1.本发明涉及语音识别技术领域,具体涉及一种方言口音普通话的语音识别优化方法及系统。
背景技术:
2.目前,语音识别仅针对标准普通话进行识别,对于方言的识别都需要针对性建立对应方言的模型,没有一个较为通用的方言口音去除的解决方案。目前的方案是针对方言口音特别严重的地区针对性建立相关的语音识别模型模块,从而减少口音对于语音识别准确度的干扰及影响。
3.现有技术中每一个方言口音识别模型都需要投入大量的成本,需要采集带有口音的普通话音频训练数据,同时对数据进行标注,后续在针对模型进行针对化训练。同时,带有方言口音的地区数量庞大,每个区域针对性建设模型时间成本以及人力成本都过大,不适合在实际场景中进行应用,因此本文提出一种方言口音普通话的语音识别优化方法及系统予以解决。
技术实现要素:
4.针对现有技术的不足,本发明公开了一种方言口音普通话的语音识别优化方法及系统,用于解决每一个方言口音识别模型都需要投入大量的成本,需要采集带有口音的普通话音频训练数据,同时对数据进行标注,后续在针对模型进行针对化训练。同时,带有方言口音的地区数量庞大,每个区域针对性建设模型时间成本以及人力成本都过大,不适合在实际场景中进行应用的问题。
5.本发明通过以下技术方案予以实现:
6.第一方面,本发明公开了一种方言口音普通话的语音识别优化方法,包括以下步骤:
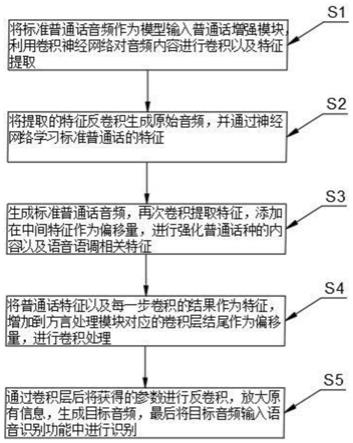
7.s1将标准普通话音频作为模型输入普通话增强模块,利用卷积神经网络对音频内容进行卷积提取特征;
8.s2将提取的特征反卷积生成原始音频,并通过神经网络学习标准普通话的特征;
9.s3生成标准普通话音频,再次卷积提取特征,添加在中间特征作为偏移量,进行强化普通话种的内容以及语音语调相关特征;
10.s4将普通话特征以及每一步卷积的结果作为特征,增加到方言处理模块对应的卷积层结尾作为偏移量,进行卷积处理;
11.s5通过卷积层后将获得的参数进行反卷积,放大原有信息,生成目标音频,最后将目标音频输入语音识别功能中进行识别。
12.更进一步的,所述方法中,普通话增强模块使用自编码的模型结构,其包括卷积部分和反卷积部分。
13.更进一步的,所述方法中,对普通话增强模块的自编码模型部分特征提取进行单
独训练,其基础输入为非单纯白噪音。
14.更进一步的,所述方法中,方言处理模块基于自编码的模型框架,在每一层卷积的结尾添加来自标准普通话模块的卷积结果参数。
15.更进一步的,所述方法中,方言处理模块携带的卷积参数包括普通话语义以及语调、含义的相关信息。
16.更进一步的,所述方法基于卷积神经网络,训练样本为同样文字阅读音频,每一段方言口音音频对应有一段标准普通话音频。
17.第二方面,本发明公开一种方言口音普通话的语音识别优化系统,所述系统用于实现如第一方面所述的一种方言口音普通话的语音识别优化方法,包括方言口音处理模块和标准普通话语音增强模块。
18.更进一步的,所述方言模块用于对方言口音音频进行特征提取,同时获得标准普通话的增强特征,对方言口音进行再生成,生成一段标准的普通话音频。
19.更进一步的,所述标准普通话增强模块用于提取标准普通话的特征以及文本内容特征,用于强化语音过程中的内容,提升语音的识别能力。
20.本发明的有益效果为:
21.本发明相比较于传统语音识别算法,仅仅单独对普通话内容进行识别,并不会通过一些增强模块对口音进行处理。
22.本发明通用型的方言口音处理模型,减少了定制化每种方言特殊模型的成本,同时利用了普通话与方言口音特征叠加的方法对需要的标准普通话的特征进行放大,泛化模型难度的同时,进一步提升了语音识别的准确度。
附图说明
23.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
24.图1是一种方言口音普通话的语音识别优化方法步骤框图;
25.图2是一种方言口音普通话的语音识别优化方法原理示意图。
具体实施方式
26.为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
27.实施例1
28.本实施例公开如图1所示的一种方言口音普通话的语音识别优化方法,包括以下步骤:
29.s1将标准普通话音频作为模型输入普通话增强模块,利用卷积神经网络对音频内容进行卷积提取特征;
30.s2将提取的特征反卷积生成原始音频,并通过神经网络学习标准普通话的特征;
31.s3生成标准普通话音频,再次卷积提取特征,添加在中间特征作为偏移量,进行强化普通话种的内容以及语音语调相关特征;
32.s4将普通话特征以及每一步卷积的结果作为特征,增加到方言处理模块对应的卷积层结尾作为偏移量,进行卷积处理;
33.s5通过卷积层后将获得的参数进行反卷积,放大原有信息,生成目标音频,最后将目标音频输入语音识别功能中进行识别。
34.本实施例通过普通话增强模块自编码的模型结构,让神经网络学习标准普通话的特征。对普通话增强模块的自编码模型部分特征提取进行单独训练,其基础输入为非单纯白噪音。
35.本实施例方言处理模块基于自编码的模型框架,在每一层卷积的结尾添加来自标准普通话模块的卷积结果参数。方言处理模块通过携带卷积参数的情况下,提升方言中普通话语义以及语调、含义的相关信息。
36.本实施例基于卷积神经网络,训练样本为同样文字阅读音频,每一段方言口音音频对应有一段标准普通话音频。
37.本实施例将输入的语音利用优化方法模型进行处理,生成去除方言口音的音频,将结果作为后续输入进行语音识别。
38.本实施例针对方言口音特别严重的地区针对性建立相关的语音识别模型模块,从而减少口音对于语音识别准确度的干扰及影响。
39.实施例2
40.本实施例公开上述方言口音普通话的语音识别优化方法的一种具体实施参照图2所示,具体如下:
41.本实施例先对普通话增强模块单独进行训练,将标准普通话音频作为模型输入,选取卷积层1:过滤器尺寸:4410x2,偏移量:441采样点。卷积层2:过滤器尺寸:441x2,偏移量:40采样点。卷积层3:过滤器尺寸:441x2,偏移量:40采样点。利用卷积神经网络对音频内容进行卷积以及特征提取。
42.本实施例基于卷积神经网络进行建设,训练样本为同样文字阅读音频,文本长度均为15个字,文本一共有3段随机选取,每段音频长度为5秒,每一段方言口音音频需要对应有一段标准普通话音频。
43.本实施例利用特征重新反卷积生成原始音频,其中选取反卷积层2:过滤器尺寸:4410x2,偏移量:441采样点。反卷积层1:过滤器尺寸:441x2,偏移量:40采样点。并通过自编码的模型结构,更好的让神经网络学习标准普通话的特征。当特征可以较完整的生成标准普通话音频后,将生成后的音频再卷积提取特征,用来添加在中间特征作为偏移量,从而强化普通话种的内容以及语音语调相关特征。
44.本实施例训练样本数量,选取广东普通话,四川普通话,湖南普通话,福建普通话,北京话音频各50段,其中男女录音各占50%。普通话录音100段,其中男女各站50%。
45.训练过程中,先对普通话增强模块的自编码模型部分特征提取进行单独训练,让模型的基础输入不是单纯的白噪音,可以进一步提升后期模型的训练效果。
46.本实施例普通话增强模块训练完成后,选择学习率:0.005,损失函数值低于0.01
时,学习率减少0.0001,训练迭代次数:5000次。将获得的普通话特征以及每一步卷积的结果作为特征,增加到方言处理模块对应的卷积层结尾作为偏移量,将普通话的特征嵌入到方言对话中。
47.本实施例方言处理模块也是基于自编码的模型框架,在每一层卷积的结尾添加了来自标准普通话模块的卷积结果参数,通过携带卷积参数的情况下,提升方言中普通话语义以及语调、含义的相关信息。
48.其中选取卷积层1:过滤器尺寸:4410x2,偏移量:441采样点。卷积层2:过滤器尺寸:441x2,偏移量:40采样点。
49.在通过卷积层后,将获得的参数进行反卷积(选取反卷积层2:过滤器尺寸:4410x2,偏移量:441采样点。反卷积层1:过滤器尺寸:441x2,偏移量:40采样点),并设定学习率:0.005,损失函数值低于0.01时,学习率减少0.0001。训练迭代次数:50000次。将原有信息进行放大,生成目标音频。最后将目标音频输入语音识别功能中进行识别。
50.本实施例相比较于传统语音识别算法,仅仅单独对普通话内容进行识别,并不会通过一些增强模块对口音进行处理。
51.本实施例减少了定制化每种方言特殊模型的成本,同时利用了普通话与方言口音特征叠加的方法对需要的标准普通话的特征进行放大,泛化模型难度的同时,进一步提升了语音识别的准确度。
52.实施例3
53.本实施例公开一种方言口音普通话的语音识别优化系统,包括方言口音处理模块和标准普通话语音增强模块。
54.本实施例方言模块主要对方言口音音频进行特征提取,同时获得标准普通话的增强特征,对方言口音进行再生成,生成一段标准的普通话音频。
55.本实施例标准普通话增强模块用于提取标准普通话的特征以及文本内容特征,用于强化语音过程中的内容,提升语音的识别能力。
56.本实施例系统整体基于卷积神经网络进行建设,训练样本为同样文字阅读音频,文本长度均为15个字,文本一共有3段随机选取,每段音频长度为5秒,每一段方言口音音频需要对应有一段标准普通话音频。
57.本实施例训练样本数量,选取广东普通话,四川普通话,湖南普通话,福建普通话,北京话音频各50段,其中男女录音各占50%。普通话录音100段,其中男女各站50%。
58.本实施例标准普通话模块参数为:
59.输入音频向量为:44100x5x2;
60.卷积层1:过滤器尺寸:4410x2,偏移量:441采样点;
61.卷积层2:过滤器尺寸:441x2,偏移量:40采样点;
62.卷积层3:过滤器尺寸:441x2,偏移量:40采样点;
63.反卷积层2:过滤器尺寸:4410x2,偏移量:441采样点;
64.反卷积层1:过滤器尺寸:441x2,偏移量:40采样点;
65.学习率:0.005,损失函数值低于0.01时,学习率减少0.0001;
66.训练迭代次数:5000次。
67.本实施例方言处理模块参数为:
68.输入音频向量为:44100x5x2;
69.卷积层1:过滤器尺寸:4410x2,偏移量:441采样点;
70.卷积层2:过滤器尺寸:441x2,偏移量:40采样点;
71.反卷积层2:过滤器尺寸:4410x2,偏移量:441采样点;
72.反卷积层1:过滤器尺寸:441x2,偏移量:40采样点;
73.学习率:0.005,损失函数值低于0.01时,学习率减少0.0001;
74.训练迭代次数:50000次。
75.本发明解决了每一个方言口音识别模型都需要投入大量的成本,需要采集带有口音的普通话音频训练数据,同时对数据进行标注,后续在针对模型进行针对化训练。同时,带有方言口音的地区数量庞大,每个区域针对性建设模型时间成本以及人力成本都过大,不适合在实际场景中进行应用的问题。
76.本发明相比较于传统语音识别算法,仅仅单独对普通话内容进行识别,并不会通过一些增强模块对口音进行处理。
77.本发明通用型的方言口音处理模型,减少了定制化每种方言特殊模型的成本,同时利用了普通话与方言口音特征叠加的方法对需要的标准普通话的特征进行放大,泛化模型难度的同时,进一步提升了语音识别的准确度。
78.以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
