1.本发明涉及一种文本快速分类方法,特别涉及一种基于主题降维结合线性判别的文本快速分类方法和装置。
背景技术:
2.随着社会服务的不断发展,社会服务中诉求受理问题愈发多样化,诉求转办的工作量也越来越大。如何快速对诉求所属部门进行预测,精确给出预测结果,最终实现诉求转办自动化处理,提升工作质量,提高分派准确率,减少人工的目的,成为当前诉求转办工作中一项急需解决的问题。
3.目前,诉求转办的方式大多以人工为主,诉求受理人员根据诉求的不同内容,结合历史经验,将问题分配给不同的办理部门。但这种方式存在效率低、面对复杂诉求难以处理、人力需求大等问题,不能显现出政府服务的快捷和高效。
4.随着数据库技术的发展应用,数据的积累不断膨胀,大数据挖掘技术不断受到重视与发展,大数据挖掘相关人员研究出基于机器学习、统计学等与业务人员经验知识相融合的方法进行诉求的半智能转办。机器学习方法是运用自然语言处理中的tf
‑
idf算法,将大量的历史诉求信息,通过分词技术后,利用tf
‑
idf算法提取某一办理部门对应的高频关键词,将该部门高频关键词作为转办参考模型。针对新诉求数据对模型关键词进行匹配,从而确定所属办理部门。统计学方法是,基于大量的历史诉求数据,对历史诉求数据进行分词,统计各办理部门的高频关键词,然后结合业务人员的经验最终确定诉求所属办理部门。但随着社会问题不断多样化,关键词不断增多,新词不断出现,数据愈发嘈杂,业务复杂性和各部门间职能存在交叉的状况,现有转办系统推荐的办理部门准确率不高,使业务人员在转办时准确率降低,致使办理部门反复推诿,诉求转办效率不能满足诉求智能化转办需求。
5.综上所述,为满足诉求数据不断扩大,快速判别诉求所属办理部门并提高分派准确率,健全智能转办工作机制的要求,本发明提出了一种基于主题降维结合线性判别的文本快速分类方法和装置。采用基于“词袋词频向量 pca 线性判别 相似度计算”的主题模型结合线性判别快速准确发现新诉求数据所属办理部门。
技术实现要素:
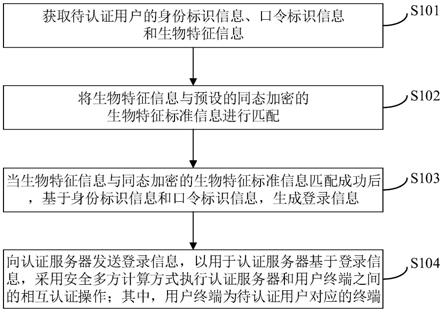
6.基于已经获取到的历史诉求数据进行数据预处理,主要包括空缺值清洗、数据规范化的操作。根据规范化数据在实际情况下所属的不同办理部门对数据进行分组,对分组后的各办理部门数据采用jieba分词进行特征词提取,并运用统计学方法构建词袋词频向量,使用基于数据降维的pca方法,训练各部门数据和总体数据,形成各部门对应的主题模型和总体数据的词
‑
主题矩阵,然后利用线性判别方法训练总体数据的词
‑
主题矩阵建立线性判别标准。获取一条新来诉求后,通过线性判别方法确定前3个候选分类。并对候选分类进行重叠关键词消除和相似度计算对其进行匹配预测,从而快速准确预测该诉求数据所属
办理部门。
7.本发明所采用的技术方案如下:
8.一种基于主题降维结合线性判别的文本快速分类方法和装置,包括以下步骤:
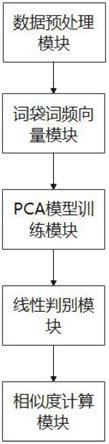
9.a.基于各不同办理部门诉求数据,采用jieba.analyse分词算法进行诉求特征词提取,并运用统计学方法对各部门历史诉求数据构建词袋词频向量。
10.b.应用pca算法对各部门词袋词频向量进行训练和总体数据的词袋词频向量进行训练,构建对应部门的pca模型;在得到各办理部门经pca训练的模型后,对所得各办理部门模型数据以“关键词*权重系数”的形式整合到模型库中,得到办理部门总模型;同时对总体数据的词袋词频向量进行pca模型训练,将词映射到不同主题,生成词
‑
主题矩阵。
11.c.针对总体数据生成的词
‑
主题模型,进行线性判别,通过调整线性判别函数的超参数,得到线性判别修正模型,建立不同部门判别标准。
12.d.获取新来诉求信息后,将其进行线性判别,给出概率最大的前3个候选部门,结合步骤b 中以“关键词*权重系数“的形式整合的总模型库,进行重叠关键词消除、权重累加得到权重最高部门,最终确定该新诉求办理部门。
13.步骤a中,在根据数据实际所属部门对数据进行分组后,对数据进行jieba.analyse分词,在分词时将全部部门诉求数据作为总语料库,得到各个数据的分词结果;根据数据分词结果,结合统计学知识,针对不同部门,统计数据词频出现次数构建词袋词频向量,同时计算出总体部门的词袋词频向量。
14.步骤b中,基于步骤a构建的词袋词频向量,进行pca模型训练,输入数据为各办理部门的词袋词频向量,得到每个主题的模型由“关键词*权重系数”组成;对总体数据的词袋词频向量进行pca模型训练,将词映射到不同主题中,形成词
‑
主题矩阵。
15.步骤c中,线性判别分析是一种分类方法,它通过一个已知类别的“训练样本”来建立判别准则,并通过预测变量来为未知类别的数据进行分类。
16.步骤d中,在办理部门预测阶段,每获取一条新来诉求数据,经过数据预处理后,利用步骤c中建立的线性判别模型,对其进行分类,给出概率最大的3个候选部门,并结合步骤 b中总模型库,进行重叠主题词消除、相似度计算得到相似度最高的部门;重叠主题词消除是指,不同的模型之间可能存在相同的主题词,而不同部门间数据量的多少会导致相同主题词的权重失衡,需要将不同模型中的相同关键词进行去除;相似度计算是指,将新诉求数据的所有分词与线性判别给出的3个候选办理部门逐一进行主题词权重累加,得到相似度最大的部门作为该新来诉求所属办理部门。
附图说明
17.为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
18.图1为文本快速分类模块图。
19.图2为文本快速分类技术路线图。
20.图3为处理新文本诉求技术流程路线图。
具体实施方式
21.为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明实施方式做进一步地详细描述。
22.我们使用中国某省的诉求热线数据进行测试。实验数据为2020年8月4日到2021年2 月16日的诉求热线数据。
23.步骤一,我们将文本数据进行预处理后,用python中的jieba.analyse分词对文本进行断句分词,分词时将全部部门诉求数据作为总语料库。然后运用统计学知识生成词袋词频向量。
24.步骤二,根据词袋词频向量运用pca模型算法对各办理部门和总体数据进行模型训练,得到各办理部门模型数据,以“关键词*权重系数“的形式整合到总模型库中;同时得到总体数据映射到不同主题后的词
‑
主题矩阵。
25.步骤三,根据步骤二中得到的词
‑
主题矩阵,利用线性判别方法,建立各办理部门判别准则。
26.步骤四,当有新诉求数据输入时,诉求经过数据预处理后(如空缺值清洗、数据规范化、数据分词、构建词袋等),利用训练好的线性判别模型,对新来诉求进行分类,给出概率最大的3个候选办理部门。
27.步骤五,结合步骤四得到的3个候选办理部门,对其在步骤二中得到的办理部门模型数据,进行重叠主题词消除、权重累加,取出权重最大的部门作为该新诉求所属办理部。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。