通过检索特定像素的深度)由像素特定像素成像的物体元素和/或确定成像的物体元素是属于第一物体91还是属于第二物体101。
[0384]
注意,先验地,自动系统(例如,块362)不知道用射线2(105)实际成像的物体元素的位置:这由物体91和101的空间配置定义(特别由物体在进入图10中的纸张的维度上的延伸定义)。无论如何,将通过使用相似性度量来检索正确的元素(例如,如上文图2所示)。
[0385]
概括该程序,可以阐述为可以将候选空间位置的范围或区间限制为:
[0386]
与第一确定物体(例如,91)相关联的可接受的候选空间位置的至少一个第一受限范围或区间(例如,射线1的线段93a;射线2的线段93a
′
);以及
[0387]
与第二确定物体(例如,101)相关联的可接受的候选空间位置的至少一个第二受限范围或区间(例如,针对射线1,为空;针对射线2,为线段103a),
[0388]
其中限制包括将至少一个包含体积(例如,96)定义为围绕第一确定物体(91)的第一包含体积(以及围绕第二确定物体(例如,106)的第二包含体积(例如,106)),以限制候选空间位置的至少一个第一(和/或第二)范围或区间(例如,93a
′
、103a);以及
[0389]
确定特定的2d表示元素是与第一确定物体(例如,91)相关联还是与第二确定物体(例如,96)相关联。
[0390]
该确定可以基于例如相似性度量,例如参考图2和/或其他技术所讨论的(例如,见下文)。
[0391]
附加地或备选地,在一些示例中,还可以利用其他观察。例如,在射线1(95)的情况下,基于观察到射线1(95)和第二包含体积106之间的交点为空,可以得出结论,射线1(95)只属于第一个物体91。值得注意的是,最后的结论不需要严格考虑相似性度量,因此可以在例如限制步骤352中执行。
[0392]
换句话说,图10示出了由六边形近似表面92描述的真实物体(圆柱体)91。然而,对于所考虑的相机视图,圆柱体物体92被绘制为菱形的另一个物体101遮挡。
[0393]
当仅考虑近似表面1(92)时,这具有以下后果:虽然与射线1(95)相关联的像素将被正确识别为属于近似表面92,但与射线2(105)相关联的像素将不会被正确识别为属于近似表面92,并且因此,当没有采取适当的对策时,将导致深度图中的伪影。
[0394]
人们可能认为解决这种情况的一种方法是创建菱形的另一个近似表面。但最终,这导致需要为场景中的所有物体手动创建精确的3d重建,这是应避免的,因为它太耗时。
[0395]
为了解决这个问题,如上所述,除了上述近似表面之外,我们的技术还引入了所谓
的包含体积96和/或106。包含体积96或106也可以以网格或任何其他几何图元的形式绘制。
[0396]
包含体积可以定义为围绕物体的粗略外壳,并指示3d点(物体元素)可能位于包含体积(例如96、106...)中的可能性。这不意味着在这样的包含体积中必须存在3d点(物体元素)。它仅可能(生成包含体积的决定可以留给用户)。为了避免不同相机位置的歧义(图10中未示出),包含体积可以是封闭体积,其具有外表面但没有边界(没有外边)。封闭的体积在放置在水下时,每个表面的一侧必须保持干燥。
[0397]
因此,使用近似表面(例如,92)、包含体积(例如,96、106)或它们的组合,允许定义由一组可能分离的深度图区间(例如,93a'和103a)组成的更复杂的深度图范围。因此,自动深度图处理(例如,在检索步骤353或37或块363处)仍然可以从减少的搜索空间中获益,同时正确处理遮挡物体。
[0398]
不要求用户在场景中的每个物体周围绘制包含体积。如果针对遮挡物体,可以可靠地估计深度,则不必绘制包含体积。更多细节可以在第10节中看到。
[0399]
参考图10,可以存在变型,根据该变型,没有针对物体91定义近似表面92。在那种情况下,对于射线2(105),可接受的候选空间位置的受限范围或区间将由下项形成:
[0400]
‑
将射线105和包含体积96的两个交点作为端点的线段(而不是线段93a');以及
[0401]
‑
线段103a。
[0402]
对于射线1(95),可接受的候选空间位置的受限范围或区间将由具有射线1(95)和包含体积96的两个交点作为端点的线段(而不是线段93a)形成。
[0403]
可以存在变型,根据该变型针对物体91定义第一近似表面并且针对物体101定义第二近似表面。在那种情况下,对于射线2(105),可接受的候选空间位置的受限范围或区间将由包含体积106和与物体101相关联的第二近似表面之间的一小线段形成。这是因为,在找到射线2(105)与物体101的近似表面的交点之后,没有必要针对被物体101遮挡的物体91进行度量比较。
[0404]
9.3使用包含体积以解决竞争约束
[0405]
近似表面通常会相互竞争,从而导致潜在的错误结果。为此,本节详细阐述了如何避免这种情况的构思。图11示出示例。这里,第一真实物体91可以在前景中并且第二真实物体111可以在相对于相机1(94)的背景中。第一物体可以被包含体积96围绕并且可以在其中包含近似表面1(92)。第二物体111(未示出)可以包含近似表面2(114)。
[0406]
这里,与射线1(95)相关联的像素(或其他2d表示元素)可以如图9中那样处理。
[0407]
与射线2(115)相关联的像素(或其他2d表示元素)可能受到以上针对图5的射线45a(第8节)所讨论的问题。真实物体元素93被成像,但原则上不容易识别其位置。然而,可以使用以下技术。
[0408]
首先(例如,在351),推导出候选空间位置的范围或区间:该范围可以沿着射线2(115)展开并且因此包含大量候选位置。
[0409]
此外(例如,在35和36和/或在352和/或在块362),候选空间位置的范围或区间可以被限制为可接受的候选空间位置的受限范围或区间。这里,可接受的候选空间位置的受限范围或区间可以包括:
[0410]
‑
由末端96'和96”(例如,包含体积96和射线115之间的交点)之间的线段96a形成的可接受的候选空间位置的第一受限范围或区间;
[0411]
由点或线段112'(例如,射线105和近似表面112之间的交点)形成的可接受的候选空间位置的第二受限范围或区间。备选地,近似表面112可以由另一个包含体积围绕以导致完整的第二深度线段。
[0412]
(受限范围112'可以根据特定示例或用户的选择被定义为一个单个点或容差区间。下面讨论了一些使用容差的示例。对于这部分的讨论,仅需要注意受限范围112'也包含候选空间位置)。
[0413]
最后(例如,在步骤37或353或363),可以计算相似性度量,但仅在线段96a和点或线段112
′
内,以便定位由特定像素成像的物体元素和/或确定所成像的物体元素是属于第一物体91还是属于第二物体111(因此,排除一些被识别为不可接受的位置)。通过将候选空间位置的范围或区间限制为可接受的候选空间位置的受限范围或区间(这里由两个不同的受限范围,即线段96a和点或线段112'形成),可以对成像物体元素93操作极其容易且需要计算功率更低的定位。
[0414]
一般而言,可以将候选空间位置的范围或区间限制为:
[0415]
与第一确定物体(例如,91)相关联的可接受的候选空间位置(例如,96a)的至少一个第一受限范围或区间;以及
[0416]
与第二确定物体(例如,111)相关联的可接受的候选空间位置(例如,112
′
)的至少一个第二受限范围或区间,
[0417]
其中限制(例如,352)包括将至少一个包含体积(例如,96)定义为围绕第一确定物体(例如,91)的第一包含体积,以限制候选空间位置的至少一个第一范围或区间(例如,96a和103a);以及
[0418]
其中检索(例如,353)包括确定特定的2d表示元素是与第一确定物体(例如,91)相关联还是与第二确定物体(例如,101、111)相关联。
[0419]
(可接受的候选空间位置的第一和第二受限范围或区间可以彼此不同和/或不相连)。
[0420]
可以获得从相机2(114)获取的定位信息(例如,深度信息),例如,以确认实际成像的元素是物体元素93。值得注意的是,从相机2(114)获取的信息可以是或包括先前获得的信息(例如,在先前的迭代处,从针对物体元素93执行的检索步骤(37、353)获得)。来自相机2(114)的信息也可以利用相机1和相机2(94和114)之间的预定义位置关系。
[0421]
基于来自相机2(114)的信息,针对从相机1(94)获得的2d图像,可以定位线段96a内的2d表示元素93和/或将2d表示元素93与物体91相关联。因此,当比较从相机1(94)获取的2d图像中的相似性度量时,位置112”将被先验排除,从而节省计算成本。
[0422]
换句话说,当我们利用我们的问题的多相机性质时,我们可以创建甚至更强大的约束。为此,假设物体(例如,球体)91被第二相机2(114)拍摄。相机2(114)的优点在于,针对由相机1(94)的射线2(115)表示的物体点93的射线114b仅撞击近似表面92(而不撞击近似表面112)。可以计算相机2(114)的深度,然后推导出对于射线2(94)仅表示物体91的深度是可行的。后者可以例如在块383和/或387处得到处理。
[0423]
使用该程序,在相似性度量的后续分析期间(例如,步骤37或353),可以避免在分析来自相机1(94)的第一2d图像时计算112
′
的相似性度量,从而减少必需的计算。
[0424]
一般而言,可以执行相机一致性操作。
[0425]
如果相机94和114一致地操作(例如,它们输出兼容的定位),则由所述方法的两次迭代提供的物体元素93的定位位置是相干的并且相同(例如,在预定容限内)。
[0426]
如果相机94和114不一致地操作(例如,它们输出不兼容的定位),则可能使定位无效(例如,通过无效器383)。在示例中,可以提高精度和/或降低容差和/或要求用户增加约束的数量(例如,增加包含体积、排除体积、近似表面的数量)和/或增加精度(例如,通过减少容差或通过更精确地重新绘制包含体积、排除体积、近似表面)。
[0427]
然而,在一些情况下,可以自动推断成像物体元素114的正确位置。例如,在图11中,如果由相机1(94)通过射线1(115)成像的物体元素93在范围112
′
中错误地被检索(例如在37或353),并且由相机2(114)通过射线114b成像的同一物体元素93被相机2(114)在区间96b中正确检索(例如在37或353),则由于相对于相机1(94)获得的可接受的候选位置的受限范围或区间的数量(两个:112'和96a)已找到了较少数量(一个:96b)的可接受的候选位置的受限范围或区间的事实,可以使针对相机2(114)提供的位置有效。因此,假设针对相机2提供的位置比针对相机1提供的位置更精确(94)。
[0428]
作为替代,可以通过分析针对每个位置计算的置信度值来自动推断成像物体元素93的正确位置。具有最高置信度值的估计定位可以是选择作为最终定位的定位(例如,387
′
)。
[0429]
图46示出了可以使用的方法460。在步骤461,可以执行第一定位(例如,使用相机1(94))。在步骤462,可以执行第二定位(例如,使用相机2(114))。在步骤463,检查第一定位和第二定位是否提供相同或至少相符合的结果。在相同或相符合结果的情况下,在步骤464确认定位有效。在不相符合的结果的情况下,根据具体示例,定位可以是:
[0430]
无效的,从而输出错误信息;和/或
[0431]
无效的,从而重新启动新的迭代;和/或
[0432]
分析,从而根据两个定位的置信度和/或可靠性选择所述两个定位之一。
[0433]
根据一个示例,可以使置信度或可靠性至少基于以下之一:
[0434]
定位位置与相机位置之间的距离,距离越近越增加;
[0435]
物体或包含体积或可接受的空间位置的受限范围的数量,以便如果在可接受的空间候选位置的范围或区间内发现较少数量的物体或包含体积或可接受的空间位置的受限范围,则增加置信度值;
[0436]
对置信度值等的度量。
[0437]
9.4正确处理平面近似表面
[0438]
到目前为止,大多数近似表面都包含体积。这通常是非常有益的,以防相机具有任意观看位置并且例如围绕物体。原因是无论相机位于何处,围绕体积的近似表面总是会导致正确的深度指示。然而,封闭的近似表面比平面的近似表面更难绘制。
[0439]
图12描绘了平面的近似表面的示例。该场景由两个圆柱形物体121和121a组成。物体121由围绕体积的近似表面122近似。圆柱体121a仅在一侧被近似,使用一个简单的平面作为近似表面122a。换句话说,近似表面122a不构建封闭体积,因此在下文中被称为平面近似表面。
[0440]
如果我们对近似表面使用目前所提倡的封闭体积,如122,这将针对所有可能的相机位置给出估计深度的正确指示。为了针对平面近似表面122a实现相同的效果,我们可能
稍微需要扩展所要求保护的方法,如下所述。
[0441]
解释基于图12a。例如,由相机124看到的近似表面122a的点125接近真实物体元素125a。因此,近似表面122a的约束将得出物体元素125a相对于相机124的正确候选空间位置。然而,当考虑相机124a时,这对于物体元素126而言并非如此。事实上,射线127在点126a处与平面近似表面相交。根据上述概念,点126a可以被认为是由射线127捕获的物体元素126的近似候选空间位置(或者至少,通过将候选空间位置的范围或区间限制为由点126a和相机124a的位置之间的区间构成的可接受的候选空间位置的受限范围或区间,当随后分析度量时(例如,在步骤37或353或块363),存在得出将点126定位在不同的、不正确的位置的错误结论的风险)。但是这个结论原则上是不可取的,因为点126a离物体元素126很远,因此近似表面122a很可能导致对点126的可接受的候选空间位置的错误约束。潜在的原因是平面近似表面可以主要表示物体“一侧”的约束。因此,我们可以区分射线(或候选空间位置的其他范围)是否在最优选的一侧撞击近似表面。幸运的是,这可以通过将法向量分配给正在逼近的物体表面(例如,圆柱体121a的表面的顶部)来实现,因此获得了一种简单但有效的技术。然后,在示例中,深度近似优选仅在法线和射线之间的点积为负时才考虑(参见第10节)。
[0442]
通过这些定义,可以支持封闭的近似表面和平面的近似表面两者。虽然第一个更通用,但后者更容易绘制。
[0443]
10.基于近似表面和包含体积的深度图(定位)生成和/或精细化
[0444]
10.1程序示例
[0445]
现在可以参考图47,其示出了方法470,该方法470例如可以是示例方法30或350或系统360的操作方案。可以看出,推导351和检索353可以如上文和/或下文的示例中的任何一个。参考步骤472,例如,其可以实现步骤352或者可以由块362操作。
[0446]
近似表面和包含体积以及其他类型的约束可以用于限制可能的深度值(或定位成像物体元素的其他形式)。通过这些方式,它们消除了确定对应关系的歧义,从而提高了结果质量。
[0447]
像素(或更一般地,与2d图像的2d表示元素相关联的物体元素)的可接受深度范围可以由与同该像素相关联的射线相交的所有近似表面和所有包含体积(或更一般地,候选空间位置的范围或区间)确定。取决于场景和用户绘制的近似表面(步骤352a),可能发生以下情况:
[0448]
1.像素射线不与任何近似表面或任何包含体积相交(即,可接受的候选空间位置的受限范围将导致为空)。在这种情况下(步骤352a1),我们考虑该像素的所有可能的深度值,并且没有对深度估计的附加约束。换句话说,我们将可接受的候选空间位置(362')的受限范围设置为等于可接受的候选空间位置(361
′
)的范围。
[0449]
2.像素射线仅与包含体积相交,但不与近似表面相交(即,可接受的候选空间位置的受限范围仅被包含体积限制,而不受近似表面的限制)。在这种情况下(352a2),可以想象仅允许对应的物体位于包含体积之一内。然而,这很关键,因为包含体积通常会超出它们所描述的物体边界,以避免需要精确指定物体的形状。因此,仅当所有3d物体被某个包含体积围绕时,这种方法才是容错的(fail
‑
safe)。在所有其他情况下,最好在不涉及近似表面时不对深度估计施加任何约束。这意味着我们考虑了该像素的所有可能深度值,并且没有对
深度估计的附加约束。换句话说,我们将可接受的候选空间位置(362')的受限范围设置为等于可接受的候选空间位置(361
′
)的范围。
[0450]
3.像素射线与近似表面和一个或多个包含体积相交(因此,可接受的候选空间位置的受限范围可以被包含体积以及近似表面限制)。在这种情况下(352a3),可接受的深度范围(其是原始范围的适当子集)可以如下所述被约束。
[0451]
4.第10.2节将讨论射线仅与近似表面相交的第四种可能性(但无论如何都会导致352a3)。
[0452]
对于受近似表面影响的每个像素,系统计算3d空间中的3d点(物体元素)的可能位置。为此,请考虑图13中描绘的场景。在示例中包含体积可以相互相交。它们甚至可能与近似表面相交。此外,近似表面可以包含体积,但不是必须的。图13示出了获取2d图像的相机134。在图13中,描绘了射线135。描绘了包含体积136a
‑
136f(例如,先前定义的,例如由用户手动定义的,例如通过使用约束定义器384)。还存在包含在包含体积136d内的近似表面132。近似表面和包含体积为限制候选空间位置的范围或区间提供约束。例如,点135
′
(在射线135中)在可接受的候选空间位置137的受限范围或区间之外,因为点135
′
不接近近似表面或不在任何包含体积或353或块363内:因此,当比较相似性度量时(例如,在步骤37),将不会分析点135
′
。相反,点135”在可接受的候选空间位置137的受限范围或区间内,因为点135”在包含体积136c内:因此在比较相似性度量时将分析点135”。
[0453]
基本上,当限制时(例如,步骤35、36、352),可以从对应于相机134的近侧位置向远侧位置(例如,对应于射线135的路径)扫描路径。具有包含体积和/或排除体积的交点(例如,i3
‑
i6、i9
‑
i13)可以定义可接受的候选位置的范围或区间的末端。根据示例,当遇到近似表面时(例如,对应于点i7),可以停止限制步骤:因此,即使存在超出近似表面132的另外的包含体积136e、136f,也排除另外的包含体积136e、136f。这是由于考虑到相机不能在比点i7更远的位置对任何事物进行成像:与点i8
‑
i13相关联的位置在视觉上被与近似表面132相关联的物体覆盖,并且不能物理成像。
[0454]
附加地或备选地,也可以排除理论上可以与射线135相关联的负位置(例如,点i0、i1、i2),因为它们不能被相机134物理地获取。
[0455]
为了定义计算可接受的深度值范围的程序,可以应用至少以下一些假设:
[0456]
·
每个近似表面都被包含体积围绕。与近似表面相关的可接受的深度范围由近似表面和包含体积之间的空间定义。第10.2节将介绍在近似表面没有被包含体积围绕的情况下的方法。
[0457]
·
令n为利用任何近似表面和任何包含体积找到的交点的数量。
[0458]
·
交点根据它们到相机的深度进行排序,首先从最负的深度值开始。
[0459]
·
令r是描述针对所考虑像素的相机入瞳的射线方向的向量。
[0460]
·
令depth_min是全局参数,其定义物体相对于相机可以具有的最小深度。
[0461]
·
令depth_max是全局参数,其定义物体相对于相机可以具有的最大深度(可以是无穷大)
[0462]
·
包含体积的法向量指向体积的外部。
[0463]
·
对于平面近似表面,法向量指向它可以提供正确深度范围约束的方向(参见第9.4节)。
[0464]
然后对于每个像素,可以使用以下程序来计算深度候选的集合。
[0465]
[0466]
[0467][0468]
该程序可以理解为针对给定的相机寻找最接近的近似表面,因为这定义了3d点的最大可能距离。此外,它遍历所有包含体积以确定可能的深度范围。如果没有围绕近似表面的包含体积,则深度范围可以通过一些其他方式计算(例如参见第10.2节)。
[0469]
通过这些方式,我们因此减少了深度估计的搜索空间(可接受的空间位置的受限范围或区间),这减少了歧义,从而提高了计算深度的质量。可以以不同方式执行实际深度搜索(例如,在步骤37或353)。示例包括以下方法:
[0470]
·
选择在允许的深度范围内示出最小匹配成本的深度
[0471]
·
在计算最小值之前,匹配成本通过像素射线与近似表面相交的深度的差异进行加权。
[0472]
为了对遮挡物更加鲁棒并且不需要通过包含体积来包围所有物体,用户可以提供附加的阈值c0(也参见第16.1节),例如可以在块383和/或387处对该阈值进行分析。在这种情况下,当在开始交互式深度图改进之前可用的所有深度的置信度大于提供的阈值时,这些深度被保留,并且不会根据近似表面进行修改。这种方法要求深度图程序针对每个像素输出所谓的置信度[17],该置信度定义了程序对所选择的深度值的确定程度。低置信度值意味着错误深度值的概率很大,因此深度值不可靠。通过这些方式,可以自动检测可以容易地估计深度的遮挡物。因此,它们不需要显式建模。
[0473]
注1:替代请求指向外部(或内部)的包含体积的法线,我们还可以对包含体积的表面多久被相交进行计数。对于第一交点,我们进入体积,对于第二交点,我们离开体积,对于第三交点,我们重新进入体积等等。
[0474]
注2:如果用户决定不在物体内放置近似表面,则第(25)行和第(35)行中的搜索范围可以按以下章节中所描述的进行扩展。
[0475]
10.2针对未被包含体积围绕的近似表面,推导可接受的深度范围
[0476]
10.1中定义的程序可以用于从围绕近似表面的包含体积计算近似表面的可接受的深度范围。然而,这不是强制约束。相反,也可以通过包含在第10.1节中的getlastdepth()函数中的其他方式来计算可接受的深度范围。下面,我们示例性地定义了这样一个可以通过getlastdepth()实现的功能。
[0477]
为此,可以假设近似表面点的法向量指向体积的外部。这可以由用户手动确保,或者在近似表面表示封闭体积的情况下可以应用自动程序。此外,用户可以定义容差值t0,该容差值本质上可以定义物体3d点(物体元素)与3d空间中的近似表面的可能距离。
[0478]
图14示出了真实物体141的物体元素143由相机1(144)通过射线2(145)成像以生成2d图像中的像素的情况。为了粗略地描述真实物体141,可以(例如,由用户)定义近似表面142以便使其位于真实物体141的内部。将确定物体元素143的位置。射线2(145)和近似表面142之间的交点由143”'表示,并且例如可以用作可接受的候选位置的受限范围或区间的第一未端,用于检索成像的位置物体元素143(随后将使用相似性度量进行检索,例如,在步骤353或37)的位置。将找到可接受的候选位置的受限范围或区间的第二末端。然而,在这种情况下,用户没有选择(或创建或定义)包含体积。
[0479]
尽管可以找到其他约束以限制可接受的候选位置的范围或区间。这种可能性可以通过下面的技术来体现,该技术考虑了交点143
”′
处近似表面142的法线将法线考虑在内的值(例如,由容差值t0缩放)可以用于将可接受的候选位置的受限范围或区间确定为点143”'(近似表面142与射线2(145)之间的交点)和点147
′
之间的区间147。换句话说,为了确定哪个像素(或其他2d表示元素)受近似表面142的影响,可以使由像素和相机1(144)的节点定义的射线2(145)(或候选位置的另一范围或区间)与近似表面142相交。对于其关联射线与近似表面相交的每个像素,可以计算3d空间中的3d点的可能位置。这些可能的位置取决于容差值(例如,由用户提供)。
[0480]
令t0为容差值(例如,由用户提供)。它可以指定要找到的3d点(例如,点143)距平面143b的最大可接受距离,平面143b由像素射线145与近似表面142的交点143
”′
以及交点143
”′
处的近似表面142的法向量定义。由于根据定义,近似表面142永远不会超过真实
物体141,并且由于近似表面142的法向量被假定指向3d物体体积的外部,因此单个正数可能足以指定3d点位置143相对于近似表面142的容差t0。原则上,在一些示例中,用户可以提供次要负值以指示真实物体点143也可以位于近似表面142后面。通过这些方式,可以补偿近似表面在3d空间中的放置错误。
[0481]
是在像素射线1(145)与近似表面142相交的点处的近似表面142的法向量。此外,令向量定义所考虑的相机144的光轴,从相机144指向场景(物体141)。然后可以通过计算将用户提供的容差值t0转换为给定相机的深度容差:
[0482][0483]
是一般向量的范数(或长度),|g|是一般标量g的绝对值,并且是向量和之间的标量积(标量积的模可以是)。参数φ
max
(例如,由用户定义)可以在和之间的角度φ变大的情况下(可选地)允许限制可能的3d点位置。
[0484]
令d为射线145与近似表面142的交点143
”′
相对于相机坐标系的的深度(例如,深度d是线段149的长度)。那么允许的深度值是
[0485]
[d
‑
δd,d]
ꢀꢀꢀꢀꢀꢀꢀ
(1)
[0486]
d
‑
δd可以是10.1节中函数getlastdepth()返回的值。因此,δd可以是可接受的候选位置147的受限范围的长度(在点143
”′
和147
′
之间)。
[0487]
对于φ
max
=0,δd=t0。也可以迭代地重复这个程序。在第一次迭代时,容差t0被选择为第一高值。然后,该过程在步骤35和36或352处执行,然后在步骤37或353处执行。随后,针对至少一些定位点计算定位错误(例如,通过块383)。如果定位错误超过预定阈值,则可以执行新的迭代,其中选择较低的容差t0。可以重复该过程以使定位错误最小化。
[0488]
区间[d
‑
δd,d](图14中用147表示)可以表示可接受的候选位置的受限范围,其中,通过使用相似性度量,物体元素143将被实际定位。
[0489]
一般而言,定义了一种用于在包含至少一个确定物体141的空间中定位与空间的2d图像中的特定2d表示元素相关联的物体元素143的方法,所述方法包括:
[0490]
基于预定义的位置关系针对成像的空间元素来推导候选空间位置的范围或区间(例如,145);
[0491]
将候选空间位置的范围或区间限制为可接受的候选空间位置(147)的至少一个受限范围或区间,其中限制包括:
[0492]
定义至少一个近似表面(142)和一个容差区间(147),以将候选空间位置的至少一个范围或区间限制为由容差区间(147)定义的候选空间位置的受限范围或区间,(其中,在示例中,至少一个近似表面可以包含在确定物体内),其中容差区间(147)具有:
[0493]
由至少一个近似表面(142)限定的远端(143
″′
);以及
[0494]
基于容差区间定义的近端(147
′
);以及
[0495]
基于相似性度量,在受限范围或区间(147)的可接受的候选空间位置中检索最合适的候选空间位置(143)。
[0496]
注意:如果用户决定不在物体内放置近似表面,则等式(1)中允许的深度范围可以扩展如下:
[0497]
[d
‑
δd,d δd2]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0498]
δd2以与δd的计算方式相同的计算方式进行计算,而参数t0被第二参数t1替换。然后,该值δd2也可以用于第10.1节第(25)和(35)行中描述的程序。换句话说,第(25)行被替换为:
[0499]
depthset=depthset [max(lastdepth,depth_min)),depth δd2],
[0500]
并且第(35)行被替换为:
[0501]
depthset=depthset [max(getlastdepth(),min_depth),depth δd2]
[0502]
10.3用户辅助深度估计
[0503]
在下文中,我们将描述如何可以执行交互式深度图估计和改进的更详细示例:
[0504]
1.识别预先计算的深度图(34)的错误深度区域(参见第14节)
[0505]
2.针对深度值难以估计的区域创建近似表面
[0506]
3.手动或自动创建包含体积(优选的),或将阈值t0设置为无穷大
[0507]
4.设置深度图置信度(可靠性)阈值c0并消除置信度值小于c0并且受近似表面(射线与近似表面相交)影响的预计算深度图(34)的所有深度值。以这样的方式设置阈值c0:针对由近似表面覆盖的所有区域的所有错误深度值都消失。需要注意的是,针对每个近似表面,c0可以不同地被定义(例如参见第16.1节)。
[0508]
5.对于未被包含体积围绕的所有近似表面,降低阈值t0(可以针对每个近似表面进行定义),直到近似表面覆盖的所有深度值都是正确的。如果这是不可能的,则精细化近似表面。
[0509]
6.对于已被包含体积围绕的所有近似表面,识别仍然错误的深度值并适当地精细化近似表面和包含体积。
[0510]
7.识别遮挡物中的错误深度值
[0511]
8.针对它们创建包含体积。如果这不够,则针对它们创建附加的近似表面。
[0512]
9.如果这导致由近似表面覆盖的3d物体中出现新的深度错误,则针对遮挡物将包含体积精细化为精确近似表面。
[0513]
10.4多相机一致性
[0514]
前几节讨论了如何限制某个相机视图的某个像素的可接受深度值。为此,射线交点(例如,93”'、96”'、103'、103”、143”'、i0
‑
i13等)确定了与所考虑相机的所考虑像素相关的范围。虽然这种方法已经可以显著减少可接受的深度值的数量,从而提高所得深度图的质量,但考虑到对应确定不仅依赖于单个相机,还依赖于多个相机,并且不同相机的深度图需要一致,这可以进一步改进。在下文中,我们列出了这种多相机分析如何进一步改进深度图计算的方法。
[0515]
10.4.1基于预计算深度值的多相机一致性
[0516]
图11举例说明了其中相机2(114)的预计算深度可以简化相机1(94)的深度计算的情况。为此,考虑图11中的射线2(115)。仅基于近似表面和包含体积,其可以表示物体91和物体111两者。
[0517]
现在让我们假设射线114b的深度值已经使用上文或下文描述的方法之一(或使用
另一种技术)确定。例如,在步骤37或353之后,针对射线114b获得的空间位置是点93。必须注意,点93不是位于近似表面92上,而是位于真实物体91上,因此与近似表面92有一定距离。
[0518]
在下一步中,我们考虑相机1(94)的射线2(115)并旨在也计算其深度。在没有针对射线114b计算的深度的知识的情况下,存在候选空间位置的两个可接受的受限范围(112'、96a)。让我们假设自动确定(例如,在37、353、363
……
)未能推导射出线2(115)相交的真实物体(91),并且错误地获得了范围112
′
中的点作为最合适的空间位置。然而,这意味着与射线2(115)相关联的像素或2d表示元素已被分配两个不同的空间位置,即93(来自射线114b)和112'中的一个位置(来自射线115),因为物体元素93中的位置(来自射线114b)和112
′
中的位置(来自射线115)意味着由相同的2d表示元素(不兼容的位置)成像。然而,一个2d表示元素不可能与不同的空间位置相关联。因此,可以自动理解(例如,通过无效器383)深度计算失败(无效)。
[0519]
为了解决这种情况,可以采用不同的技术。一种技术可以包括针对射线2(115)选择最接近的空间位置93。换句话说,可以用针对相机2(114)的射线114b的空间位置重写针对相机1(94)的射线2(115)的自动计算深度值)。
[0520]
当计算针对射线2(115)的空间位置时,不是搜索整个深度范围(115),当针对射线114b的空间候选位置之前已被可靠地确定时,也可以仅在相机1(94)和点93之间的范围内搜索。通过这些方式,可以节省大量的计算时间。
[0521]
图41示出了稍微不同的情况。假设针对射线114b的深度已被计算为与空间候选位置93匹配。现在让我们考虑射线3(415)。先验地,情况与图11相同。仅基于包含体积96和近似表面92,射线3(415)可以描绘真实物体91,或可以描绘物体111。因此,有可能(在步骤37或353)错误地将像素定位在空间位置a
′
(射线3(415)不与真实物体91相交,并且因此描绘了物体111)。
[0522]
然而,知道(例如,基于先前的处理,例如,基于对射线114和相机2114执行的方法30或350)射线114b描绘了物体元素93(并且在空间位置a
′
处没有元素),可以自动推断针对射线3(415),空间位置a
′
是不可接受,因为空间位置a
′
中的假设元素将遮挡针对相机2的物体元素93。换句话说,只要相机2(114b)看到的空间位置a'的深度比点93的深度值小至少某个预定义阈值,就可以针对相机1(94)的射线3(415)而排除空间位置a
′
。
[0523]
10.4.2基于可接受空间候选位置的基于多相机的一致性
[0524]
前一节描述了根据空间位置的一个受限范围(例如,96b)计算出的深度值的知识如何减少针对另一相机(例如,94)的可接受的候选空间位置的范围。
[0525]
但是,即使没有这样的计算出的深度值的知识,仅仅存在针对一台相机应用的包含体积就可以限制针对另一相机的可接受的候选空间位置。
[0526]
这在图42中进行了描述。在一些示例中可以考虑存在两个包含体积和一个近似表面。现在考虑来自相机2(424b)的射线425b指向近似表面422。假设没有预先计算针对射线425b的可靠深度(或其他类型的定位)。然后对于与近似表面422相交的每条射线,可接受的空间候选位置位于相交的包含体积426a和426b内。
[0527]
然而,这意味着任何物体都不能位于字母a、b和c指示的区域内。原因如下:
[0528]
如果在区域a、b或c之一中存在物体,则该物体将在相机2(424b)中可见。同时,物
体将位于包含体积1(426a)和包含体积2(426b)之外。根据定义,这是不允许的,因为我们指出无法计算可靠的深度,因此所有物体都必须位于包含体积内。因此,可以自动排除区域a、b和c中的任何物体。随后可以将这一事实用于任何其他相机,例如相机1(424a)。基本上,根据区域a、b和c获得排除体积(其中从针对相机1的受限范围排除不可接受的候选位置)。
[0529]
当物体位于区域d中(在包含体积2(426b)后面,即使相对于包含体积1(426a)在前景中),该物体也不会引起任何矛盾,因为该物体在相机2(424b)中不可见。因此,存在用户未绘制任何包含体积的物体的可能性。可以定义允许存在来自区域d的物体的策略。特别地,可以执行一种方法,包括,在定义第一近侧包含体积(426b)或近似表面和第二远侧包含体积或近似表面(422、426a)时,自动定义:
[0530]
在第一包含体积(426b)或近似表面与至少一个相机(424b)的位置之间的第一排除体积(c);以及
[0531]
在第二包含体积(426a)或近似表面(422)与至少一个相机(424b)的位置之间的第二排除体积(a,b),其中排除在第一排除体积(c)和第二排除体积(a,b)之间的非排除区域(体积d)。
[0532]
基本地,对于相机2(424b),体积d被包含体积426b遮挡,体积d实际上可以容纳物体,因此事实上不是排除体积。区域d可以由候选位置的范围或区间(例如,射线)的在包含体积2(426b)和包含体积1(426a)或近似表面422之间的位置形成,所述候选位置相比包含体积2(426b)距离相机2(424b)更远,但相比包含体积1(426a)或近似表面422距离相机2(424b)更近。因此区域d的位置是约束之间的中间位置。
[0533]
图45可以提供另一个示例,示出了在一些情况下可以与图42的示例相关的方法450。
[0534]
方法450(可以是方法30和350之一的示例)可以包括第一操作(451),其中获得与第二相机位置(424b)相关联的位置参数(不严格需要实际上获取图像)。我们注意到可以已经定义了包含体积(例如,426a、426b)(例如,由用户定义)。
[0535]
随后打算执行获取第一2d图像的物体元素的定位的方法(例如,30、350),例如,第一2d图像由相机1(424a)获取,相机1(424a)与相机2(424b)处于预定位置关系。为此目的,可以使用第二操作452(例如,其可以被理解为实施方法350)。因此,例如,第二操作452可以包括步骤353和353。
[0536]
对于第一2d图像的每个2d表示元素(例如,像素),定义射线(候选空间位置的范围)。在图42中,示出了射线425c、425d、425e,每一条射线与由相机1(424a)获取的2d图像的特定像素(可以每次都用(x0,y0)识别)相关联。
[0537]
我们从图42中看到,射线425d中的线段425d
′
中的位置(体积a、b、c内的那些位置)(例如,位置425d”)将遮挡第二2d图像中的包含体积426a和426b。因此,即使未对约束进行预定义,仍然可能从可接受空间候选的受限范围中排除425d
′
中的位置。
[0538]
我们还从图42中看到,射线425e中的线段425e
′
中的位置(体积d内的那些位置)(例如,位置425e
”′
)将被第二2d图像中的包含体积426b遮挡。因此,即使在步骤中预定义了不同的约束(图42未示出),仍然可以将425e
′
中的位置包括在可接受空间候选的受限范围内。
[0539]
这可以通过方法450的第二操作452获得。在步骤453(其可以实施步骤351)中,对
于通用像素(x0,y0),对应的射线(可以与射线425c
‑
425e中的任一个相关联)可以被关联。
[0540]
在步骤454(可以实现步骤352的至少一个子步骤),射线被限制在可接受的候选空间位置的受限范围或区间。
[0541]
尽管如此,现在正在寻找一种技术,用于进一步限制射线中的位置以随后仅处理(在37或353处)可接受的候选位置。因此,通过考虑已经针对第二相机位置提供的(例如,由用户提供的)包含体积426a和426b,可以从可接受空间位置的受限范围中排除空间位置。
[0542]
因此可以迭代步骤456和459(例如,体现步骤352)之间的循环。这里,对于每条射线425c
‑
425e,候选空间位置(这里表示为深度d)从相机1(424a)的近侧位置向远侧位置(例如,无限大)扫描。
[0543]
在步骤456,选择在可接受空间候选位置的可接受范围或区间中的第一候选d。
[0544]
在步骤457a,基于在第一操作(451)处获得的位置参数,分析候选空间位置d(例如,关联到候选空间位置,例如在射线425d中的位置425d”、或在射线425e中的425e”)是否被第二2d图像中的至少一个包含体积(426a)遮挡,如此,以确定可能的遮挡(457a
′
)。例如,对于相机1(424b),位置425e”'在包含体积426b之后(换句话说,从相机2(424b)射出的射线在与位置425e”'相交之前与包含体积426b相交;或者,对于从相机2(424b)射出并与位置425e”'相关联的射线,包含体积426b位于相机2(424b)和425e”'之间)。在这种情况下(过渡457a'),在步骤458,诸如位置425e”'(或相关联的深度d)的位置被保持在可接受的候选空间位置的受限范围内(因此,将在检索步骤353或459d处针对位置425e
”′
实际评估相似性度量)。
[0545]
如果在步骤457a,基于在第一操作(451)处获得的位置参数识别到至少一个候选空间位置d不可能被至少一个包含体积遮挡(过渡457a”),则基于在第一操作(451)处获得的位置参数分析(在步骤457b),至少一个候选空间位置(深度d)是否会遮挡第二2d图像中的至少一个包含体积(426b)。这可能发生在候选空间位置425d”,候选空间位置425d”(在随后被识别的情况下,在步骤37或353,作为最优选的候选空间位置)将遮挡包含体积426b(换句话说,从相机2(424b)射出的射线在与位置425d”相交之后与包含体积426b相交;或者,对于从相机2(424b)射出并与位置425d”相关联的射线,候选位置425d”在相机2(424b)的位置和包含体积426b之间)。在这种情况下,通过过渡457b
′
和步骤457c,从可接受空间位置的受限范围排除候选位置(例如,425d”),并且随后(在步骤353或459d处)不评估相似性度量。
[0546]
在步骤459,更新新的候选位置(例如,选择相对于先前位置更远侧的新d,即使接近先前位置),并且新的迭代开始。
[0547]
当(在459处)识别出在受限范围内没有可能的候选位置(例如d达到近似“无限”或达到近似表面的最大阈值)时,则在458d处执行最终定位(这可能理解为体现步骤353)。在这里,仅考虑那些候选位置,在458中针对获选位置已测量了相似性度量。
[0548]
10.4.3多相机一致性感知深度计算的程序
[0549]
以下程序更详细地描述了在计算给定相机的深度值时如何使用多相机一致性。在下文中,不失一般性,该相机被称为“相机1”。
[0550]
[0551]
[0552][0553]
为了能够处理第10.4.1节和第10.4.2节中阐述的所有构思,该程序以递增顺序迭代所有深度候选d。通过这些方式,一旦出现第10.4.1节中描述的第一种情况,就可以停止接受更多深度候选,其中已经定位的物体会遮挡所考虑的相机1(94)的物体。
[0554]
接下来,该程序可以本质上将由针对相机1(94、424a)的深度候选d定义的候选空间位置转换为针对第二相机c的深度候选d
′
。此外,它计算像素坐标(x',y'),在该像素坐标中候选空间位置在第二相机c中可见(相机c可以是获取已执行定位的2d图像的相机;相机c的示例可以是例如图11中的相机2(114)和图42中的相机2(424b))。
[0555]
然后,基于针对相机c的可用像素坐标(x
′
,y
′
),检查之前是否已经针对相机c(424b,114)和像素(x
′
,y
′
)计算了深度候选d
′
,该深度候选d
′
足够可靠以影响针对相机1(94,424a)的深度计算。为此可以采用不同的启发式方法。在最简单的情况下,深度候选d
′
可以仅当其置信度或可靠性值足够大时,或者当其不可靠性值足够小时才被接受。然而,也可以检查针对相机c中的像素(x',y')要检查的深度候选的数量比针对相机1(94,424a)中的像素(x0,y0)的深度候选的数量少多少。通过这些方式,可以认为针对(x',y')的深度候
选d'比针对相机1(94,424a)中的(x0,y0)的深度候选d更可靠。因此,该程序可以允许针对像素(x
′
,y
′
)的深度候选d
′
影响针对像素(x0,y0)的深度候选选择。
[0556]
然后,根据该决定,无论是否存在可靠的深度候选d
′
,程序然后考虑第10.4.1节或第10.4.2节中讨论的场景。第(28)
‑
(34)行考虑这样一种情况,其中由像素(x0,y0)和深度d定义的针对相机1(94,424a)的新物体将遮挡由(x
′
,y
′
)和深度d
′
定义的针对相机c(424b,114)的现有物体。由于这是不允许的,因此拒绝深度候选。另一方面,第(42)
‑
(50)行考虑这样一种情况,其中由像素(x0,y0)和深度d定义的相机1中的新物体将被相机2(424b,114)中的已知物体遮挡。这也是不允许的,因此所有较大的深度候选都被拒绝。
[0557]
第55ff行最后与第10.4.2节相关。
[0558]
需要注意的是,在上述程序中,检索和限制是以交错方式执行的。具体地,在第(3)
‑
(5)行中的第一限制步骤之后,剩余的行在第34、49、67行中执行附加的限制,并在第40、61、71行中计算相似性度量。必须理解这不会影响要求保护的主题。换句话说,限制和交错是否是按顺序、交错或甚至并行计算,都会导致相同的结果,因此以所要求保护的事项为准。
[0559]
然而,为了清楚起见,以下算法示出了仅执行附加限制步骤的相同构思。
[0560]
[0561]
[0562][0563]
图43提供了另一个示例(也可以参考图11和图41)。图43示出了方法430,包括:
[0564]
作为第一操作(431),定位(例如,使用任何方法,包括方法30或350)针对第二2d图像的多个2d表示元素(例如,由图11或图41中的相机2(114)、在上面的代码中的相机c......获取),
[0565]
作为第二后续操作(432):
[0566]
对于第一2d图像(例如,由图11和图41中的相机1(94)或上面代码中的“相机1”获取),针对2d表示元素(例如,与射线115或415相关联的像素)执行推导步骤(351、433)和限制步骤(352、434),以获得可接受的候选空间位置的至少一个受限范围或区间(图11:线段96a和112
′
;图41:具有射线3(415)与包含体积96的交点作为未端的线段);
[0567]
在第二2d图像的先前定位的2d表示元素中找到(352,435)与第一确定的2d表示元素的候选空间位置(例如代码中为(x0,y0),以及受限范围96a、112
′
内的位置等)相对应的元素(代码中为(x
′
,y'));
[0568]
进一步限制(352、436)可接受的候选空间位置的受限范围或区间(在图11中:通过排除线段112
′
和/或通过在位置93处停止;在图41中:通过从可接受的候选空间位置的受限范围或区间进一步排除位置a');
[0569]
在可接受的候选空间位置的进一步受限范围或区间内检索(353、437)针对第一确定的2d图像的所确定的2d表示元素(例如,代码中的(x0,y0))的最合适的候选空间位置。
[0570]
参考图11的示例:在已执行作为第一操作(431)的对由相机2(114)获取的第二2d图像的定位并已检索到物体元素93的正确位置(与特定像素(x
′
,y
′
)和射线114b相关联)等之后,现在是执行用于定位与由相机1(94)获取的第一确定的2d图像的像素相关联的位置的第二操作(432)的时候了。检查射线2(115)(与像素(x0,y0)相关联)。首先,执行推导步骤(351、433)和限制步骤(352、434),以得到由线段96a和112
′
形成的候选空间位置的受限范围或区间。扫描多个深度d(例如,从近端96
′
到远端96b,目的是随后扫描区间112
′
)。然而,当到达物体元素93的位置时,在步骤435中搜索来自第二2d图像的像素是否与元素93的位置相关联。来自第二2d图像(从相机2(114)获取)的像素(x',y
′
)被发现对应于物体93的位置。由于发现像素(x',y
′
)对应于位置93(例如,在预定的容差阈值内),得出结论第一图像(相机1(94))的像素(x0,y0)也与相同的位置(93)相关联。因此,在436,可接受的空间位置的受限范围或区间实际上被进一步限制(因为,相对于相机1(94),比物体元素93的位置更
远侧的位置被排除在可接受的空间位置的受限范围或区间之外),并且在437,在相应检索步骤之后,物体元素93的位置可以与第二图像的像素(x0,y0)相关联。
[0571]
参考图41的示例:在已执行作为第一操作(431)的对由相机2(114)获取的第二2d图像的定位并已检索到物体元素93的正确位置(与特定像素(x',y')和射线114b相关联)等之后,现在是在第二操作(436)中找到相机1的位置的时候了。候选空间位置的至少一个受限范围或区间被限制(352、434)到射线3(415)与包含体积96的交点之间的线段。对于与射线3(415)相关联的像素(x0,y0),考虑了几个深度d,例如,通过从近侧末端415
′
向远侧末端415”扫描。当深度d与位置a'相关联时,在步骤435搜索像素(x
′
,y')是否与位置a
′
相关联。找到来自第二2d图像(从相机2(114)获取)的像素(x
′
,y')以与位置a
′
相对应。然而,在第一操作431处像素(x',y
′
)已经与位置93相关联,在与像素(x
′
,y
′
)相关联的候选空间位置(射线114b)的范围内,该位置93比位置a
′
更远。因此,在步骤436(例如,352),可以自动理解,针对像素(x0,y0)(与射线3(415)相关联),位置a
′
是不可接受的。因此,在步骤436,位置a
′
被排除在可接受的候选空间位置的受限范围之外,并且在步骤437(例如,37、353)中将不计算位置a
′
。
[0572]
11.用于深度估计的可接受表面法线的限制
[0573]
虽然第10节致力于限制给定像素的可接受深度值,但近似表面还允许对表面法线施加约束。除了第10节中讨论的范围限制之外,还可以使用这种约束,这是优选方法。然而,在不限制可能的深度值的情况下对法线施加约束也是可能的。
[0574]
11.1问题表述
[0575]
深度的计算需要针对不同的深度候选而计算一些匹配成本和/或相似性度量(例如,在步骤37)。然而,由于图像中的噪声,仅考虑单个像素的匹配成本是不够的,而是考虑位于感兴趣像素周围的整个区域的匹配成本。该区域也称为集成窗口,因为为了计算感兴趣像素的相似性度量,聚合或累加位于该区域或集成窗口内的所有像素的匹配成本。在许多情况下,在计算聚合匹配成本时,假设区域中的所有像素都具有相同的深度。
[0576]
图15举例说明了这种方法,假设应计算左图像154a中的交叉像素155的深度。为此,将其像素值与右图像154b中的每个可能对应候选进行比较。然而,比较单个像素值会导致非常嘈杂的深度图,因为像素颜色受到各种噪声源的影响。作为补救,通常假设相邻像素155b将具有相似的深度。因此,将左图像中的每个相邻像素与右图像中的相应相邻像素进行比较。然后将所有像素的匹配成本聚合(相加),然后分配为左图像中的交叉像素的匹配成本。聚合匹配成本的像素数量由聚合窗口的大小定义。如果场景中的物体的表面大致前置平行于相机,则这种方法会提供良好的结果。如果不是,那么假设所有相邻像素具有大致相同的深度是不准确的,并且会导致匹配成本最小的污染:为了实现最小匹配成本,需要基于它们的真实深度值来确定对应的像素。否则,将像素与其错误的对应部分进行比较,从而增加由此产生的匹配成本。后者增加了针对深度计算选择错误最小值的风险。
[0577]
这种情况可以通过借助法线可以具有任意取向的平面而近似物体的表面来改善[9]。这对于如图16所示相对于相机的光轴强烈倾斜的表面特别有益。在这种情况下,通过考虑位置和法线,可以针对左聚合窗口(例如,154a)中的每个像素确定更准确的右侧图像(例如,154b)中的对应像素。换句话说,给定应计算深度值的像素(或其他2d表示元素)的深度候选(或其他候选定位,例如,如在步骤37、353等中处理和/或通过块363处理)和关联的
法向量,可以针对集成窗口中的所有其他像素进行计算,其中它们将位于3d空间中,假设所假定的表面平面。然后,每个像素具有这个3d位置允许在右侧图像中计算正确的对应关系。一方面,这种方法降低了可实现的最小匹配成本,从而获得了卓越的深度图质量,另一方面,它极大地增加了每个像素的搜索空间。这可能需要应用一种技术以避免搜索所有可能的法线和深度值组合。相反,选择的深度和法线组合会根据它们的匹配成本进行评估。从所有评估的深度和法线组合中,选择导致最小局部或全局匹配成本的组合作为给定像素的深度值和表面法线。然而,这种启发式方法可能会失败,从而导致错误的深度值。
[0578]
11.2使用用户提供的约束进行法线感知深度估计
[0579]
用于克服11.1节中描述的困难的一种方法是通过使用通过用户绘制的近似表面给出的信息来减少搜索空间。更详细地,近似表面的法线可以被认为是对物体表面的法线的估计。因此,不需要调查所有可能的法向量,而仅需要调查接近该法线估计的法向量。结果,对应关系确定的问题被消除了歧义并导致了卓越的深度图质量。
[0580]
为了实现这些益处,我们执行以下步骤:
[0581]
1.用户绘制(或以其他方式定义或选择)表面的粗略近似。例如,这种近似表面可以由网格组成以与现有的3d图形软件兼容。通过这些方式,近似表面上的每个点都有关联的法向量。如果近似表面是网格,则法向量可以例如仅是网格的对应三角形的法向量。由于法向量本质上定义了平面的取向,因此法向量和是等效的。因此,法向量的取向可以基于一些其他约束来定义,例如在第9.4和10节中施加的。
[0582]
2.用户指定(或以其他方式输入)容差,真实物体表面的实际法向量可以偏离从近似表面导出的法线估计。该容差可以通过相对于坐标系的最大倾斜角θ
max
来表示,在该坐标系中法向量表示z轴(深度轴)。此外,近似表面和包含体积的容差角可能不同。
[0583]
3.对于应估计深度的相机视图中的每个像素,射线与用户提供的所有近似表面和包含体积相交。如果存在这样的交点,则在交点处的该近似表面或包含体积的法向量被视为表面物体的法向量的估计。
[0584]
4.优选地,可以限制可接受的深度值的范围,如第10节和第13节所述。
[0585]
5.自动深度估计程序然后考虑法线估计,例如如第11.3节所述。
[0586]
为了避免施加错误的法线,可以将近似表面约束为仅位于物体内部而不超出物体。可以通过以与第9.3节中讨论的相同方式定义包含体积来减轻竞争约束。如果射线与近似表面和包含体积相交,则可以考虑多个法线候选。
[0587]
这可以通过图11中的射线2(115)看到。如前面部分所述,射线2可以描绘物体111的物体元素或物体91的物体元素。对于这两种可能性,预期法向量是很不一样。如果物体元素将属于物体111,则法向量将与近似表面112正交。如果物体元素将属于物体91,则法向量将与点93中的球体(91)表面正交。因此,对于由相应包含体积定义的候选空间位置的每个受限范围,可以选择并考虑不同的法向量
[0588]
对于平面近似表面(参见第9.4节),仅当与相交射线的点积为负时才应该应用对法向量的约束。
[0589]
11.3法线信息成本聚合与平面假设的使用
[0590]
这里解释了一种通过使用相似性度量来定位物体元素的方法。在所述方法中,使
用了交点处的近似表面(或包含体积)的法线向量。
[0591]
当聚合几个像素的匹配成本时,可以使用像素区域的法线估计。设(x0,y0)是相机1中的应计算深度值的像素。然后可以通过以下方式执行匹配成本的聚合
[0592][0593]
d是深度候选,是应计算相似性度量(匹配成本)的法向量候选。向量通常类似于近似表面或包含体积(96)在其与所考虑像素(x0,y0)的候选空间位置115的交点(96')处的法向量(参见第11.4节)。在检索步骤中,d和的几个值被测试。
[0594]
n(x0,y0)包含匹配成本将被聚合以计算像素(x0,y0)的深度的所有像素的。c(x,y,d)表示针对像素(x,y)和深度候选d的匹配成本。等式(3)中的和符号可以表示和,也可以表示更一般的聚合函数。
[0595]
是在由法向量表示的平面表面的假设下,基于像素(x0,y0)的深度候选d来计算像素(x,y)的深度候选的函数。为此,考虑位于3d空间中的平面。这样的平面可以用以下等式来描述:
[0596][0597]
不失一般性,令表示在相机的坐标系中,针对该坐标系,深度值应该被计算。然后在相机坐标系中表示的3d点(x,y,z)和相应的像素(x,y)之间存在简单的关系,如图17所示:
[0598][0599]
k是所谓的内参相机矩阵(并且可能包含在相机参数中),f是相机的焦距,pp
x
和pp
y
是主点的位置,s是像素剪切(shearing)因子。
[0600]
结合等式(4)和(5)得到
[0601][0602]
给定z=d(x0,y0,x,y,d)和d(x0,y0,x0,y0,d)=d,b可以计算如下:
[0603][0604]
因此,像素(x,y)的深度候选可以由下式确定:
[0605][0606]
换句话说,与深度上的1成正比的视差是x和y中的线性函数。
[0607]
通过这些方式,我们能够针对第一个相机中的每个像素(x,y)以及每个深度候选d和每个法线候选来计算深度候选d。具有这样的深度候选允许计算在第二相机中的相应的匹配像素(x
′
,y
′
)。然后可以通过比较第一相机中的像素(x,y)的值与第二相机中的像素(x
′
,y
′
)的值来更新匹配成本或相似性度量。代替该值,可以使用诸如census变换之类的推导量。由于(x
′
,y
′
)可能不是整数坐标,因此可能在比较之前进行插值。11.4在利用平面假设进行深度估计中使用法线信息
[0608]
基于第11.3节的这些关系,存在两种可能的方法来包括用户提供的法线信息,从而消除对应关系确定的歧义,并获得更大的深度图质量。在简单的情况下,假设从用户生成的近似表面中推导的法向量是正确的。在这种情况下,通过将设置为用户提供的近似表面的法向量,直接从等式(6)计算针对每个像素(x,y)的深度候选不建议对包含体积使用这种方法,因为像素射线和包含体积之间的交点处的法向量可能与像素射线和真实物体之间的交点处的法向量完全不同。
[0609]
在更高级的情况下,深度估计过程(例如,在步骤37或353)在由源自近似表面或包含体积的法向量和一些容差值定义的范围内搜索最佳可能法向量。这些容差值可以由最大倾斜角θ
max
表示。该角度可能会有所不同,取决于像素的射线与哪个近似表面或哪个包含体积相交。令是由近似表面或包含体积定义的法向量。那么这组可接受的法向量定义如下:
[0610][0611]
θ是围绕法向量的倾斜角(即,对于),θ
max
是预定阈值(相对于的最大倾斜角)。φ是方位角,其可能值设置为[0,2π]以覆盖所有可能的法向量,这些法向量偏离近似表面的法向量一角度φ。获得的向量相对于正交坐标系进行解释,该正交坐标系的第三轴(z)与平行,另外两个轴(x,y)与正交。向量使用的坐标系的转换可以通过以下矩阵向量乘法获得:
[0612][0613]
向量和中的每一个都是列向量,而和计算如下:
[0614][0615][0616]
由于该集合包含无限数量的向量,因此可以测试角度的子集。该子集可以随机定义。例如,对于每个测试向量和要测试的每个深度候选d,等式(6)可用于计算聚合窗口中的所有像素的深度候选并计算匹配成本。然后可以使用法线的深度计算程序通过最小化局部或全局匹配成本来决定每个像素的深度。在简单的情况下,对于每个像素,选择具有最小匹配成本的法向量和深度候选d(赢者全赢的策略)。可以应用替代的全局优化策略,惩罚深度不连续性。
[0617]
在这种情况下,重要的是要考虑到包含体积仅是底层物体的非常粗略的近似,除非当它们是根据近似表面自动计算出来的(参见第12节)。如果包含体积仅是非常粗略的近似,则其容差角应设置为比用于近似表面的容差角大得多的值。
[0618]
这可以在图11中再次看到。虽然包含体积96是球体(真实物体91)的相当精确的近似,但在射线2(115)和真实物体(91)之间的交点(93)处的法向量与在射线2(115)和包含体积(96)之间的交点(96')处的法向量有很大不同。遗憾的是,在限制步骤中仅后者是已知的并且将其分配给向量因此,为了将真实物体(91,93)的表面的法向量包含到法线候选集合中,确定的法向量之间存在相当大的容差角。在射线2(115)和包含体积(96)之间的交点中,需要允许可接受的候选法向量
[0619]
换句话说,空间候选位置的每个区间都可以有自己关联的法向量如果射线与近似表面相交,那么在这个近似表面所限定的空间候选位置的区间内,近似表面在其与射线的交点处的法向量可以认为是候选法向量例如,参考图48,对于位于点486a和486b之间的所有候选空间位置,选择法向量以对应于向量485a,因为近似表面通常是物体表面的相当精确的表示。另一方面,包含体积482b仅是对所包含的物体487的非常粗略的近似。此外,486c和486d之间的候选空间位置的区间不包含任何近似表面。因此,法向量只能非常粗略地估计,建议使用较大的容差角θ
max
。在一些示例中,θ
max
甚至可能设置为180
°
,这意味着近似表面的法向量完全不受限制。在其他示例中,可以使用不同的技术来尝试内插最佳可能的法线估计。例如,在图48的情况下,对于486d和486c之间的每个候选空间位置相关联的法向量可以估计如下:
[0620][0621]
其中
[0622]
·
考虑的候选空间位置
[0623]
·
与所考虑的候选空间位置相关联的法向量
[0624]
·
交点486d
[0625]
·
交点486c
[0626]
·
包含体积在交点486c处的法向量485c
[0627]
·
包含体积在交点486d处的法向量485d
[0628]
如果射线不与任何近似表面相交,则没有法线候选可用,并且深度估计器的行为与往常一样。
[0629]
方法440在图44中示出。在步骤441,在第一图像中考虑像素(x0,y0)(例如,与射线2(145)相关联)。因此,在步骤442,推导步骤352和限制步骤353允许将候选空间位置的范围或区间(最初是射线2(145))限制到可接受的候选空间位置149的受限范围或区间(例如,在第一近端(即相机位置)与第二远端(即射线2(145)和近似表面142之间的交点)之间)。然后在443,在可接受的候选空间位置149的范围或区间内选择新的候选深度d。找到垂直于近似表面142的向量在444,从候选向量中选择候选向量(其与在预定的角度容差内形成角度)。然后,在445处获得(例如,使用公式(7))深度候选然后,在446处得到更新。在447处验证是否存在其他候选向量要处理(如果是,则在444处选择新的候选向量在448,验证是否存在其他候选深度d要处理(如果是,则在443选择新的候选深度)。最后,在449,可以比较和以便选择与最小相关联的深度d和法线
[0630]
12从近似表面自动创建包含体积
[0631]
该方法给出了如何从近似表面推导包含体积以解决相互竞争的近似表面并定义可接受的深度范围的一些示例。需要注意的是,所有呈现的方法都只是示例,其他方法也是可能的。
[0632]
12.1通过缩放封闭体积近似表面来计算包含体积
[0633]
参考图18,可以通过相对于缩放中心182a缩放近似表面186,来从近似表面186生成包含体积186,例如上文和下文的至少一些包含体积。对于网格的每个控制点(顶点),计算该控制点和缩放中心之间的向量并将其按常数因子延长以计算控制点的新位置:
[0634][0635]
虽然非常简单,但该方法的特征是对应表面元素之间的距离不是恒定的,而是取决于到缩放中心182a的距离。对于非常复杂的近似表面,生成的缩放体积与近似表面相交,这通常是不希望的。
[0636]
12.2从平面近似表面计算包含体积
[0637]
当近似表面186是封闭体积时,第12.1节中描述的简单方法特别有效。封闭体积可以理解为网格或结构,其中所有网格元素(如三角形)的每条边都具有偶数个相邻网格元素。
[0638]
如果不满足该属性,则需要稍微更改方法。然后,对于仅连接到一个网格元素的所有边,需要插入附加的网格元素,将它们与原始边连接起来,如图19所示。
[0639]
12.3网格移动和新控制点和网格元素的插入
[0640]
虽然第12.1和12.2节中讨论的方法易于实现,但由于固有的局限性,它们通常不会被普遍应用。因此,下面将描述一种更先进的方法。
[0641]
假设如图20所示的表面网格200。表面网格200是包括顶点(控制点)208、边200bc、200cb、200bb和表面元素200a
‑
200i在内的结构。每条边连接两个顶点,并且每个表面元素被至少三条边围绕,并且存在从每个顶点到结构200的任何其他顶点的边的连接路径。每条边可以连接到偶数个表面元素。每条边可以连接到两个表面元素。该结构可以占据没有边界的封闭结构(结构200,不是封闭结构,可以理解为封闭结构的缩小部分)。即使图20看起来是平面,也可以理解结构200在3d中延伸(即,顶点208不必全部共面)。具体地,一个表面元素的法向量可以不同于任何其他表面元素的法向量。
[0642]
定义表面网格200的法向量都指向相应3d物体的外部。网格200的外表面可以被理解为近似表面202,并且可以体现上文讨论的近似表面之一(例如,近似表面92)。
[0643]
然后可以通过将所有网格元素(如三角形)或表面元素200a
‑
200i沿着它们的法向量移动用户定义的值来生成包含体积。
[0644]
例如,在从图20到图21的过渡中,表面元素200b已经沿其法线平移了用户定义的值r。图20和图21中的法向量具有三个维度,并且因此以某种方式指向离开纸平面的第三维度。例如,与图20中的表面200cb连接的表面200bc现在与图21中的表面200cb分离。在该步骤中,先前连接的所有边都可以通过相应的网格元素重新连接,如图22所示。例如,点211c通过线段211
′
连接到点211bc以形成两个新元素210cb和210bc。这些新元素将先前连接的边200bc和200cb互连(图20),它们通过沿法线的移动而断开(图21)。我们还注意到,在图20中,定义了控制点210,其连接到多于两个的网格元素(200a
‑
200i)。接下来,如图23所示,针对连接到多于两个的网格元素的每个先前控制点(例如,210),可以插入重复的控制点(例如,220),例如先前控制点210的所有新位置的平均值。(在图22中,新元素以全色着色,而旧元素未着色。)
[0645]
最后,如图24所示,复制的控制点220可以与附加的网格元素(例如,200a
‑
200i)连接到每条边,所述每条边重新连接源自相同源控制点的控制点。例如,复制的控制点220连接到控制点211c和211d之间的边241,因为它们都对应于相同的源点210(图20)。
[0646]
在原始近似表面200不闭合的情况下,对于连接到奇数个网格元素的所有边,可以插入将它们与原始边连接的附加网格元素。
[0647]
上述程序可能导致网格元素相互交叉。这些相交可以通过某种形式的网格清理来解决,其中与另一个三角形相交的所有三角形沿着相交线切割成多达三个新三角形,如图25和图26所示。然后可以去除完全包含在创建的网格的另一体积中的所有子体积。
[0648]
在如此修改的网格200的外表面内占据的体积可以用作包含体积206,并且可以体
现上面讨论的包含体积之一(例如,在图9中,包含体积96,从近似表面92生成)。
[0649]
一般而言,一个包含体积(例如,96、206)的至少一部分可以从结构(例如,200)开始形成,并且其中至少一个包含体积(例如,96、206)通过以下方式获得:
[0650]
通过沿至少一些元素(例如,200a
‑
200i)的法线分解所述至少一些元素(例如,200a
‑
200i)来移动元素(例如,200a
‑
200i)(例如,从图20到图21);
[0651]
通过生成附加元素(例如,210bc、210cb)重新连接在移动之前已连接并因移动而断开连接的元素(例如,200b、200c)边(200bc、200cb)(例如,从图21到图22);和/或
[0652]
在原始结构中的已连接到多于两个的网格元素的每个控制点(210)的分解区域(例如,200
′
)内插入新的控制点(例如,220)(例如,从图22到图23);
[0653]
通过构建对新的控制点(例如,220)和起源于同一源控制点(210)的两个控制点(211d、211c)进行连接的并且其各个连接边(210bc、210cb)是邻居的三角形网格元素(220bc),将新控制点(例如,220)与分解元素(例如,210bc)重新连接以形成另外的元素(例如,220bc)(例如,从图23到图24)。
[0654]
13排除体积约束
[0655]
13.1原理
[0656]
第9至12节中讨论的方法通过提供相关物体的粗略模型来直接精细化深度图。这种方法对用户来说非常直观,并且接近当今的工作流程,其中3d场景通常由3d技术人员重建。
[0657]
然而,有时通过定义没有3d点或物体元素的区域来排除深度值是更直观的。此类约束可以由排除体积定义。
[0658]
图27示出了相应的示例。它图示了包含多个物体271a
‑
271d的场景,这些物体可以由不同的相机1和2(274a和274b)观察以执行定位处理,例如深度估计和3d重建。如果深度(或其他定位)估计错误,则点在3d空间中定位错误。通过场景理解,用户通常可以快速识别这些错误点。然后他可以在3d空间中绘制或以其他方式定义体积279(所谓的排除体积或排除体积),该体积279指示没有放置物体的位置。例如,深度估计器可以使用该信息来避免深度估计中的歧义。
[0659]
13.2通过封闭体积明确用户指定的排除区域
[0660]
为了定义不应存在3d点或物体元素的区域,用户可以绘制或以其他方式定义封闭的3d体积(例如,使用约束定义器364)。封闭的体积可以直观地理解为当体积被置于水下时水不能渗透到其中的体积。
[0661]
这种体积可以具有简单的几何形状,例如长方体或圆柱体,但更复杂的形状也是可能的。为了简化计算,这些表面的体积可以用三角形网格来表示(例如,如图20至图24所示)。独立于实际表示,这种排除体积的表面上的每个点都可能有关联的法向量为了简化后面的计算,法向量可以以这样的方式定向,即它们全部指向体积的外部,或者指向体积的内部。在下文中,我们假设法向量都指向体积279的外部,如图28所示。深度的计算涉及到(range from)排除体积。
[0662]
排除体积允许限制相机视图的每个像素的可能深度范围。通过这些方式,例如,可以减少深度估计的歧义。图29描绘了具有多个排除体积299a
‑
299e的对应示例。为了计算图
像的每个像素的可能深度值,射线295(或候选位置的另一范围或区间)可以从像素投射通过相机294的节点。然后该射线295可以与体积表面(例如,以类似于图8至图14的方式)相交。交点i0
′‑
i9
′
可以(至少表面上)在射线275的两个方向上完成,尽管光仅从右侧进入相机(因此点i0'
‑
i2
′
被排除)。逆射线上的交点i0
′‑
i2
′
与相机294的距离为负。所有找到的交点i0
′‑
i9
′
(可接受的候选位置的多个受限范围或区间的末端)然后按距离递增排序。
[0663]
令n是找到的交点的数量(例如,在图29的情况下为9),并且r是描述来自相机入瞳的射线方向的向量。令depth_min为全局参数,其定义了物体可以从相机获得的最小深度。令depth_max为全局参数,其定义了物体可以从相机获得的最大深度(可以是无穷大)。
[0664]
下面给出了计算给定像素可能的深度值集合的过程(该集合形成可接受的候选位置的受限范围或区间)。
[0665]
[0666]
[0667][0668]
必须注意的是,与第10.1节类似,对于深度可以由自动程序确定为具有大于或等于用户提供的阈值c0的可靠性或置信度的那些像素,可以被忽略排除值。换句话说,如果针对已计算出具有足够可靠性的深度值的给定像素,则其深度值不改变,并且不针对该像素执行前述程序。
[0669]
13.4在深度估计程序中使用排除体积
[0670]
深度估计器(例如,在步骤37或353或通过块363)可以计算每个深度的匹配成本(参见第5节)。因此,通过将不允许的深度的成本设置为无穷大,可以容易地使用排除体积进行深度估计(或其他定位)。
[0671]
13.5排除体积的定义
[0672]
排除体积可以通过基于3d图形软件的方法来定义。它们可以以网格的形式表示,例如图20至图24中所示的那些,它们可以基于三角形结构。
[0673]
备选地,替代直接在3d图形软件中绘制闭合体积,也可以从3d表面推导闭合体积。然后可以通过任何方法将该表面挤压成体积。
[0674]
13.6通过表面网格排除区域的规范
[0675]
除了指定被体积排除的区域外,它们也可以被表面排除。然而,这样的表面仅对可用相机的子集有效。这在图30中示出。假设用户放置(例如,使用约束定义器364)表面309并声明该表面没有留下任何物体(因此该表面是排除表面)。虽然这个陈述对于相机1(304a)肯定有效,但对于相机2(304b)是错误的。这个问题可以通过指示表面309仅被考虑用于相机1(304a)来解决。因为这更复杂,所以它不是优选方法。
[0676]
13.7排除体积与近似表面和包含体积的组合
[0677]
排除体积可以与近似表面和包含体积相结合,以进一步限制可接受的深度值。
[0678]
13.8自动创建排除体积以用于多相机一致性
[0679]
10.4节介绍了如何基于多个相机进一步精细化约束的方法。该方法本质上考虑两种情况:首先,在可以针对第一相机中的第一物体计算出可靠的深度的情况下,避免在第二相机中计算出的深度值会以第二物体遮挡第一相机中的第一物体的方式放置第二物体。其次,如果针对第一相机中的第一物体不存在这种可靠的深度,那么可以理解,第一相机中的第一物体的深度值受到与第一相机中第一物体相关的包含体积和近似表面的约束。这意味着对于第二相机不允许以第二物体会遮挡第一物体在第一相机中的所有包含体积和近似表面的方式计算第二物体的深度值。
[0680]
通过自动创建排除体积,可以以替代方式表达第10.4节的构思。这在图37中示出。基本思想包括创建排除体积(例如379)以防止物体被放置(在步骤37)在相机374a和像素射线的第一相交的包含体积376之间。此外,甚至可以防止将物体放置在包含体积之间。然而,这种方法将要求用户已用包含体积围绕每个物体,这通常不是这种情况。因此,尽管有可能(另请参见第10.4.2节),但在下文中不会详细考虑这种情况。
[0681]
下面描述了创建排除体积以防止相机和每个相机射线的相关第一相交包含体积之间出现物体的程序。假设包含体积由三角形或平面网格元素描述。
[0682]
[0683]
[0684][0685]
该程序的核心思想在于针对每个像素(或其他2d表示元素)找到与由所考虑的像素和相机入瞳或节点定义的射线相交的第一包含体积。然后,相机和这个相交的包含体积之间的所有空间位置都是不可接受的,并且因此在射线也与近似表面相交的情况下可以排除。否则,可以忽略包含体积,如第10.1节所述。
[0686]
基于这个基本思想,现在的挑战在于将所有不同的像素射线分组到以网格形式描述的紧凑的排除体积中。为此,先前的程序创建了两个像素映射(pixel map)i_1和i_2。像素映射i_1针对每个像素定义了与由相应射线相交的最近包含体积的标识符。值为零意味着没有包含体积已经被相交。像素映射i_2针对每个像素定义了与由相应射线相交的最近近似表面的标识符。零值意味着没有近似表面已经被相交。组合像素映射i_3最终针对每个像素定义了与由相应射线相交的最近包含体积的标识符,假设近似表面也已经被相交。否则像素映射值等于零,这意味着没有相关的包含体积已经被相交。
[0687]
第14
‑
25行然后负责创建包含体积的副本,其中仅保留在相机c_i中可见的那些部分。或者换句话说,仅保留包含体积的部分,这些部分到相机c_i的投影与i_3中的映射值等于包含体积的标识符的那些像素重合。第26行到第37行最终通过将相关边与相机的节点连接起来,来从那些剩余的网格中形成排除体积。相关边是位于复制的包含体网格边界处的边。
[0688]
更一般地,在图37的示例中(除了这里不感兴趣的包含体积376b之外),参考两个相机1和2(374a和374b),已经针对物体371(未示出)定义了包含体积376,例如,通过用户手动定义。此外,已经(例如由用户手动)针对物体371b(未示出)定义近似表面372b。可能存在自动创建排除体积379的可能性。事实上,由于包含体积376由相机1(374a)成像的事实,可以先验地推断出没有物体位于包含体积2(372)和相机1(374a)之间。这样的结论可能取决于相应的射线是否与近似表面相交的事实。这种限制可以从第10.1节的枚举项2得出结论,建议在射线(或其他候选位置范围)不与近似表面相交的情况下忽略包含体积。必须注意,在自动预先计算的视差值(34、383a)的可靠性小于所提供的用户阈值c0的情况下,这个创建的排除体积可能是特别相关的(并且在一些情况下,仅相关)。因此,当限制候选空间位置的区间范围(可以是从相机2(374b)射出的射线375)时,可接受的候选空间位置的受限范围可以包括两个区间(例如,两个不相连的区间):
[0689]
‑
从相机374b的位置到排除体积379的第一近侧区间375';以及
[0690]
‑
从排除体积379朝向无限远的第二远侧区间375”。
[0691]
因此,当检索可接受空间位置的受限范围时(例如,在37或353处或通过块363,或通过其他技术),将避免(并且不会处理)排除体积379内的位置。
[0692]
在其他示例中,排除体积可以由用户手动生成。
[0693]
一般而言,限制(例如,在35、36、352处、通过块362等)可以包括找到候选位置的范
围或区间与至少一个排除体积之间的交集。限制可以包括用包含体积、排除体积、近似表面中的至少一个来找到候选位置的范围或区间的末端。
[0694]
14检测深度图错误的方法
[0695]
为了能够将3d物体放置在最佳可能位置以改进深度图,用户需要能够分析发生深度图错误的位置。为此,可以使用不同的方法:
[0696]
·
当深度图包含孔洞(缺少深度值)时发生最容易的情况。为了纠正这些伪影,用户需要绘制3d物体,这些3d物体帮助深度估计软件填充这些孔洞。需要注意的是,通过应用不同种类的一致性检查,可以在孔中转换错误的深度值。
[0697]
·
也可以通过查看深度或视差图像本身来检测大的深度图错误。
[0698]
·
最后,可以通过将虚拟相机放置在不同位置并基于光场程序执行视图渲染或显示来识别深度图错误。下一节将对此进行更详细的说明。
[0699]
14.1基于视图渲染或显示的粗深度图错误检测
[0700]
图39示出了实现如何基于视图渲染或显示来确定错误位置的程序的过程390(也参见图38)。为此,用户可以执行自动深度图计算(例如,在步骤34)。生成的深度图391
′
(例如,383a)在392处用于使用视图渲染或显示创建新的虚拟相机视图392
′
。基于合成结果,在393,用户可以识别(例如,视觉上)哪些深度值对合成结果392
′
中可见的伪影有贡献(在其他示例中,这可以自动执行)。
[0701]
因此,用户可以输入(例如,在384a)约束364
′
,例如排除候选空间位置的部分范围或区间,意图排除明显无效的位置。因此,可以获得深度图394(具有约束364
′
),以便获得可接受的空间位置的受限范围。然后可以通过上述方法380处理相关物体(具体参见前面的部分)。否则,可以执行新的视图渲染或显示395以确认是否可以有效消除伪影,或者是否需要改进用户约束。
[0702]
图31示出了基于图像的视图渲染或显示的示例。每个矩形对应于相机视图(例如,2d先前处理的2d图像,例如第一或第二2d图像363或363b,并且其可能已经由诸如相机94、114、124、124a、134、144、274a、274b、294、304a、304b等相机获取)。实心矩形313a
‑
313f表示由真实相机(例如,94、114、124、124a、134、144、274a、274b、294、304a、304b等)以彼此预定的位置关系获取的图像,而虚线矩形314定义了要合成的虚拟相机图像(使用确定的深度图,或图像313a
‑
313f中的物体元素的定位)。箭头315a和315e
‑
315f定义了用于渲染或显示虚拟目标视图314的相机(此处为313a和313e
‑
313f)。可以看出,并非所有的相机视图都需要被选择(这可以遵循来自用户的选择或来自自动渲染或显示程序的选择)。
[0703]
如图32所示,当用户(例如,在步骤38或351)发现视图渲染或显示伪影时,他可以通过标记工具316来标记相应的区域。用户可以进行操作,使得标记区域包含错误的像素。为了简化用户的操作,标记区域316还可以包含被正确渲染的一些像素(或其他2d表示元素)(但是由于用户所做的标记的接近性,被正确渲染的一些像素恰好在标记区域中)。换句话说,标记不需要非常精确。伪影区域的粗略标记就足够了。仅正确像素的数量不应该太大,否则分析的精度会降低。
[0704]
然后,视图渲染或显示程序可以标记对标记区域有贡献的所有源像素(或其他2d表示元素),如图32所示,基本上识别与标记的错误区域316相关联的区域316d、316e、316f'和316f”。这是可能的,因为视图渲染或显示程序基本上已经基于源像素的深度值将源相机
视图(313a、313d
‑
313f)的每个像素移动到虚拟目标视图(314)中的位置。然后移除314中被其他像素遮挡的所有像素。换句话说,如果来自图像313a
‑
313f的多个源像素被渲染到目标视图314中的相同像素,则仅保留与虚拟相机距离最小的那些。如果几个像素具有相同的距离,则它们被合并或混合,例如通过计算具有相同最小距离的所有像素的平均值。
[0705]
因此,通过简单地跟踪哪个像素对错误区域有贡献,视图渲染或显示程序可以识别源像素。源区域316d、316e、316f
′
和316f”不需要连接,尽管错误标记是连接的。基于对场景的语义理解,用户可以轻松识别哪些源像素不应该对标记区域做出贡献,并采取措施来纠正它们的深度值。
[0706]
14.2基于视图渲染或显示的小深度图错误检测
[0707]
当一些深度值与其正确值相当不相同时,上述错误检测效果很好。但是,如果深度值仅偏离很小的值,则标记的源区域将是正确的,尽管视图渲染或显示会变得模糊或显示小伪影。
[0708]
然而,可以执行与上述类似的方法。在源区域正确的情况下,这意味着深度值近似正确,但需要精细化以获得更清晰的视图渲染或显示或更少的伪影。因此,用户需要采取措施来改善指示源区域的深度图。
[0709]
15在3d空间中创建位置约束的方法
[0710]
本节描述用户界面和用户如何在3d编辑软件中创建近似表面的一些一般策略。
[0711]
注意,图4至图14和图29、图30、图37、图41、图49等可以被理解为基于例如在步骤34获得的先前粗略定位向用户显示的图像(例如,2d图像)(例如,通过与约束定义器364相关联的gui)。用户可以看到图像并且可以暗示使用上文和/或下文的方法之一来精细化它们(例如,用户可以图形地选择约束,例如近似表面和/或包含体积)。
[0712]
15.1问题表述
[0713]
为了能够以交互方式改进深度图,用户可以创建与捕获的镜头尽可能接近地匹配的3d(例如,使用约束定义器363)几何约束。
[0714]
可以通过多种方式创建3d几何图形。更可取的方法是使用任何现有的3d编辑软件。由于这种方法是众所周知的,下面不再详述。相反,我们考虑基于一个、两个或多个2d图像绘制3d几何图形的方法。
[0715]
15.2基本概念
[0716]
由于我们有相同场景的多张照片316a
‑
316f,用户可以选择其中的两张或更多张照片以在3d空间中创建约束。然后可以在图形用户界面的窗口中显示这些图像中的每一个(例如,由约束定义器364操作)。然后,用户通过将3d几何图元的2d投影与几何图元应建模的2d图像的部分进行重叠,在这两个2d图像中定位3d几何图元的2d投影。由于用户在两个图像中定位几何图元投影,几何图元也位于3d空间中。
[0717]
为了确保绘制的3d几何图元永远不会超出物体并且仅包含在物体内部,绘制的3d几何图元可能在之后相对于相机的光轴移动一点。同样,有多种方法可用于实现这些目标。在下文中,我们将介绍该构思的扩展,以简化创建和编辑过程。
[0718]
15.3恒定坐标投影模式下的单相机编辑
[0719]
在这种绘图模式下,用户定义了可以任意放置的3d参考坐标系。然后用户可以选择应该具有固定值的坐标。在单个相机视图窗口中绘制2d物体时,创建3d物体,该3d物体的
投影指向相机窗口中显示的2d物体,并且固定坐标具有定义的值。请注意,通过这种方法,3d物体在3d空间中的位置是唯一定义的。
[0720]
假设投影的2d图像的坐标用u和v标记。参考坐标系中3d坐标的计算可以通过反转以下关系来实现:
[0721][0722][0723]
k是相机内参矩阵,r是相对于3d参考坐标系的相机旋转矩阵。由于坐标x,y,z之一是固定的,并且u和v也已给定,因此三个方程还剩下三个未知变量,从而得到唯一解。
[0724]
15.4多相机严格外极编辑模式
[0725]
严格的外极编辑模式是一种非常强大的模式,以根据捕获的相机视图将3d物体放置在3d空间中。为此,用户需要打开两个相机视图窗口并选择两个不同的相机。这两个相机应该示出要在3d空间中进行部分建模的物体,以帮助深度估计。
[0726]
参考图33,允许用户选取网格、线或样条的控制点(例如三角形的角部点)330并将其在选定的相机视图的像素坐标系(在图像空间中也称为uv坐标系)中移动。换句话说,选定的控制点被投影到选定的相机视图/被选定的相机视图成像,然后用户被允许在图像坐标系中移动这个投影的控制点。然后以这样的方式调整控制点在3d空间中的位置:使其在相机视图上的投影对应于用户选择的新位置。然而,通过假设另一个相机视图(335
′
)中的相同控制点(330
′
)的位置不改变,图像坐标系中的可能移动受到限制。因此,仅允许用户沿着所选择的相机对的外极线331改变相机1中的控制点。换句话说,给定在相机视图1(335)中由点330和在相机视图2(335)中由点330
′
描绘的3d网格的控制点,假设在相机视图2(335
′
)中控制点位置330
′
已经在显示所需物体元素的右侧像素上。然后用户以这样的方式移动相机视图1中的控制点位置330:使得其位置与同相机视图2的物理元素相同的物体元素匹配。通过这些方式,用户可以精确地设置修改的控制点的深度。
[0727]
因此,可以定义一种方法,包括:
[0728]
选择空间的第一2d图像(例如,335)和空间的第二2d图像(例如,335
′
),其中第一2d图像和第二2d图像已经在彼此预定位置关系的相机位置处被获取;
[0729]
至少显示第一2d图像(例如,335),
[0730]
引导用户选择第一2d图像(例如,335)中的控制点,其中所选择的控制点(例如,330)是形成近似表面或排除体积或包含体积的结构(例如,200)的元素(例如,200a
‑
200i)的控制点(例如,210);
[0731]
引导用户选择性地平移第一2d图像(例如,335)中的所选择的点(例如,330),同时限制该点沿着第二2d图像(例如,335')中的与点(例如,330
′
)相关联的外极线(例如,331)移动,其中点(例如,330
′
)与同点(例如,330)相同的结构(例如,200)的元素(例如,200a
‑
200i)的控制点(例如,210)相对应,
[0732]
以便定义结构(例如,200)的元素(例如,200a
‑
200i)在3d空间中的移动。
[0733]
15.5多相机自由外极编辑模式
[0734]
在该示例中,用户选择显示在两个窗口中的两个不同的相机视图。这两个相机彼此具有预定的空间关系。这两个图像示出了物体,该物体应至少部分地在3d空间中建模以帮助深度估计。
[0735]
与之前的节类似,参考图34,考虑在相机视图1(345)中的位置340处和相机视图2中的位置340
′
处成像的网格控制点。然后,用户被允许在相机视图1(345)中选取网格、线或样条的控制点340并将其在图像空间或图像坐标系中移动。虽然之前示例的严格外极编辑模式假设控制点340'在第二相机视图中的位置固定,但本示例的自由外极编辑模式假设第二相机视图中的控制点340
′
尽可能少地移动。换句话说,用户可以自由地移动相机视图1中的控制点,例如,从340到341。然后以这样的方式计算控制点的深度值:相机视图2(345')中的控制点需要尽可能少地移动。
[0736]
从技术上讲,这可以通过计算由相机视图1中的控制点的新位置341给出的外极线342来实现。然后调整相机视图2中的控制点,使其位于该外极线342上,但到其原始位置的距离最小。
[0737]
因此,可以定义一种方法,包括:
[0738]
选择空间的第一2d图像(例如,345)和空间的第二2d图像(例如,345
′
),其中第一2d图像和第二2d图像已经在彼此预定义的位置关系的相机位置处被获取;
[0739]
至少显示第一2d图像(例如,345),
[0740]
引导用户选择第一2d图像(例如,345)中的第一控制点(例如,340),其中第一控制点(340)与形成近似表面或排除体积或包含体积的结构(例如,200)的元素(例如,210a
‑
200i)的控制点(例如,210)相对应;
[0741]
从用户获得与第一2d图像(例如,345)中的第一控制点的新位置(例如,341)相关联的选择;
[0742]
将控制点(例如,210)的空间中的新位置限制为第二2d图像(例如,345')中的与第一2d图像(例如,345)中的第一控制点的新位置(例如,341)相关联的外极线(例如,342)上的位置,并将空间中的新位置确定为外极线(例如,342)上的最接近第二2d图像(例如,345
′
)中的初始位置(例如,340')的第二控制点的位置(例如,341
′
),
[0743]
其中第二控制点(例如,340
′
)与同第一控制点(例如,340)相同的结构(例如,200)的元素(例如,200a
‑
200i)的相同的控制点(例如,210)相对应,
[0744]
以便定义结构(例如,200)的元素(例如,200a
‑
200i)的移动。
[0745]
15.6与用户交互的通用技术
[0746]
参考以上示例,可以执行以下过程:
[0747]
‑
首先,根据多个视图(例如,根据2d图像313a
‑
313e)执行粗略定位(例如,在步骤34);
[0748]
‑
然后,至少一个图像(例如,虚拟图像314和/或图像313a
‑
313f中的至少一个)被可视化或渲染;
[0749]
‑
用户进行目视检查以识别错误区域(例如,虚拟图像314中的314,或图像313a
‑
313f中的任何区域316d、316e、316f'、316f”)(备选地,可以自动执行检查);
[0750]
‑
例如,用户通过根据图像语义理解,区域316f”永远不会对区域316中的显示的物体做出贡献(这可能是例如由图5和图6中所示的与遮挡物体相关的问题之一产生的),从而
理解区域316f”错误地对区域316的渲染或显示做出了贡献;
[0751]
‑
为了应对,用户(例如,在步骤35或351)设置了一些约束,例如:
[0752]
○
至少一个近似表面(例如92、32、142、182、372b等),例如针对区域316f”中所示的物体(在一些示例中,近似表面可以自动生成包含体积,如图18和图20至图24的示例中那样;在一些示例中,近似表面可以与其他值相关联,例如图14示例中的容差值t
o
);和/或
[0753]
○
至少一个包含体积(例如,86、96、136a
‑
136f、376、376b等),例如针对区域316f”中所示的物体(在一些示例中,如图37中所示,一个相机的包含体积376的定义可能导致自动创建排除体积379);和/或
[0754]
○
至少一个排除体积(例如,299a
‑
299e、379等),例如在区域316f”中所示的物体和另一个物体之间;
[0755]
○
例如,用户可以手动创建与区域316f'和316f”相对应的包含体积(例如,在区域316f'和316f”中的物体周围)、或区域316f'和316f”之间的排除体积、或与区域316f'和316f”相对应的近似表面(例如,在区域316b'和316b”中的物体内);
[0756]
‑
在已设置约束之后,候选空间位置的范围被限制在可接受的候选空间的受限范围内(例如,在步骤351)(例如,区域316f'和316f”之间的区域可以从可接受的候选空间位置的受限范围中排除);
[0757]
‑
随后,相似性度量可以仅在可接受的候选空间位置的受限范围内处理,以便更正确地定位区域316f'和316f”中的物体元素(以及与标记区域316相关联的其他区域中的物体元素)(备选地,它们可以已在之前的运行中存储,并且现在可以重复使用);
[0758]
‑
因此,图像313f和314的深度图被更新;
[0759]
‑
可以重新启动该过程,或者在用户满意的情况下,可以存储所获得的深度图和/或定位。
[0760]
16建议解决方案的优点和更多示例
[0761]
·
见第6节
[0762]
·
适用于广泛的深度估计程序
[0763]
·
从同一用户输入推导多种约束类型(深度范围、法线范围)
[0764]
·
使用标准3d图形软件生成用户约束。通过这些方式,用户获得了一个非常强大的工具集来绘制用户约束
[0765]
16.1其他示例
[0766]
一般而言,可以实施以上讨论的策略以精细化先前获得的深度图(或至少先前定位的物体元素)。
[0767]
例如,可以实现以下迭代程序:
[0768]
‑
根据先前步骤,提供深度图,或提供物体元素(例如,93)的至少一个定位;
[0769]
‑
使用深度图或定位的物体元素,测量可靠性(或置信度)(例如,如[17]中所述);
[0770]
‑
如果可靠性低于预定阈值c0(定位不满意),则执行新的迭代,例如,通过:
[0771]
○
基于预定义的位置关系推导成像空间元素(例如,93)的候选空间位置(例如,95)的范围或区间;
[0772]
○
将候选空间位置的范围或区间限制(例如,35、36)到可接受的候选空间位置的至少一个受限范围或区间(例如,93a),其中限制包括以下约束中的至少一种:
[0773]
■
使用围绕至少一个确定物体(例如,91)的至少一个包含体积(例如,96)来限制候选空间位置的范围或区间(例如,包含体积可以由用户手动定义);和/或
[0774]
■
使用包括不可接受的候选空间位置的至少一个排除体积(例如,手动定义或如图37中定义的)来限制候选空间位置的范围或区间;和/或
[0775]
■
定义(例如,由用户手动)至少一个近似表面(例如,142)和一个容差区间(例如,t0),以便将候选空间位置的至少一个范围或区间限制为由容差区间定义的候选空间位置(例如,147)的受限范围或区间,其中容差区间具有:
[0776]
由至少一个近似表面(例如,142)定义的远端(例如,143
”′
);以及
[0777]
基于容差区间定义的近端(例如,147');以及
[0778]
■
基于相似性度量,在受限范围或区间的可接受的候选空间位置中检索最合适的候选空间位置
[0779]
○
基于相似性度量,在受限范围或区间(例如,93a)的可接受的候选空间位置中检索(例如,37)最合适的候选空间位置(例如,93)。
[0780]
所述方法可以重复(如图3),以增加可靠性。因此,可以精细化先前的粗略深度图(例如,即使使用另一种方法获得)。用户可以创建约束(例如,近似表面和/或包含体积和/或排除体积),并且可以在目视检查之后通过指示需要以更高可靠性处理的先前获得的深度中的不正确区域来进行补救。用户可以容易地插入这样的约束,这些约束随后用上述方法自动进行处理。因此,没有必要精细化整个深度图,而可以简单地将相似性分析限制在深度图的一些部分,从而减少用于精细化深度图的计算工作量。
[0781]
因此,上述方法是用于在包含至少一个确定物体的空间中定位与该空间的确定的2d图像中的特定2d表示元素相关联的物体元素的方法的示例,所述方法包括:
[0782]
获得成像空间元素的空间位置;
[0783]
获得成像空间元素的该空间位置的可靠性值或不可靠性值;
[0784]
在可靠性值不符合预定义的最小可靠性或不可靠性不符合预定义的最大不可靠性的情况下,执行前述权利要求中任一项所述的方法。
[0785]
也可以基于图14的示例实现迭代方法。例如,用户可以针对物体141选择近似表面142并定义预定容差值t0,其随后将确定可接受的候选位置的受限范围或区间147。从图14可以理解,区间147(以及容差值t0)应该足够大以包围物体141的真实表面。然而,存在区间147太大而包含另一个非预期的不同物体的风险。因此,如果结果不令人满意,则可以有迭代解决方案,在该迭代解决方案中降低(或在其他情况下增加)容差值。在一些示例中,可以验证可靠性(例如,如[17]中的)是否符合预定义的最小可靠性或不可靠性不符合预定义的最大不可靠性,并使用不同的容差值(例如,增加或降低容差值t0)。
[0786]
一般而言,上述方法可以允许获得一种用于在包含至少一个确定物体的空间中精细化与该空间的确定的2d图像中的特定2d表示元素相关联的物体元素的定位的方法,所述方法包括根据前述权利要求中任一项所述的方法,其中在限制时,由用户选择至少一个包含体积、至少一个近似表面和至少一个近似表面中的至少一个。
[0787]
17另外的示例
[0788]
通常,示例可以被实现为具有程序指令的计算机程序产品,当计算机程序产品在计算机上运行时,程序指令可操作以用于执行方法之一。程序指令可以例如存储在机器可
读介质上。
[0789]
其他示例包括存储在机器可读载体上的用于执行本文描述的方法之一的计算机程序。换句话说,因此方法的示例是具有程序指令的计算机程序,当该计算机程序在计算机上运行时,该程序指令用于执行本文描述的方法之一。
[0790]
因此,方法的另一个示例是数据载体介质(或数字存储介质,或计算机可读介质),包括其上记录的用于执行本文描述的方法之一的计算机程序。数据载体介质、数字存储介质或记录介质是有形和/或非瞬时性的,而不是无形和瞬时的信号。
[0791]
因此,所述方法的另一个示例是数据流或信号序列,其表示用于执行本文描述的方法之一的计算机程序。数据流或信号序列例如可以通过数据通信连接(例如通过互联网)传输。
[0792]
另一个示例包括处理装置,例如计算机,或执行本文描述的方法之一的可编程逻辑设备。
[0793]
另一示例包括其上安装有用于执行本文描述的方法之一的计算机程序的计算机。
[0794]
另一个示例包括向接收器传送(例如,电子地或光学地)用于执行本文描述的方法之一的计算机程序的装置或系统。例如,接收器可以是计算机、移动设备、存储设备等。例如,该装置或系统可以包括用于将计算机程序传送到接收器的文件服务器。
[0795]
在一些示例中,可编程逻辑器件(例如,现场可编程门阵列)可以用于执行本文描述的方法的一些或全部功能。在一些示例中,现场可编程门阵列可以与微处理器协作以执行本文描述的方法之一。通常,这些方法可以由任何合适的硬件设备来执行。
[0796]
上述示例仅仅是对上述讨论的原理的说明。应当理解,本文描述的布置和细节的修改和变化将是清楚的。因此,其意图是由权利要求的范围而不是由通过本文的示例的描述和解释的方式呈现的具体细节来限制。
[0797]
相同或等效的元件或具有相同或等效功能的元件在以下描述中也由相同或等效的附图标记表示,即使出现在不同的图中。
[0798]
17文献
[0799]
[1]h.yuan,s.wu,p.an,c.tong,y.zheng,s.bao,and y.zhang,“robust semiautomatic 2d
‑
to
‑
3d conversion with welsch m
‑
estimator for data fidelity,”mathematical problems in engineering,vol.2018.p.15,2018。
[0800]
[2]d.donatsch,n.farber,and m.zwicker,“3d conversion using vanishing points and image warping,”in 3dtv
‑
conference:the true vision
‑
capture,transmission and dispaly of 3d video(3dtv
‑
con),2013,2013,pp.1
–
4。
[0801]
[3]x.cao,z.li,and q.dai,“semi
‑
automatic 2d
‑
to
‑
3d conversion using disparity propagation,”ieee transactions on broadcasting,vol.57,no.2,pp.491
–
499,2011。
[0802]
[4]s.knorr,m.hudon,j.cabrera,t.sikora,and a.smolic,“deepstereobrush:interactive depth map creation,”international conference on 3d immersion,brussels,belgium,2018。
[0803]
[5]c.lin,c.varekamp,k.hinnen,and g.de haan,“interactive disparity map post
‑
processing,”in second international conference on 3d imaging,modeling,
processing,visualization and transmission(3dimpvt),2012,2012,pp.448
–
455。
[0804]
[6]m.o.wildeboer,n.fukushima,t.yendo,m.p.tehrani,t.fujii,and m.tanimoto,“a semi
‑
automatic depth estimation method for ftv,”special issue image processing/coding and applications,vol.64,no.11,pp.1678
–
1684,2010。
[0805]
[7]s.d.cohen,b.l.price,and c.zhang,“stereo correspondance smoothness tool,”us 9,208,547 b2,2015。
[0806]
[8]k.
‑
k.kim,“apparatus and method for correcting disparity map,”us 9,208,541 b2,2015。
[0807]
[9]michael bleyer,christoph rhemann,carsten rother,“patchmatch stereo
‑
stereo matching with slanted support windows”,bmvc 2011 http://dx.doi.org/10.5244/c.25.14。
[0808]
[10]https://github.com/alicevision/meshroommaya。
[0809]
[11]heiko hirschm
ü
ller and daniel scharstein,“evaluation of stereo matching costs on images with radiometric differences”,ieee transactions on pattern analysis and machine intelligence,august 2008。
[0810]
[12]johannes l.jan
‑
michael frahm,“structure
‑
from
‑
motion revisited”,conference on computer vision and pattern recognition(cvpr),2016。
[0811]
[13]johannes l.enliang zheng,marc pollefeys,jan
‑
michael frahm,“pixelwise view selection for unstructured multi
‑
view stereo”,eccv 2016:computer vision
–
eccv 2016 pp 501
‑
518。
[0812]
[14]blender,“blender renderer passes”,https://docs.blender.org/manual/en/latest/render/blender_render/settings/passes.html,accessed 18.12.2018。
[0813]
[15]glyph,the glyph mattepainting toolik,http://www.glyphfx.com/mptk.html,accessed 18.12.2018。
[0814]
[16]enwaii,“photogrammetry software for vfx
–
ewasculpt”,http://www.banzai
‑
pipeline.com/product_enwasculpt.html,accessed 18.12.2018。
[0815]
[17]ron op het veld,joachim keinert,“concept for determining a confidence/uncertainty measure for disparity measurement”,ep18155897.4。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。