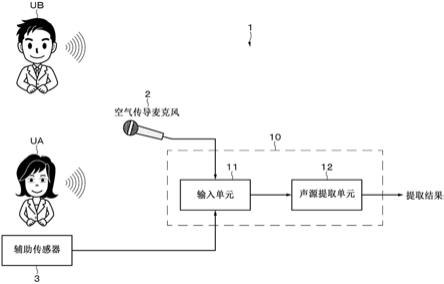
1.本公开涉及一种信号处理装置、一种信号处理方法和一种程序。
背景技术:
2.已经开发了用于从混合声音中提取用户发出的声音的技术(例如,参见非专利文献1和非专利文献2),在该混合声音中,用户发出的声音和其他声音(例如,环境噪声)混合。
3.现有技术文献
4.非专利文献
5.非专利文献1:a.efferat,i.mosseri,o.lang,t.dekel,k.wilson,a.hassidim,w.freeman,m.rubinstein,“looking to listen at the cocktail party:a speaker
‑
independent audio
‑
visual model for speech separation”,[在线],2018年8月9日,[2019年4月5日检索],互联网<url:https://arxiv.org/abs/1804.03619>。
[0006]
非专利文献2:m.delcroix,k.zmolikova,k.kinoshita,a.ogawa,t.nakatani,“single channel target speaker extraction and recognition with speaker beam”,2018ieee international conference on acoustics,speech and signal processing(icassp),p.5554
‑
5558,2018。
技术实现要素:
[0007]
本发明要解决的问题
[0008]
在本领域中,期望能够从混合有目标声音和除该目标声音以外的声音的混合声音中适当地提取要提取的声音(以下适当地被称为目标声音)。
[0009]
鉴于上述观点构成本公开,并且涉及一种信号处理装置、一种信号处理方法和一种程序,能够从混合了目标声音和除目标声音以外的声音的混合声音中适当提取目标声音。
[0010]
问题的解决方案
[0011]
例如,本公开是:
[0012]
一种信号处理装置,包括:
[0013]
输入单元,包括混合有目标声音和除目标声音之外的声音的混合声音的麦克风信号、和由辅助传感器获取并与目标声音同步的一维时间序列信号输入到该输入单元;以及
[0014]
声源提取单元,基于一维时间序列信号从麦克风信号中提取与目标声音相对应的目标声音信号。
[0015]
另外,例如,本公开是:
[0016]
一种信号处理方法,包括:
[0017]
将包括混合有目标声音和除目标声音之外的声音的混合声音的麦克风信号、和由辅助传感器获取并与目标声音同步的一维时间序列信号输入到输入单元;并且
[0018]
由声源提取单元基于一维时间序列信号从麦克风信号中提取与目标声音相对应
的目标声音信号。
[0019]
另外,例如,本公开是:
[0020]
一种程序,用于使计算机执行信号处理方法,该信号处理方法包括:
[0021]
将包括混合有目标声音和除目标声音之外的声音的混合声音的麦克风信号和由辅助传感器获取并与目标声音同步的一维时间序列信号输入到输入单元;并且
[0022]
由声源提取单元基于一维时间序列信号从麦克风信号中提与目标声音相对应的目标声音信号。
附图说明
[0023]
图1是用于描述根据实施例的信号处理系统的配置示例的图;
[0024]
图2的a至图2的d是在描述根据实施例的信号处理装置执行的处理的概要时参考的图;
[0025]
图3是用于描述根据实施例的信号处理装置的配置示例的图;
[0026]
图4是用于解释根据实施例的信号处理装置的一个方面的图;
[0027]
图5是用于描述根据实施例的信号处理装置的另一方面的图;
[0028]
图6是用于描述根据实施例的信号处理装置的另一方面的图;
[0029]
图7是用于描述根据实施例的声源提取单元的详细配置示例的图;
[0030]
图8是用于描述根据实施例的特征量生成单元的详细配置示例的图;
[0031]
图9的a至图9的c是在描述由根据实施例的短时傅立叶变换单元执行的处理时参考的图;
[0032]
图10是用于描述根据实施例的提取模型单元的详细配置示例的图;
[0033]
图11是用于描述根据实施例的重构单元的详细配置示例的图;
[0034]
图12是在描述根据实施例的学习系统时参考的图;
[0035]
图13是示出根据实施例的学习数据的图;
[0036]
图14是在描述根据该实施例的空气传导麦克风和辅助传感器的具体示例时参考的图;
[0037]
图15是在描述根据该实施例的空气传导麦克风和辅助传感器的另一具体示例时参考的图;
[0038]
图16是示出根据实施例的信号处理装置执行的整体处理的流程的流程图;
[0039]
图17是示出根据实施例的声源提取单元执行的处理流程的流程图;
[0040]
图18是在描述修改时参考的图;
[0041]
图19是在描述修改时参考的图;
[0042]
图20是在描述修改时参考的图;
[0043]
图21是在描述修改时参考的图;
[0044]
图22是在描述修改时参考的图。
具体实施方式
[0045]
在下文中,将参考附图描述本公开的实施例等。注意,将按以下顺序给出描述。
[0046]
<1.实施例>
[0047]
<2.修改>
[0048]
下面描述的实施例等是本公开的优选具体示例,并且本公开的内容不限于这些实施例等。
[0049]
<1.实施例>
[0050]
[本公开的概要]
[0051]
首先,将描述本公开的概要。本公开是一种通过教学的声源提取类型,除了用于获取混合声音的麦克风(空气传导麦克风)之外,还包括用于获取教学信息的传感器(辅助传感器)。作为辅助传感器的示例,可以想到以下任意一种或两种或多种的组合。(1)安装(附接)在目标声音优于干扰声音的状态下能够获取目标声音的位置的另一空气传导麦克风,例如,耳道;(2)获取在除了大气之外的区域中传播的声波的麦克风,例如,骨导麦克风或喉部麦克风;以及(3)获取除了声音之外的模态信号并且与用户的话语同步的传感器。例如,辅助传感器附接到目标声音产生源。在上述(3)的示例中,脸颊和喉咙附近的皮肤振动、面部附近的肌肉运动等被认为是与用户的话语同步的信号。稍后将描述获取这些信号的辅助传感器的具体示例。
[0052]
图1示出了根据本公开实施例的信号处理系统(信号处理系统1)。信号处理系统1包括信号处理装置10。信号处理装置10基本上具有输入单元11和声源提取单元12。另外,信号处理系统1具有收集声音的空气传导麦克风2和辅助传感器3。空气传导麦克风2和辅助传感器3连接到信号处理装置10的输入单元11。空气传导麦克风2和辅助传感器3以有线或无线方式连接到输入单元11。例如,辅助传感器3是附接到目标声音产生源的传感器。本示例中的辅助传感器3设置在用户ua的附近,具体地,佩戴在用户ua的身体上。辅助传感器3获取稍后将描述的与目标声音同步的一维时间序列信号。在这种时间序列信号的基础上获得教学信息。
[0053]
由信号处理系统1中的声源提取单元12提取的目标声音是由用户ua发出的语音。目标声音始终是语音,并且是定向声源。干扰声源是发出与目标声音不同的干扰声音的声源。这可以是语音,也可能是非语音,甚至可以存在同一个声源产生两个信号的情况。干扰声源是定向声源或非定向声源。干扰声源的数量为零或一个或多个的整数。在图1所示的示例中,用户ub发出的语音被示为干扰声音的示例。不言而喻,噪音(例如,开门关门声、直升机在头顶盘旋的声音、人多的地方人群的声音等)也可以是干扰声。空气传导麦克风2是记录通过大气传输的声音的麦克风,并且获取目标声音和干扰声音的混合声音。在以下描述中,所获取的混合声音被适当地称为麦克风观察信号。
[0054]
接下来,将参考图2的a至图2的d描述由信号处理装置10执行的处理的概要。在从图2的a到图2的d的图中,横轴代表时间,纵轴代表体积(或功率)。
[0055]
图2的a是麦克风观察信号的图像图。麦克风观察信号是混合了从目标声音导出的分量4a和从干扰声音导出的分量4b的信号。
[0056]
图2的b是教学信息的图像图。在本示例中,假设辅助传感器3是安装在与空气传导麦克风2不同的位置处的另一空气传导麦克风。因此,由辅助传感器3获取的一维时间序列信号是声音信号。这样的声音信号用作教学信息。图2的b类似于图1,其中,目标声音和干扰声音混合,但是由于辅助传感器3的附接位置在用户的身体上,所以观察到从目标声音导出的分量4a比从干扰声音导出的分量4b更占优势。
[0057]
图2的c是教学信息的另一图像图。在本示例中,假设辅助传感器3是除了空气传导麦克风之外的传感器。由除空气传导麦克风之外的传感器获取的信号的示例包括由骨传导麦克风、喉部麦克风等获取并在用户体内传播的声波、用户脸颊、喉部等的皮肤表面的振动、以及由除麦克风之外的传感器获取的用户嘴附近的肌肉的肌电位和加速度。由于这些信号不在大气中传播,因此认为这些信号几乎不受干扰声的影响。为此,教学信息主要包括从目标声音导出的分量4a。即,信号强度随着用户开始说话而上升,随着说话结束而下降。
[0058]
由于教学信息与目标声音的话语同步获取,所以从目标声音导出的分量4a和从目标声音导出的分量4b的上升和下降的定时与从目标声音导出的分量4a的定时相同。
[0059]
如图1所示,信号处理装置10的声源提取单元12接收从空气传导麦克风2导出的麦克风观察信号和从辅助传感器3导出的教学信息作为输入,从麦克风观察信号中消除从干扰声音导出的分量,并留下从目标声音导出的分量,从而生成提取结果。
[0060]
图2的d是提取结果的图像。理想的提取结果仅包括从目标声音导出的分量4a。为了产生这样的提取结果,声源提取单元12具有表示提取结果和麦克风观察信号以及教学信息之间的关联的模型。通过大量数据提前得知这样的模型。
[0061]
[信号处理装置的配置示例]
[0062]
(整体配置示例)
[0063]
图3是用于描述根据实施例的信号处理装置10的配置示例的图。如上所述,空气传导麦克风2观察到目标声音和在大气中传输的除了目标声音之外的声音(干扰声音)混合的混合声音。辅助传感器3附接于用户身体,并获取与目标声音同步的一维时间序列信号,作为教学信息。由空气传导麦克风2收集的麦克风观察信号和由辅助传感器3获取的一维时间序列信号通过信号处理装置10的输入单元11输入到声源提取单元12。另外,信号处理装置10具有控制单元13,该控制单元13整体控制信号处理装置10。声源提取单元12从由空气传导麦克风2收集的混合声音中提取并输出与目标声音相对应的目标声音信号。具体地,声源提取单元12使用基于一维时间序列信号生成的教学信息来提取目标声音信号。目标声音信号被输出到后处理单元14。
[0064]
后处理单元14的配置根据应用信号处理装置10的装置而不同。图4示出了后处理单元14包括声音再现单元14a的示例。声音再现单元14a具有用于再现声音信号的配置(放大器、扬声器等)。在所示示例的情况下,目标声音信号由声音再现单元14a再现。
[0065]
图5示出了后处理单元14包括通信单元14b的示例。通信单元14b具有用于通过诸如互联网或预定通信网络的网络将目标声音信号发送到外部装置的配置。在所示示例的情况下,目标声音信号由通信单元14b发送。另外,通信单元14b接收从外部装置发送的音频信号。在本示例的情况下,例如,信号处理装置10应用于通信装置。
[0066]
图6示出了后处理单元14包括话语区段估计单元14c、语音识别单元14d和应用处理单元14e的示例。作为从空气传导麦克风2到声源提取单元12的连续流处理的信号被话语区段估计单元14c分成话语单位。作为话语区段估计(或语音区段检测)的方法,可以应用已知的方法。此外,作为话语区段估计单元14c的输入,除了作为声源提取单元12的输出的干净目标声音之外,可以使用由辅助传感器3获取的信号(在这种情况下,由辅助传感器3获取的信号流由图6中的虚线表示)。即,不仅可以通过使用声音信号,还可以通过使用辅助传感器3获取的信号,来执行话语区段估计(检测)。作为这样的方法,也可以应用已知的方法。
[0067]
虽然话语区段估计单元14c可以输出划分的声音本身,但是话语区段估计单元14c也可以输出指示诸如开始时间和结束时间的区段的话语区段信息来代替声音,并且可以由语音识别单元14d使用该话语区段信息来执行划分本身。图6是假设后一种形式的示例。语音识别单元14d接收作为声源提取单元12的输出的干净目标声音和作为话语区段估计单元14c的输出的区段信息,作为输入,并输出与该区段相对应的字串,作为语音识别结果。应用处理单元14e是与使用语音识别结果的处理相关联的模块。在信号处理装置10应用于语音交互系统的示例中,应用处理单元14e与执行响应生成、语音合成等的模块相对应。另外,在信号处理装置10应用于语音翻译系统的示例中,应用处理单元14e与执行机器翻译、语音合成等的模块相对应。
[0068]
(声源提取单元)
[0069]
图7是用于描述声源提取单元12的详细配置示例的框图。声源提取单元12例如具有模数(ad)转换单元12a、特征量生成单元12b、提取模型单元12c和重构单元12d。
[0070]
声源提取单元12有两种类型的输入。一种是由空气传导麦克风2获取的麦克风观察信号,另一种是由辅助传感器3获取的教学信息。麦克风观察信号由ad转换单元12a转换成数字信号,然后被发送到特征量生成单元12b。教学信息被发送到特征量生成单元12b。虽然图7中未示出,但是在辅助传感器3获取的信号是模拟信号的情况下,模拟信号由与ad转换单元12a不同的ad转换单元转换成数字信号,然后输入到特征量生成单元12b。这种转换的数字信号也是基于由辅助传感器3获取的一维时间序列信号生成的一种教学信息。
[0071]
特征量生成单元12b接收麦克风观察信号和教学信息,作为输入,并且生成要输入到提取模型单元12c的特征量。特征量生成单元12b还保存将提取模型单元12c的输出转换成波形所需的信息。提取模型单元12c的模型是预先学习干净目标声音和一组麦克风观察信号以及教学信息之间的对应关系的模型,该麦克风观察信号是目标声音和干扰声音的混合信号,该教学信息是要提取的目标声音的提示。在下文中,对提取模型单元12c的输入被适当地称为输入特征量,并且从提取模型单元12c的输出被适当地称为输出特征量。
[0072]
重构单元12d将来自提取模型单元12c的输出特征量转换成声音波形或类似信号。此时,重构单元12d从特征量生成单元12b接收波形生成所需的信息。
[0073]
(声源提取单元的每个配置的详细信息)
[0074]“特征量生成单元的详细信息”[0075]
接下来,将参照图8描述特征量生成单元12b的详细信息。在图8中,假设频谱等作为特征量,但是也可以使用其他特征量。特征量生成单元12b具有短时傅立叶变换单元121b、教学信息转换单元122b、特征量缓冲单元123b和特征量对准单元124b。
[0076]
存在两种类型的信号作为特征量生成单元12b的输入。由ad转换单元12a转换成数字信号的作为一个输入的麦克风观察信号被输入到短时傅立叶变换单元121b。然后,麦克风观察信号被短时傅立叶变换单元121b转换成时频域(即频谱)中的信号。
[0077]
来自辅助传感器3的作为另一输入的教学信息由教学信息转换单元122b根据信号的类型进行转换。在教学信息是声音信号的情况下,类似于麦克风观察信号执行短时傅立叶变换。在教学信息是除声音之外的模态的情况下,可以执行短时傅立叶变换或者使用教学信息而不进行转换。
[0078]
由短时傅立叶变换单元121b和教学信息转换单元122b转换的信号在预定时间内
存储在特征量缓冲单元123b中。在此处,时间信息与转换结果彼此关联地存储,并且在后续阶段中存在从模块获取过去特征量的请求的情况下,可以输出特征量。另外,关于麦克风观察信号的转换结果,由于在后续阶段的波形生成中使用该信息,转换结果被存储为一组复频谱。
[0079]
特征量缓冲单元123b的输出用于两个位置,具体地,在重构单元12d和特征量对准单元124b的每一个中。在从麦克风观察信号导出的特征量与从教学信息导出的特征量之间的时间粒度不同的情况下,特征量对准单元124b执行调整特征量的粒度的处理。
[0080]
例如,假设麦克风观察信号的采样频率是16khz,并且短时傅立叶变换单元121b中的移位宽度是160个样本,以每1/100秒一次的频率生成从麦克风观察信号导出的特征量。另一方面,在以每1/200秒一次的频率生成从教学信息导出的特征量的情况下,生成从麦克风观察信号导出的一组特征量和从教学信息导出的两组特征量组合的数据,并且所生成的数据用作提取模型单元12c的一次输入数据。
[0081]
相反,在以每1/50秒一次的频率生成从教学信息导出的特征量的情况下,生成将从麦克风观察信号导出的两组特征量和从教学信息导出的一组特征量组合的数据。此外,在该阶段,还根据需要执行从复频谱到幅度谱等的转换。以这种方式生成的输出被发送到提取模型单元12c。
[0082]
在此处,将参照图9描述由上述短时傅立叶变换单元121b执行的处理。从由ad转换单元12a获得的麦克风观察信号的波形(见图9的a)中切出固定长度,并向其应用诸如汉宁窗或汉明窗的窗函数。这个切割单位被称为帧。通过将短时傅立叶变换应用于一帧的数据,例如,从x(1,t)获得x(k,t),作为时频域中的观察信号(参见图9的b)。然而,注意,t表示帧数量,k表示频率仓的总数量。切出帧之间可能存在重叠,因此信号在时频域中的变化在连续帧之间是平滑的。作为一帧数据的从x(1,t)到x(k,t)的集合被称为频谱,并且多个频谱在时间方向上排列的数据结构被称为频谱图(参见图9的c)。在图9的c的频谱图中,横轴表示帧数量,纵轴表示频率仓数量,从图9的a生成三个频谱(x(1,t
‑
1)到x(k,t
‑
1)、x(1,t)到x(k,t)、x(1,t 1)到x(k,t 1))。
[0083]“提取模型单元的详细信息”[0084]
接下来,将参照图10描述提取模型单元12c的详细信息。提取模型单元12c使用特征量生成单元12b的输出,作为输入。特征量生成单元12b的输出包括两种类型的数据。一种是从麦克风观察信号导出的特征量,另一种是从教学信息导出的特征量。在下文中,从麦克风观察信号导出的特征量被适当地称为第一特征量,从教学信息导出的特征量被适当地称为第二特征量。
[0085]
提取模型单元12c包括例如输入层121c、输入层122c、中间层123c和输出层124c,该中间层123c包括中间层1至中间层n。图10所示的提取模型单元12c表示所谓的神经网络。输入层被分成输入层121c和输入层122c这两层的原因在于两种类型的特征值被输入到相应的层。
[0086]
在图10所示的示例中,输入层121c是输入有第一特征量的输入层,输入层122c是输入有第二特征量的输入层。神经网络的类型和结构(层数)可以任意设置,并且干净目标声音与一组第一特征量和第二特征量之间的对应关系由稍后描述的学习系统预先学习。
[0087]
提取模型单元12c在输入层121c处接收第一特征量和在输入层122c处接收第二特
征量,作为输入,并且执行预定的前向传播处理,以生成与作为输出数据的干净目标声音的目标声音信号相对应的输出特征量。作为输出特征量的类型,可以使用对应于干净目标声音的幅度谱、用于从麦克风观察信号的频谱生成干净目标声音的频谱的时频掩模等。
[0088]
注意,虽然在图10中两种类型的输入数据在紧接着的中间层(中间层1)中合并,但是这两种类型的输入数据可以合并在更靠近输出层124c的中间层中。在这种情况下,从每个输入层到结点的层数可以不同,并且作为示例,可以使用从中间层输入一个输入数据的网络结构。可以如下想象用于在中间层中合并两种类型数据的若干种类型的方法。一种方法是将前两层输出的矢量格式的数据连接起来的方法。另一种方法是如果两个向量的元素数量相同,则将元素相乘。
[0089]“重构单元的详细信息”[0090]
接下来,将参照图11描述重构单元12d的详细信息。重构单元12d将提取模型单元12c的输出转换成与声音波形或声音类似的数据。为了执行这样的处理,重构单元12d也从特征量生成单元12b中的特征量缓冲单元123b接收必要的数据。
[0091]
重构单元12d具有复频谱图生成单元121d和逆短时傅立叶变换单元122d。复频谱图生成单元121d对提取模型单元12c的输出和来自特征量生成单元12b的数据进行集成,以生成目标声音的复频谱图。生成的方式根据提取模型单元的输出是幅度谱还是时频掩模而变化。在幅度谱的情况下,由于缺少相位信息,为了将幅度谱转换成波形,有必要添加(恢复)相位信息。可以应用已知的技术来恢复相位。例如,从特征量缓冲单元123b获取相同时间的麦克风观察信号的复频谱,并从中提取相位信息,并与振幅频谱合成,以生成目标声音的复频谱。
[0092]
另一方面,在时频掩模的情况下,类似地获取麦克风观察信号的复频谱,然后将时频掩模应用于复频谱(针对每个时频相乘),以生成目标声音的复频谱。对于时频掩模的应用,可以使用已知的方法(例如,日本专利公开2015
‑
55843中描述的方法)。
[0093]
逆短时傅立叶变换单元122d将复频谱转换成波形。逆短时傅立叶变换包括逆傅立叶变换、叠加法等。作为这些方法,可以应用已知的方法(例如,日本专利公开2018
‑
64215中描述的方法)。
[0094]
注意,根据后续阶段中的模块,可以在重构单元12d中将数据转换成除波形之外的数据,或者可以省略重构单元12d本身。例如,在后续阶段中的模块是话语区段检测和语音识别,并且在该阶段中使用的特征量是幅度谱或可以从其生成的数据的情况下,重构单元12d仅需要将提取模型单元12c的输出转换成幅度谱。此外,在提取模型单元12c本身输出幅度谱的情况下,可以省略重构单元12d本身。
[0095]
(提取模型单元的学习系统)
[0096]
接下来,将参照图12和图13描述提取模型单元12c的学习系统。这种学习系统用于预先对提取模型单元12c执行预定的学习。虽然除了提取模型单元12c之外,下面描述的学习系统被假设为与信号处理装置10不同的系统,但是与学习系统相关的配置可以包含在信号处理装置10中。
[0097]
学习系统的基本操作例如如下(1)至(3)所描述,重复(1)至(3)的处理被称为学习。(1)从目标声音数据集21和干扰声音数据集22生成输入特征量和教师数据(输入特征量的理想输出特征量)。(2)输入特征量被输入到提取模型单元12c,并且通过前向传播来生成
输出特征量。(3)将输出特征量与教师数据进行比较,并更新提取模型中的参数,以减少误差,换言之,以最小化损失函数中的损失值。
[0098]
在下文中,这对输入特征量和教师数据被适当地称为学习数据。如图13所示,有四种类型的学习数据。在该图中,(a)是用于在目标声音和干扰声音混合的情况下学习提取目标声音的数据,(b)是用于使得在安静环境中的话语不恶化地输出的数据,(c)是用于在用户没有发声的情况下导致静音输出的数据,以及(d)是用于在用户没有在安静环境中发声的情况下导致静音输出的数据。注意,图13的教学信息中的“不存在”意味着信号本身存在,但是不包括从目标声音导出的分量。
[0099]
根据情况以预定比率生成这四种类型的学习数据。可替代地,如稍后将描述的,通过在目标声音和干扰声音的数据集中包括安静环境中记录的接近静音的声音,可以根据情况在不应用数据的情况下生成所有组合。
[0100]
在下文中,将描述学习系统中包括的模块及其操作。目标声音数据集21是包括一对目标声音波形和与目标声音波形同步的教学信息的组。然而,注意,为了生成对应于图13中的(c)的学习数据或对应于图13中的(d)的学习数据,当人不在安静的地方说话时的一对麦克风观察信号和与其对应的辅助传感器的输入信号也包括在该数据集中。
[0101]
干扰声音数据集22是包括可以是干扰声音的声音的组。因为语音也可以是干扰声音,所以干扰声音数据集22包括语音和非语音。此外,为了生成对应于图13中的(b)的学习数据和对应于图13中的(d)的学习数据,在安静的地方观察到的麦克风观察信号也包括在该数据集中。在学习时,从目标声音数据集21中随机提取包括目标声音波形与教学信息的对中的一个。在通过空气传导麦克风获取教学信息的情况下,教学信息被输入到混合单元24,但是在通过除空气传导麦克风之外的传感器获取教学信息的情况下,教学信息被直接输入到特征量生成单元25。目标声音波形被输入到混合单元23和教师数据生成单元26中的每一个。另一方面,从干扰声音数据集22中随机提取一个或多个声音波形,并将声音波形输入到混合单元23。在辅助传感器是除了空气传导麦克风之外的装置的情况下,从干扰声音数据集22提取的波形也被输入到混合单元24。
[0102]
混合单元23以预定的混合比(信噪比(sn比))混合目标声音波形和一个或多个干扰声音波形。混合结果与麦克风观察信号相对应,并被发送到特征量生成单元25。混合单元24是在辅助传感器3是空气传导麦克风的情况下应用的模块,并且以预定的混合比率将干扰声音与作为声音信号的教学信息混合。干扰声音在混合单元24中混合的原因是,即使在某种程度上在教学信息中混合了干扰声音,也可以实现良好的声源提取。
[0103]
特征量生成单元25有两种类型的输入,一种是麦克风观察信号,另一种是教学信息或混合单元24的输出。从这两种类型的数据生成输入特征量。提取模型单元12c是学习之前和学习期间的神经网络,并且具有与图10相同的配置。教师数据生成单元26生成作为理想输出特征量的教师数据。教师数据的形状基本上与输出特征量相同,并且是幅度谱、时频掩模等。然而,注意,如稍后将描述的,提取模型单元12c的输出特征量是时频掩码而教师数据是幅度谱的组合也是可以的。
[0104]
如图13所示,教师数据根据目标声音和干扰声音的存在或不存在而变化。教师数据是在目标声音存在的情况下与目标声音的输出特征量相对应,教师数据是在目标声音不存在的情况下与静音的输出特征量相对应。比较单元27将提取模型单元12c的输出与教师
数据进行比较,并计算包括在提取模型单元12c中的参数的更新值,使得损失函数中的损失值减小。作为比较中使用的损失函数,可以使用均方误差等。作为比较方法和参数更新方法,可以应用被称为神经网络学习算法的方法。
[0105]
[空气传导麦克风和辅助传感器的具体示例]
[0106]
(具体示例1)
[0107]
接下来,将描述空气传导麦克风2和辅助传感器3的具体示例。图14是示出耳机30中的空气传导麦克风2和辅助传感器3的具体示例的图。外部(与耳廓侧相反的一侧)麦克风32和内部(耳廓侧)麦克风33分别设置在耳罩31的外侧和内侧,耳罩31是要覆盖在耳朵上的部件。例如,作为外部麦克风32和内部麦克风33,可以应用用于噪声消除的麦克风。作为麦克风的类型,外部和内部都是空气传导麦克风,但使用目的不同。外部麦克风32与上述空气传导麦克风2相对应,并且用于获取目标声音和干扰声音混合的声音。内部麦克风33与辅助传感器3相对应。
[0108]
由于人的发声器官与耳朵相连,不仅外部麦克风32通过大气观察,而且内部麦克风33通过内耳和耳道观察耳机佩戴者(即用户)的话语(目标声音)。不仅外部麦克风32而且内部麦克风33都可以观察到干扰声音。然而,由于干扰声音被耳罩31衰减到一定程度,所以声音在目标声音优于内部麦克风33中的干扰声音的状态下观察。然而,由内部麦克风33观察到的目标声音穿过内耳,因此具有与从外部麦克风32导出的声音的频率分布不同的频率分布,并且可以收集除了在身体中产生的话语之外的声音(例如,吞咽声音)。因此,对于另一个人来说,听由内部麦克风33观察到的声音或者直接将声音输入到语音识别中不一定是合适的。
[0109]
鉴于以上所述,本公开通过使用由内部麦克风33观察到的声音信号作为用于声源提取的教学信息来解决该问题。具体地,该问题由于以下原因(1)至(3)而得到解决。(1)从作为空气传导麦克风2的外部麦克风32的观察信号中产生提取结果,此外,由于在学习时使用从空气传导麦克风导出的教师数据,所以提取结果中的目标声音的频率分布接近于在安静环境中记录的频率分布。(2)不仅目标声音,而且干扰声音也可以混合在由内部麦克风33观察到的声音中,即教学信息中。然而,由于使用在学习时从这样的教学信息和外部麦克风观察信号输出目标声音的数据来学习关联,所以提取结果是相对干净的声音。(3)即使内部麦克风33观察到吞咽声音等,外部麦克风32也不会观察到声音,因此不会出现在提取结果中。
[0110]
(具体示例2)
[0111]
图15是示出单耳插入式耳机40中的空气传导麦克风2和辅助传感器3的具体示例的图。外部麦克风42设置在壳体41的外部。外部麦克风42对应于空气传导麦克风2。外部麦克风42观察混合声音,在该混合声音中,目标声音和在空气中传输的干扰声音混合。
[0112]
耳机43是要插入用户耳道的部分。内部麦克风44设置在耳机43的一部分中。内部麦克风44与辅助传感器3相对应。在内部麦克风44中,观察到通过内耳传输的目标声音和通过壳体部分衰减的干扰声音混合的声音。由于提取声源的方法类似于图14所示的耳机的方法,所以将省略多余的描述。
[0113]
(其他具体示例)
[0114]
注意,辅助传感器3不限于空气传导麦克风,并且可以使用除麦克风之外的其他类
型的麦克风和传感器。
[0115]
例如,作为辅助传感器3,可以使用能够获取直接在体内传播的声波的麦克风,例如,骨传导麦克风或喉部麦克风。由于在体内传播的声波几乎不受在大气中传播的干扰声音的影响,因此认为由这些麦克风获取的声音信号接近用户干净的话语声音。然而,在实践中,类似于在图14的耳机30中使用内部麦克风33的情况,存在出现诸如频率分布差异和吞咽声音的问题的可能性。鉴于以上描述,通过使用骨传导麦克风、喉部麦克风等作为辅助传感器3并利用教学提取声源来解决该问题。
[0116]
作为辅助传感器3,也可以应用检测除声波之外的信号的传感器,诸如,光学传感器。发出声音的物体的表面(例如,肌肉)振动,在人体的情况下,靠近发声器官的喉咙和脸颊的皮肤根据人体发出的声音振动。为此,通过光学传感器以非接触方式检测振动,可以检测话语本身的存在或不存在,或者估计语音本身。
[0117]
例如,已经提出了使用检测振动的光学传感器来检测话语区段的技术。此外,还提出了一种技术,其中,通过将激光应用于皮肤而产生的斑点的亮度由具有高帧速率的相机来观察,并且根据亮度的变化来估计声音。虽然在本示例中也使用了光学传感器,但是光学传感器的检测结果并不用于话语区段检测或声音估计,而是用于带有教学的声源提取。
[0118]
将描述使用光学传感器的具体示例。从诸如激光指示器或led的光源发射的光施加到发声器官附近的皮肤,例如,脸颊、喉咙和后脑勺。通过施加光在皮肤上产生光点。光点的亮度由光学传感器观察。该光学传感器与辅助传感器3相对应,并且附接到用户的身体。为了便于光收集,光学传感器和光源可以集成。
[0119]
为了便于携带,空气传导麦克风2可以与光传感器和光源集成在一起。由空气传导麦克风2获取的信号作为麦克风观察信号输入到模块,并且由光学传感器获取的信号作为教学信息输入到模块。
[0120]
虽然在上述示例中使用检测振动的光学传感器作为辅助传感器3,但是也可以使用其他类型的传感器,只要这些传感器获取与用户的话语同步的信号。其示例包括用于获取下颌和嘴唇附近的肌肉的肌电位的肌电传感器、用于获取下颌附近的运动的加速度传感器等。
[0121]
[处理流程]
[0122]
(整体处理流程)
[0123]
接下来,将描述根据实施例的信号处理装置10执行的处理的流程。图16是示出根据实施例的信号处理装置10执行的整体处理的流程的流程图。当处理开始时,在步骤st1中,由空气传导麦克风2获取麦克风观察信号。然后,处理进行到步骤st2。
[0124]
在步骤st2中,辅助传感器3获取作为一维时间序列信号的教学信息。然后,处理进行到步骤st3。
[0125]
在步骤st3,声源提取单元12使用麦克风观察信号和教学信息生成提取结果,即目标声音信号。然后,处理进行到步骤st4。
[0126]
在步骤st4,确定该系列处理是否已经结束。这种确定处理例如由信号处理装置10的控制单元13执行。如果该系列处理没有结束,则处理返回到步骤st1,并且重复上述处理。
[0127]
注意,尽管图16中未示出,但是在通过根据步骤st3的处理生成目标声音信号之后,执行后处理单元14的处理。如上所述,后处理单元14的处理是根据应用信号处理装置10
的装置的处理(通话、记录、语音识别等)。
[0128]
(声源提取单元的处理流程)
[0129]
接下来,将参照图17中的流程图描述在图16中的步骤st3中由声源提取单元12执行的处理的流程。
[0130]
当处理开始时,在步骤st11中,执行由ad转换单元12a进行的ad转换处理。具体地,由空气传导麦克风2获取的模拟信号转换成麦克风观察信号,该麦克风观察信号是数字信号。另外,在麦克风用作辅助传感器3的情况下,由辅助传感器3获取的模拟信号被转换成作为数字信号的教学信息。然后,处理进行到步骤st12。
[0131]
在步骤st12中,特征量生成单元12b执行特征量生成处理。具体地,麦克风观察信号和教学信息由特征量生成单元12b转换成输入特征量。然后,处理进行到步骤st13。
[0132]
在步骤st13中,执行提取模型单元12c的输出特征量生成处理。具体地,在步骤st12中生成的输入特征量输入到作为提取模型的神经网络,并且执行预定的前向传播处理,以生成输出特征量。然后,处理进行到步骤st14。
[0133]
在步骤st14中,执行重构单元12d的重构处理。具体地,对步骤st13中生成的输出特征量应用复频谱的生成、逆短时傅立叶变换等,从而生成作为声音波形或类似数据的目标声音信号。然后,处理结束。
[0134]
注意,根据声源提取处理之后的处理,可以生成除声音波形之外的数据,或者可以省略重构处理本身。例如,在后续阶段执行语音识别的情况下,可以在重构处理中生成用于语音识别的特征量,或者可以在重构处理中生成幅度谱,以从语音识别中的幅度谱生成用于语音识别的特征量。此外,当学习提取模型,以输出幅度谱时,可以跳过重构处理本身。
[0135]
注意,可以改变上述流程图中所示的一些处理的处理顺序,或者可以并行执行多个处理。
[0136]
[通过实施获得的效果]
[0137]
根据本实施例,例如,可以获得以下效果。
[0138]
根据该实施例的信号处理装置10包括获取混合了目标声音和干扰声音的混合声音(麦克风观察信号)的空气传导麦克风2以及获取与用户的话语同步的一维时间序列的辅助传感器3。通过使用由辅助传感器3获取的信号作为关于麦克风观察信号的教学信息来执行具有教学的声源提取,在干扰声音是语音的情况下,可以选择性地仅提取用户的话语,并且在干扰声音是非语音的情况下,与没有教学信息的情况相比,随着输入数据的信息量增加,可以以高精度提取。
[0139]
具有教学的声源提取使用一种模型,在该模型中,预先学习干净目标声音和作为麦克风观察信号的输入数据与教学信息之间的对应关系。为此,教学信息可以包括干扰声音,只要该声音与学习时使用的数据相似。此外,教学信息可以是声音或者可以是声音以外的形式。即,由于教学信息不需要是声音,所以可以使用与话语同步的任意一维时间序列信号,作为教学信息。
[0140]
另外,根据本实施例,传感器的最小数量是两个,即,空气传导麦克风2和辅助传感器3。为此,与使用大量空气传导麦克风通过波束成形处理提取声源的情况相比,系统本身可以缩小尺寸。另外,由于可以携带辅助传感器3,所以该实施例可以应用于各种场景。
[0141]
例如,也可以设想应用不是一维时间序列信号的信号,例如,包括空间信息的图像
信息,作为教学信息。然而,用户自己很难佩戴捕捉正在说话的用户的面部图像(嘴)的相机,并且总是获取能够运动的用户的面部图像。另一方面,在该实施例中使用的教学信息是通过内耳传输的用户话语、说话者皮肤的振动、说话者嘴附近的肌肉的运动等,并且用户容易佩戴或携带观察他们的传感器。为此,即使在用户运动的情况下,也可以容易地应用该实施例。
[0142]
在本实施例中,由于与用户话语同步的信号用作教学信息,所以即使在不能获取用户干净声音的情况下,也可以高精度地执行提取。为此,还可以容易地允许多人共享一个信号处理装置10,或者允许未指定数量的人在短时间内使用信号处理装置10。
[0143]
<2.修改>
[0144]
虽然上面已经具体描述了本公开的实施例,但是本公开的内容不限于上述实施例,并且基于本公开的技术思想的各种修改是可能的。在下文中,将描述修改。注意,在修改的描述中,相同的附图标记被给予与根据上述实施例的那些相同或相似的配置,并且将适当地省略多余的描述。
[0145]
[修改1]
[0146]
修改1是同时估计具有教学的声源提取和话语区段估计的示例。在上述实施例中,声源提取单元12生成提取结果,并且话语区段估计单元14c基于提取结果生成话语区段信息。然而,在修改1中,提取结果与话语区段信息的生成同时生成。
[0147]
执行这种同时估计的原因是为了在干扰声音也是声音的情况下提高话语区段估计的准确性。这一点将参照图2进行描述。在不仅目标声音而且干扰声音都是声音的情况下,与干扰声音是非声音的情况相比,识别精度可能大大降低。一个原因是话语区段估计失败。在基于输入声音是否可能是声音来估计话语区段的方法中,在目标声音和干扰声音都是声音的情况下,无法区分目标声音和干扰声音。因此,仅存在干扰声音的区段也被检测为话语区段,这导致识别错误。例如,作为包括作为话语区段的目标声音之前和之后存在的干扰声音的长区段的检测结果,可以获得识别结果,其中,在从原始目标声音导出的词串之前和之后连接从干扰声音导出的不必要的词串。作为当仅存在干扰声音时检测作为话语区段的区段的结果,可能产生不必要的识别结果。
[0148]
即使在对声源提取单元12的提取结果执行话语区段估计的情况下,只要在提取结果中存在干扰声音的消除残留,也有可能出现相同的问题。即,提取结果不一定是完全去除了干扰声音的理想信号(参见图2的d),并且可以在目标声音之前和之后连接从干扰声音导出的小音量的声音。当对这样的信号执行话语区段估计时,存在比真实目标声音长的区段被估计为话语区段或者干扰声音的消除残余被检测为话语区段的可能性。
[0149]
除了作为声源提取单元12的输出的提取结果之外,话语区段估计单元14c还打算通过使用从辅助传感器3导出的教学信息来提高区段估计精度。然而,在作为声音的干扰声音也在教学信息中混合的情况下(例如,在图2的b中,干扰声音4b也是声音),仍然存在比原始话语长的区段被估计为话语区段的可能性。
[0150]
鉴于以上描述,当学习神经网络时,不仅学习干净目标声音与麦克风观察信号和教学信息这两个输入之间的对应关系,而且学习关于该声音是在话语区段内部还是外部的确定结果与两个输入之间的对应关系。然后,当使用信号处理装置时,同时执行提取结果的生成和话语区段的确定(输出两种类型的信息),以解决上述问题。即,即使在提取结果中存
在作为声音的干扰声音的消除残余,如果在该时间的另一输出显示确定结果为“在话语区段之外”,则可以避免仅存在干扰声音的区段被估计为话语区段的问题。
[0151]
图18是示出根据修改1的信号处理装置(信号处理装置10a)的配置示例的图。图18中所示的信号处理装置10a和图6与具体示出的信号处理装置10之间的区别在于,根据信号处理装置10的声源提取单元12和话语区段估计单元14c集成,并且被称为声源提取/话语区段估计单元52的模块代替。声源提取/话语区段估计单元52有两个输出。一个是声源提取结果,声源提取结果被发送到语音识别单元14d。另一个是话语区段信息,并且话语区段信息也被发送到语音识别单元14d。
[0152]
图19示出了声源提取/话语区段估计单元52的详细信息。声源提取/话语区段估计单元52和声源提取单元12之间的区别在于,提取模型单元12c由提取/检测模型单元12f代替,并且新提供了区段跟踪单元12g。其他模块与声源提取单元12的模块相同。
[0153]
提取/检测模型单元12f有两个输出。一个输出被输出到重构单元12d,并且生成目标声音信号作为声源提取结果。另一个输出被发送到区段跟踪单元12g。后一数据是话语检测的确定结果,并且是例如针对每个帧二进制化的确定结果。换言之,用户话语在帧中的存在与否由值“1”或“0”来表示。因为这是话语的存在或不存在,而不是声音的存在或不存在,所以在用户没有发声的时间产生作为声音的干扰声音的情况下,理想值是“0”。
[0154]
区段跟踪单元12g通过在时间方向上跟踪每个帧的确定结果来获得作为话语区段信息的话语开始时间和结束时间。作为处理的示例,如果确定结果1持续预定时间长度或更长,则被视为话语的开始,并且类似地,如果确定结果0持续预定时间长度或更长,则被视为话语的结束。可替代地,代替基于这种规则的方法,可以通过基于使用神经网络的学习的已知方法来执行跟踪。
[0155]
在上述示例中,已经描述了从提取/检测模型单元12f输出的确定结果是二进制值,但是可以替代地输出连续值,并且可以通过区段跟踪单元12g中的预定阈值来执行二进制化。如此获得的声源提取结果和话语区段信息被发送到语音识别单元14d。
[0156]
接下来,将参照图20描述提取/检测模型单元12f的详细信息。提取/检测模型单元12f与提取模型单元12c的不同之处在于,存在两种类型的输出层(输出层121f和输出层122f)。输出层121f类似于提取模型单元12c的输出层124c操作,从而输出与声源提取结果相对应的数据。另一方面,输出层122f输出话语检测的确定结果。具体地,这是针对每一帧二进制化的确定结果。
[0157]
虽然输出侧的分支发生在作为图20中的前一层的中间层n中,但是分支可以发生在比中间层n更靠近输入层的中间层中。在这种情况下,从分支发生的中间层到每个输出层的层数可以不同,并且作为示例,可以使用从中间层输出一个输出数据的网络结构。
[0158]
接下来,将参照图21描述提取/检测模型单元12f的学习系统。与提取模型单元12c不同,提取/检测模型单元12f输出两种类型的数据,因此需要执与提取模型单元12c不同的学习。学习输出多种类型数据的神经网络称为多任务学习,图21是一种多任务学习机。一种已知的方法可以应用于多任务学习。
[0159]
目标声音数据集61是包括以下三个信号(a)至(c)的集合的组。(a)目标声音波形(声音波形包括作为目标声音的语音话语和在语音话语之前和之后连接的预定长度的静音)、(b)与(a)同步的教学信息、以及(c)与(a)同步的话语确定标志。
[0160]
作为上述(c)的示例,可以考虑通过将(a)划分成预定时间间隔(例如,与图9的短时傅立叶变换的移位宽度相同的时间间隔),然后如果在每个时间间隔内有发声,则分配值“1”,如果在每个时间间隔内没有发声,则分配值“0”,而生成的位串。
[0161]
在学习时,从目标声音数据集61中随机提取一集合,并且该集合中的教学信息被输出到混合单元64(在通过空气传导麦克风获取教学信息的情况下)或特征量生成单元65(在其他情况下),目标声音波形被输出到混合单元63和教师数据生成单元66,并且话语确定标志被输出到教师数据生成单元67。另外,从干扰声音数据集62中随机提取一个或多个声音波形,并将提取的声音波形发送到混合单元63。在通过空气传导麦克风获取教学信息的情况下,干扰声音的声音波形也被发送到混合单元64。
[0162]
由于提取/检测模型单元12f输出两种类型的数据,所以准备每种类型数据的教师数据。教师数据生成单元66生成与声源提取结果相对应的教师数据。教师数据生成单元67生成与话语检测结果相对应的教师数据。在话语确定标志是如上所述的位串的情况下,话语确定标志可以原样用作教师数据。在下文中,由教师数据生成单元66生成的教师数据被称为教师数据1d,并且由教师数据生成单元67生成的教师数据被称为教师数据2d。
[0163]
由于提取/检测模型单元12f有两种类型的输出,所以还需要两个比较单元。在两种类型的输出中,与声源提取结果相对应的输出被输出到比较单元70,并且被比较单元70与教师数据1d进行比较。比较单元70的操作与上述图12中的比较单元27的操作相同。另一方面,与话语检测结果相对应的输出被输出到比较单元71,并且被比较单元71与教师数据2d进行比较。比较单元71也使用类似于比较单元70的损失函数,但是这是用于学习二进制分类器的损失函数。
[0164]
参数更新值计算单元72计算提取/检测模型单元12f的参数的更新值,使得损失值从由两个比较单元70和71计算的损失值减小。作为多任务学习中的参数更新方法,可以使用已知的方法。
[0165]
[修改2]
[0166]
在上述修改1中,假设声源提取结果和话语区段信息被单独发送到语音识别单元14d侧,并且在语音识别单元14d侧执行划分成话语区段和生成作为识别结果的字串。另一方面,在修改2中,可以临时生成通过集成声源提取结果和话语区段信息获得的数据,并且可以输出生成的数据。在下文中,将描述修改2。
[0167]
图22是示出根据修改2的信号处理装置(信号处理装置10b)的配置示例的图。信号处理装置10b与信号处理装置10a的不同之处在于,在信号处理装置10b中,从声源提取/话语区段估计单元52输出的两种类型的数据(声源提取结果和话语区段信息)输入到区段外消音单元55,并且区段外消音单元55的输出输入到新设置的话语划分单元14h或语音识别单元14d。其他配置与信号处理装置10a的配置相同。
[0168]
区段外消音单元55通过将话语区段信息应用于作为声音信号的声源提取结果来生成新的声音信号。具体地,区段外消音单元55执行用静音或接近静音的声音来替换与话语区段之外的时间相对应的声音信号的处理。接近静音的声音例如是通过将声源提取结果乘以接近0的正常数而获得的信号。另外,在不执行声音再现的情况下,并非用静音代替声音信号,可以用不会对后续阶段中的话语划分单元14h和语音识别单元14d产生不利影响的类型的噪声来代替声音信号。
[0169]
区段外消音单元55的输出是连续流,并且为了将该流输入到语音识别单元14d,通过以下方法(1)和(2)中的一种来处理该流。(1)在区段外消音单元55与语音识别单元14d之间添加话语划分单元14h。(2)使用与流输入相关的语音识别,被称为顺序语音识别。在(2)的情况下,可以省略话语划分单元14h。作为话语划分单元14h,可以应用已知的方法(例如,日本专利号4182444中描述的方法)。
[0170]
可以应用已知的方法(例如,日本专利公开2012
‑
226068中描述的方法),作为顺序语音识别。由于静音的声音信号(或不会对后续阶段的操作产生不利影响的声音)通过区段外消音单元55的操作被输入到除了用户正在讲话的区段之外的区段中,所以声音信号被输入到的话语划分单元14h或语音识别单元14d可以比直接输入声源提取结果的情况更准确地操作。此外,通过在声源/话语区段估计单元52的后续阶段中提供区段外消音单元55,本公开教学的声源提取不仅可以应用于包括顺序语音识别机的系统,还可以应用于话语划分单元14h和语音识别单元14d集成的系统。
[0171]
当对声源提取结果执行话语区段估计时,在干扰声音也是声音的情况下,话语区段估计对干扰声音的消除残余做出反应,这可能导致错误识别或产生不必要的识别结果。在该修改中,声源提取和话语区段估计的两个估计处理同时执行,使得即使声源提取结果包括干扰声音的消除残余,也独立于此执行准确的话语区段估计,结果,可以提高语音识别精度。
[0172]
[其他修改]
[0173]
将描述其他修改。
[0174]
上述信号处理装置中的全部或区段处理可以由云中的服务器等来执行。另外,目标声音可以是除了人发出的声音之外的声音(例如,机器人或宠物的声音)。此外,辅助传感器可以附接到机器人或宠物,而不是人。另外,辅助传感器可以是不同类型的多个辅助传感器,并且要使用的辅助传感器可以根据使用信号处理装置的环境来切换。另外,本公开还可以应用于为每个对象生成声源。
[0175]
注意,由于根据辅助传感器的类型可以省略图12中的“混合单元24”和图21中的“混合单元64”,所以在括号中示出图12中的“混合单元24”和图21中的“混合单元64”。
[0176]
注意,本公开的内容不应被解释为受本公开中示例的效果的限制。
[0177]
本公开还可以采用以下配置。
[0178]
(1)一种信号处理装置,包括:
[0179]
输入单元,包括混合有目标声音和除目标声音之外的声音的混合声音的麦克风信号、和由辅助传感器获取并与目标声音同步的一维时间序列信号输入到该输入单元;以及
[0180]
声源提取单元,基于一维时间序列信号从麦克风信号中提取对应于目标声音的目标声音信号。
[0181]
(2)根据(1)的信号处理装置,其中,
[0182]
声源提取单元使用基于一维时间序列信号生成的教学信息来提取目标声音信号。
[0183]
(3)根据(1)或(2)的信号处理装置,其中,
[0184]
辅助传感器包括附接到目标声音的源的传感器。
[0185]
(4)根据(1)至(3)中任一项的信号处理装置,其中,
[0186]
麦克风信号包括由第一麦克风检测的信号,并且
[0187]
辅助传感器包括与第一麦克风不同的第二麦克风。
[0188]
(5)根据(4)的信号处理装置,其中,
[0189]
第一麦克风包括设置在耳机的壳体的外部的麦克风,并且第二麦克风包括设置在壳体的内部的麦克风。
[0190]
(6)根据(1)至(4)中任一项的信号处理装置,其中,
[0191]
辅助传感器包括检测在体内传播的声波的传感器。
[0192]
(7)根据(1)至(4)中任一项的信号处理装置,其中,
[0193]
辅助传感器包括检测除声波之外的信号的传感器。
[0194]
(8)根据(7)的信号处理装置,其中,
[0195]
辅助传感器包括检测肌肉的运动的传感器。
[0196]
(9)根据(1)至(8)中任一项的信号处理装置,还包括:
[0197]
再现单元,再现由声源提取单元提取的目标声音信号。
[0198]
(10)根据(1)至(8)中任一项的信号处理装置,还包括:
[0199]
通信单元,将由声源提取单元提取的目标声音信号发送到外部装置。
[0200]
(11)根据(1)至(8)中任一项的信号处理装置,还包括:
[0201]
话语区段估计单元,基于声源提取单元的提取结果来估计指示话语存在或不存在的话语区段,并且生成话语区段信息作为估计结果;以及
[0202]
语音识别单元,在话语区段中执行语音识别。
[0203]
(12)根据(1)至(8)中任一项的信号处理装置,其中,
[0204]
声源提取单元还被配置作为声源提取/话语区段估计单元,该声源提取/话语区段估计单元估计指示话语存在或不存在的话语区段,并且生成话语区段信息作为估计结果,并且
[0205]
声源提取/话语区段估计单元输出目标声音信号和话语区段信息。
[0206]
(13)根据(12)的信号处理装置,还包括
[0207]
区段外消音单元,基于从声源提取/话语区段估计单元输出的话语区段信息,确定与目标声音信号中的话语区段之外的时间相对应的声音信号,并使所确定的声音信号消音。
[0208]
(14)根据(1)至(8)、(11)或(12)中任一项的信号处理装置,其中,
[0209]
声源提取单元包括提取模型单元,该提取模型单元接收基于麦克风信号的第一特征量和基于一维时间序列信号的第二特征量作为输入、对该输入执行前向传播处理、并输出输出特征量。
[0210]
(15)根据(1)至(8)、(12)或(13)中任一项的信号处理装置,其中,
[0211]
声源提取单元包括提取/检测模型单元,提取/检测模型单元接收基于麦克风信号的第一特征量和基于一维时间序列信号的第二特征量,作为输入,对输入执行前向传播处理,并输出多个输出特征量。
[0212]
(16)根据(14)或(15)的信号处理装置,还包括:
[0213]
重构单元,基于输出特征量至少生成目标声音信号。
[0214]
(17)根据(14)或(15)的信号处理装置,其中,
[0215]
预先学习输入特征量与输出特征量之间的对应关系。
[0216]
(18)一种信号处理方法,包括:
[0217]
将包括混合有目标声音和除目标声音之外的声音的混合声音的麦克风信号、和由辅助传感器获取并与目标声音同步的一维时间序列信号输入到输入单元;并且
[0218]
由声源提取单元基于一维时间序列信号从麦克风信号中提取与目标声音相对应的目标声音信号。
[0219]
(19)一种程序,用于使计算机执行信号处理方法,该信号处理方法包括:
[0220]
将包括混合有目标声音和除目标声音之外的声音的混合声音的麦克风信号、和由辅助传感器获取并与目标声音同步的一维时间序列信号输入到输入单元;并且
[0221]
由声源提取单元基于一维时间序列信号从麦克风信号中提取与目标声音相对应的目标声音信号。
[0222]
附图标记列表
[0223]
2 空气传导麦克风
[0224]
3 辅助传感器
[0225]
10、10a、10b 信号处理装置
[0226]
11 输入单元
[0227]
12 声源提取单元
[0228]
12c 提取模型单元
[0229]
12d 重构单元
[0230]
14a 声音再现单元
[0231]
14b 通信单元
[0232]
32、33、42、44 麦克风
[0233]
52 声源提取/话语区段估计单元
[0234]
55 区段外消音单元。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。