1.本发明涉及交通安全技术领域,尤其是涉及一种道路交通安全隐患点可视化鉴别方法。
背景技术:
2.道路交通安全在人们的社会生活中占据着举足轻重的地位,交通事故不仅会破坏交通秩序,还会造成更大的经济及人员损失。因此,研究道路交通安全隐患对道路交通安全管理至关重要。目前的研究多运用数理统计方法(如事故数法、泊松统计法、累计频率法、神经网络聚类法等)鉴别安全隐患点,进一步随着gis应用的不断发展,多采用核密度估计方法将空间统计纳入研究范畴内,更直观地发现道路安全隐患点的分布。但是目前的研究也存在一定的不足,一方面,研究虽考虑了安全隐患点的空间分布,但是在建模分析时没有考虑时间属性的影响;另一方面,在运用核密度估计方法时,常直接采用欧式距离计算方法,忽略路网的空间自相关性,影响隐患点分布的准确性。
技术实现要素:
3.本发明的目的是为了更准确地从时间和空间双维度上挖掘公路安全隐患点,把含有交通事故情景指数的网络核密度估计值作为识别指标。考虑路网的非匀质性,提出了基于网络时空核密度估计的方法。考虑网络核密度估计方法对0值的处理与实际具有较大差别,引入零膨胀负二项回归模型对核密度累积概率进行拟合,提出交通事故安全隐患点级别的划分标准和方法。
4.为实现上述目的,本发明提供了如下技术方案:
5.一种道路交通安全隐患点可视化鉴别方法,包括如下步骤:
6.s1、基于事故情景分类的网络核密度估计
7.依据交通事故严重性建立道路交通的网络核密度估计函数,然后依据核密度估计值建立三维可视化地图;
8.s2、安全隐患点段可视化分级鉴别
9.基于零膨胀的负二项回归模型对网络核密度估计结果进行拟合,然后采用累计频率法划分安全隐患点段等级阈值,最后通过实例分析对安全隐患点段分等级进行可视化展示。
10.优选的,所述步骤s1的具体过程如下:
11.s11:道路网络核密度估计
12.将道路路网引入网络空间环境中,并将道路划分为基本路段和交叉口,然后分别建立网络核密度估计函数;
13.s12:事故情景类别等级指数影响的网络核密度估计方法
14.网络核密度估计函数中引入事故情景等级指数,事故情景等级指数依据交通事故的严重性、可能性、危害性进行划分;
15.s13:基于事故情景分类的网络核密度估计可视化
16.通过数据处理和地图匹配,运用arcgis技术将网络核密度估计值进行三维可视化。
17.优选的,所述步骤s2的具体过程如下:
18.s21:基于零膨胀负二项回归的网络核密度估计
19.使用负二项回归模型对核密度估计值的过度离散数据进行回归分析,并将零膨胀参数引入负二项回归模型中,以解决核密度估计值的过度离势特征和零膨胀现象;
20.s22:基于累计频数法的隐患点等级阈值划分
21.采用累计频率法确定安全隐患点段等级阈值的划分标准;
22.s23:安全隐患点段等级鉴别可视化
23.利用网络核密度估计结果,使用arcgis软件中地理配准工具将路网底图和实景底图进行地理位置配准,同时将道路名称进行标注,实现安全隐患点段等级划分结果的可视化。
24.本发明的优点在于:
25.1、本发明以事故情况作为隐患挖掘的评价指标,充分反映了事故可能性、事故严重性与隐患的双重关系,解决了传统的交通事故隐患点挖掘基于交通事故的次数或概率,根据交通事故发生的可能性来衡量其隐患大小;
26.2、考虑路网结构特征及其在空间的非匀质性,融合事故情景推理结果,提出了基于网络时空核密度的山区普通干线公路事故隐患点鉴别方法;
27.3、核密度估计中以事故情景作为聚类指标,充分考虑了事故的可能性和严重性,与采用事故数量这一单指标相比,能更加深刻地揭露交通事故的分布特征。
附图说明
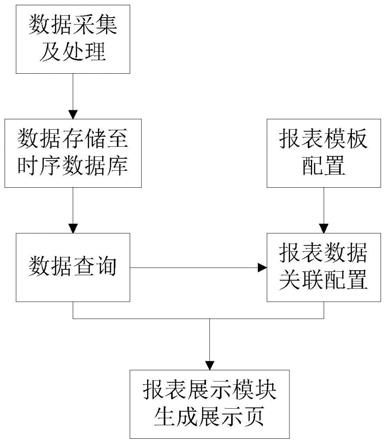
28.图1为本发明实施例的方法流程图;
29.图2为欧式距离与网络距离对比图;
30.图3为本发明实施例中交叉口区域的网络核密度画数图;
31.图4为本发明实施例中研究道路地理位置图;
32.图5为本发明实施例中网络核密度估计值分布图;
33.图6为本发明实施例中零膨胀负二项回归拟合前后的累计概率分布图;
34.图7本发明实施例中事故多发点段识别结果。
具体实施方式
35.以下结合附图和实施例对本发明的技术方案作进一步说明。
36.如图1所示的一种道路交通安全隐患点可视化鉴别方法,包括如下步骤:
37.s1、基于事故情景分类的网络核密度估计
38.s11:道路网络核密度估计
39.如图2所示,任意两点间的网络距离会明显大于两点之间的欧式距离,所以采用欧式距离的核密度估计可能引起一些不在窗宽范围内的事故点也被计算在核密度估计中,导致计算结果过大。因此,本发明采用网格距离对道路交通安全隐患点进行分析。具体步骤
为:
40.s111:道路基本路段网络核密度估计
41.网络核密度估计类似于平面核密度估计,也是在一定的带宽下,按照一个设定的密度函数,根据已知的事故点估算网络上任意一点的事件强度。不同的是,在网络空间环境中,待估计点的延展不是向所有方向发散,而是严格沿着道路网延续;带宽也不是以欧式距离计算,而是根据两个事故点之间的网络距离进行计算。网络核密度估计可以用来识别在网络限制的情况下,交通事故分布的安全隐患点路段。道路基本段网络核密度估计函数可以表示为:
[0042][0043]
式中,k(q)为点q处的网络核密度值,h为捜索半径(或窗宽),ds(q,p
i
)点事件p
i
到核中心q的距离,k()为核函数。
[0044]
s112:道路交叉口网络核密度估计
[0045]
公路网是道路基本段和交叉口共同组成的网络结构。与基本段道路环境的连续变化不同的是交叉口上几条交叉的路段在几何特征和交通流特性上存在明显的变化。道路基本段上交通事故点的核密度值在通过交叉口处会产生衰减效应,衰减系数的大小与交叉口处相交道路的个数有关。
[0046]
本发明中设置衰减系数α为1/(n
s
‑
1),n
s
是指交叉口处相交道路的个数。也就是说,若该交叉口是一个三路交叉,则交叉口处相交道路的个数为3,道路基本段上的核密度值通过三路交叉口处,其衰减系数α是1/(3
‑
1)=1/2,即将没有通过交叉口时的核密度估计值等分为2份,把等分之后的核密度值分配给通过交叉口处的两条道路基本段。
[0047]
图3说明了交叉口范围内网络核密度函数的变化情况,图中点q表示核中心,l1,l2,l3指的是三条不同道路基本段,v表示交叉口节点,s(q,p)表示从点q到点p的最短路径,k(ds(q,p))表示与点q距离ds(q,p)的网络核密度估计值。据此,交叉口范围内的网络核密度估计函数可以表示为:
[0048][0049]
s12:事故情景类别等级指数影响的网络核密度估计方法
[0050]
核密度估计函数中并没有考虑到事故所属情景类别对最终事故黑点鉴别的影响。相同的交通事故数量,其所属情景类别不同,即事故的严重性和可能性不同,对人民和社会的危害性也会不同。例如,若道路1上统计的交通事故大多是引起财产损失的轻微事故,而道路2上统计的交通事故不少是引起人死亡的恶性事故。这种情况下如果只考虑事故数量的影响,而不结合事故的严重程度对道路隐患点识别的影响,可能会导致之后的事故安全隐患点段的识别存在一定的偏差,以及影响优化措施的选取。因此,在网络核密度估计方法中结合交通事故所属情景类别,可以令道路交通安全隐患点的识别结果与实际交通安全情况更加符合。
[0051]
本发明在网络核密度估计函数中引入交通事故情景类别指数s
i
,交通事故属于情景一、二、三、四、五对应的s
i
分别取值为1、2、3、4、5。因此,道路基本段基于事故情景类别指数的网络核密度估计函数表示形式如下:
[0052][0053]
交叉口区域基于事故情景类别指数的网络核密度估计函数表示形式如下:
[0054][0055]
s13:基于事故情景分类的网络核密度估计可视化
[0056]
通过数据处理和地图匹配,运用arcgis技术将网络核密度估计值三维可视化,更加具象和直观的判定安全隐患点,有助于安全管理部门快速了解到安全隐患点所处的位置。通过三维地图的放大缩小实现道路细节展示及总体统筹,可对安全隐患点进行依次分析并制定相应的整治措施。
[0057]
s2、安全隐患点段分级鉴别
[0058]
考虑到网络核密度估计结果可能会出现零膨胀和过度离势的现象,为了更加准确的识别交通安全隐患点路段,本发明先基于零膨胀的负二项回归模型对通过网络核密度估计的结果进行拟合,然后采用累计频率法划分安全隐患点段等级阈值,最终可通过实例分析对研究区域内安全隐患点段分等级进行可视化展示。
[0059]
s21:基于零膨胀负二项回归的网络核密度估计
[0060]
分段统计网络核密度估计值的频率,结果显示核密度估计值为0的路段频率很高,这种现象就是所谓的零膨胀现象。产生这种现象的原因之一是事故的时空聚集特征,也就是有大量的交通事故出现在了极少数的道路上,另一个原因就是高斯核函数所具有的值跳跃现象可能会生成一些零值。
[0061]
通过对交通事故点网络核密度估计值进行统计分析,结果表明核密度估计值的方差显著大于其平均值,这种现象就是所谓的过度离势。
[0062]
若不讨论网络核密度估计值中具有的零膨胀以及过度离势特征,拟合出的曲线会总体逼近于零值,会导致多数交通安全隐患点段的丢失。基于此,本发明采用基于零膨胀的负二项回归模型拟合公路交通事故点网络核密度估计的结果。
[0063]
s211:负二项回归核密度估计
[0064]
负二项回归(negative binomial,nb)模型对泊松模型进行了一定的改进,一般情况下应用于泊松模型无法拟合的“过度离散”型的数据的回归分析中。负二项分布是一种连续的混合泊松分布,它的泊松均值可以服从γ分布,公式5表示了其概率分布:
[0065][0066]
其中λ为y的均值,τ为模糊参数,y是因变量也称为响应变量。当τ趋于无穷大时,该分布将没有过度离散现象,负二项分布接近于泊松分布。负二项分布具有方差大于均值的
特性。负二项回归模型的表达式和泊松回归模型类似,其数学表达式如式6所示:
[0067][0068]
式中,μ是自变量的指数函数,负二项方差为μ kμ2,其中k≥0为离散参数。离散参数及回归方程ln(μ)中的相关参数可以采用最大似然方法估计法进行计算。
[0069]
s212:零膨胀负二项回归核密度估计
[0070]
零膨胀负二项回归(zero
‑
inflated negative binomial,zinb)模型适用于包含大量零值的离散型数据的回归分析,它是一个由零分布和负二项分布组合的混合分布。zinb模型对应的混合分布的数学表达式如下:
[0071][0072]
式中:ω为零膨胀参数;μ为负二项回归分布的期望;θ为负二项回归分布的散度参数,θ=1/α。
[0073]
当ω>0时,模型为zinb模型;当ω=0时,模型演变成nb模型。
[0074]
zinb分布的期望和方差分别为:
[0075]
e(y)=(1
‑
ω)μ
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
[0076][0077]
在模型种加入协变量构建基于zinb分布的公路交通事故数量的zinb分析模型,如下式:
[0078][0079]
式中:x
i
为模型nb分布部分路段i上的交通事故影响因素,x
i
=(1,x
i1
,x
i2
,
…
,x
in
);z
i
为模型zi分布部分路段i上的交通事故影响因素,z
i
=(1,z
i1
,z
i2
,
…
,z
im
);β为模型中nb分布部分待估计的参数向量,β=(β0,β1,
…
,β
n
)
t
;γ为模型中zi分布部分待估计的参数向量,γ=(γ0,γ1,
…
,γ
m
)
t
。
[0080]
通过极大似然估计法能够用来求解零膨胀负二项回归模型,它的对数似然函数表达形式为:
[0081][0082]
令α=1/θ,分别对参数β,γ,α取偏导数,令偏导数为0,构成方程组,通过迭代平衡算法计算该方程组,最后求出过离散参数α、参数向量β和γ。
[0083]
s22:基于累计频数法的隐患点等级阈值划分
[0084]
采用累计频率法确定交通事故安全隐患点段等级阈值的划分标准。
[0085]
s23:安全隐患点段等级鉴别可视化
[0086]
利用网络核密度估计结果,使用arcgis软件中地理配准工具将路网底图和实景底图进行地理位置配准,同时将道路名称进行标注,实现安全隐患点段等级划分结果的可视化。
[0087]
案例分析
[0088]
s1:事故情景类别的网路核密度估计可视化
[0089]
路网数据:在识别事故多发点段的研究中,首先需要获取研究区域道路属性数据以及道路实景地图。基于道路属性数据可以获得研究道路的位置信息、道路等级信息、路网拓扑关系信息以及点事件与路网的空间位置关系等。基于道路实景地图可获得识别结果可视化程度较高的展示,更为清晰的判断事故多发点在地图中所处的实际位置,地图的可缩放性也使识别结果从总体概览到细节放大都得以实现。因此事故多发点段识别的第一步是从openstreetmap下载对应于研究区域的路网底图及实景底图,将路网底图转化为可被arcgis导入的shp文件,导入arcgis中筛选出研究道路(g324、g15、s308、x305等道路),并使用软件中地理配准工具将路网底图和实景底图进行地理位置配准,同时将道路名称进行标注,配准后的路网图如图4所示。
[0090]
事故数据:以2014
‑
2020年福建省内山区公路研究道路4652起交通事故数据为样本数据,利用关联规则和贝叶斯预测交通事故所属情景概率,作为本次实例的数据基础。将包含每起事故经纬度坐标和事故所属情景的事故数据导入arcgis中,并转化为包含空间位置信息和属性信息的点要素来表示道路交通事故发生的位置和对应情景。
[0091]
地图匹配:交通事故的发生位置理应是在道路路网上,由于统计误差,部分事故数据的位置坐标并未落在道路上,因此有必要将事故点图层进行绑路处理。同时由于研究道路彼此之间距离较远,基于几何的地图匹配较为简便且精度上不会有较大损失,因此本案例采取基于几何的地图匹配算法,即将事故点匹配到距离其位置最近的相邻道路上,实现方法为使用arcgis中的生成临近表工具,在arcgis中批量生成每条道路和每个事故点之间的距离,使用汇总统计数据工具筛选距离每起事故点最近的道路距离,使用连接工具进行表的关联,并以此距离为缓冲区大小建立缓冲区,取缓冲区面层和路网线层的交集作为匹配后的事故点位置,实现将事故点图层匹配到路网线图层上。由于距离值arcgis中存在细
微误差,有可能出现个别事故点匹配不上的情况,需进一步使用arcgis中的工具进行进一步灵活处理匹配。
[0092]
核函数:基于事故情景类别等级指数的网络核密度估计函数,本发明选取高斯函数为核函数,按照其积分均方误差最小的方法求最优带宽,取其临近值150m,既有研究表明线性单元长度值取线性单元长度的1/10左右较为合适,因此本例中取为15m。对网络核密度值进行计算,对划分路段单元后的道路属性表添加字段存储计算后的事故情景类别指数加权的网络核密度估计值。
[0093]
图5展示了研究道路的可视化结果。由图5可以直观观察到研究道路基本路段位置被渲染的颜色中绿色和黄色占比较大,相应的三维高度也较低,表示对应于较低的网络核密度值和较低的事故风险。与之相比,两条道路相交的交叉口附近路段被渲染的颜色中偏红色占比较大,相应的三维高度也有明显增高的趋势,表示对应于较高的网络核密度值和较高的事故风险,这与道路实际交通安全情况大致吻合。
[0094]
s2:安全隐患点段可视化鉴别
[0095]
s21:零膨胀负二项回归模型的网络核密度累计概率统计
[0096]
本案例累计概率分布曲线如图6所示。从图6中可以看出原始的累计概率分布曲线网络核密度值为0的纵坐标起始点处于累计频率50%左右,对网络核密度值采用零膨胀负二项回归模型拟合之后该曲线从0起始,且上升阶段相较于拟合前更加光滑,且能够更加准确反映出网络核密度值的分布情况。表1列出了基于零膨胀负二项回归模型得到的研究区域内累计概率分别为90%、80%和70%对应的网络核密度值。
[0097]
表1基于零膨胀负二项回归模型的事故多发路段划分标准
[0098][0099]
s22:安全隐患点段等级识别结果可视化展示
[0100]
并在可视化结果中用不同颜色进行区分,其中红色、橙色、黄色分别代表一级、二级和三级隐患点,绿色代表非隐患点,研究区域内事故安全隐患点段等级识别结果见图7,方框部分为红点集中出现处。
[0101]
以上是本发明的具体实施方式,但本发明的保护范围不应局限于此。任何熟悉本领域的技术人员在本发明所揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内,因此本发明的保护范围应以权利要求书所限定的保护范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。