基于yolov3和c3d神经网络的视频中异常人体行为检测
技术领域
1.本发明涉及视频处理和神经网络领域,设计了一种基于yolov3(you only look once version 3)和c3d(convolutional 3d)神经网络的视频中异常人体行为检测模型,并给出了具体的实现方法。该方法的特色在于,当前许多方法在提取行为特征时,往往把整个视频帧作为输入,但在一个视频帧中,人体只占整个画面的一部分,因此使得模型提取出无用的特征。针对这个问题,本发明使用yolov3定位视频帧中的人体,再基于人体区域提取行为特征,以便于模型能够不受环境影响,更加鲁棒、细致地对行为信息进行学习。另外,卷积神经网络被广泛用于图像特征提取,传统卷积神经网络的卷积核为二维,只能提取视频帧在空间上的特征,无法提取时间上的特征,本发明采用卷积核与池化核均为三维的c3d神经网络可同时提取人体行为的空间和时间特征。
背景技术:
2.随着科技的发展及民众对于社会安保的要求越来越高,监控摄像头被大量地安装于公共场所中。但监控摄像头数量的增加以及监控系统的复杂化、多样化,使得传统的监控数据处理方式(如人工观看监控视频)已不能满足当前的安保需求,因此智能视频监控系统成为了研究的热点。视频中异常人体行为检测是智能视频监控系统的研究核心,其研究重点是如何从视频中提取与行为相关的特征并进行异常识别。
3.在传统的研究方法中,通常使用人工构建的低级视觉特征来表征各种行为,如:
4.1.能够描述静止图像中人体轮廓以及形状的梯度方向直方图;
5.2.常用于描述运动信息,可以描述像素点的灰度值在相邻视频帧之间变化的光流;
6.3.描述运动目标轨迹的特征,该类特征重点关注运动目标的轨迹。
7.这些人工构建的低级视觉特征,由于特征本身较为单一,且很难描述较为复杂的行为,因此泛化能力通常不够强。另外,需要一定的先验知识才能构建这些人工设计的特征,而这些知识依靠于监视目标,在不同的应用中很难进行定义。近年来,由于基于神经网络的异常检测技术具有不需要人工选取特征、受环境因素影响小等优点,现已成为研究热点,可以预见使用神经网络进行端到端的人体行为异常检测将是未来发展的方向。
技术实现要素:
8.本发明的目的是克服现有技术中存在的不足,提出一种面向视频的鲁棒的异常行为检测方法。主要工作包括两个方面:
9.(1)模型构建:构建的模型包含人体检测模块与异常检测模块,其中人体检测模块基于yolov3神经网络,用于提取当前检测帧中的人体区域;异常检测模块基于c3d神经网络,用于提取连续的只包含人体的图像序列中的特征信息,并根据该特征信息进行异常检测。
10.(2)模型测试:本文将对模型在帧级及像素级两个标准下分别进行测试,测试时模
型的输入是由当前检测帧、当前检测帧的前n帧和后n帧组成连续帧序列,输出是当前检测帧的判断结果(即是否出现异常人体行为)。
11.跟现有技术相比,本发明的主要优势在于:
12.(1)传统方法在提取行为特征时基于整个视频帧,由于人体只占视频帧的一小部分,因此会提取出无用的特征。为了解决这个问题,本发明使用yolov3先对视频帧中的人体进行定位,然后再基于人体区域进行特征提取,使得模型不受环境影响,鲁棒性更强。
13.(2)传统卷积神经网络的卷积核为二维,只能提取视频帧在空间上的特征,无法提取时间上的特征。本发明采用卷积核与池化核均为三维的c3d神经网络,可同时提取空间和时间特征。
附图说明
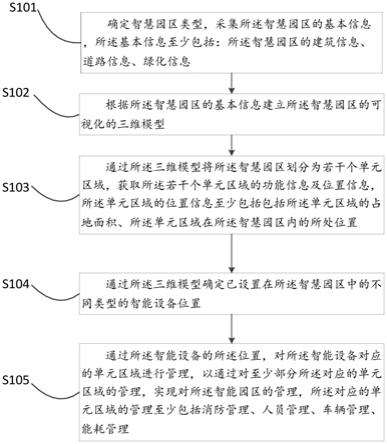
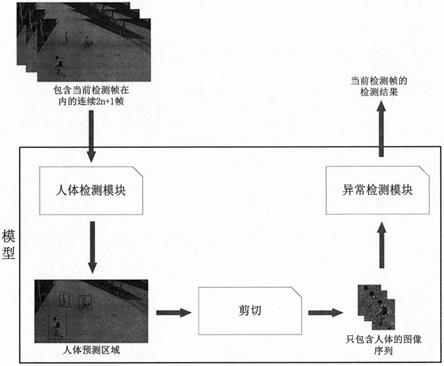
14.图1模型的总体流程。
15.图2 yolov3神经网络结构。
具体实施方式
16.本发明中模型的总体流程可参考图1,具体包括以下几个方面:
17.(1)模型输入
18.视频中的异常人体行为检测属于实时动作识别的一种,需要模型对视频中的每一帧进行检测,并给出检测的结果,但动作是一个变化过程,同时具有时间以及空间上的信息,仅靠一个视频帧无法进行动作识别。因此为了解决这个问题,模型的输入为连续的2n 1个帧,即把当前检测帧和它的前n帧以及后n帧作为一个样本输入进模型,从而提取当前检测帧中的动作信息,以便进行动作识别。
19.(2)基于yolov3的人体检测模块
20.yolov3网络结构如图2所示。视频帧中人体的检测流程具体为:
21.a.人体检测模块的输入为当前检测帧。为了方便yolov3网络进行目标检测,将每个输入进网络的帧放缩为416*416*3;
22.b.网络输出三个特征图,大小分别为13*13*[3*(5 n)],26*26*[3*(5 n)],52*52*[3*(5 n)],其中n为训练数据集中的类别数;
[0023]
c.对于每个检测区域,取n类中分数最高的那个类作为预测的类,并将所有预测类别为人体且置信度高于阈值的检测区域加入输出列表,剩余的舍弃;
[0024]
d.对输出列表中的所有检测区域进行非极大值抑制来去除重复度较大的区域;
[0025]
e.将输出列表中剩下的预测区域作为人体检测模块的输出。
[0026]
(3)基于c3d的异常检测模块
[0027]
c3d网络结构如表1和表2所示。由于使用尺寸为3*3*3的卷积核时,模型的表现最好,本发明将c3d网络的卷积核尺寸统一固定为3*3*3,并把卷积操作的步长统一固定为1*1*1。同时为了提升网络的泛化能力,降低网络的计算复杂度,在每个卷积层的后面都设置了一个池化层来对卷积层产生的信息进行降采样。池化层的池化方式均为最大池化,除了第一个池化层的池化核设置为1*2*2,步长设置为1*2*2,其余池化层的池化核统一固定为2*2*2,池化操作的步长统一固定为2*2*2。而第一个池化层之所以这样设置,是为了避免图
像序列中的时序信息被过早地降采样。在卷积核数量的设置上,由于前几层用于提取低级特征,后几层用于提取高级特征,而低级特征种类较少,多为通用的特征,高级特征种类较多,多为具体的特征,因此本发明中c3d网络的高层卷积核数量要多于低层。
[0028]
表1卷积及池化层结构
[0029][0030]
表2全连接层结构
[0031][0032]
为了提高网络的非线性表达能力,每个全连接层和卷积层的输出都需要经过relu激活函数,如式(1)所示:
[0033][0034]
网络使用的损失函数为二分类交叉熵,如式(2)所示:
[0035][0036]
其中n为样本数,y
i
为标签值,为预测值。
[0037]
网络使用的优化算法为动量梯度下降法,如式(3)所示:
[0038][0039]
其中α为学习率,β为动量参数,w为权重值,b为偏置值,v
dw
和v
db
分别为权重值和偏置值的指数加权平均。此外,本发明还在c3d网络中使用dropout层来降低网络在训练时产生的过拟合现象,从而提高网络的泛化能力。
[0040]
基于c3d的异常检测模块的具体检测流程为:
[0041]
a.异常检测模块的输入为连续2n 1个经过剪切的只包含人体的图像序列,剪切过程如下:以当前检测帧中第i个包含人体的预测区域为例,设该区域左上角的坐标为(x,y),区域的长度和高度为(w,h)。基于这四个值,将所有帧中相同位置的区域进行剪切,并将各帧剪切出的图像按原视频帧的顺序进行排序。为了方便c3d网络进行特征提取以及异常检测,在剪切结束后将所有图像的大小放缩为60*60*3;
[0042]
b.网络输出异常分数,将得到的分数与给定阈值比较,若大于或等于阈值则把该
输入判断为异常,反之则判定为正常;
[0043]
c.统计当前检测帧中所有预测区域的判定情况,若出现一个区域被检测为异常,则认为将该帧判定为异常帧,反之判定其是正常帧。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。