1.本发明属于计算机视觉技术领域,具体涉及基于图卷积网络的细微动作识别方法。
背景技术:
2.随着计算机视觉技术的发展,人体动作识别成为了计算机视觉领域中一项活跃但具有挑战性的任务。近年来,随着深度传感器和人体姿态估计技术的进步,获得准确的人体姿态数据变得更加容易。在过去的十年里,基于骨骼的人体动作识别引起了广泛的关注并取得了显著的进展。与原始的rgb视频剪辑序列相比,一个带有2d或3d坐标形式的人体关节骨骼序列信息量更稀疏。因此,为基于骨骼的动作识别设计的神经网络可以十分轻量和高效。最近几年也有很多学者进一步开发了各种深度神经网络,试图充分挖掘动态人体骨骼序列的内部特征。
3.作为单模态动作识别网络的输入,骨骼序列可以有效地描述全身人体运动。然而,在从视频帧中提取人体姿态的过程中,局部细微的运动线索可能会丢失。而且由于骨骼序列的稀疏性,它很难捕捉到人体运动中的细微特征,单纯依靠骨骼序列来识别人的动作有明显的缺点。首先,对于主要以局部细微运动为特征的动作类别,从两个连续帧中提取的骨骼之间的差异非常细微,这对于描述细微动作几乎没有用处。此外,当动作的身体运动较弱时,这种局部细微运动很容易被噪声姿态估计所掩盖。这种限制使得现有的方法不能正确地对仅表现出细微运动差异的动作进行识别以及分类。
技术实现要素:
4.本发明的目的是提供基于图卷积网络的细微动作识别方法,解决了现有技术中存在的仅稀疏骨骼信息不足以完全表征人体运动的问题。
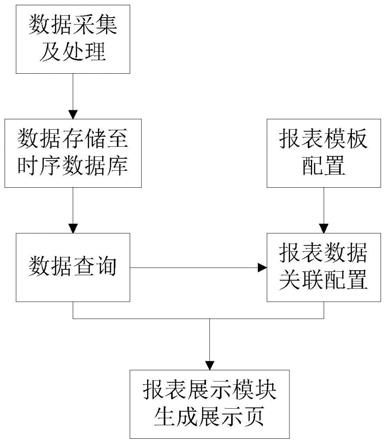
5.本发明所采用的技术方案是,基于图卷积网络的细微动作识别方法,具体按照以下步骤实施:
6.步骤1、采集人体运动视频,将该视频估计包括骨骼特征的视频,结合骨骼特征数据库,从骨骼特征数据库中选取所有类动作的骨骼特征序列;
7.步骤2、对包括骨骼特征的视频行处理,得到多个关节对齐光流片序列;
8.步骤3、搭建图卷积网络;
9.步骤4、设计图卷积网络的损失函数;
10.步骤5、初始化图卷积网络中参数;
11.步骤6、分别将骨骼特征序列、关节对齐光流片序列作为输入,训练图卷积网络,得到训练好的图卷积网络;
12.步骤7、使用训练好的图卷积网络进行识别,得到未知细微动作类别信息。
13.本发明的特点还在于:
14.步骤1具体为:采集人体运动视频,使用姿态估计算法根据人体运动视频估计得到
包括骨骼特征的视频。
15.骨骼特征数据库中包括ntu rgb d.数据集、ntu rgb d 120数据集、kinetics
‑
skeleton数据集。
16.步骤2具体包括以下步骤:
17.步骤2.1、对包括骨骼特征的视频按帧进行拆分,得到t帧图像;
18.步骤2.2、假设t帧图像中每帧图像有k个关节,以每个关节作为中心,通过裁剪得到k个长度为l的方形局部裁剪片
19.步骤2.3、将预估骨骼特征数据对应的方形局部裁剪片序列标记为步骤2.3、将预估骨骼特征数据对应的方形局部裁剪片序列标记为
20.步骤2.4、取同一关节在相邻两帧图像为一对关节对,对标记后的裁剪片采用lucas
‑
kanade方法估计每个连续关节对之间的光流片序列;
21.步骤2.5、对每个连续关节对之间的光流片序列进行零均值归一化,获得关节对齐的光流片序列;
22.步骤2.6、使用双线性插值函数对每个关节对齐的光流片进行下采样,将分辨率从l
×
l降低到μ
×
μ,得到(t
‑
1)
×
k个尺寸为μ
×
μ的关节对齐光流片序列。
23.步骤3图卷积网络结构为双支路gcn结构,第一gcn分支输入骨骼特征序列,第二个gcn分支输入关节对齐光流片序列。
24.图卷积网络结构包括输入层、批量归一化层、九个级联的图卷积层、全局平均池化层、全连接层和softmax输出层;
25.每个图卷积层包括三部分:1、注意力机制层,2、空间图卷积层,在空间维度上,即单帧内对每个重心点上,进行图卷积操作,卷积核大小为3;3、时间图卷积层,在时间维度上进行图卷积操作,卷积核大小为9。
26.步骤4损失函数为交叉熵损失函数:
[0027][0028]
其中y表示ground
‑
truth类的one
‑
hot标签向量,表示预测得分。
[0029]
步骤5图卷积网络中参数包括训练遍历所有数据的次数epoch、每批次训练的样本数batch_size、学习率learning_rate,其中epoch设定为10
‑
20之间的整数,batch_size设定为{8,16,32,64,128,256}中的一个,learning_rate初始学习率为0.01,每10个epochs后,学习率衰减0.1,共遍历全部样本60次。
[0030]
步骤6具体为:将每个骨骼特征序列作为一个三维矩阵(c,t,v),c为关节特征也就是坐标,v为节点数量,每个骨骼特征序列输入至图卷积网络结构的第一gcn分支中;将关节对齐光流片序列进行下采样,将下采样得到的关节对齐光流片序列输入第二个gcn分支进行训练,得到训练好的图卷积网络。
[0031]
步骤7具体为:根据待识别的人体动作视频获得该视频对应的骨骼特征序列和关节对齐的光流片序列;将两个序列分别输入训练好的模型中,通过线性混合来自两个gcn分支的预测分数来获得最终的类别预测分数,根据最终的类别预测分数确定细微动作。
[0032]
本发明有益效果是:
[0033]
本发明基于图卷积网络的细微动作识别方法,将每个骨骼关节周围的视觉信息表示为关节对齐的光流片,有效地捕捉有用的身体局部细微运动线索,用于基于骨骼的动作识别。
[0034]
本发明基于图卷积网络的细微动作识别方法,将图卷积在时间维度上进行拓展,同时学习空间维度上的人体结构信息和时间维度上的信息,达到更好的识别效果。
附图说明
[0035]
图1是本发明基于图卷积网络的细微动作识别方法的从两个具有对应的2d姿态关节的连续帧中估计得到的关节对齐的光流片的流程图;
[0036]
图2是本发明基于图卷积网络的细微动作识别方法的两个连续帧的关节对齐光流片示意图;
[0037]
图3是本发明基于图卷积网络的细微动作识别方法的用于分别独立处理骨骼序列和关节对齐光流片序列的双流图卷积网络分支结构图;
[0038]
图4是本发明基于图卷积网络的细微动作识别方法的网络结构图。
具体实施方式
[0039]
下面结合附图和具体实施方式对本发明进行详细说明。
[0040]
本发明基于图卷积网络的细微动作识别方法,具体按照以下步骤实施:
[0041]
步骤1、采集人体运动视频,将该视频估计包括骨骼特征的视频,结合骨骼特征数据库,从骨骼特征数据库中选取所有类动作的骨骼特征序列;具体为:采集人体运动视频,使用姿态估计算法根据人体运动视频估计得到包括骨骼特征的视频。
[0042]
骨骼特征数据库中包括ntu rgb d.数据集、ntu rgb d 120数据集、kinetics
‑
skeleton数据集。
[0043]
步骤2、对包括骨骼特征的视频行处理,得到多个关节对齐光流片序列;步骤2具体如图1所示,包括以下步骤:
[0044]
步骤2.1、对包括骨骼特征的视频按帧进行拆分,得到t帧图像;
[0045]
步骤2.2、假设t帧图像中每帧图像有k个关节,以每个关节作为中心,通过裁剪得到k个长度为l(l取32)的方形局部裁剪片
[0046]
步骤2.3、将预估骨骼特征数据对应的方形局部裁剪片序列标记为步骤2.3、将预估骨骼特征数据对应的方形局部裁剪片序列标记为
[0047]
步骤2.4、取同一关节在相邻两帧图像为一对关节对,如图2所示,对标记后的裁剪片采用lucas
‑
kanade方法估计每个连续关节对之间的光流片序列;
[0048]
步骤2.5、对每个连续关节对之间的光流片序列进行零均值归一化,获得关节对齐的光流片序列;
[0049]
步骤2.6、使用双线性插值函数对每个关节对齐的光流片进行下采样,将分辨率从l
×
l降低到μ
×
μ,(μ取8),得到(t
‑
1)
×
k个尺寸为μ
×
μ的关节对齐光流片序列。
[0050]
步骤3、搭建图卷积网络如图3所示;图卷积网络结构为双支路gcn结构,第一gcn分
支输入骨骼特征序列,第二个gcn分支输入关节对齐光流片序列。
[0051]
图卷积网络结构如图4所示,包括输入层、批量归一化层、九个级联的图卷积层、全局平均池化层、全连接层和softmax输出层;
[0052]
每个图卷积层包括三部分:1、注意力机制层,用于衡量不同运动部位的重要性;2、空间图卷积层,在空间维度上,即单帧内对每个重心点上,进行图卷积操作,卷积核大小为3,用于计算某时刻空间中包含的信息;3、时间图卷积层,在时间维度上进行图卷积操作,卷积核大小为9,用于计算重心点在时间上运动包含的信息,卷积层步长为1,即在时间上每次移动一帧,空间上每次移动1个节点,计算后进行下一帧节点的卷积,每个图卷积层后进行随机dropout操作,dropout概率为0.5以避免过拟合,在第4、7层图卷积层以步长为2进行卷积来降低数据维度。
[0053]
图卷积公式如下:
[0054][0055]
其中节点v
ti
邻域定义为b(v
ti
)={v
qj
|d(v
ti
,v
tj
)≤d,|q
‑
t|≤γ/2},邻域同时包含空间上的邻域和时间上的邻域,其中d(v
tj
,v
ti
)表示v
ti
到v
tj
的最小路径,|q
‑
t|表示节点在时间上的距离,d与γ均为参数,因此采样函数可以写作p(v
ti
,v
tj
)=v
tj
,而权重函数并非给每个相邻节点一个唯一的标签,而是将一个关节点的邻域节点集合划分为多个子集,权重函数w(v
ti
,v
tj
)=w'(l
ti
(v
ti
)),其中l为将节点到子集标签的映射关系l
st
(v
qj
)=l
ti
(v
tj
) (q
‑
t γ/2)
×
k,其中l
ti
(v
tj
)是v
ti
中单帧情况下的标签映射关系,实际训练参数d=1,γ=9,k=2。
[0056]
步骤4、设计图卷积网络的损失函数;损失函数为交叉熵损失函数:
[0057][0058]
其中y表示ground
‑
truth类的one
‑
hot标签向量,表示预测得分。通过线性加权混合来自两个gcn分支的预测分数来获得最终的类别预测分数。
[0059]
步骤5、初始化图卷积网络中参数;
[0060]
图卷积网络中参数包括训练遍历所有数据的次数epoch、每批次训练的样本数batch_size、学习率learning_rate,其中epoch设定为10
‑
20之间的整数,batch_size设定为{8,16,32,64,128,256}中的一个,learning_rate初始学习率为0.01,每10个epochs后,学习率衰减0.1,共遍历全部样本60次。
[0061]
步骤6、分别将骨骼特征序列、关节对齐光流片序列作为输入,训练图卷积网络,ground
‑
truth类的one
‑
hot标签向量作为输出,成批次地输入到网络中,计算前向传播的损失,使用反向传播算法,调整各层神经元参数,最终得到训练好的图卷积网络;具体为:将每个骨骼特征序列作为一个三维矩阵(c,t,v),c代表关节特征也就是坐标,t=64,v表示节点数量,取25,对应其动作标签作为输出,每个骨骼特征序列输入至图卷积网络结构的第一gcn分支中;将关节对齐光流片序列进行下采样,下采样因子的值为2,并且序列长度是64,关节对齐的光流片序列(t
×
k
×
μ
×
μ
×2×
n=64
×
14
×8×8×2×
2)经下采样后转换为2t
×
k
×
μ2
×
n=128
×
14
×
64
×
2,再输入到,输入第二个gcn分支进行训练,模型训练过程采用随机梯度下降法,得到训练好的图卷积网络。
[0062]
步骤7、使用训练好的图卷积网络进行识别,得到未知细微动作类别信息,具体为:根据待识别的人体动作视频获得该视频对应的骨骼特征序列和关节对齐的光流片序列;将两个序列分别输入训练好的模型中,通过线性混合来自两个gcn分支的预测分数来获得最终的类别预测分数,根据最终的类别预测分数确定细微动作。
[0063]
实施例
[0064]
分别采用st
‑
gcn、as
‑
gcn、2s
‑
agcn、agc
‑
lstm、pb
‑
gcn以及本发明基于图卷积网络的细微动作识别方法对ntu数据集进行跨对象测试和跨视角测试,经验证测试准确率如表1所示:
[0065]
表1
[0066][0067]
表1中,ntu x
‑
sub(%)为ntu数据集跨对象测试准确率,ntu x
‑
view(%)为ntu数据集跨视角测试准确率。
[0068]
根据表1可知,本发明的基于图卷积网络的细微动作识别方法对ntu数据集进行跨对象测试和跨视角测试时,准确率均高于现有技术。
[0069]
通过上述方式,本发明基于图卷积网络的细微动作识别方法,将每个骨骼关节周围的视觉信息表示为关节对齐的光流片,有效地捕捉有用的身体局部细微运动线索,用于基于骨骼的动作识别。导出的光流片序列具有紧凑表示的优点,并且从人体姿态骨骼继承了有运动学意义的结构。基于所提出的双支路gcn框架,我们同时利用来自关节对齐的光流片序列的局部细微运动线索和来自骨骼序列的全局运动线索进行动作识别,识别率高且计算成本较低。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。