1.本发明是有关于一种语音识别技术,且特别是有关于一种应用神经网络模型的语意辨识方法与语意辨识装置。
背景技术:
2.随着科技的进步,越来越多的电子装置开始使用语音控制,语音控制今后将成为大多数电子装置常用的用户接口。由此可知,语音识别(speech recognition)的辨识率将直接影响用户使用电子装置的用户体验。在语音控制的应用领域中,当语音指令是限制为具有固定语音长度且语音指令的词汇顺序是固定的时,语音识别所需的运算资源较少,但使用上非常不人性化且误判率较高。像是,当用户说出不同词汇顺序的语音指令或具有赘词的语音指令或存在周围噪音干扰时,误判率皆会大幅上升。举例而言,当语音指令被设计为“打开电视”但用户说出“电视打开”的语句时,就会发生无法辨识语音指令的情况。“3.另一方面,自然语言理解(natural language understanding,nlu)技术是目前重要的关键技术。自然语言理解技术能负责提取使用者语句中的关键信息,并且能判断使用者的意图,以对应于使用者的意图执行后续处理。因此,当应用可以进行词汇分割与词汇重新排列的nlu技术时,语音指令的语音长度与的词汇顺序可以是不固定的,好让使用者可依据自己习惯的说话方式来下达语音指令。然而,在实际应用中,自然语言理解技术所需的运算资源相当大,不易实做于嵌入式系统中。举例而言,在应用自然语言理解技术来实现语音识别的情境中,数据量庞大的声学数据库与语言数据库都是必须的,因而运算处理一般都是由云端计算平台来负责。
技术实现要素:
4.有鉴于此,本发明提出一种语意辨识方法与语意辨识装置,其可在无须云端运算资源的条件下增加语意辨识的弹性。
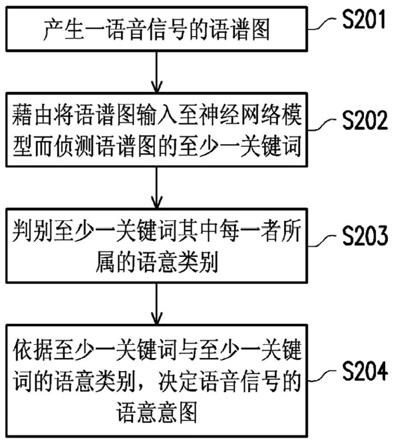
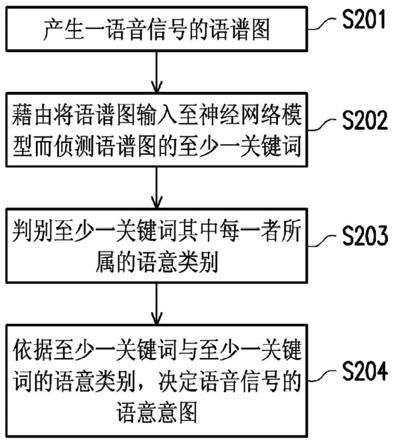
5.本发明实施例提供一种语意辨识方法,其包括下列步骤。产生一语音信号的语谱图。通过将语谱图输入至一神经网络模型而侦测语谱图的至少一关键词。判别至少一关键词其中每一者所属的语意类别。依据至少一关键词与至少一关键词的语意类别,决定语音信号的语意意图。
6.本发明实施例提供一种语意辨识装置,其包括存储装置以及处理电路。处理电路耦接存储装置,经配置以执行存储装置中的指令,以执行下列步骤。产生一语音信号的语谱图。通过将语谱图输入至一神经网络模型而侦测语谱图的至少一关键词。判别至少一关键词其中每一者所属的语意类别。依据至少一关键词与至少一关键词的语意类别,决定语音信号的语意意图。
7.基于上述,于本发明的实施例中,由经训练的神经网络模型对语音信号的语谱图进行目标特征的侦测。通过自语音信号的语谱图侦测出关键词所对应的目标特征区块,可自语音信号中辨识出关键词。因此,语音信号的语意意图可基于一或多个关键词各自的语
only memory,rom)、闪存(flash memory)、硬盘或其他类似装置、集成电路及其组合。于一实施例中,存储装置110可记录有神经网络模型与其模型参数。
34.处理电路120耦接存储装置110,例如是中央处理单元(central processing unit,cpu),或是其他可程序化之一般用途或特殊用途的微处理器(microprocessor)、数字信号处理器(digital signal processor,dsp)、可程序化控制器、特殊应用集成电路(application specific integrated circuits,asic)、可程序化逻辑设备(programmable logic device,pld)或其他类似装置或这些装置的组合。于一实施例中,处理电路120可执行记录于存储装置110中的程序代码、固件/软件模块、指令等等,以实现本发明实施例的语意辨识方法。
35.图2是依照本发明一实施例的语意辨识方法的流程图。请参照图1与图2,本实施例的方法适用于图1中的语意辨识装置100,以下即搭配语意辨识装置100中的各项组件说明本实施例方法的详细流程。
36.于步骤s201,处理电路120产生一语音信号的语谱图。透过收音装置(例如麦克风)接收用户说出的语音信号,处理电路120可获取语音信号。接着,处理电路120可对模拟的时域(time-domain)语音信号进行一系列的语音处理而产生对应的语谱图。语谱图(spectrogram,亦称为声谱图)用以表示语音信号随时间变化的语音频谱特性。语谱图的横轴表示时间,语谱图的纵轴表示频率,而语谱图上每一特征点的颜色深浅则用以表示特定频带的能量强度。换言之,语谱图包括语音信号的时间信息、频率信息与强度信息。语音信号中许多有用的信息可通过语谱图彰显出来,像是音量大小、中心频率、频率分布范围与语音长度等等。
37.于一实施例中,处理电路120可使用快速傅立叶变换(fast fourier transformation,fft)将语音信号转换为语谱图。或者,于一实施例中,处理电路120可使用快速傅立叶变换与梅尔滤波(mel-filtering)将语音信号转换为语谱图。
38.详细而言,图3是依照本发明一实施例的产生语谱图的流程图。请参照图3,于步骤s301,处理电路120可对语音信号进行音频预处理。处理电路120可先对模拟的时域语音信号进行取样而获得取样后的语音信号,而取样频率例如是8k赫兹或16k赫兹等等,本发明对此不限制。接着,处理电路120可进行预加重(pre-emphasis)处理与音框化(frame blocking)处理。详细而言,处理电路120可使用高通滤波器来进行预加重处理。接着,处理电路120可通过将n个取样数据组为一个音框(frame)来进行音框化处理。
39.于步骤s302,处理电路120可进行加窗处理。举例而言,处理电路120可通过将每一个音框乘上汉明窗(hamming window)来进行加窗处理。于步骤s303,处理电路120可进行快速傅立叶变换。具体而言,处理电路120可透过快速傅立叶变换对一个取样时段(亦即一个音框)内的时域数据进行时间频率变换处理,而获得关联于一个音框的频谱信息。频域信息包括对应至不同频率的频谱系数。
40.于一实施例中,于步骤s304,处理电路120可进一步进行梅尔滤波处理,以产生语谱图s1。具体而言,处理电路120可将快速傅立叶变换产生的频谱信息输入至多个非线性分布的三角带通滤波器(triangular bandpass filters)进行滤波,以获取梅尔倒频谱系数(mel-frequency cepstral coefficient,mfcc)。梅尔倒频谱系数模拟了人耳的听觉特性,能够反映人对语音的感知特性,可取得较高的辨识率。接着,处理电路120可将对应至不同
时间的多个音框的梅尔倒频谱系数组合起来而获取语谱图s1。如图3所示,语谱图s1的横轴表示时间(单位:秒),语谱图的纵轴表示频率(单位:千赫兹(khz)),而语谱图上每一特征点的颜色深浅则用以表示特定频带的能量强度。然而,本发明对于语谱图的时间长度并不加以限制,其可视实际需求而设置。
41.需说明的是,于一实施例中,处理电路120可直接依据快速傅立叶变换所产生的频谱信息产生语谱图,并将对应至不同时间的每一音框的频谱信息组合起来而获取语谱图。由此可知,步骤s304的实施是选择性的。
42.回到图2的流程,在获取语音信号的语谱图之后,于步骤s202,处理电路120通过将语谱图输入至一神经网络模型而侦测语谱图的至少一关键词。于此,语音信号的语谱图可包括p*q个特征点(p与q为正整数),而语谱图可视为一张用以输入至神经网络模型的影像数据。处理电路120可使用神经网络模型来判断语谱图是否包括对应至关键词的目标特征区块。处理电路120将语谱图输入至神经网络模型,以自语谱图中侦测对应至至少一关键词的至少一目标特征区块。
43.于此,经训练的神经网络模型是依据训练数据集进行深度学习而事先建构,其可存储于存储装置110中。换言之,经训练的神经网络模型的模型参数(例如神经网络层数目与各神经网络层的权重等等)已经由事前训练而决定并存储于存储装置110中。具体而言,当语谱图输入至神经网络模型时,首先进行特征撷取而产生特征向量(feature vector)。之后,这些特征向量会被输入至神经网络模型中的分类器,分类器再依照此些特征向量进行分类,进而侦测出语谱图中对应至关键词的目标特征区块。于此,神经网络模型可包括卷积神经网络(convolution neural network,cnn)模型或应用注意力机制(attention mechanism)的神经网络模型。举例而言,神经网络模型可为卷积神经网络(convolution neural network,cnn)模型中用以进行目标特征侦测的r-cnn、fast r-cnn、faster r-cnn、yolo或ssd等等,但本发明对此不限制。
44.图4是依照本发明一实施例的依据cnn模型侦测关键词的示意图。请参照图4,以下将语谱图s1输入至cnn模型为例进行说明。在本范例中,卷积神经网络400是由至少一个的卷积层(convolution layer)410、至少一个的池化层(pooling layer)420、至少一个的全连接层(fully connected layer)430以及输出层440所构成。
45.在卷积神经网络400的前段通常由卷积层410与池化层420串连组成,用以取得语谱图s1的特征值。此特征值可以是多维数组,一般被视为输入的语谱图s1的特征向量。在卷积神经网络400的后段包括全连接层430与输出层440,全连接层430与输出层440会根据经由卷积层410与池化层420所产生的特征值来将语谱图s1中的物件(即目标特征区块)进行分类,并且可以取得物件分类信息450。物件分类信息450将可包括分类类别与分类机率。图4的范例中,处理电路120可透过卷积神经网络400自语谱图s1侦测到分类为“电视”的目标特征区块obj1。目标特征区块obj1对应至分类机率p1。藉此,处理电路120可判定从语谱图s1侦测到关键词“电视”。然而,本发明对于关键词的数量与种类并不限制,其可视实际需求而设置。
46.此外,于一实施例中,处理电路120可透过应用注意力机制的神经网络模型来侦测语谱图中的关键词。举例而言,将卷积神经网络模型产生特征向量的方法,改为以实现注意力机制的连接层取代,可建构出一个应用注意力机制的神经网络模型。
47.另一方面,为了建构可以从语谱图侦测关键词的神经网络模型,用以训练神经网络模型的训练数据集包括许多样本语谱图。这些样本语谱图是由一位以上的人员说出已知关键词而产生。在模型训练阶段,这些样本语谱图中的对应于已知关键词的区块皆已经被框选并赋予解答信息(即对应的已知关键词)。这些样本语谱图逐一输入至神经网络模型,并透过比对神经网络模型依据样本语谱图所产生的侦测结果与解答信息来计算出误差。之后,通过此误差并以倒传递的方式,来调整网络中每一个网络层的权重。误差计算的方式(即损失函数)例如是平方差或softmax等等。
48.图5是依照本发明一实施例的语谱图与目标特征区块的示意图。请参照图5,处理电路120可获取持续一分钟的语音信号au1,并产生语音信号au1的语谱图s2。接着,处理电路120可依据经训练的神经网络模型自语谱图s2侦测出多个目标特征区块n1~n9。这些目标特征区块n1~n9可各自被分类为对应至一关键词,并具有对应的分类机率。之后,处理电路120便可依据目标特征区块n1~n9各自对应的关键词来决定语意意图。换言之,本发明实施例可透过将语音信号的语谱图输入至神经网络模型来辨识出语音信号所包含的关键词,再进一步依据关键词来辨识语意意图。
49.回到图2的流程,在从语谱图侦测出至少一关键词后,于步骤s203,处理电路120可判别至少一关键词其中每一者所属的语意类别。于此,处理电路120可通过查询存储装置110中的关键词列表来判别语谱图中每一个关键词的语意类别,上述关键词列表记录有多个关键词与其对应的语意类别。上述的语意类别的数量与种类可视实际应用场合而设计,本发明对此不限制。表1为关键词列表的范例,但本发明不限制于此。
50.表1
51.编号语意类别关键词1动作打开、关闭
…
2物件电视、电扇、冷气、电灯
…
3场景房间、客厅、厕所
…
52.于步骤s204,处理电路120依据至少一关键词与至少一关键词的语意类别,决定语音信号的语意意图。于一实施例中,处理电路120可进行语意槽填充(semantic slot filling)来决定语音信号的语意意图。处理电路120依据至少一关键词的语意类别,将至少一关键词填入语意框架(semantic frame)的至少一语意槽。具体而言,于一实施例中,语意框架的多个语意槽也各自对应于语意槽类别。当关键词的语意类别相同于语意槽的语意槽类别时,处理电路120可将关键词填入对应的语意槽。反应于至少一语意槽皆填满,处理电路120可依据填入至少一语意槽中的至少一关键词决定语意意图。
53.举例而言,图6是依照本发明一实施例的辨识语意意图的示意图。请参照图6,于此范例中,三个语意槽slot1~slot3各自对应至语意槽类别“动作”、“物件”、“场景”。假设处理电路120可自语谱图侦测出三个关键词“打开”、“电视”、“房间”,则处理电路120可将关键词“打开”填入对应至语意槽类别“动作”的语意槽slot1;将关键词“电视”填入对应至语意槽类别“物件”的语意槽slot2;以及将关键词“房间”填入对应至语意槽类别“场景”的语意槽slot3。反应于三个语意槽slot1~slot3皆填满,处理电路120可输出语意意图。由此可知,于一实施例中,即便使用者说出关键词的先后顺序不同,处理电路120还是可辨识出相同的语意意图。举例而言,无论用户说出“房间电视请打开”或“打开电视在房间”,经过步骤
s201~步骤s204的执行,处理电路120都会输出相同的语意意图。
54.值得一提的是,于一实施例中,当至少一关键词中的第一关键词的语意类别相同于至少一关键词中的第二关键词的语意类别,处理电路120选择将具有第一分类机率的第一关键词填入语意框架的至少一语意槽。于此,第一关键词的第一分类机率与第二关键词的第二分类机率由神经网络模型产生,且第一分类机率大于第二分类机率。详细而言,处理电路120可能自语谱图侦测出对应至相同语意类别的一个以上的关键词(即第一关键词与第二关键词)。当进行语意槽填充时,将存在多个关键词的语意类别相同于语意槽的语意槽类别的情况,但处理电路120会选择将具有较高分类机率的其中一个关键词(即第一关键词)填入对应的语意槽。举例而言,处理电路120可能透过神经网络模型自语谱图当中同时侦测出关键词“房间”与“客厅”,且关键词“房间”对应于分类机率0.8而关键词“客厅”对应于分类机率0.5。于此情况下,处理电路120会选择将具有较高分类机率的关键词“客厅”填入语意槽,并舍弃具有较低分类机率的关键词“客厅”。
55.综上所述,于本发明的实施例中,在无须庞大的声学数据库、语言数据库以及复杂运算的情况下,可透过神经网络模型来侦测语谱图中对应于关键词的目标特征区块,因而适于实做于嵌入式系统中。神经网络模型的目标特征侦测结果可用以判别用户说出的语音信号是否包括关键词,致使使用者的语意意图可依据关键词来决定。因此,即便语音指令中的词汇顺序改变,依然可辨识出使用者的语意意图,大幅语意辨识的弹性,从而提升语音控制的实用性、便利性与应用广度。
56.最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。