1.本发明涉及神经网络领域,特别涉及一种车辆检测训练中二级损失函数的计算方法。
背景技术:
2.当今社会,人工智能领域中神经网络技术发展迅猛。其中mtcnn技术也是近年来较为流行的技术之一。mtcnn,multi-task convolutional neural network(多任务卷积神经网络),将人脸区域检测与人脸关键点检测放在了一起,总体可分为p-net、r-net、和o-net三层网络结构。用于人脸检测任务的多任务神经网络模型,该模型主要采用了三个级联的网络,采用候选框加分类器的思想,进行快速高效的人脸检测。这三个级联的网络分别是快速生成候选窗口的p-net、进行高精度候选窗口过滤选择的r-net和生成最终边界框与人脸关键点的o-net。
3.但是,mtcnn级联检测存在以下缺陷:
4.1、存在一定的误检,召回率和正确率相对较低。
5.2、特别是,现有技术中使用的一级损失函数计算,对于长宽比例接近1的目标,很容易收敛,对于车辆长宽尺寸比较大,无法收敛。导致正确率和召回率低。
6.此外,现有技术中还包括以下常用的技术术语:
7.1、网络结构级联:是指几个检测器通过串联的方式进行检测的方式称为级联。
8.2、卷积核:卷积核是用来做图像处理时的矩阵,与原图像做运算的参数。卷积核通常是一个列矩阵数组成(例如3*3的矩阵),该区域上每个方格都有一个权重值。矩阵形状一般是1
×
1,3
×
3,5
×
5,7
×
7,1
×
3,3
×
1,2
×
2,1
×
5,5
×
1,
…
.
9.3、卷积:将卷积核的中心放置在要计算的像素上,一次计算核中每个元素和其覆盖的图像像素值的乘积并求和,得到的结构就是该位置的新像素值,这个过程称为卷积。
10.4、激励函数:一种对卷积后结果进行处理的一种函数。
11.5、特征图:输入数据通过卷积计算后得到的结果称之为特征图,数据通过全连接后生成的结果也称为特征图。特征图大小一般表示为长
×
宽
×
深度,或1
×
深度
12.6、步长:卷积核中心位置再坐标上移动的长度。
13.7、两端非对齐处理:图像或数据通过卷积核大小为3
×
3处理时,如果不够一个卷积核处理,会导致两侧数据不够,此时采用丢弃两侧或一侧数据,这种现象叫做两端非对其处理。
14.8、损失计算级联:是指在网络结构某个节点进行计算损失值,并将该损失值加权计算到整体损失中,这种计算损失值的方法叫做损失计算级联。
15.9、损失函数(loss function)也叫代价函数(cost function)。是神经网络优化的目标函数,神经网络训练或者优化的过程就是最小化损失函数的过程(损失函数值小了,对应预测的结果和真实结果的值就越接近。
技术实现要素:
16.为了解决上述现有技术存在的问题,本发明的目的在于通过本技术实现:解决车辆形状任意时,一级损失函数的计算存在的问题,以及在级联检测中正确率和召回率低的现象,且训练收敛。
17.具体地,本发明提供一种车辆检测训练中二级损失函数的计算方法,所述方法包括以下步骤:
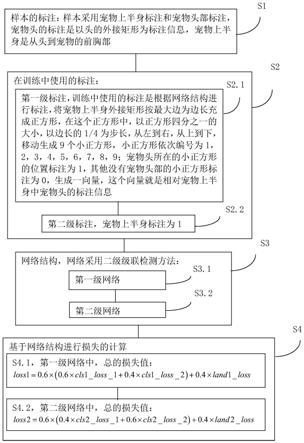
18.s1,制作样本,标注样本:
19.s1.1,以车辆最小外接矩形为标注目标,每一张图中的所有车辆都进行标注;
20.s1.2,根据标注分类样本:总共四类,车辆分类为三类,三类车辆都是正样本,和负样本一类,负样本是没有任何车辆;
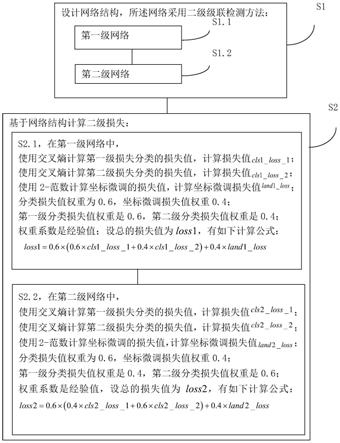
21.s2,采用二级损失函数训练样本标注:
22.s2.1,第一级损失函数使用目标四分类和坐标两点四值的微调,通过交叉熵计算第一级损失值,通过2-范数计算微调中的损失值;
23.s2.2,第二级损失函数使用判断是否为目标的二分类和坐标两点四值的微调,通过对数似然函数计算第二级分类中的损失函数值,通过2-范数计算微调中的损失值;
24.s3,二级损失函数的计算:计算整个二级损失函数时,第一级损失值占0.65,第二级分类损失值占0.35;每一级中,分类损失值占0.4,坐标微调损失值占0.6。
25.所述步骤s1.2进一步包括:
26.所述负样本的第一级标注为[0,0,0],第二级损失标注为0;
[0027]
所述车辆分类为三种车辆目标类型:
[0028]
第一类车辆目标为当长宽比时,第一级损失标注为[1,0,0],第二级损失标注为1;
[0029]
第二类车辆目标为当长宽比时,第一级损失标注为[0,1,0],第二级损失标注为1;
[0030]
第三类车辆目标为当长宽比时,第一级损失标注为[0,0,1],第二级损失标注为1。
[0031]
所述步骤s2中所述的2-范数计算即向量元素绝对值的平方和再开方:
[0032]
所述步骤s2.1中所述的交叉熵计算是通过交叉熵代价函数获得,其中n是训练数据的个数,这个加和覆盖了所有的训练输入x,y是期望输出。
[0033]
所述步骤s2.2中所述的对数似然函数计算是通过对数似然函数c=-∑
k
y
k log a
k
获得,其中,a
k
表示第k个神经元的输出值,y
k
表示第k个神经元对应的真实值,取值为0或1。
[0034]
所述步骤s2中交叉熵计算或对数似然函数计算中,当分类输出正确类的结果即输
出层使用softmax函数之后的值,softmax函数为其中,表示第l层(通常是最后一层)第j个神经元的输入,表示第l层第j个神经元的输出,e表示自然常数。表示了第l层所有神经元的输入之和。
[0035]
由此,本技术的优势在于:本发明方法通过二级损失函数的计算方法,提高车辆检测训练中的正确率,方法简单,节约成本。
附图说明
[0036]
此处所说明的附图用来提供对本发明的进一步理解,构成本技术的一部分,并不构成对本发明的限定。
[0037]
图1是本发明方法的流程图。
[0038]
图2是本发明方法中样本制作的第一类车辆目标的示意图。
[0039]
图3是本发明方法中样本制作的第二类车辆目标的示意图。
[0040]
图4是本发明方法中样本制作的第三类车辆目标的示意图。
具体实施方式
[0041]
为了能够更清楚地理解本发明的技术内容及优点,现结合附图对本发明进行进一步的详细说明。
[0042]
如图1所示,本发明涉及一种车辆检测训练中二级损失函数的计算方法,所述方法包括以下步骤:
[0043]
s1,制作样本,标注样本:
[0044]
s1.1,以车辆最小外接矩形为标注目标,每一张图中的所有车辆都进行标注;
[0045]
s1.2,根据标注分类样本:总共四类,车辆分类为三类,三类车辆都是正样本,和负样本一类,负样本是没有任何车辆;
[0046]
s2,采用二级损失函数训练样本标注:
[0047]
s2.1,第一级损失函数使用目标四分类和坐标两点四值的微调,通过交叉熵计算第一级损失值,通过2-范数计算微调中的损失值;
[0048]
s2.2,第二级损失函数使用判断是否为目标的二分类和坐标两点四值的微调,通过对数似然函数计算第二级分类中的损失函数值,通过2-范数计算微调中的损失值;
[0049]
s3,二级损失函数的计算:计算整个二级损失函数时,第一级损失值占0.65,第二级分类损失值占0.35;每一级中,分类损失值占0.4,坐标微调损失值占0.6。
[0050]
所述步骤s1.2进一步包括:
[0051]
所述负样本的第一级标注为[0,0,0],第二级损失标注为0;
[0052]
所述车辆分类为三种车辆目标类型,如图2-4所示:
[0053]
第一类车辆目标为当长宽比时,第一级损失标注为[1,0,0],第二级损失标注为1;
[0054]
第二类车辆目标为当长宽比时,第一级损失标注为[0,1,0],第二级损失标注为1;
[0055]
第三类车辆目标为当长宽比时,第一级损失标注为[0,0,1],第二级损失标注为1。
[0056]
所述步骤s2中所述的2-范数计算即向量元素绝对值的平方和再开方:2-范数:范数(norm),是具有“长度”概念的函数。所述步骤s2.1中所述的交叉熵计算是通过交叉熵代价函数获得,其中n是训练数据的个数,这个加和覆盖了所有的训练输入x,y是期望输出。交叉熵(cross-entropy)代价函数来源于信息论中熵的概念。是目前神经网络分类问题中(比如图像分类)常用的代价函数。交叉熵代价函数对分类问题有一个很好的解释:当分类输出正确类的结果(输出层使用softmax函数之后的值)接近于1时,对应正确类的标签为1,即y=1。则可得到,c中第一项接近于0,第二项等于0。对于非正确类,a接近于0,y=0,则c中第一项为0,第二项接近于0。故最终c接近于0;当分类输出正确类的结果与1的差距越大,则上式c的值越大。
[0057]
所述步骤s2.2中所述的对数似然函数计算是通过对数似然函数c=-∑
k
y
k
log a
k
获得,其中,a
k
表示第k个神经元的输出值,y
k
表示第k个神经元对应的真实值,取值为0或1。对数似然函数与交叉熵代价函数类似,但只考了正确类损失,不考虑错误类的损失。与交叉熵代价函数一样,对数似然也对分类有一个很好的解释:当正确类的输出值a(输出层只用softmax后的值)接近于1时,y=1,c接近于0;当输出值a距离a越大时,c值越大。
[0058]
所述步骤s2中交叉熵计算或对数似然函数计算中,当分类输出正确类的结果即输出层使用softmax函数之后的值,softmax函数为其中,表示第l层(通常是最后一层)第j个神经元的输入,表示第l层第j个神经元的输出,e表示自然常数。表示了第l层所有神经元的输入之和。softmax函数最明显的特点在于:它把每个神经元的输入占当前层所有神经元输入之和的比值,当作该神经元的输出。这使得输出更容易被解释:神经元的输出值越大,则该神经元对应的类别是真实类别的可能性更高。
[0059]
本方法还涉及对应的网络结构,具体如下:
[0060]
1)第一级网络:
[0061]
第一层输入数据47
×
47
×
1,灰度图,卷积核大小是3
×
3,步长是2,输出深度是16,输出结果是特征图(1)23
×
23
×
16。
[0062]
第二层输入数据特征图(1)23
×
23
×
16,卷积核大小是3
×
3,步长是2,输出深度是16,输出结果是特征图(2)11
×
11
×
16。
[0063]
第三层输入数据特征图(2)11
×
11
×
16,卷积核大小是3
×
3,步长是2,输出深度是16,输出结果是特征图(3)5
×5×
16。
[0064]
第四层输入数据特征图(3)5
×5×
16,卷积核大小是3
×
3,步长是1,输出深度是16,输出结果是特征图(6)3
×3×
16。
[0065]
第五层输入数据特征图(3)5
×5×
16,去掉特征图宽方向上下两端一个值,得到特征图(4)5
×3×
16。
[0066]
第六层输入数据特征图(3)5
×5×
16,去掉特征图高度方向左右两端一个值,得到特征图(5)3
×5×
16。
[0067]
第七层输入数据特征图(4)5
×3×
16,卷积核大小是3
×
1,步长是1,输出深度是16,输出结果是特征图(7)3
×3×
16。
[0068]
第八层输入数据特征图(5)3
×5×
16,卷积核大小是1
×
3,步长是1,输出深度是16,输出结果是特征图(8)3
×3×
16。
[0069]
第九层输入数据特征图(6)3
×3×
16,卷积核大小是3
×
3,步长是1,输出深度是1和4,输出结果是特征图1
×1×
1和1
×1×
4。
[0070]
第十层输入数据特征图(7)3
×3×
16,卷积核大小是3
×
3,步长是1,输出深度是1和4,输出结果是特征图1
×1×
1和1
×1×
4。
[0071]
第十一层输入数据特征图(8)3
×3×
16,卷积核大小是3
×
3,步长是1,输出深度是1和4,输出结果是特征图1
×1×
1和1
×1×
4。
[0072]
第十二层是将第九层、第十层、第十一层结果合并为特征图(9)1
×1×
3和特征图(10)1
×1×
12。第十二层输入数据特征图(9)1
×1×
3和特征图(10)1
×1×
12,卷积核大小是1
×
1和1
×
1,步长是1,输出深度是1和4,输出结果是特征图(11)1
×1×
1和特征图(12)1
×1×
4。所有卷积都使用两端非对齐处理。其中,使用特征图(9)1
×1×
3和特征图(10)1
×1×
12作为第一级网络的第一级损失函数计算的预测值,根据预测值和标注的真实值计算损失函数值。使用特征图(11)1
×1×
1和特征图(12)1
×1×
4作为第二级损失函数计算的预测值,根据预测值和标注的真实值计算损失函数值。
[0073]
2)第二级网络:
[0074]
初始层输入数据49
×
49
×
1,灰度图,卷积核大小是3
×
3,步长是1,输出深度是16,输出结果是特征图(0)47
×
47
×
16;
[0075]
第一层输入数据特征值(0)47
×
47
×
16,卷积核大小是3
×
3,步长是2,输出深度是32,输出结果是特征图(1)22
×
23
×
32;
[0076]
第二层输入数据特征图(1)23
×
23
×
32,卷积核大小是3
×
3,步长是2,输出深度是64,输出结果是特征图(2)11
×
11
×
64;
[0077]
第三层输入数据特征图(2)11
×
11
×
64,卷积核大小是3
×
3,步长是2,输出深度是64,输出结果是特征图(3)5
×5×
64;
[0078]
第四层输入数据特征图(3)5
×5×
64,卷积核大小是3
×
3,步长是1,输出深度是64,输出结果是特征图(6)3
×3×
64;
[0079]
第五层输入数据特征图(3)5
×5×
64,去掉特征图宽方向上下两端一个值,得到特征图(4)5
×3×
64;
[0080]
第六层输入数据特征图(3)5
×5×
64,去掉特征图高度方向左右两端一个值,得到特征图(5)3
×5×
64;
[0081]
第七层输入数据特征图(4)5
×3×
64,卷积核大小是3
×
1,步长是1,输出深度是
64,输出结果是特征图(7)3
×3×
64;
[0082]
第八层输入数据特征图(5)3
×5×
64,卷积核大小是1
×
3,步长是1,输出深度是64,输出结果是特征图(8)3
×3×
64;
[0083]
第九层输入数据特征图(6)3
×3×
64,卷积核大小是3
×
3,步长是1,输出深度是1和4,输出结果是特征图1
×1×
1和1
×1×
4;
[0084]
第十层输入数据特征图(7)3
×3×
64,卷积核大小是3
×
3,步长是1,输出深度是1和4,输出结果是特征图1
×1×
1和1
×1×
4;
[0085]
第十一层输入数据特征图(8)3
×3×
64,卷积核大小是3
×
3,步长是1,输出深度是1和4,输出结果是特征图1
×1×
1和1
×1×
4;
[0086]
第十二层是将第九层、第十层、第十一层结果合并为特征图(9)1
×1×
3和特征图(10)1
×1×
12;
[0087]
第十二层输入数据特征图(9)1
×1×
3和特征图(10)1
×1×
12,卷积核大小是1
×
1和1
×
1,步长是1,输出深度是1和4,输出结果是特征图(11)1
×1×
1和特征图(12)1
×1×
4;
[0088]
所有卷积都使用两端非对齐处理。
[0089]
其中,使用特征图(9)1
×1×
3和特征图(10)1
×1×
12作为这第二级网络的第一级损失函数计算的预测值,根据预测值和标注的真实值计算损失函数值;使用特征图(11)1
×1×
1和特征图(12)1
×1×
4作为第二级损失函数计算的预测值,根据预测值和标注的真实值计算损失函数值。
[0090]
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明实施例可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。